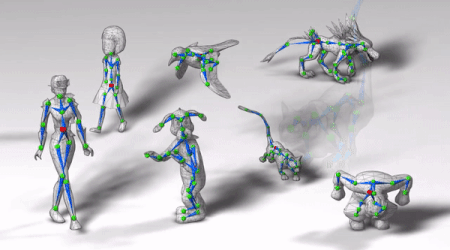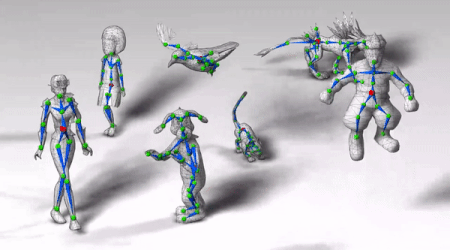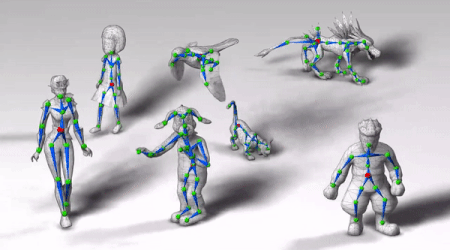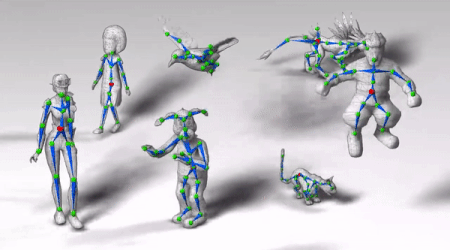点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
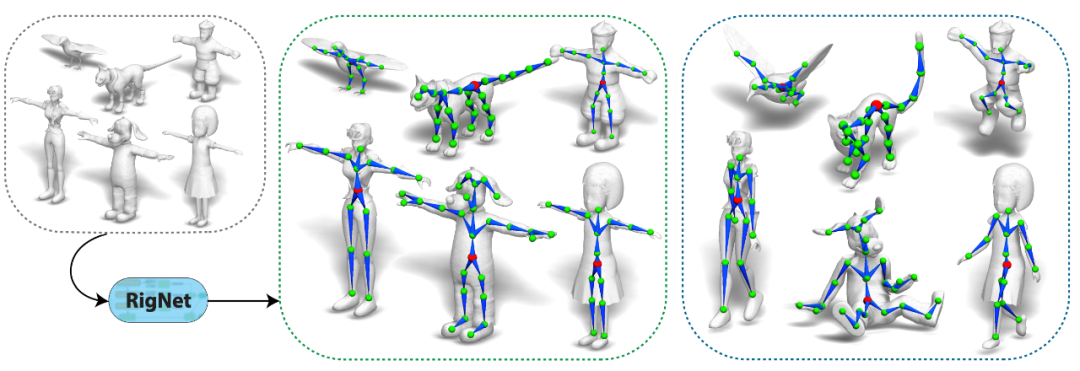
这篇SIGGRAPH 2020 论文提出基于输入角色模型生成动画骨架绑定结果的端到端自动化方法 RigNet,这或许能帮助加速动画制作流程。
在动画制作中,骨架绑定(Rigging)与动画密切相关。
