像编辑文本一样编辑语音,可能吗?

(本文阅读时间:19分钟)
无论是演示视频、教学视频、会议录像还是记录生活片段的 vlog,在很多实际的应用场景中,人们常常需要重新录制语音(视频)或对语音(视频)进行编辑。因为拍摄的素材中往往会存在大量停顿和脱口而出、词不达意的语句,或者是冗余的内容。但由于声音的特性,我们没有办法在录音底本的基础上去修改字词,只能一帧一帧在剪辑上下功夫,因此声音的剪辑工作繁琐又充满挑战。如果拥有一个基于文本的语音编辑系统,可以通过直接编辑语音对应的文本,完成对语音(视频)的编辑,那么普通用户也能成为一个有创意的剪辑师,把一段冗杂的音视频变得清晰、自然又专业。
市场上现在已经有一些类似的产品或相关的研究工作,但都有一些限制:有的研究工作可以根据文本合成匹配上下文的语音,但是必须是模型训练过程中学习过的音色;有的产品想合成定制化的声音,比如用户自己的音色,但需要用户准备至少10分钟的声音,并将声音上传,然后再等待2-24小时,通过后台对声音进行训练之后,软件才可以合成定制化的声音。这些限制无疑都给基于文本的语音编辑在现实中的使用带来了极大的不便。为此,微软亚洲研究院的研究员们研发了一个基于文本的语音编辑系统,来解决这些技术难点。
在以语音为主的音视频中,语音中的内容和文本有着时间上的一一对应。研究员们发现,若要让基于文本的语音编辑系统可以直接编辑文本,再根据语音和文本的对应关系自动完成语音的编辑,需要着重关注以下技术要点:

图1:语音和文本的对应关系
1. 自动语音识别:如果语音不是按照已有脚本读的,那就没有文本信息,需要 ASR(自动语音识别)来识别得到文本,现有的 ASR 系统已经能够准确地识别语音,但受限于训练数据,部分 ASR 系统并不能完全检测出语音中的填充词。
2. 语音和文本对齐:研究中需要一个语音文本对齐(forced alignment)模块来提供准确的文本和语音的对齐结果,以便可以精确定位到要编辑的文本在语音中的时间戳。这是一个非常基础但十分重要的技术点,也是一个传统的研究问题,一般用于语言学研究或发音评估或为 TTS(语音合成)提供对齐的训练数据。现有的强制对齐方法几乎可以满足这些需求,但是对于基于文本的语音编辑,则需要更准确的对齐方式。现有的对齐方法在几十毫秒的误差级别下仍不能做到完美,而一旦出现几十毫秒的误差,比如切割语音的时候多切或少切了几十毫秒,人的听觉会很容易察觉到,并产生不适。
3. 语音合成:当插入或修改文本时,需要语音合成模块来生成新的声音。语音合成的最大挑战是自然和流畅,对于基于文本的语音编辑尤其重要,因为如果只修改语音的一部分,稍有不连贯就会非常明显。而且研究员们期望在使用语音编辑技术的时候,可以随意进行编辑而不需要准备足量的语音数据去微调模型。因此一个零样本上下文感知(zero-shot context-aware)的 TTS 是必不可少的。
4. 填充词检测:填充词检测模块可以自动检测语音中的填充词,用户可以选择手动删除部分或自动全部删除。上文提到,部分 ASR 系统并不能检测到全部填充词,所以此时就没办法通过文本删除填充词来编辑语音。有的词是否是填充词可能取决于语境,比如“you know”是英语中常用的填充词,但是在“Do you know him?”这句话中它并不是填充词,这时就需要一个语言模型来进行判断。
研究员们首先调用微软云计算平台 Azure 上的 ASR 服务将上传的语音文件转化为文本,同时调用自行研发的填充词检测模型,并将填充词检测结果和 ASR 识别结果合并。然后就可以对文本进行编辑——对于删除操作,系统会根据对齐结果删除对应的语音片段;对于插入操作,系统会调用语音合成模型合成要插入的语音并插入原有语音中。下面是几个通过上述方法完成的基于文本的语音编辑样例:
修改文本样例
原始文本:understand for the question and answer benchmark we're also the first reach human parity
修改后文本:understand for the question and answer benchmark we're also the second reach human parity
原始语音:
修改后语音:
插入文本样例
原始文本:The song of the wretched
修改后文本:The famous song of the wretched
原始语音:
修改后语音:
删除文本样例
原始文本:some have accepted it as a miracle without physical explanation
修改后文本:some have accepted it without physical explanation
原始语音:
修改后语音:
填充词检测和去除样例
原始文本:We can edit your speech uh by just editing.You know, its transcript.
