【吐血整理】台湾大学李宏毅深度强化学习笔记(49PPT)
新智元推荐
来源:Medium
作者:Ivan Lee
【新智元导读】来自台湾超受欢迎的李宏毅老师深层强化学习49页PPT以及笔记,熬夜整理,值得收藏。本文授权转载自Medium,作者Ivan Lee。

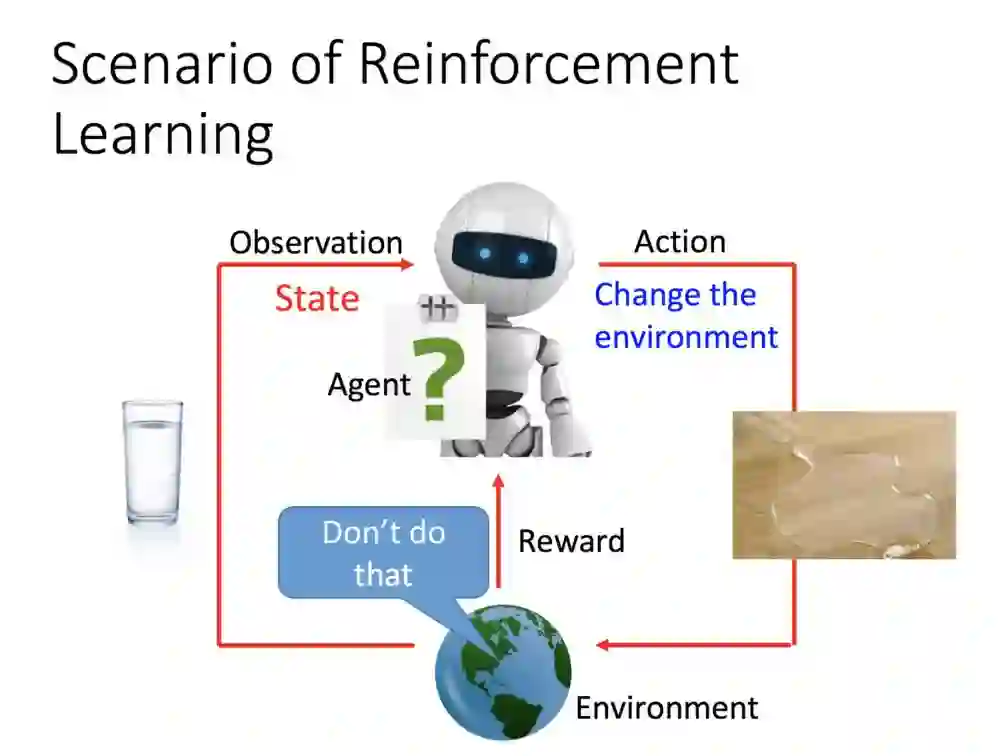
李宏毅老师通过下面的地球跟机器人比喻RL(Reinforcement Learning)过程是怎么回事。
地球是环境(environment),代理(agent)用感测器去接收外接讯息,就像无人车在路上有六种以上装置感知外接讯息。
外边感知到了一杯水,它(agent)感知到讯息接着采取行动,它把水打翻了。因他的改变而外界有所改变,一摊水洒在地上。
接着外界(地球)给她了一个回馈:你刚刚的动作是不好的(Don't do that),所以机器人得到一个负面回馈。