什么是动画骨架绑定呢?基于 3D 蒙皮创建骨骼。动画模型中的关节就像现实中人的关节一样,两个关节组成一段骨骼,几段骨骼组成一个骨架。绑定就是把模型绑定到骨骼上边,通过骨骼来控制模型的运动。
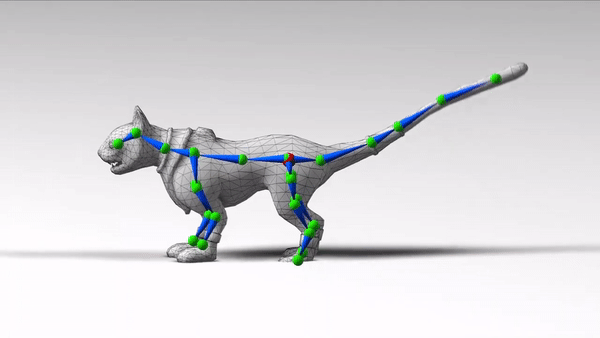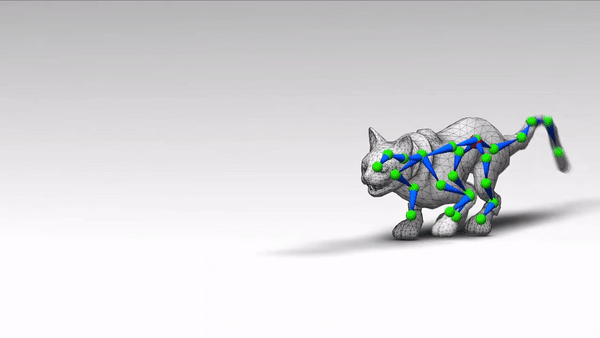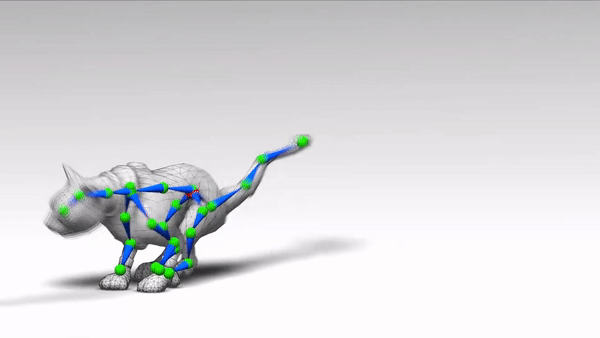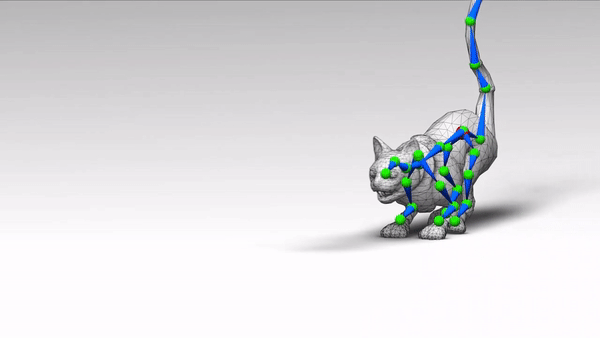
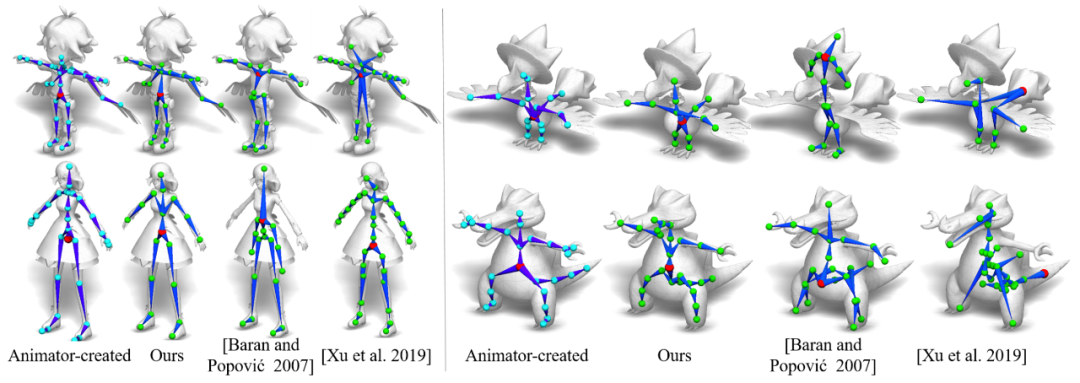
如下图所示,绿色球即为关节,蓝色线段为骨骼,多个骨骼构成了骨架。
![]()
给定 3D 角色蒙皮,RigNet 生成动画骨骼和蒙皮权重。
Rigging 本身是一项专门技术,骨架绑定结果的好坏对动画的质量有很大影响。那么,有没有什么办法可以简化该过程呢?