修改后文本:We can edit your speech by just editing its transcript.
原始语音:
修改后语音:
服务于语音编辑的语音合成模型需要做到三点:零样本、自然和流畅。其中自然又可细化为两点子要求:生成与目标说话人相似的音色,以及足够高的音质。经过不断探索,微软亚洲研究院的研究员们达成了以上目标,开发了一个零样本上下文感知 TTS 模型 RetrieverTTS,并在语音领域的顶级学术会议 InterSpeech 2022上发表了论文“RetrieverTTS: Modeling Decomposed Factors for Text-Based Speech Insertion”(欲了解论文详情,请查看:https://arxiv.org/pdf/2206.13865.pdf )。
设计思路
不同于已有方法中将语音插入任务视为文本-语音模态融合的思路 [3,5],如图2所示,研究员们将语音先解耦成文本、韵律(音素序列的音高、音量、时长)、音色、风格四个要素,再在每个要素上进行可控的编辑操作,最后将四部分合成为插入后的语音。一言以蔽之,即“先解耦再编辑”。

图2:语音合成设计思路
但是,在执行插入操作时对四种要素的操作是不同的:文本可以直接使用用户编辑后的文本;对于韵律而言,未被编辑的部分无需改变,而插入词的部分需要由模型根据上下文预测得到;由于说话人没有改变,因此音色和风格两个要素保持不变。文本和韵律在一句话的不同时刻是不同的,而音色和风格在一句话甚至连续的几句话中都不会改变,所以前者为局域要素,而后者为全局要素。
模型架构
研究员们使用 Fastpitch[1] 作为语音合成的主干网络。为了准确地以零样本的方式适应到任意说话者的音色,全局要素与局域要素之间的解耦应足够精准,全局要素的表征需足够完备且应泛化至任意说话人。研究员们在 ICLR 2022 发表的论文“Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph”[2] 中,已经在很大程度上解决了这一问题,并在零样本语音风格转换任务中取得了最先进的性能。在此,研究员们将“Retriever”中的全局要素建模方法引入到了语音插入任务中。

图3:语音合成模型架构
实验结果
如表1所示,RetrieverTTS 的语音插入效果对插入长度并不敏感。对于训练中没见过的说话人,即使插入语音长度超过两秒乃至生成一整句(long insert, full generation),其语音自然度仍然保持在较高水平。在插入少于6个词时 (short insert, mid insert),甚至达到与真人录音相近的自然度评分。

表1:语音合成对不同插入长度的鲁棒性测试
在表2的消融实验中,研究员们分别去掉了对抗训练(- adv),韵律平滑任务(- prosody-smooth),以及 Retriever 的全局要素建模方法 (- retriever),结果均发现明显的性能下降。在三次实验的测试样例中,研究员们分别发现了音质差、韵律不连贯以及音色不像的问题。这验证了 RetrieverTTS 三方面设计均达到了设计初衷。
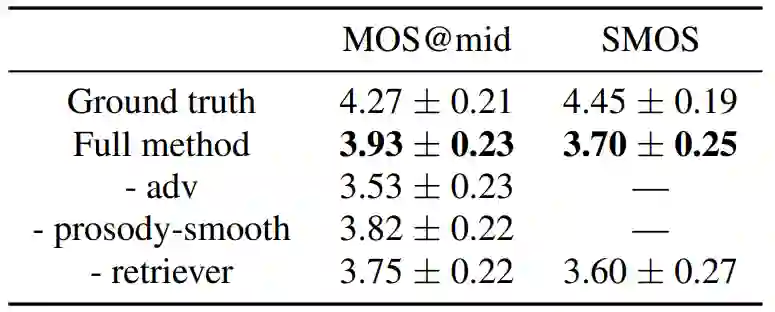
表2:语音合成消融实验
在表3中,研究员们与其他方法进行了对比,发现基于模态融合的方法[3]在插入较长语音的情形下语音自然度表现较差,而其他的零样本说话人自适应语音合成(zero-shot speaker adaptive TTS)[4] 在音色相似度方面与 RetrieverTTS 的方法有较大差距。上述对比体现出了 RetrieverTTS 方法的优越性。
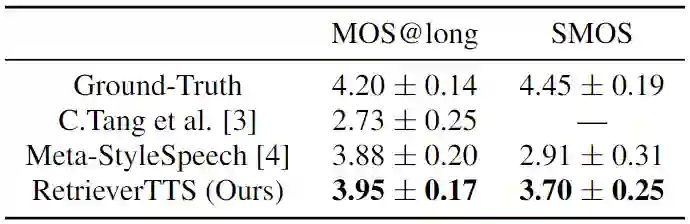
表3:语音合成系统对比
