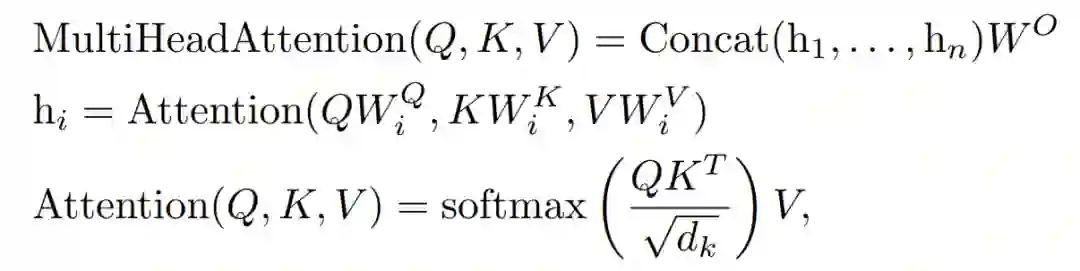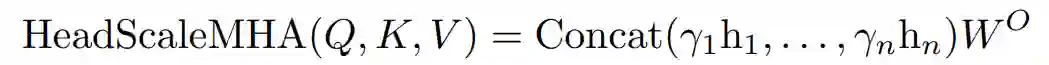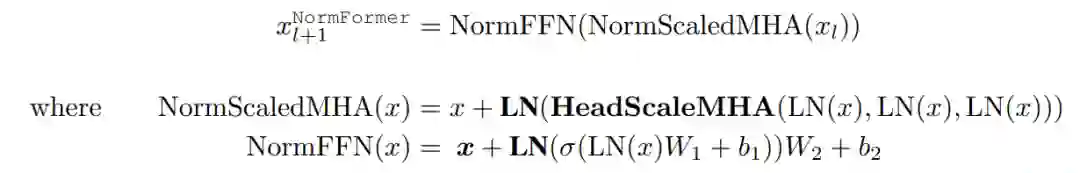©作者 | 杜伟、陈萍
来源 | 机器之心
来自 Facebook AI 的研究者提出了 NormFormer,该模型能够更快地达到目标预训练的困惑度,更好地实现预训练困惑度和下游任务性能。
在原始的 Transformer 架构中,LayerNorm 通常在 Residual 之后,称之为 Post-LN(Post-Layer Normalization)Transformer,该模型已经在机器翻译、文本分类等诸多自然语言的任务中表现突出。
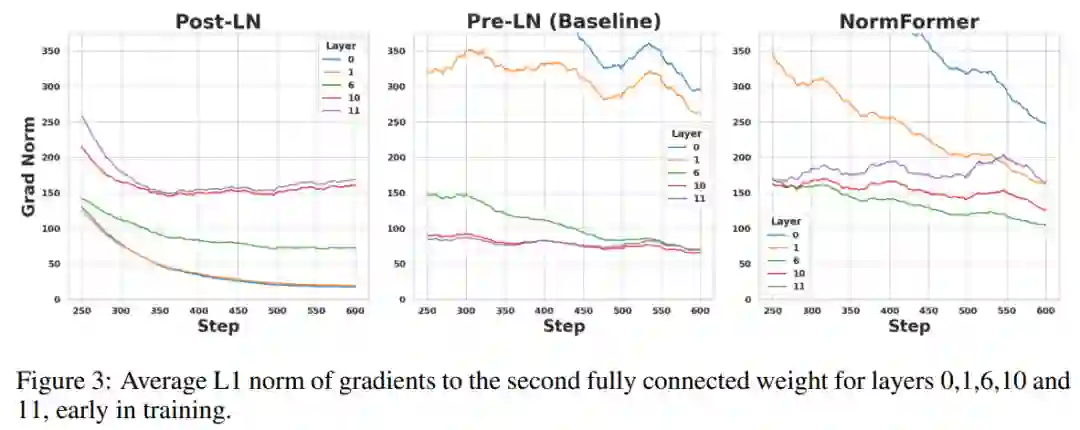
最近的研究表明,在 Post-LN transformer 中,与较早层的网络相比,在较后层的网络中具有更大的梯度幅度。
实践表明,Pre-LN Transformer 可以使用更大的学习率、极小的学习率进行预热(即 warm-up),并且与 Post-LN Transformer 相比通常会产生更好的性能,所以最近大型预训练语言模型倾向于使用 Pre-LN transformer。
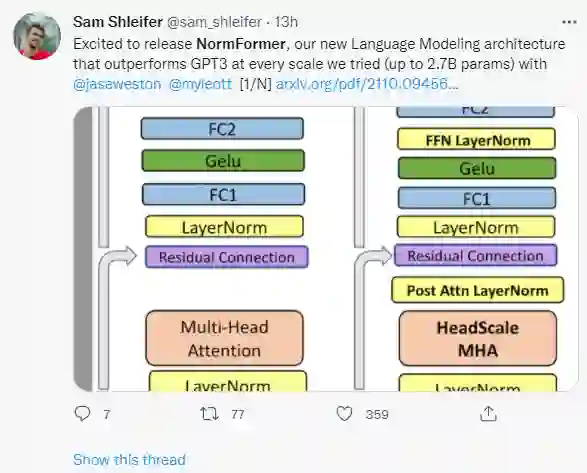
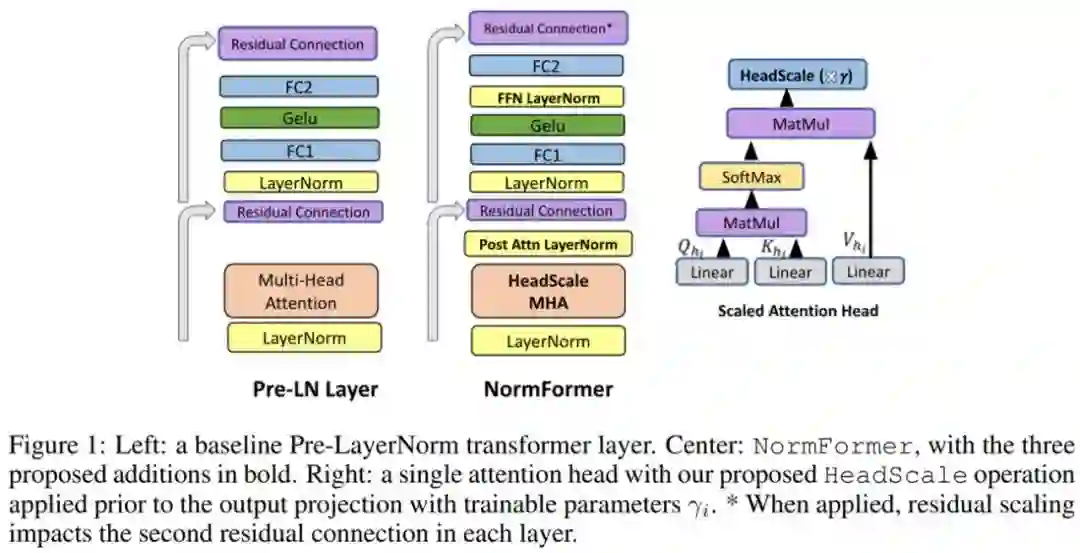
来自 Facebook AI 的研究者表明,虽然 Pre-LN 比 Post-LN 提高了稳定性,但也具有缺点:较早层的梯度往往大于较后层的梯度。这些问题可以通过该研究提出的 NormFormer 来缓解,它通过向每一层添加 3 个归一化操作来缓解梯度幅度不匹配问题(见图 1,中间):自注意力之后添加层归一,自注意力输出的 head-wise 扩展,在第一个全连接层之后添加层归一。这些操作减少了早期层的梯度,增加了后期层的梯度,使不同层的梯度大小更接近。
此外,这些额外的操作产生的计算成本可以忽略不计(+0.4% 的参数增加),但这样做可以提高模型预训练困惑度和在下游任务的表现,包括在 1.25 亿参数到 27 亿参数的因果模型和掩码语言模型的性能。例如,该研究在最强的 1.3B 参数基线之上添加 NormFormer 可以将同等困惑度提高 24%,或者在相同的计算预算下更好地收敛 0.27 倍困惑度。该模型以快 60% 的速度达到了与 GPT3-Large (1.3B)零样本相同的性能。对于掩码语言模型,NormFormer 提高了微调好的 GLUE 性能,平均提高了 1.9%。
![]()
论文地址:https://arxiv.org/pdf/2110.09456.pdf
与计算匹配、微调好的 Pre-LN 基线相比,NormFormer 模型能够更快地达到目标预训练的困惑度,更好地实现预训练困惑度和下游任务性能。