最近,
来自马萨诸塞大学阿默斯特分校和多伦多大学的研究者提出了一种基于输入角色模型生成动画骨架绑定结果的端到端自动化方法 RigNet,并以其优秀效果在 reddit 上引发大量关注
。
![]()
图中角色动作敏捷,关节活动自然,左摇右晃时身体协调性也不错。
![]()
走路、蹦跳、前跃、跳舞、飞翔,这些角色的动作都很自然。
论文链接:https://arxiv.org/abs/2005.00559
项目页面:https://zhan-xu.github.io/rig-net/
代码(暂未发布):https://github.com/zhan-xu/RigNet
了解了效果,接下来我们来看看 RigNet 是如何做到的。
给出表示某个铰接式角色的 3D 模型作为输入,RigNet 能够预测角色的骨架,且骨架的关节位置和拓扑结构与动画师的预期相匹配。此外,RigNet 还可以基于预测的骨架估计蒙皮权重。
该方法基于深度架构构建而成,此架构可以直接在蒙皮(mesh)表征上运行,无需对形状类别和结构进行假设。该架构的训练数据包含大量不同的骨架绑定模型,及其蒙皮、骨架和对应的蒙皮权重。
给定某个角色的 3D 蒙皮作为输入,RigNet 可以基于其底层关节结构和几何来预测动画骨架和蒙皮。动画师可对骨架和蒙皮权重进行编辑,以便通过标准建模和动画制作流程进行细化。
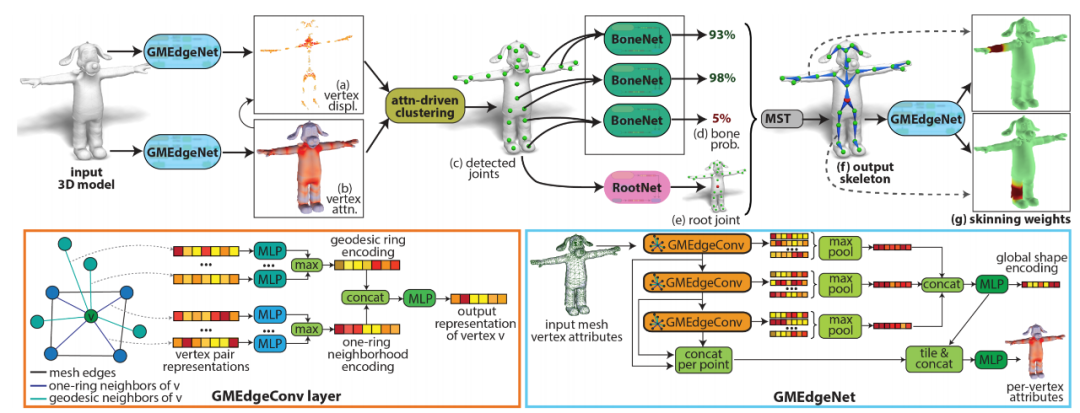
RigNet 的整体架构如下图 4 所示,它可以直接在蒙皮表征上运行,在训练或测试过程中无需事先了解角色的类别、部件结构或骨骼关节类别。该方法唯一需要的假设是,输入训练和测试形状需要具备一致的方向:直立、面朝前方。
![]()
图 4:(上)RigNet 流程概览。(下)GMEdgeNet 架构及其图卷积层(GMEdgeConv)。
给定一个输入 3D 模型,使用图神经网络 GMEdgeNet 预测顶点相对相邻关节发生的变化;
使用另一个具备分离参数的 GMEdgeNet 网络,预测蒙皮的注意力函数,这有助于找出与关节预测更为相关的区域(红色越重表示注意力越强,替换后的顶点也会根据注意力着色);
受蒙皮注意力的驱动,聚类模块检测出所有关节,即图中绿色球;
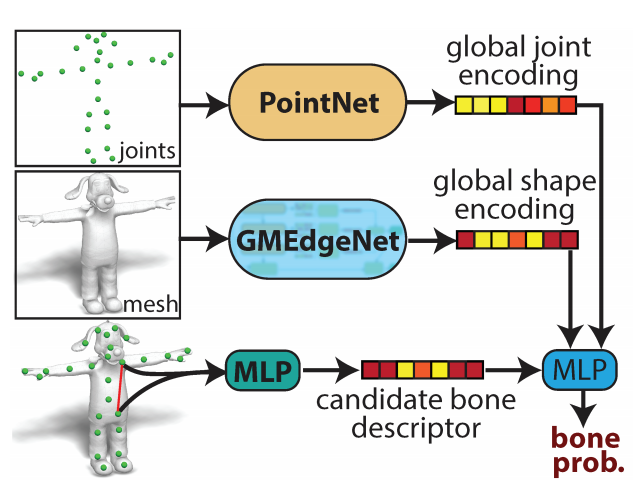
现在关节已经检测出来了,使用神经模块 BoneNet 来预测每对关节的相连概率;
使用另一个模块 RootNet 提取根关节(root joint);
最小生成树(MST)算法利用 BoneNet 和 RootNet,构建动画骨架;
最后,GMEdgeNet 模块基于预测到的骨架生成蒙皮权重。
该架构的第一个模块用于预测关节位置,可用于后续的动画骨架生成
。它学习替换候选关节位置的蒙皮几何(图 4a)。该模块基于图神经网络构建,从蒙皮中提取拓扑和几何特征,以学习这些替换。
在这一阶段,该架构的主要思路是:学习输入蒙皮的权重函数,用于找出与关节位置更相关的区域(图 4b)。实验表明,这带来了更加精确的骨架。替换后的蒙皮几何能够围绕候选关节位置形成集簇。
研究者提出一种可微聚类机制,利用神经蒙皮注意力来提取关节位置(图 4c)。
该架构的第二个模块学习哪些关节对应该与骨骼相连
。
该模块以之前步骤中得到的预测关节作为输入,包括学得的形状和骨骼表征,然后输出每个关节对是否与骨骼相连的概率(图 4d)。
研究者发现,学得的关节和形状表征对于骨骼估计很重要,因为骨骼连接不仅依赖关节位置,还依赖整体的形状和骨骼几何。
接下来,将得到的骨骼概率作为最小生成树的输入,即使用概率最高的骨骼构建树结构骨架。该步骤从另一个神经模块得到的根关节开始(图 4e)。
![]()
给定预测到的骨架(图 4f),该架构中的最后一个模块为每个蒙皮顶点生成权重向量,用以表示不同骨骼对顶点的影响程度(图 4g)。虽然该研究提出的方法受到 NeuroSkinning 的启发,但在架构、骨骼和形状表征、从顶点到骨骼的体积测地距离使用方面都有重要差别。
该架构使用了多个损失函数进行训练,这些损失函数用来衡量关节位置偏移、骨骼连接和蒙皮权重差异。
训练输入角色不管从结构、数量还是移动部分的几何来看都具备极大的多样性,如人形物、二足动物、四足动物、鱼、玩具、虚构角色等。同样地,测试集也具备类似的多样性。
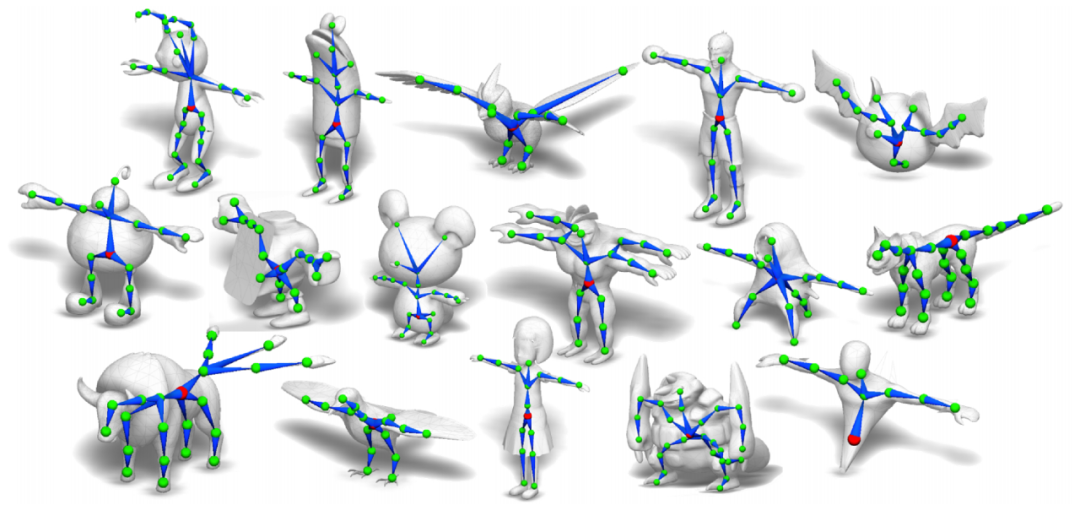
研究者观察到,该方法能够泛化到具备不同数量关节部位的角色中。
