微信AI的语音合成技术,让“读”书更尽兴

项目背景
微信语音合成+微信读书
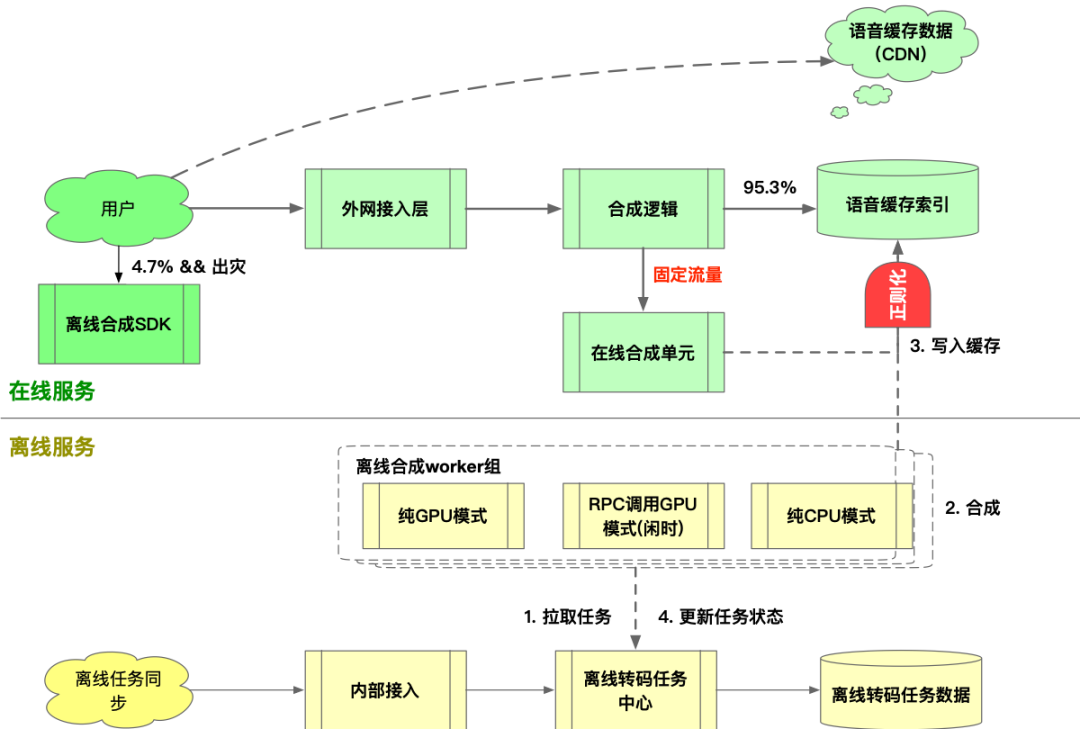
业务模型
系统构架
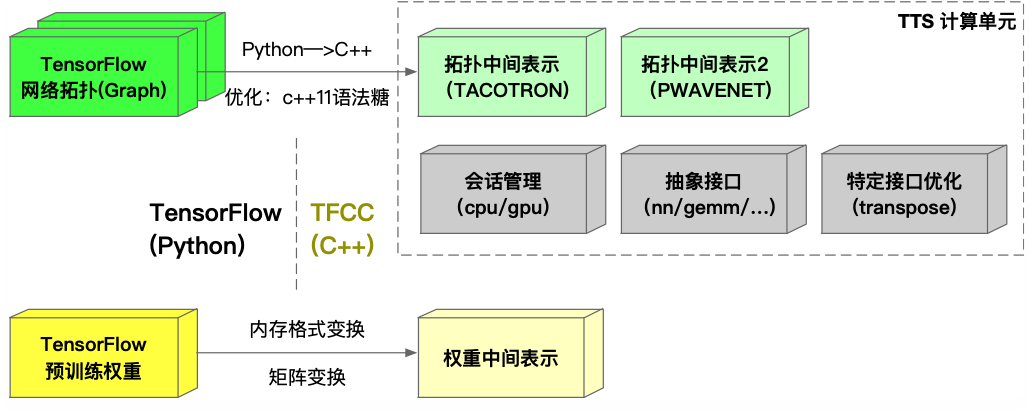
TFCC
模型多为python实现,而在线服务为c++,因此需要实现c++ - python的通信;
使用TF-serving的时候可能会遇到protobuf版本不兼容的问题,因此即使使用tf-serving依然需要将模型的inference放在一个单独的进程中;
不同业务用法不尽相同,增加了运维部署及扩容的成本与风险;
当业务需要在同一台机器部署多个模型时,无法按业务的模型定制化加载策略;
模型的前向计算是一个黑盒,要接入监控系统需要大量工作。
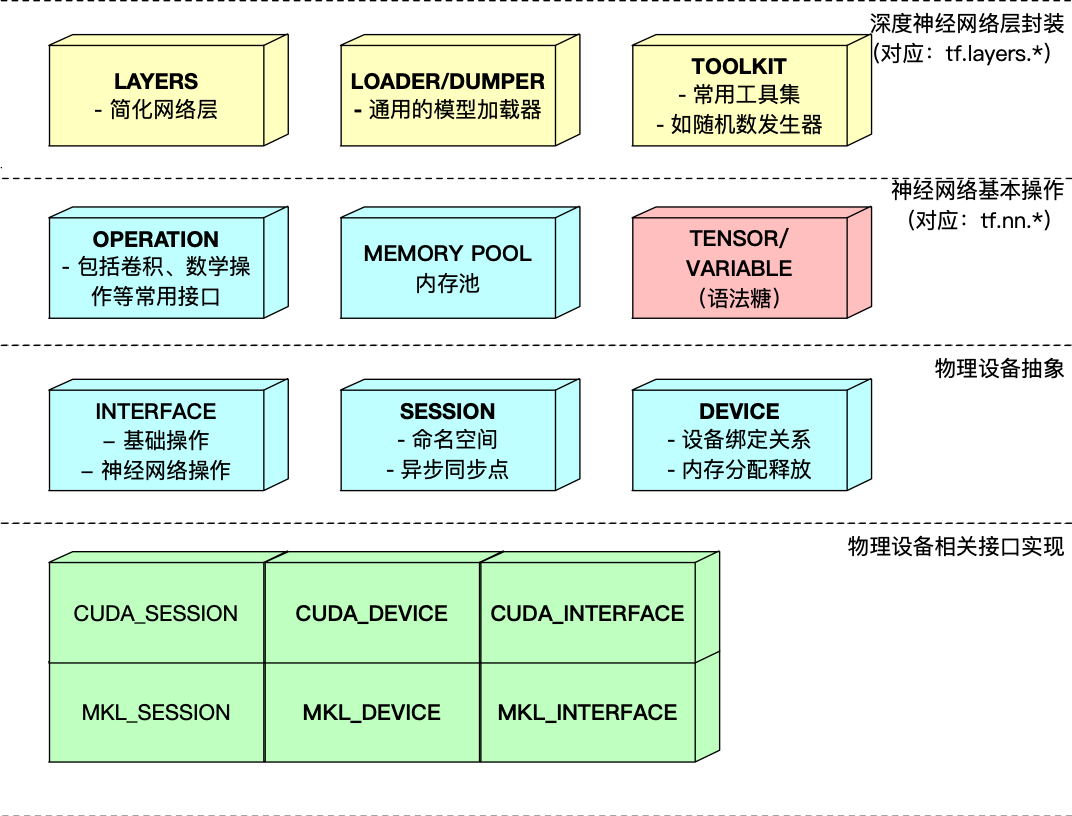
该框架可以应用于多种常用模型,如seq2seq,wavenet等;
使用该框架可以低成本地将一个tensorflow模型的前向计算转写为c++实现;
该框架原生支持tensorflow的checkpoint;
该框架可以提供给使用者自由选择在cpu或是gpu上完成前向计算。
Tensorflow(python)
With variable_scope(“dilated_conv_%d” % i)
C = conv1d(mel, gate_width, fiter_length, dilation)
D = d + c;
D = tf.sigmoid(D[:,:,:m]) * tf.tanh(D[:,:,m:]
TFCC(c++)
{
Auto x = tfcc::Scope::scope(“dilated_conv_”+tostr(i));
c = tfcc::layers::conv1d(l, args…);
}
D = d + c;
D = tfcc::math::sigmoid(tfcc::slice(d, 2, 0, m))
* tfcc::math::tanh(tfcc::slice(d, 2, m, -1));
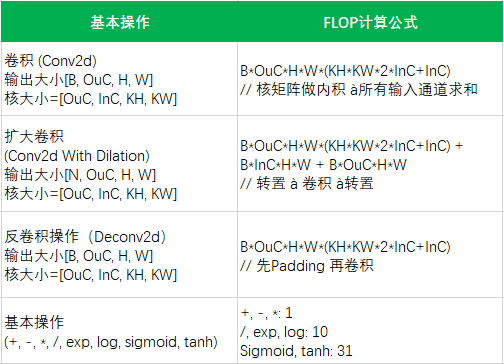
性能及成本优化
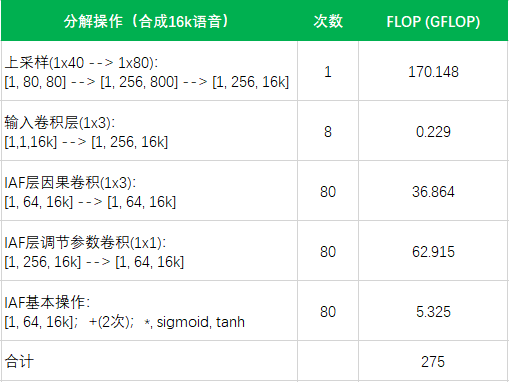
分析
估算
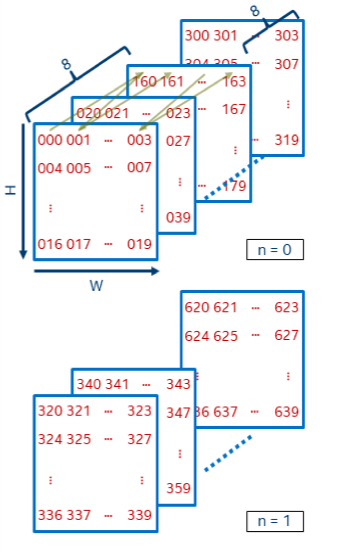
GPU的优化
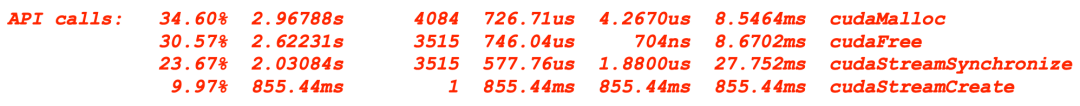
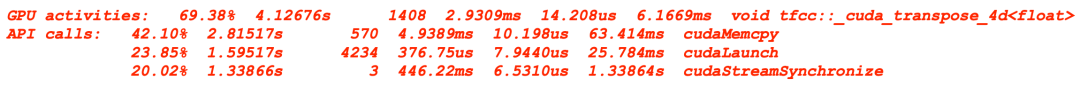

