最好用的音轨分离软件spleeter:处理一首歌仅几秒,上线一周收获2.4k星 | 附实测
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
喜欢自己用手机K歌?但K歌App里人声往往清除得不够干净,录制起来效果一般。
现在有个AI神器可以干净地剥离歌曲里的乐器声啦。

来自法国的音乐流媒体公司Deezer开源了一个音轨分离软件spleeter,只需输入一段命令就可以将音乐的人声和各种乐器声分离,支持mp3、wav、ogg等常见音频格式。
这款软件基于TensorFlow开发,效果拔群,有网友说自己曾经试过无数类似软件,spleeter是最好用的一个。
量子位尝试了周杰伦的新歌《说好不哭》,人声轨道在开头部分几乎实现了静音,听不到任何乐器声,直到26秒才开始出现周杰伦的歌声:
而伴奏部分在整个过程中仅有极少量微弱的换气声:
spleeter还支持GPU加速。如果在GPU上运行,会比实时分解速度快100倍,也就是说分解一首5分钟的歌曲只需要3秒。
spleeter在GitHub上线仅仅一周,就收获了2.4K星,在Hacker News上也有1000+的热度。
最多分离5个音轨
用户可以根据自己的需求来训练模型,Deezer还给出了在musdb数据集上的预训练模型,因此能直接拿来使用。
在官方提供的预训练模型里,spleeter可将人声和乐器声分为2个音轨,已经能满足基本的要求。
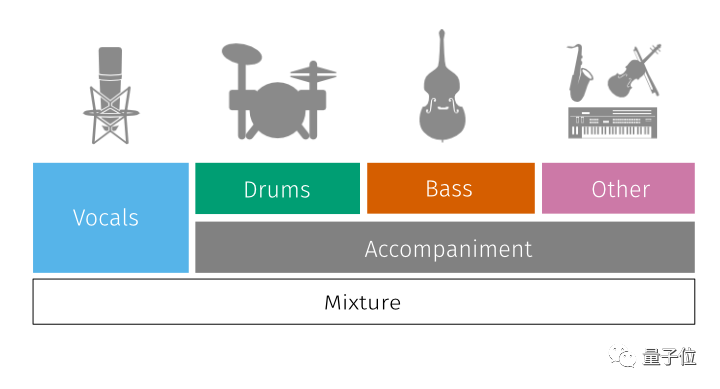
其中,2个音轨和4个音轨的模型在musdb据集上均具有最先进的性能。
使用方法
spleeter可以从conda或者pip安装。
如果用conda安装,可以选择CPU或者GPU环境,以CPU环境为例:
git clone https://github.com/deezer/spleeter
conda env create -f spleeter/conda/spleeter-cpu.yaml
conda activate spleeter-cpu
如果想换成GPU环境,只需将上述代码中的spleeter-cpu换成spleeter-gpu。
在分离音轨的命令中,加入选项-p spleeter:4stems来指定音轨数量,如果不加,系统默认分离为2个音轨。
spleeter separate -i audio_example.mp3 -o audio_output -p spleeter:4stems最终乐器和人声将以wav文件的格式保存在audio_output文件夹中。
分离过程可以在GPU或CPU上执行。在GPU上运行,速度非常快,可以实现100倍的加速。
经过实测,在单个英伟达 GTX 1080上,spleeter只用了90秒就分解完了3小时27分钟长度的musDB测试数据。
pip安装更简单,但是不支持GPU加速,一般分解一两首歌已足够使用:
pip install spleeter传送门
项目地址:
https://github.com/deezer/spleeter
— 完 —
大咖齐聚!量子位MEET大会报名开启
量子位 MEET 2020 智能未来大会启幕,将携手优秀AI企业、杰出科研人员呈现一场高质量行业峰会!VIP票即将售罄,快扫码报名吧~

榜单征集!三大奖项,锁定AI Top玩家
2019中国人工智能年度评选启幕,将评选领航企业、商业突破人物、最具创新力产品3大奖项,并于MEET 2020大会揭榜,欢迎优秀的AI公司扫码报名!


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !