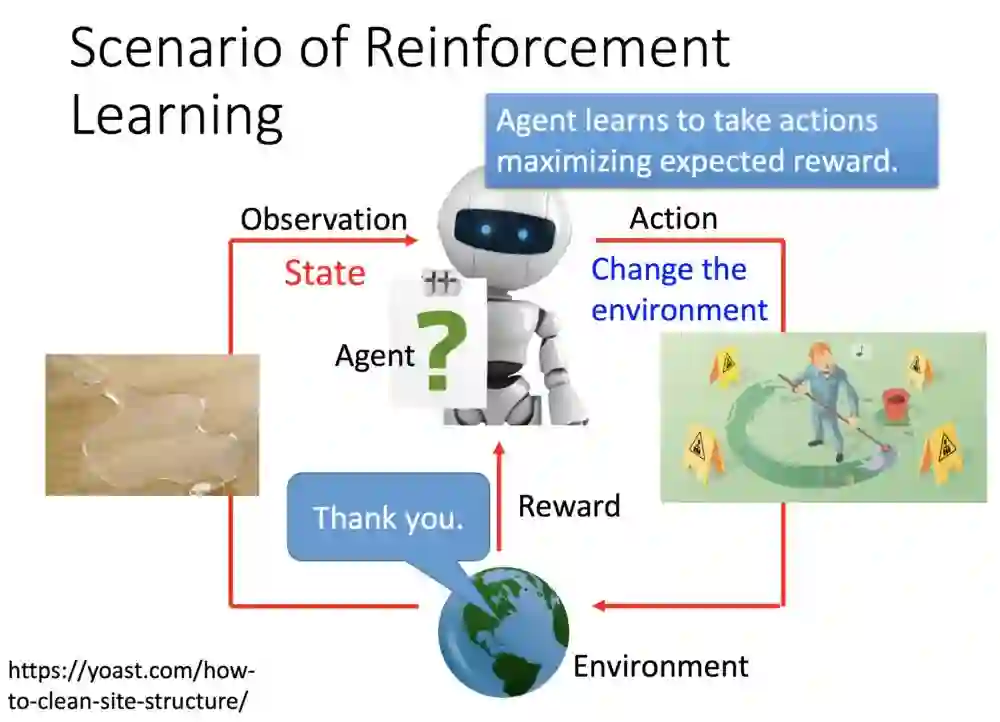
接着,机器人感测到地上有一滩水后,便采取行动——把地上水擦净,改变了外界的状态。
接着地球给了个回馈:干得好兄弟!这是一个正面的奖励,接着这个反馈机器人也接收起来了:我这个动作是好的。
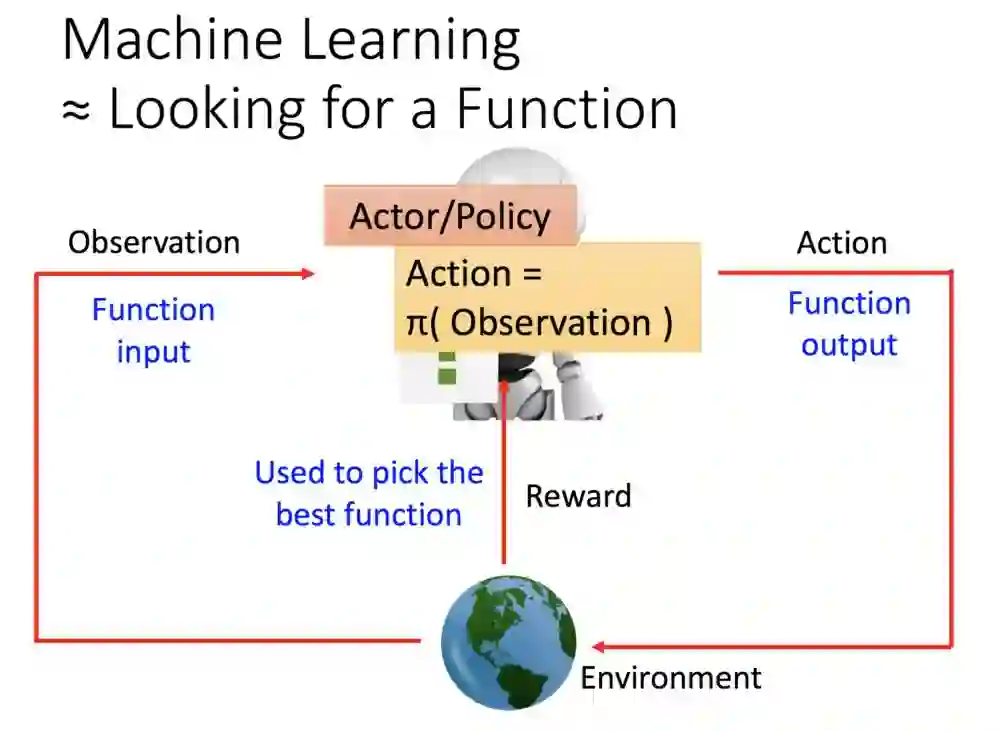
这里比喻机器的学习过程就是找到一个函数,函数的输入是外界(观察),而机器学习得目标就是要把这个函数(奖励)最大化。
这边举例阿法狗的学习过程。首先观测棋局(左),阿法狗下了一手。外部环境接收到了讯息,反馈给阿法狗。
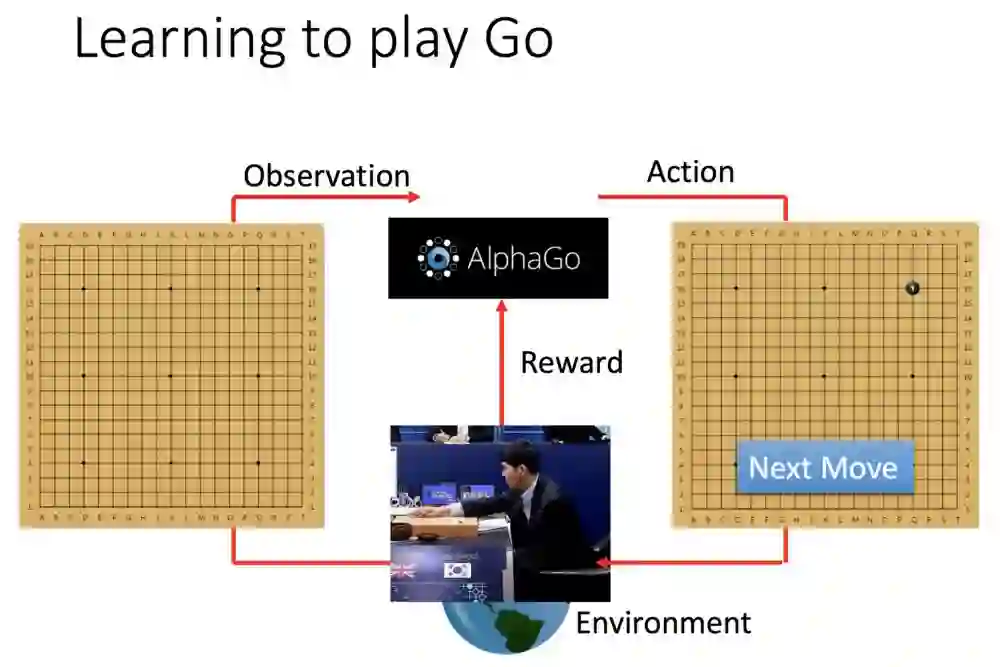
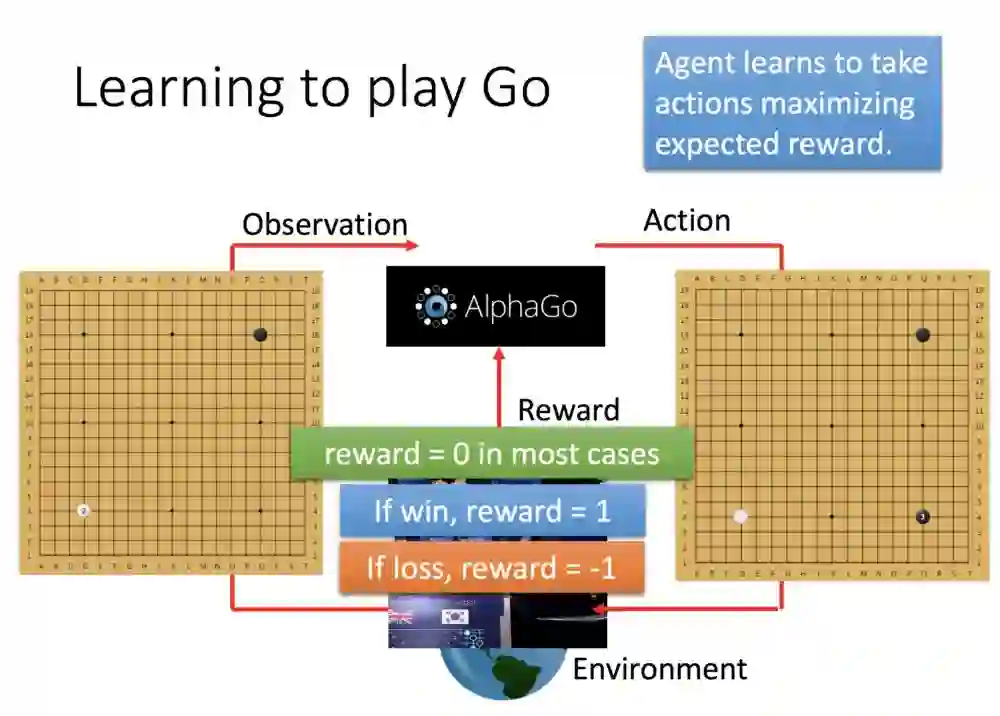
