两分钟录音就可秒变语言通!火山语音音色复刻技术如何修炼而成?
先来欣赏一段音视频,或许你会有惊喜发现呢?
没错,这就是动漫海绵的配音模仿者的声音呈现。
不同的是,这位即将奔四的美国喜剧动画主角,如今在模仿者的演绎下一改往日的单一语言以及固定风格,居然一股脑儿说出了译制腔、TVB腔、粤语甚至上海话。
更重要的一点,所有风格以及语言,都是基于一段仅仅两分钟时长的纯中文音频训练而成。
话说两分钟时长的音频究竟可以包含多少内容?
经过语音方向的专业人士估算,基本等同于人们正常语速说出的20句话的内容量。
而这样既能保留本尊音色,又能实现多风格多语种无缝切换的“神奇语音”,还要归功于火山语音研发的“声音黑科技”,即音色复刻技术。
长期以来火山语音面向字节跳动内部各业务线以及火山引擎ToB行业与创新场景,提供全球优质的语音AI技术能力以及卓越的全栈语音产品解决方案。
这次推出的“音色复刻技术”,可以简单理解为“音色克隆”,是一种全自动、高效且轻量级的音色定制方案。
数据少成本低 便捷高效
不同于传统语音合成技术在模型训练环节对于数据的高门槛要求,火山语音音色复刻技术对数据量的需求仅为传统方法的0.3%,且对音色获取的要求也更简单——
无需专业播音员在录音棚长时间录制,普通人在相对安静的开放环境录制2分钟以上,即可达到音色空间建模的标准,生成专属音色的AI模型,便捷又高效。
多风格多语种 稳定质优
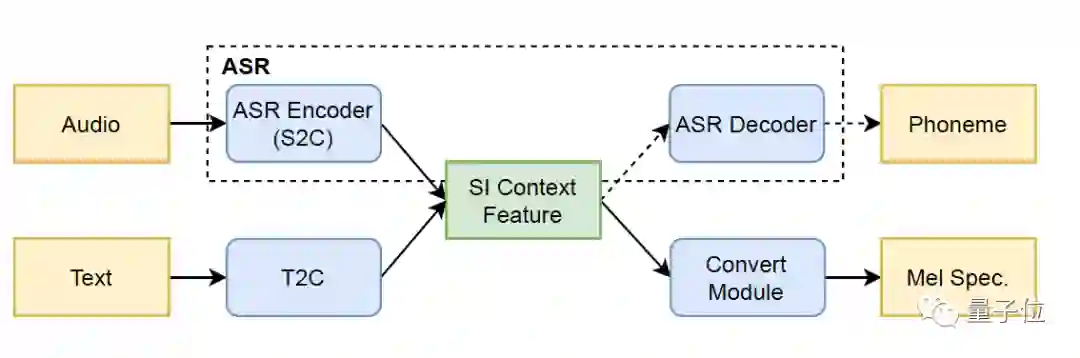
此外,火山语音自研的Imitator模型结构还可以做到从音频中提取与说话人无关的隐层语音表征(SI Context Feature),例如更多的韵律以及口音信息等,并以此作为文本与音频的中间特征来进行辅助模型训练,让音色还原更加准确。
据了解在预训练阶段,团队还采用了多风格、多语种、 多说话人的语音库进行平均模型训练,可以理解为在极少量的录音数据支持下,利用迁移学习自适应地创建音色还原度较高的语音合成模型,让合成音色在发音韵律和相似度上表现突出。
在音色复刻过程无需任何音频或者文本标注,不但节约人力成本,也降低了实操环节的系统复杂度。
此外,流式合成的技术可以使音色复刻的首包延时小于500ms,适用于大部分个性化语音场景。
整体来讲,不仅实现音色、风格以及语种的解耦,在发音稳定性以及音质上也达到业界领先水平。
全链路自动化 接入即用
该技术方案将通过火山引擎对外提供企业级服务,依托于火山语音优质的音色复刻SDK支持,其便捷的文本领读与录音功能,还有自带的环境检测以及字准检测,都能最大限度保障音频输入的质量。
同时后端经过自动化的模型加载功能,在不重启服务的基础上,做到将对应的音色进行热加载,实现音频录制到音色体验的全链路闭环,也就是说仅使用一套SDK就可完成全部资源的使用,目前线上SDK已支持中文普通话和英文两种语种选择。
该技术应用严格遵循合规要求,火山语音团队表示:
我们十分重视用户个人信息权益的保护,对于声音采集与训练,都已取得充分授权,保证音色复刻过程的合法性以及声音使用的合规性,再应用到企业服务场景中。
值得提及的是,目前该项技术已有核心专利加持。

总之想要制作个性化音频,只需单次录制2-10分钟并训练10-20分钟,输入文本后选择期望的风格和语种,就能快速合成并应用在新闻播报、智能客服等多个企业级服务场景中。
如今火山语音沉淀的语音识别和语音合成技术能力已成功应用到抖音、剪映、番茄小说等多款产品上,并通过火山引擎开放给外部企业。
*本文系量子位获授权刊载,观点仅为作者所有。
— 完 —

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~