论文一作 Sam Shleifer 在推特上表示:很高兴发布 NormFormer,这是我们新的语言建模架构,在实验过的每个扩展(高达 2.7B 参数)上都优于 GPT-3。
![]()
来自魁北克蒙特利尔学习算法研究所的机器学习研究者 Ethan Caballero 表示:「更多的归一化 is All You Need,在 GPT-3 架构中使用 NormFormer 达到了 SOTA 性能, 速度提高了 22%,并在下游任务中获得了更强的零样本性能。」
![]()
NormFormer 对 Pre-LN transformer 做了三处修改:在注意力模块内部应用 head-wise 缩放,并添加两个额外的 LayerNorm 操作(一个放在注意力模块后面,另一个放在首个全连接层后面)。这些修改引入了少量额外的可学得参数,使得每个层都能以经济高效的方式改变特征大小,进而改变后续组件的梯度大小。这些变化的细节如下图 1 所示:
![]()
![]()
研究者提出通过学得的标量系数γ_i 缩放每个注意力头的输出:
![]()
额外层归一化以及将所有组件放在一起。在 Pre-LN transformer 中,每个层 l 将输入 x_l 做出如下修改:
![]()
相反,NormFormer 将每个输入 x_l 修改如下:
![]()
其中,新引入了 bolded operations。
对于因果语言模型(Casual Language Model),研究者预训练的 CLM 模型分别为 Small(1.25 亿参数)、Medium(3.55 亿参数)、Large(13 亿参数)和 XL(27 亿参数)。