人类下了第一手,阿法狗观测棋盘,然后不断循环刚刚的步骤。整个过程奖励是0,直到棋局结束,才会产生1或0的奖励。
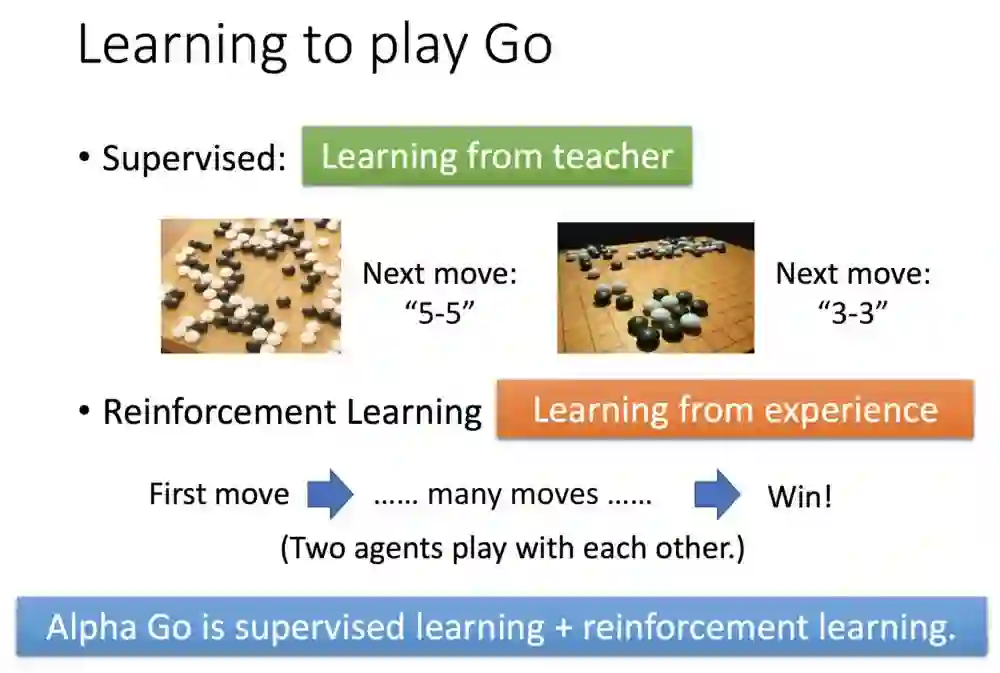
假设是监督式方法让机器去学习,就会变成你教授5-5后,第二手教机器下3-3,一步一步的带下法。
但强化学习不一样,是到棋局结束才有奖励。
阿法狗的算法则是,监督式先学习许多的棋谱,然后才用强化学习去探索更多棋谱跟走法。
我们用语音机器人举例。一开始的监督则是从你一句我一句训练,然后根据动作奖励值,机器的目标就是要最大化期望值。
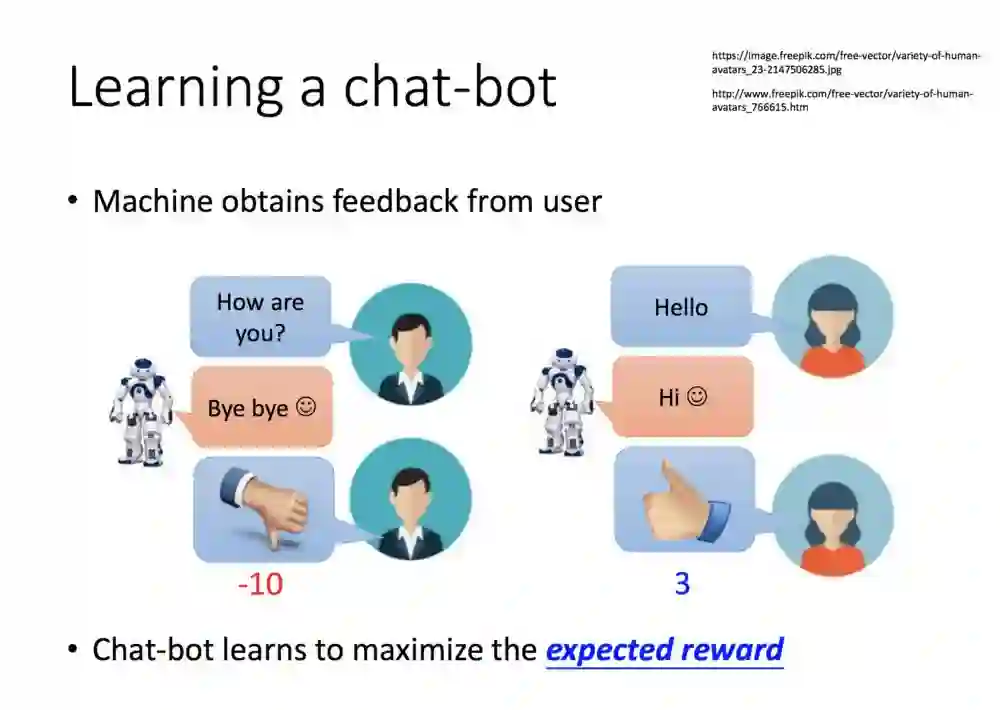
如果像阿法狗一样,让两个机器人训练呢?那机器人就会不断的对话出很多的句子。
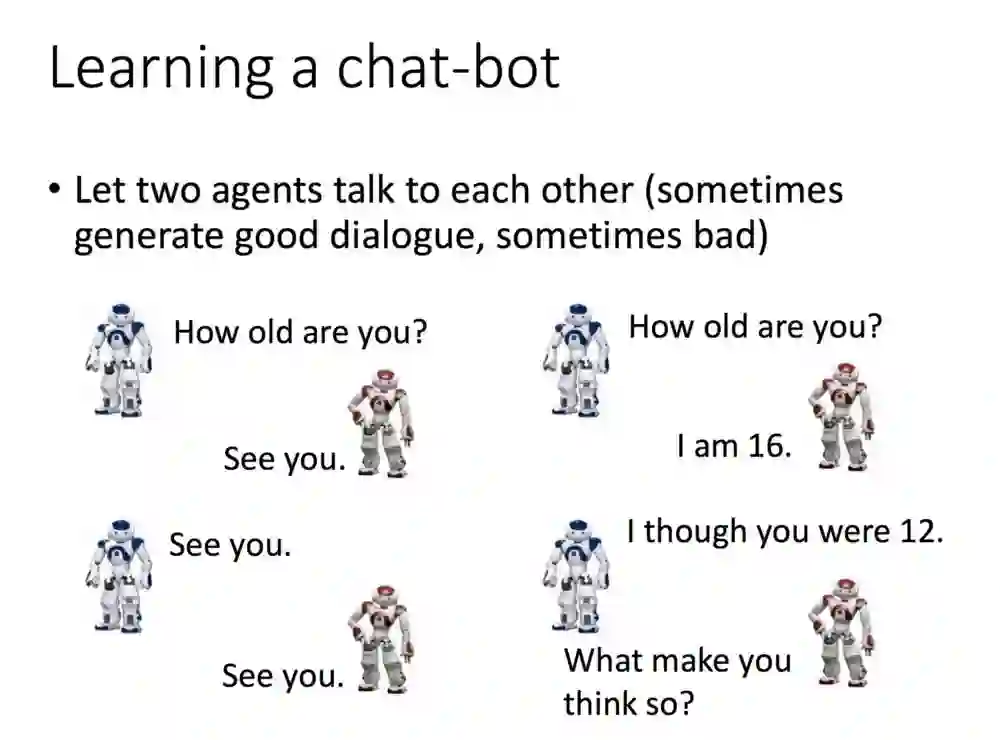