很多 ASR 模型由于受限于训练数据,不能完整的检测到填充词,因此需要一个单独的模块进行填充词的检测。事实上,基于语音的填充词检测技术属于语音关键词检测的一个特例,所以研究员们将语音关键词检测视为目标检测问题,而不是语音分类问题。受计算机视觉中目标检测方法的启发[6], 研究员们提出了一种名为 AF-KWS(anchor free detector for continuous speech keyword spotting) 的关键词检测方法。
在 AF-KWS 方法中,研究员们通过预测一个关键词热力图,得到每一类关键词在连续语音中的位置,然后通过两个预测模块,分别预测关键词的长度和用于矫正关键词位置误差的位置偏移量。不同于计算机视觉中的目标检测算法[6][7][8],研究员们引入了一个“unknown”类别,表示非目标关键词的其他词,这种设计将“unknown”和语音中的背景噪音和安静片段分开,能够显著提高关键词检测的准确性。该方法的论文“An Anchor-Free Detector for Continuous Speech Keyword Spotting”已经被 InterSpeech 2022 接收(更多论文细节,请查看:https://arxiv.org/pdf/2208.04622.pdf )。
算法框架
如图4所示,对于输入语音,研究员们首先提取了语音的 STFT 频谱图,然后使用 ResNet[9] 进一步提取特征,然后将特征输入三个预测模块,分别用于预测关键词的热力图、关键词的长度和关键词位置偏置。在训练阶段,热力图以关键词的位置为中心,使用高斯核函数将关键词的位置扩展。在预测阶段,研究员们取预测得到的热力图的峰值点作为预测得到的关键词的位置,然后提取对应位置的关键词长度和偏置的预测结果,计算得到最终的关键词的位置和类别。
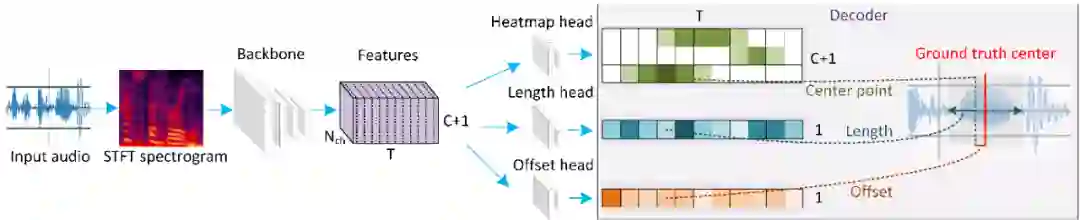
图4:AF-KWS 算法框架
实验结论
研究员们选用了两个先进的关键词检测模型[10][11]做对比,在连续语音关键词检测的实验设定中,AF-KWS 的模型在可比的运行速度下,平均准确率远超其他模型。

表4:填充词检测性能对比
为了验证 AF-KWS 方法的提升不是因为 backbone 更强大,研究员们将三个预测模块替换成了一个分类模块(AF-KWS-cls),发现模型性能明显下降。为了验证引入的“unknown”类别的有效性,研究员们去掉了这个类别(w/o unknown),发现模型性能也明显下降。
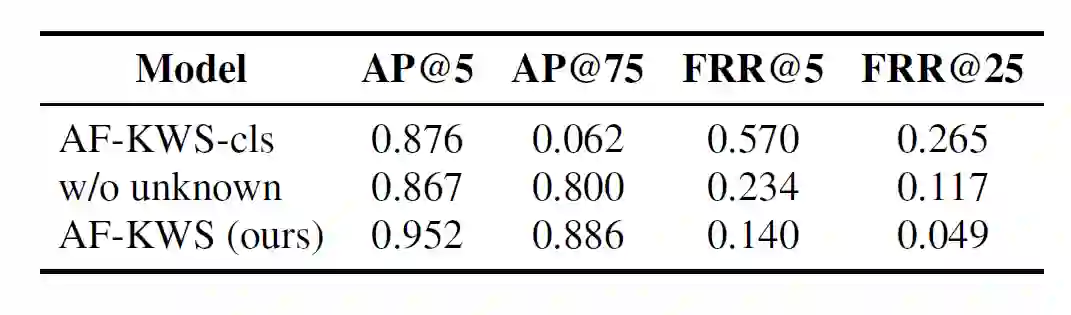
表5:填充词检测消融实验
关键词检测模型用于填充词检测
由于填充词也可以看作一种特殊的关键词,所以研究员们基于 SwitchBoard 数据集[12],制作了一个语音填充词检测数据集,并在这个数据集上重新训练关键词检测模型。在真实的测试数据中,AF-KWS 方法得到了与市面上最好的方法几乎相同的性能。针对填充词的特点,比如填充词一般包含的音节较少,更容易与特定类别的词混淆,研究员们会继续改进模型。
尽管现有的技术和本文中的语音编辑系统已经实现了基于文本的语音编辑的部分功能,但仍有很多研究需要持续探索,其中包括:开发富文本格式,进行语音解耦,精准控制语音的重度,语气语调和情绪;开发更精确的语音文本对齐算法;在 TTS 中背景噪音或背景音乐进行建模,让合成的语音包含匹配的背景噪声或背景音乐;开发结合语音和文本的多模态填充词检测检测算法;等等。
参考文献:
[1] A. Lancucki, “Fastpitch: Parallel text-to-speech with pitch prediction,” in ICASSP, 2021.