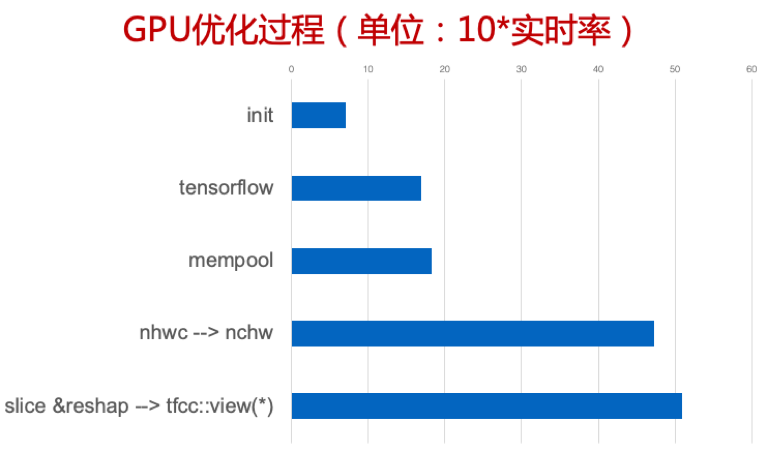
CPU的优化

export OMP_NUM_THREADS=12
export KMP_BLOCKTIME=0
exportKMP_AFFINITY=granularity=fine,verbose,compact,1,0


总结

微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。