产生的句子很多,也不可能一个一个去看完,那就要采用监督式学习了。你可以制定一个规则,假如你希望一个机器人学习骂脏话,那就让输入的句子奖励都能得到正值,反之如果不希望,则加入规则,骂脏话的时候变的反馈负分。
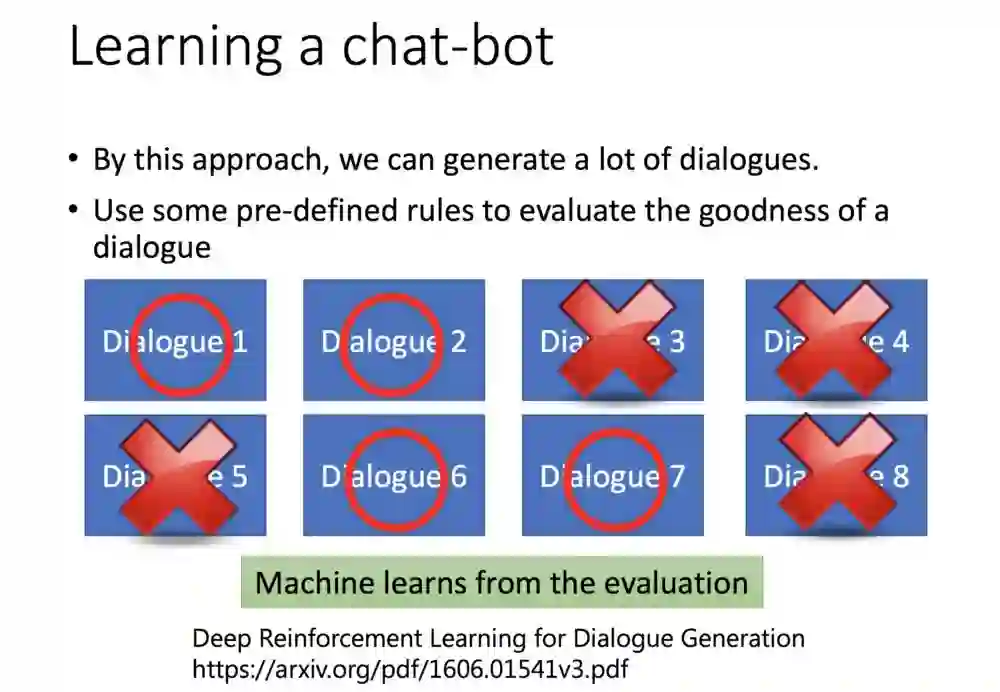
如果把语音机器人用监督和强化学习来比喻,非监督方式就是一句一句地教,强化学习就是让机器自己去对话,直到对方挂电话结束语音聊天。
以下是提供的两个RL环境,有空可以上去玩玩试试。接下来的内容大部分会以机器人玩游戏为主题做延伸。

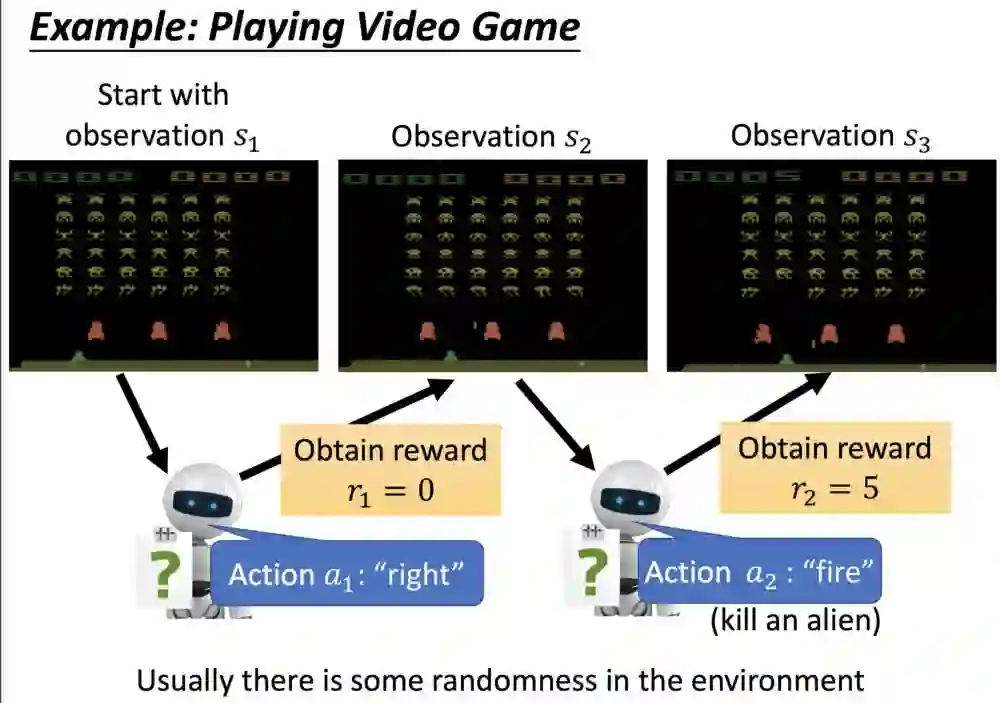
下面是一个用RL玩游戏的例子,左上方是已获得分数,中间是还没打完的怪,下方则是你可操作的动作,包括向左移动、向右移动以及开火。
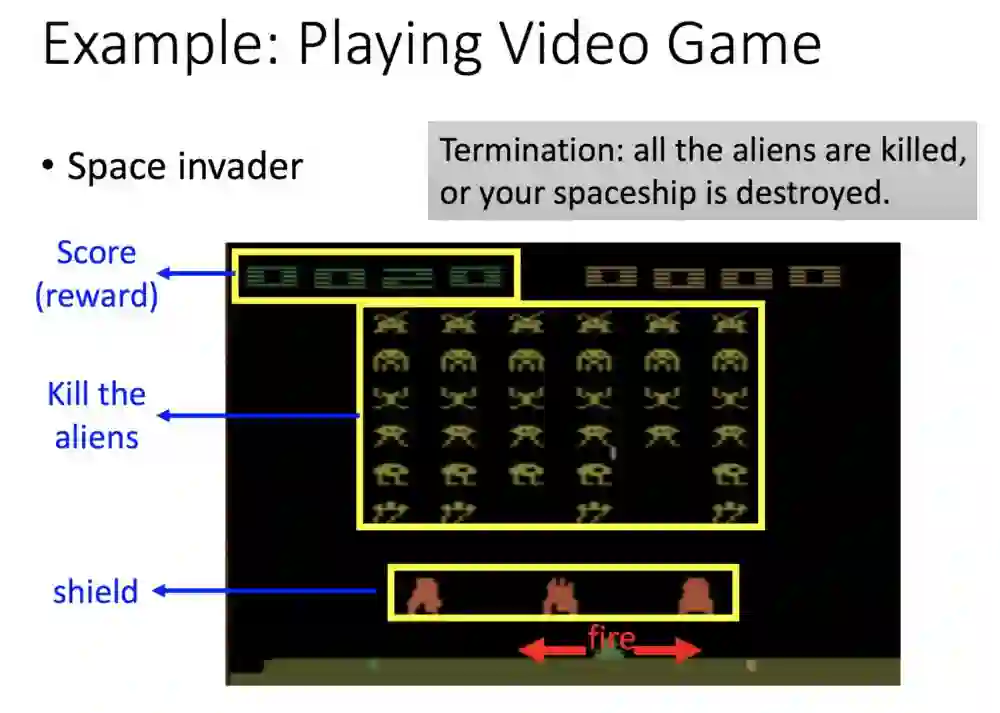
整个流程你可以这样了解如何互通。
首先机器看到最左边的画面(state s1),接着采取行动(action a1)向右走一步,得到回馈reward(r1 = 0),然后再接收状态资讯(state s2),接着再选择开火(action a2),然后环境给予他的回馈奖励(r2 = 5),s1→a1→r1→s2→a2→r2。
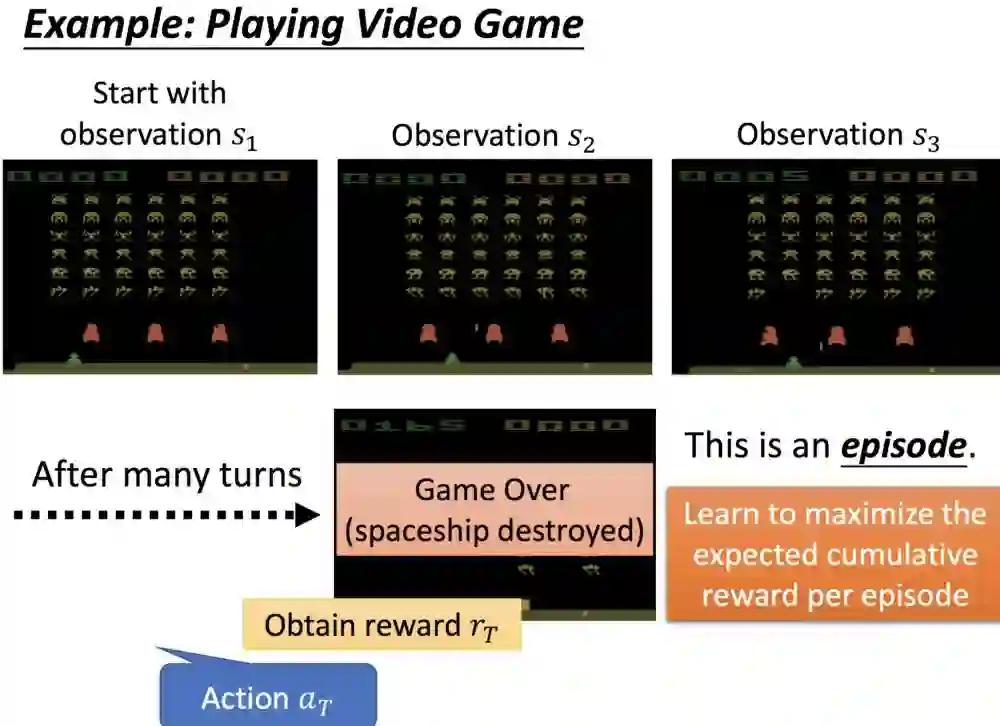
直到游戏结束,整个过程会得一个累积的奖励,游戏会以整个情节的奖励为目标,并按照目标最大化原则调整行为。
目前强化学习有两个需要关注的特性。
首先是关于学习,有着奖励延迟的特性,你的机器人或许会知道开火跟得分有关系,但不能直接了解得分跟往右移动有什么关系,这样机器最后只会不断地开火。
再举个围棋的例子,在与环境对弈的过程,并不是每步都有明显的回馈说这步下得很好,有时早期的牺牲些区块,诱敌等战术都能让你在后面获得更好的期望利益,学习的对象是一连串的行为(轨迹),机器才能了解,有些没有及时奖励值也是很重要,目标是最大化整个过程的奖励。
另一个特性是,机器不是一开始便拥有标注好的资料,机器要跟环境持续做互动,改变环境获得反馈,玩许多次才会更新算法,过程整个这样持续。

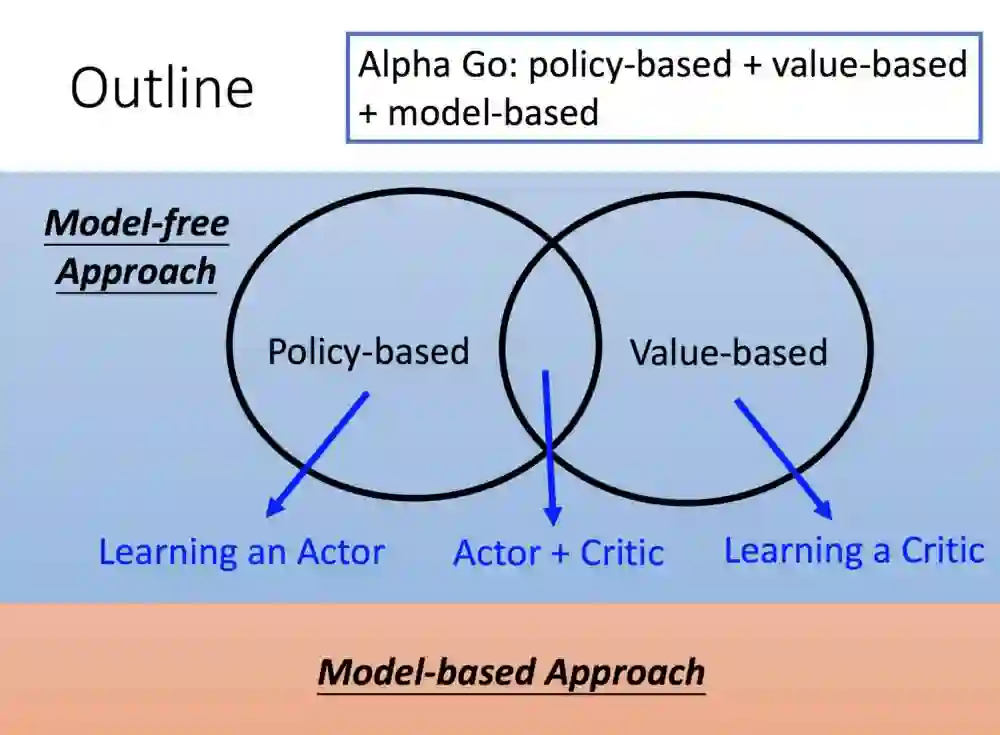
强化学习模型主要有两个,第一个是模型的基础上。
以围棋举例:你下一步后,机器便可以预想后面所有可能的棋步,然后推出胜率最大的下一步,但这是基于对规则与环境的充分理解,才有可能做到。
另外一个则是无模型,你并不是对环境很有着充分理解,基于这个产生两个方向,基于策略的和基于价值的,以及混杂的Actor+Critic。阿法狗可以参考,它是兼这三个类型使用。
接下来就开始介绍基于政策途径,如何得到一个好的Actor。

这边分三个部分介绍,RL导入NN(Neural Network),如何定义好的函式及如何找出最好的。

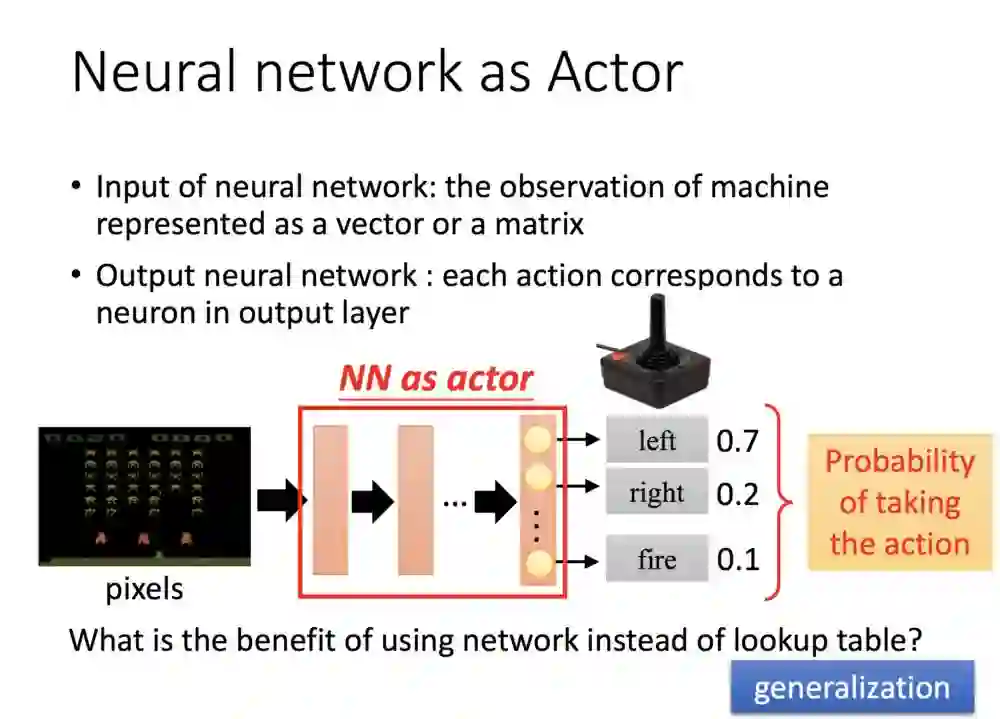
左下角可以看到整个游戏画面,进入NN会输出三个维度的结果,分别是三个动作的值。
其实过往RL就有些固定算法,例如Q-表,现在导入NN的原因是,原本的RL输入的内容必须比较固化,如果针对没看过的例子性能会较差,但NN优点就在于泛化能力好,就算画面没看到但仍会找到个看到且相似的画面,具有泛化特性。
有了使用NN设计Actor的概念,接下来我们要来定义什么是好的函式。
这是过去我们知道的分类问题:手写数字辨识经过神经网路,给定一个值,对照标签去评估损失。
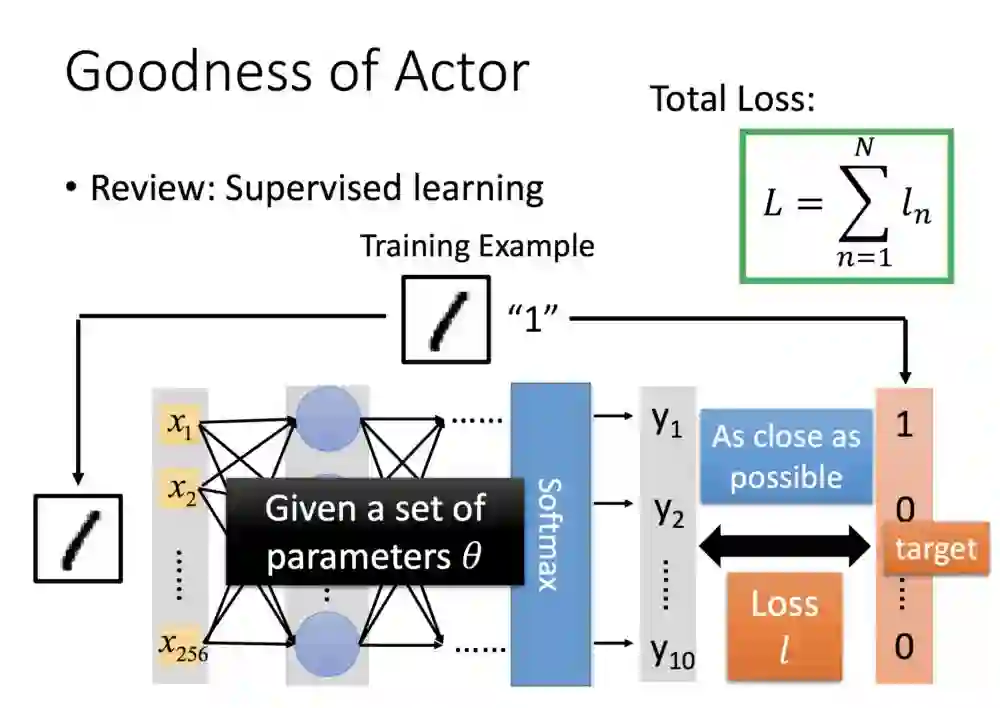
函式π(Actor)会有一组参数θ,接着会先让Actor玩第一回游戏,整个过程(轨迹)结束会得到一个总奖励R.