![]()
图 10:该方法基于测试模型得到的不同结构和形态的骨骼。
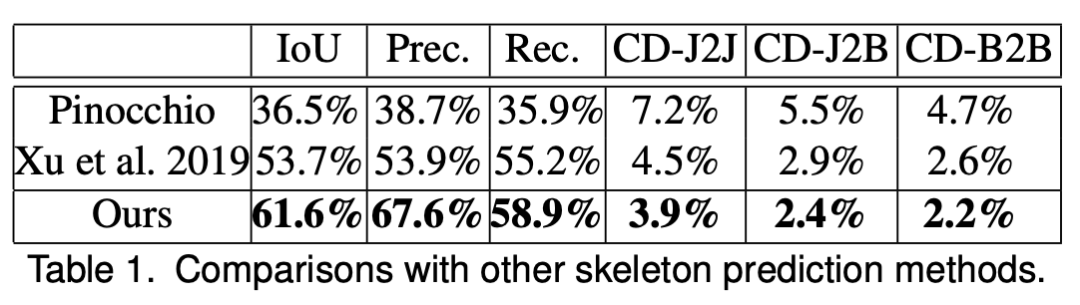
研究者对他们提出的方法与其他用于动画骨架和蒙皮预测的方法进行了定量和定性评估。下表 1 展示了不同方法之间骨架提取的评估度量。
本研究提出的方法在所有度量上均优于其他方法
。
![]()
![]()
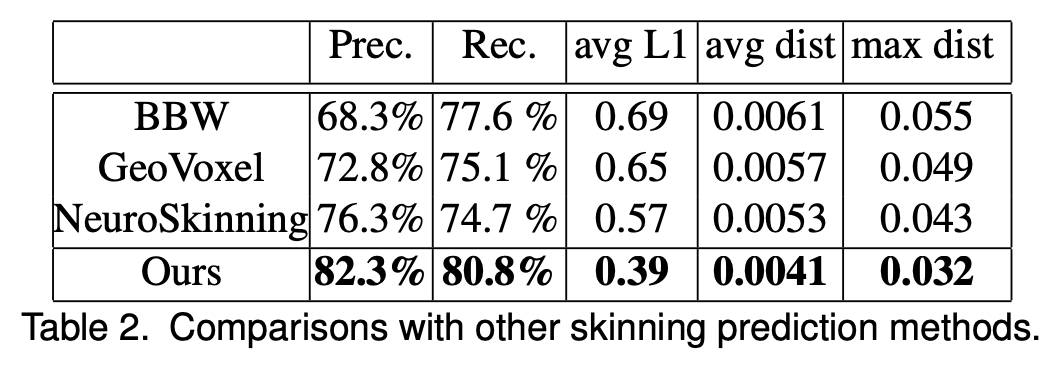
下表 2 展示了蒙皮的评估度量。结果显示,该研究提出的方法在所有度量上均优于 BBW、GeoVoxel 和 NeuroSkinning 方法。
![]()
表2:与其他蒙皮预测方法的比较。
![]()
该研究的作者为 ZHAN XU、YANG ZHOU、EVANGELOS KALOGERAKIS、CHRIS LANDRETH 和 KARAN SINGH,来自马萨诸塞大学阿默斯特分校和多伦多大学。
其中第一作者 ZHAN XU 是马萨诸塞大学阿默斯特分校的博士在读学生,导师为 Evangelos Kalogerakis。研究方向为视觉计算,计算机图形学、计算机视觉和机器学习的交叉领域。
第二作者 Yang Zhou 本科毕业于上海交大,导师为林巍峣教授。现在马萨诸塞大学阿默斯特分校读博,导师为 Evangelos Kalogerakis。其研究方向为计算机图形学和机器学习,研究兴趣是:利用深度学习技术帮助艺术家、动画师做出更好的设计。
前不久他和 Adobe、虎牙的研究人员合作提出了一种使单张照片张嘴说话的新方法 MakeItTalk,该方法不仅能让真人头像说话,还可以让卡通、油画、素描、日漫中的人像说话(参见论文《MakeItTalk: Speaker-Aware Talking Head Animation》)。
论文下载
在CVer公众号后台回复:RigNet,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1400+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
请给CVer一个在看!![]()