[2] Y. Dacheng, R. Xuanchi, L. Chong, W. Yuwang, X. Zhiwei, and Z. Wenjun, “Retriever: Learning content-style representation as a token-level bipartite graph,” in ICLR, 2022.
[3] C. Tang, C. Luo, Z. Zhao, D. Yin, Y. Zhao, and W. Zeng, “Zero-shot text-to-speech for text-based insertion in audio narration,” in Interspeech, 2021.
[4] D. Min, D. B. Lee, E. Yang, and S. J. Hwang, “Meta-stylespeech : Multi-speaker adaptive text-to-speech generation,” in ICML, 2021.
[5] Z. Borsos, M. Sharifi, and M. Tagliasacchi, “Speechpainter: Textconditioned speech inpainting,” arXiv preprint arXiv:2202.07273, 2022.
[6] X. Zhou, D. Wang, and P. Kr¨ahenb¨uhl, “Objects as points,” arXiv preprint arXiv:1904.07850, 2019.
[7] C. Zhu, Y. He, and M. Savvides, “Feature selective anchor-free module for single-shot object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 840–849.
[8] T. Kong, F. Sun, H. Liu, Y. Jiang, L. Li, and J. Shi, “Foveabox: Beyound anchor-based object detection,” IEEE Transactions on Image Processing, vol. 29, pp. 7389–7398, 2020.
[9] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 466–481.
[10] O. Rybakov, N. Kononenko, N. Subrahmanya, M. Visontai, and S. Laurenzo, “Streaming keyword spotting on mobile devices,” Proc. Interspeech 2020, pp. 2277–2281, 2020.
[11] S. Majumdar and B. Ginsburg, “Matchboxnet: 1d time-channel separable convolutional neural network architecture for speech commands recognition,” Proc. Interspeech 2020, pp. 3356–3360, 2020.
[12] John J Godfrey, Edward C Holliman, and Jane Mc-Daniel, “Switchboard: Telephone speech corpus for research and development,” in Acoustics, Speech, and Signal Processing, 1992. ICASSP-92., 1992 IEEE International Conference on. IEEE, 1992, vol. 1, pp. 517–520.
你也许还想看: