吴恩达团队提出倒计时回归模型:用AI技术预测病患死亡时间

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
对于事件(例如死亡)发生时间的个性化概率预测在制定决策中是十分重要的,尤其在临床情况下。受到气象学研究的启发,吴恩达团队通过最大化预测分布的锐度(sharpness)来解决这个问题。在回归问题中,研究显示通过优化连续分级概率评分(continuous ranked probability score, CRPS),能够带来锐度更高的预测分布,同时能够保持校准度(calibration)。
这篇论文介绍了 Survival-CRPS 模型,该方法是 CRPS 在预测事件发生时间上的推广,并且提出了右删失数据和间隔删失数据两个变种。为了全面评价预测分布的锐利程度,研究人员提出了 Survival-AUPRC 评价标准,计算方法类似于准确度 - 召回曲线下的面积。通过构建一个循环神经网络,将提出的方法应用于死亡预测。研究使用了电子医疗记录(Electronic Health Record, EHR)数据库,其中包含数百万个患者的医疗数据。实验结果显示,通过 Survival-CRPS 目标函数训练的模型的表现相比于最大似然法有显著提高。

在近几十年内,电子医疗记录(EHR)的普及为科学研究带来了数百万病患的详细医疗数据。大量的数据使利用机器学习模型对病人做出个性化的预测成为可能。
传统方法将病人的生存预测视作一个概率分类问题,即在一定的时间跨度上训练二值分类器来预测事件结果。但是这种方法有三个缺陷:首先,模型受到时间跨度的限制——如果模型的训练目标是预测一年内的死亡率,那么就很难直接获取 6 个月内的死亡率预测;其次,不能应用所有病人的数据——如果一个病人的 EHR 只有 3 个月的记录,那么对于预测一年内的死亡率问题,很难决定该将这个人划为正样本还是负样本。最后,在建立数据集时,对预测时间的选择毫无疑问受限于未来的结果——研究结果显示评价标准相比于真实情况过于乐观。
另一种方法是生存预测,即通过评价未来时间的概率分布来预测事件发生时间。但是常用的生存预测模型也有一些问题:第一,传统模型通常做出很强的假设。第二,这种模型应用于有大量删失数据的数据库时,对于低发病人群的预测不是很准确。第三,此类生存分析方法通常是对风险的点评价,而不是对预测分布的全局评价。
对比之下气象学预报通常是基于过去和目前的观测情况,对所有的天气情况作出全面的预测分布。预测结果由最大化预测分布的锐利程度来评价。一个预测分布的有用程度体现在它的锐利程度中,即数据的聚集程度。为了提高预测分布曲线的锐利程度,我们提出采用优于最大似然法的适当评分法则(Proper Scoring Rule)作为训练的目标函数。我们将 CRPS 扩展至生存问题中,定义为 Survival-CRPS,并且分别进行了数据右删失和间隔删失的延伸。
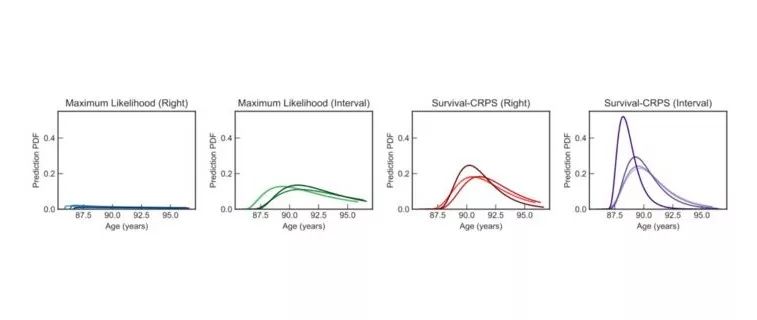
图 1
(1) 提出了适当评分法则 Survival-CRPS 作为生存预测的目标函数,并且提出了它的右删失和间隔删失变体。
(2) 提出了新的评价标准 Survival-AUPRC,来全面评价预测分布的质量。
(3) 给出了死亡预测任务的实用方法:在训练时使用对数正则参数化和间隔删失。
(4) 我们应用上述技巧,利用 EHR 数据训练一个深度循环神经网络模型,对患者的死亡进行准确的预测。
参数生存预测将事件发生的时间建模为一簇由分布参数定义的概率分布曲线。生存函数定义为 S(t)=[0,正无穷),定义域为 0 到 1。在正实数范围内单调递减。S(0)=1,t= 正无穷时 S(t)=0。生存函数代表一个个体在给定时间 t 内没有发生事件(死亡)的概率。每一个生存函数都有一个对应的累积分布函数(CDF):F(t)=1-S(t),和一个概率密度函数(PDF):f(t)=dF(t)/dt。
我们将病人 i 的医疗记录记为:
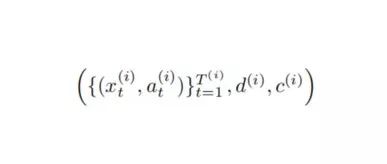
t 代表病人与该健康记录的交互次数。xt(i) 对应于第 t 次交互对应的特征,at 是时间 t 时的年龄,d(i) 代表死亡年龄,或最后进行交互的年龄。c(i) 是删失指标。对于每一个 xt(i),我们定义一个量 yt(i)=d(i)-a(i),代表对应的死亡时间或数据删失时间。
评分法则是评价概率预报质量的方法。对于连续输出的预报是所有可能结果的概率密度函数 f(PDF),以及对应的累积分布函数 F。在现实生活中,我们可以观测到一些实际结果 y。评分法则 S 计算预测分布和实际结果之间的误差,返回损失值 S(F, y)。如果对于所有的可能分布 G,S 都是一个合适评分法则,则有:
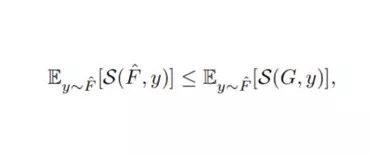
合适评分法则鼓励模型进行真实预测。当采用合适评分法则作为损失函数时,它自然地约束模型输出校准后的概率。
气象学中常用 CRPS 作为预测连续结果的适当评分法则:

CRPS 通常作为回归问题的目标函数,相比于最大似然法能够产生更锐利的预测分布,同时保持数据校准。上式的后两项积分对应于图 2a 中的两个阴影区域。
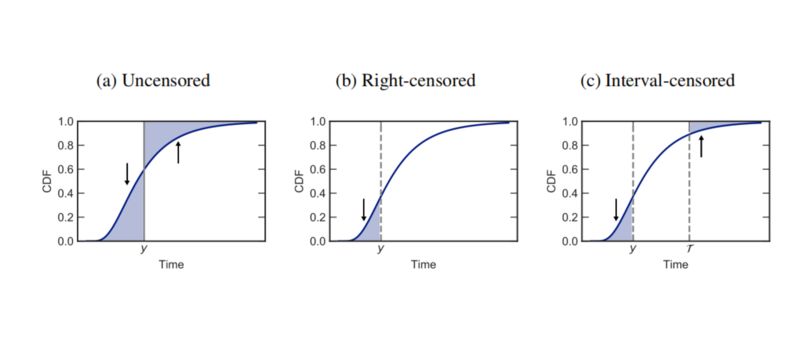
图 2
为了预测事件发生所需时间,我们提出了 Survival-CRPS,用于计算右删失或间隔删失数据的概率:
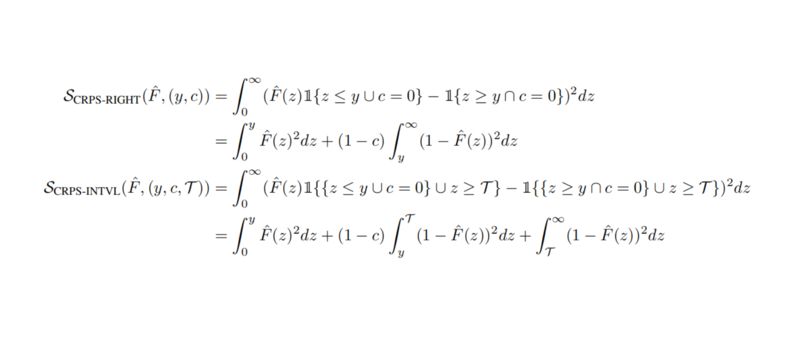
当 c=0 时,上面两个方程都退化成原始的 CRPS。同样的,上面两个式子的积分项也分别对应于图 2b 和图 2c 中的阴影区域。对于删失数据的结果,Survival-CRPS 惩罚出现在删失时间之前的值,对于间隔删失,则删失时间之后的值也会被惩罚。
Survival-CRPS 的两个变体都是适当评分法则。他们可以算是阈值加权 CRPS 的特例,权重函数即为未删失区域的指示值。
校准度评估的是预测事件概率与观测事件频率的匹配程度。它对于预测模型,尤其是临床诊断决策来说是十分重要的。我们采用下面的方法来衡量校准度:我们在预测累积密度的分位点处对比预测累积概率密度和观测的事件频率。右删失的观测值不计算删失点之后的分位点。间隔删失的观测数据与此类似,但是在事件一定会出现的时间点之后的分位点再引入。
在保证校准度的情况下,我们也希望得到锐度较高的预测分布。我们使用变异系数(Coefficient of Variation, CoV)作为锐度的度量指标。CoV 定义为标准差和均值的比值:
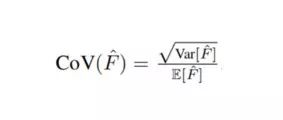
由于锐度仅仅是预报分布的一个函数,因此只有当模型完全校准时,评价锐度才是有意义的。我们提出一个新的衡量标准,可以衡量预报分布质量的聚集程度,对未校准的模型具有鲁棒性。这个想法与计算精确度 - 召回率曲线(Precision-Recall curve)下方的面积类似,只是这里仅考虑一个结果和对应的一个预测分布。
首先考虑未删失的情况,我们用事件发生时间附近的间隔来类比精确度,例如在时间 y 的事件周围,预测精度为 0.9 的间隔则为 [0.9y, y/0.9]。对应于这个精度的区域,我们用预报分布在这个区间段上分配的质量来类比召回率:F(y/0.9)-F(0.9y)。曲线下的面积衡量的是随精度窗口扩展,预测的质量在真实结果附近的聚集速度。
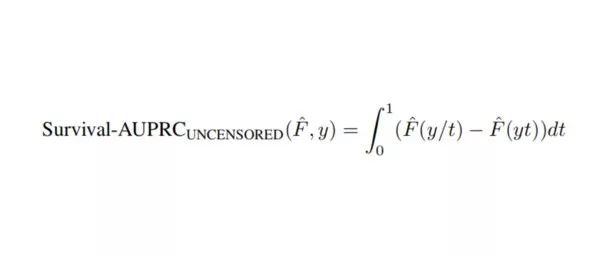
Survival-AUPRC 的最高分为 1,此时预测分布为一个狄拉克函数,在事件发生时间附近聚集。最低分数为 0,此时预测分布无穷大。所有样例的 Survival-AUPRC 分数的平均值为预测的质量提供了一个整体的评估。
上述的度量指标只适用于未删失的情况,在删失数据的情况下,我们使用同样的类比方法,但是对时间间隔进行了调整:

我们通过构建一个多层循环神经网络,将提出的方法应用在死亡预测任务中。网络输入为特征序列(EHR 中的病人信息),来预测概率分布函数 F 的参数。该网络只依赖目前和之前的时间点数据,不依赖未来的数据。每个时间点输出的概率分布构成整体损失:
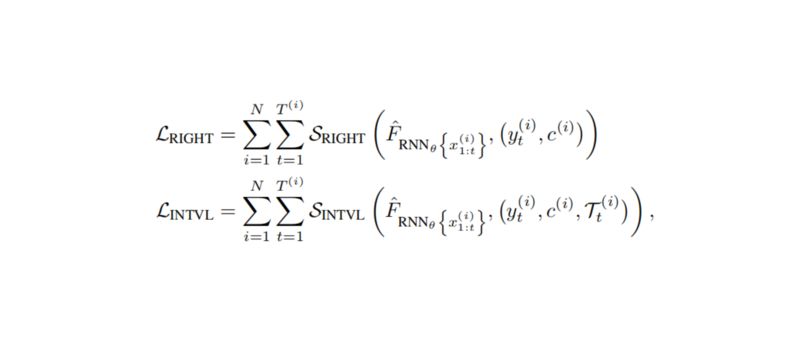
这种序列性的单调递减模型,我们称之为倒计时回归(Countdown Regression)。
我们在死亡预测任务上进行实验,评估四个不同的训练目标:最大似然 S-MLE-RIGHT 和 S-MLE-INTVL,以及基于我们提出的评分法则的损失函数:S-CRPS-RIGHT 和 S-CRPS-INTVL。
我们采用电子医疗档案 EHR(来自 STARR 数据仓储)用于训练和验证。该数据包含超过 300 万名病人的记录(约 2.6% 的病人有死亡日期记录),跨度大概为 27 年。每个病人的输入序列的时间点对应 EHR 给定日期的所有数据。我们使用了诊断码、实验测试顺序码、治疗类型码以及人口统计学数据(年龄和性别)。每个代码都有一个随即初始化的内嵌矢量,作为需要学习的参数。300 万个病人,对应 5100 万的时间点,按比例随机分成 8:1:1,分别作为训练集、验证集、测试集。
我们首先验证模型的校准度(图 3)。变异系数和 Survival-AUPRC 度量指标均显示带有间隔删失的 Survival-CRPS 方法可以得到锐度最高的预测分布(表 1)。
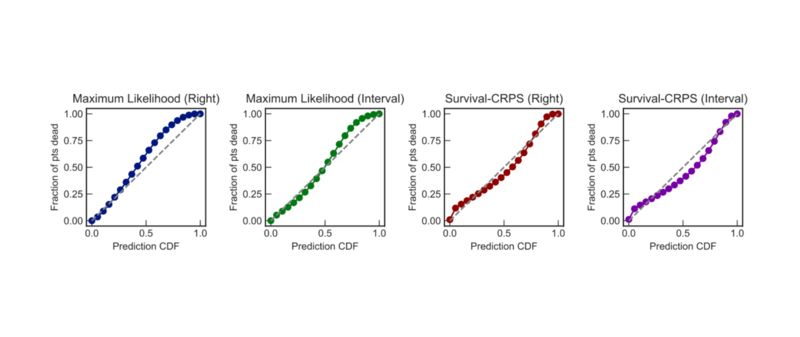
图 3
每个模型的校准度图。我们对比了预测累积密度和观测时间频率,分别在预测累积密度的分位点进行比较。
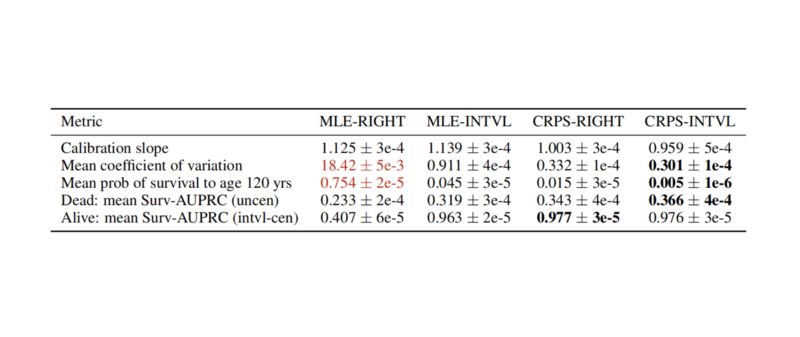
表 1 分别用最大似然和 Survival-CRPS 目标函数训练的右删失和间隔删失模型的锐度和校准度比较。
通过分析预测模型给超过 120 岁之后分配的死亡时间可以看出,用最大似然简单训练的模型会将超过 75% 的质量分配给不合理的时间。我们发现这种行为主要由于未删失数据中低发病率的样例,但这在真实世界的 EHR 数据中广泛存在。删失样例的损失函数可以通过将质量尽可能推向右侧来最小化,也因此支配了少量未删失样例。
通过对死亡时间的整体预测,这个模型也可以应用于对不同时间点进行预测。当预测 6 个月、1 年和 5 年内的死亡概率时,我们的模型可以保持很好的校准度,以及极高的区分度。
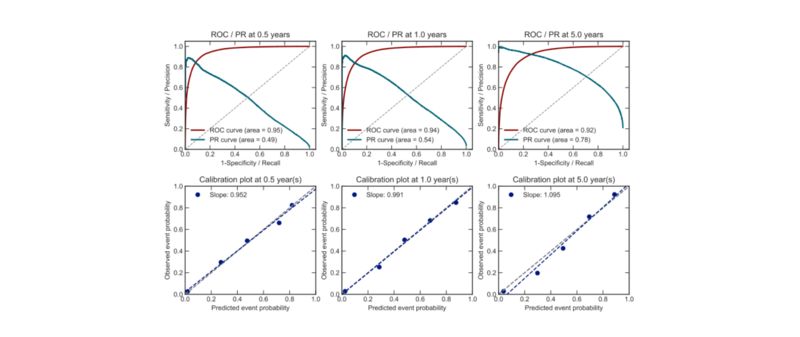
图 4 间隔删失 Survival-CRPS 模型的区分度和校准度曲线。
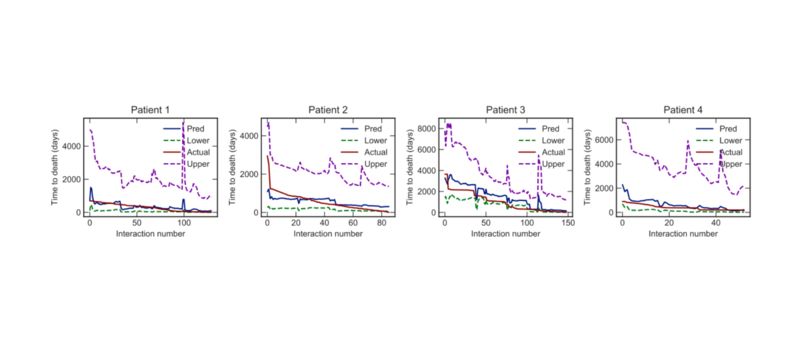
图 5 间隔删失 Survival-CRPS 模型预测单个病人死亡时间的中位数。我们的模型给出了最可靠的预测结果。真实的死亡时间基本位于预测的时间段内。
我们可以通过比最大似然更好的目标函数,以及对预测分布进行全面评价的标准来打造更好的生存预测模型。在这篇论文中,由于受到 CRPS 评分标准的启发,我们提出了 Survival-CRPS 目标函数,可以产生锐度较高的预测分布,同时保持校准度。我们介绍了 Survival-CRPS 评价标准,能够捕捉到预测分布在观测时间附近的聚集情况。通过对数正则参数化方法,我们训练了一个深度循环模型,能够成功进行大型生存预测。通过对事件发生时间的整体分布预测,我们解决了二值分类法不能解决的时间点预测问题,并且可以给出指定时间内的精确预测结果。能够进行精确生存预测的意义是巨大的,尤其对于健康护理领域。我们希望我们的工作可以帮助到那些正在设计或部署这种模型的人。
论文原文链接:
https://arxiv.org/pdf/1806.08324v1.pdf


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!