他们训练了 3000 亿个 token 的基线模型,并用等量的 GPU 小时数训练 NormFormer 模型,由于归一化操作的额外开销,后者通常会减少 2%-6% 的 steps 和 tokens。
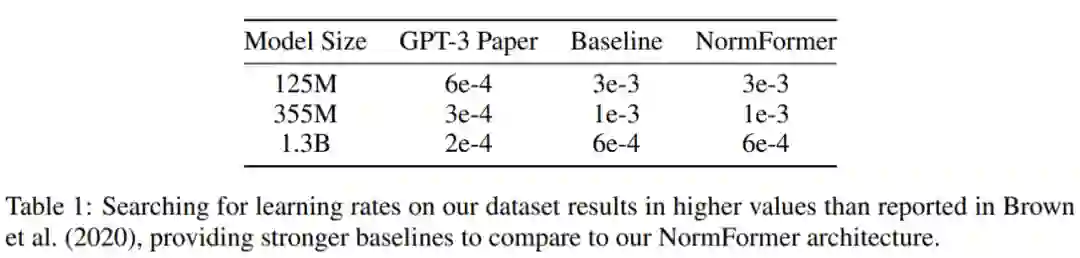
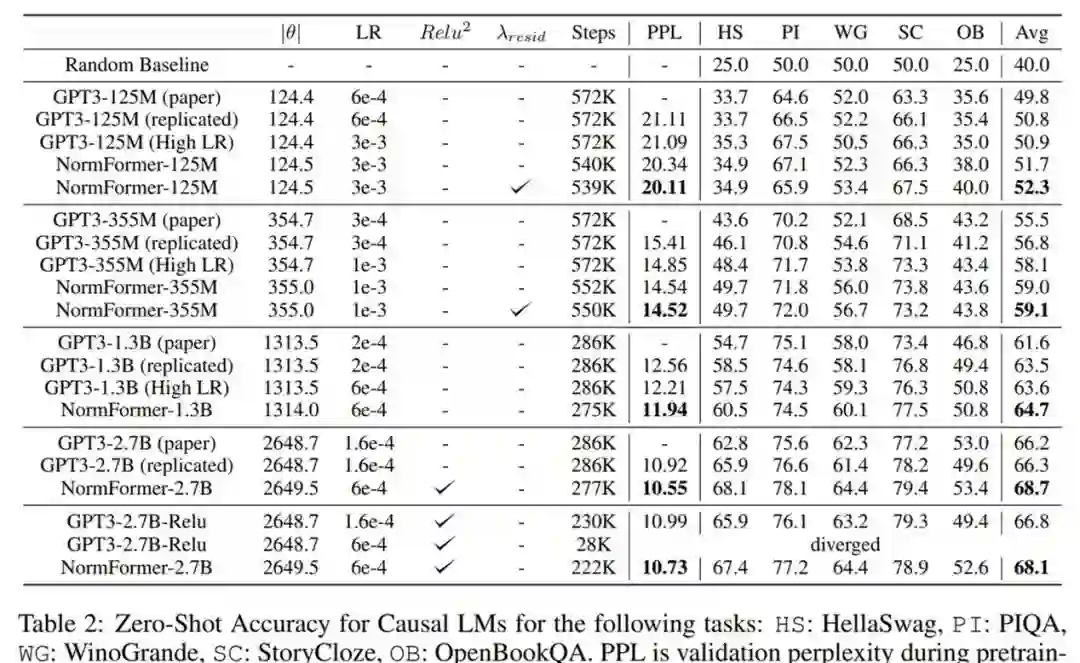
在使用的数据集上,研究者发现 GPT-3 中提出的学习率不是最理想的。因此,对于除了 27 亿参数之外的每个大小的基线和 NormFormer 模型,他们通过训练 5 万 steps 的模型并从 {1e−4, 6e−4, 3e−4, 6e−4, 1e−3, 3e−3} 中选择性能最佳的学习率来对学习率进行调整。这一过程中获得的学习率如下表 1 所示,NormFormer 的学习率是 GPT-3 的 3-5 倍。
![]()
对于掩码语言模型(Masked Language Model, MLM),研究者采用了 Liu et al. (2019)中使用的 RoBERTa-base、Pre-LN 架构和超参数。对于基线模型,他们对 100 万个 token 预训练了 200 万个 batch,是原始 roberta-base 训练预算的 1/4。相较之下,NormFormer 在相同时间内运行了 192 万个 batch。
对于预训练数据,研究者在包含 CC100 英语语料库以及由 BookCorpus、英文维基百科和 Common Crawl 过滤子集组成的 Liu et al. (2019)的数据英语文本集合上对所有模型进行预训练。
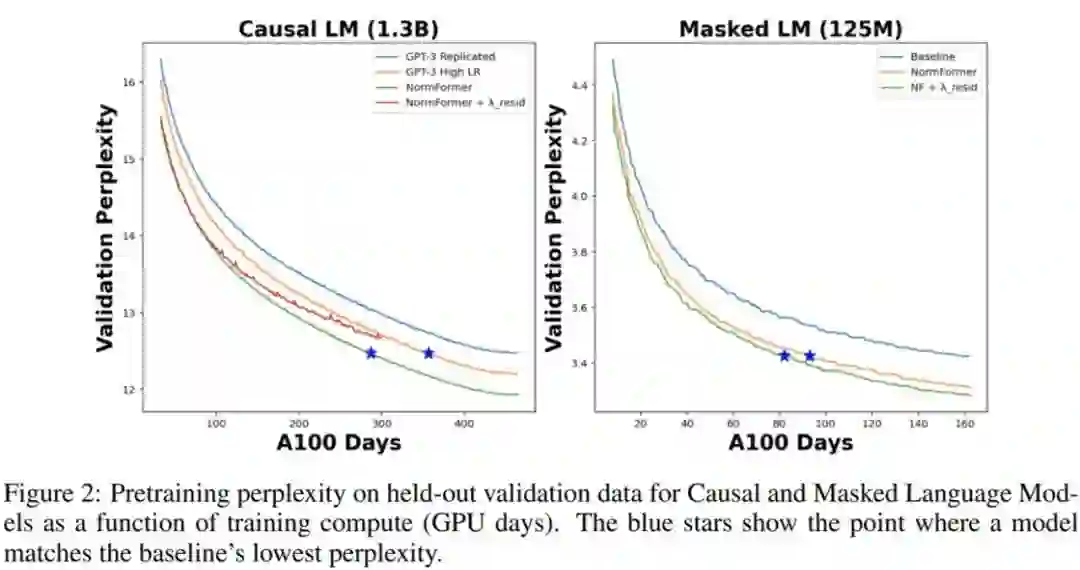
在下图 2 中,研究者将 CLM 和 MLM 的预训练困惑度表示训练时间,即 GPU days。可以看到,NormFormer 的训练速度明显更快,并且在给定训练计算预算下实现了更好的验证困惑度。
![]()
研究者在下游任务上也观察到了类似的趋势。如下表 2 所示,研究者使用 Brown et al. (2020)中的任务和 prompt 来观察 CLM 模型的零样本准确率。同样地,NormFormer 在所有大小上均优于 GPT-3。
![]()
对于 MLM 模型,研究者在下表 3 中报告了在 GLUE 上的微调准确率。再次,NormFormer MLM 模型在每个任务上都优于它们的 Pre-LN 模型。
![]()
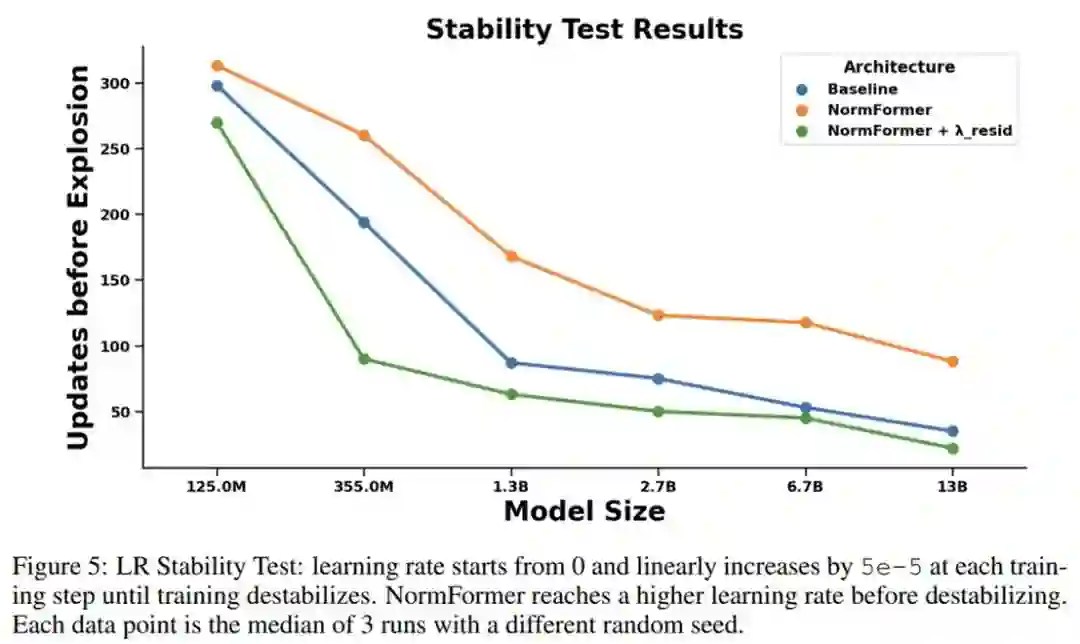
为了度量架构的稳定性,研究者使用具有极大峰值学习率的学习率计划对其进行训练,使得学习率每个 step 增加一点,直到损失爆炸。图 5 显示了与基线相比,NormFormer 模型在此环境中可以承受更多的更新。
![]()
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()