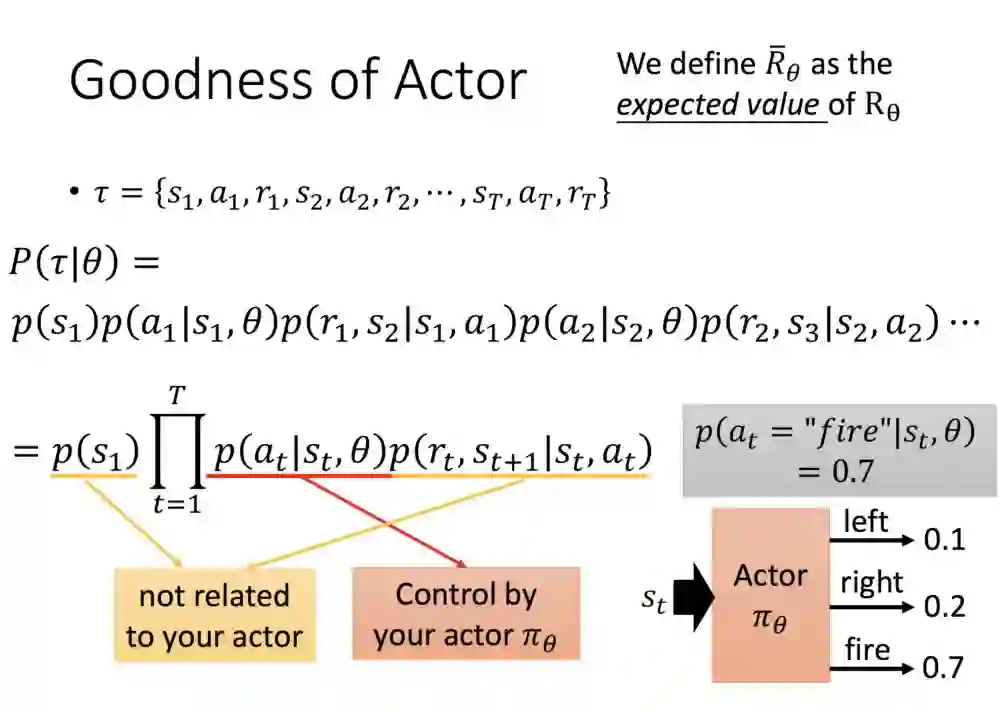
对于相同的Actor来说,每次环境回馈的R并不一定相同,以及RL算法某些时刻会采取随机的方式选择策略,这是为了满足探索新的可能的需求。因为这些原因,我们会求𝓡(注,应为右下角有下缀θ,暂时以𝓡代替)。求每次的机率与奖励,得期望值。

我们知道想要的值是什么后,就先来求机率的公式。
首先定义τ,整个轨迹展开,求机率P(τ|θ),展开来后从第一项开始:环境初始状态P(S1),在状态(S1)状态下,基于θ所以采取的行动(a1)中,接着基于a1,state1(S1)过渡到状态state(S2),中间所产生的奖励(R1),接着持续下去...
切到下方公式,除了θ外可拿掉,因为我们所关注的仅有参数。右下角是对于求出公式的理解state1进入NN,a =文件的机率是0.7,另外则是对= 0.2, left = 0.1的机率。
现在公式可表达每次的奖励值与机率,但延伸出另外一个问题:我们不太可能穷举所有的τ,找出所有可能性。
所以这边的替代方法是,让演员玩N次游戏,加起来后除N,作为奖励的期望值。

接着我们要想方法找出最好的函数。
怎么定义出我们想要找的函数呢?只要θ能使得奖励最大化,便是我们想要的目标。这个一样需要求梯度,右下是根据参数,我们要修改的θ,除了权重还包含偏差,右下角经过微分的向量,便是我们要更新的梯度。

这里如何去求梯度呢?
我们现在的目标是𝛻𝓡,公式就是原本的奖励乘机率,但机率前面加sum,这样没法直接求值,这里先乘一个τ的机率以及除一个τ的机率。分子分母的部分带微分,然后左边的部分从sum所有轨迹替换成样本N次,蓝线部分就是τ的n次方的机率求log与𝛻。

τ的机率求log𝛻,怎么解?这边一样从轨迹展开,每一项带机率,然后求值。我们求有关参数的项就好,其他去掉,就可找出值。

这就是整个参数梯度更新的方法。
下面的式子都可以与前面求得的带入。可以从物理方面去理解,如果你的回馈是正的,便可以改变参数,让其对这个state采取的行动机率提高,负值的话则反之。
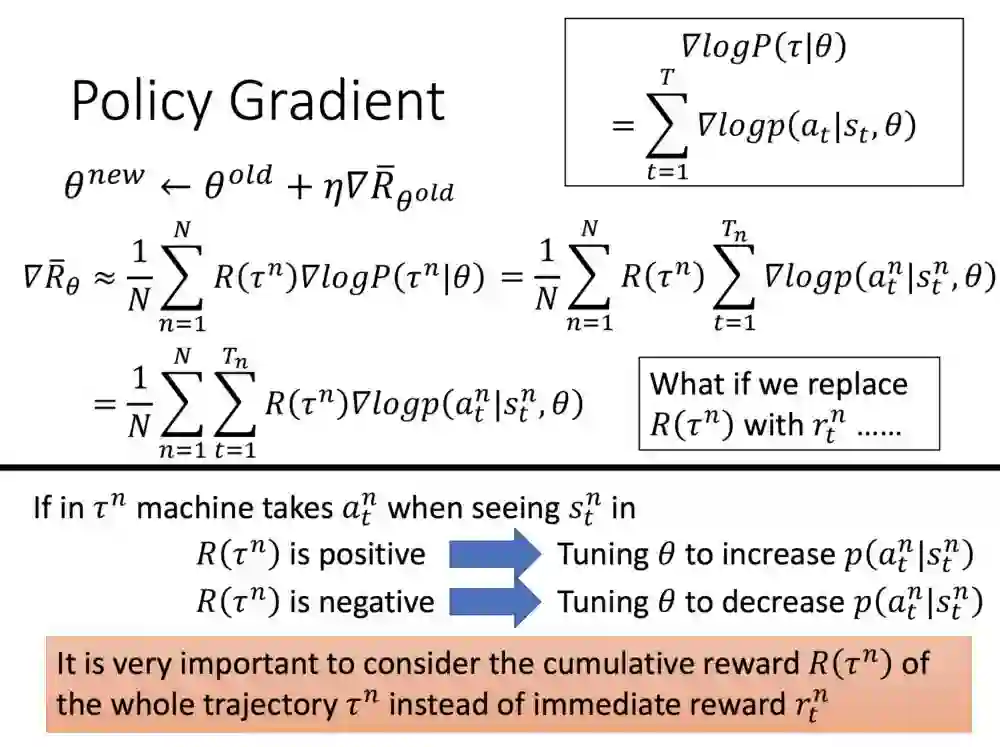
理解完公式,就是整个循环了。不过RL都是玩好几次游戏,再一次回头列出参数,比起其他AI应用,强化学习过程挺花时间。
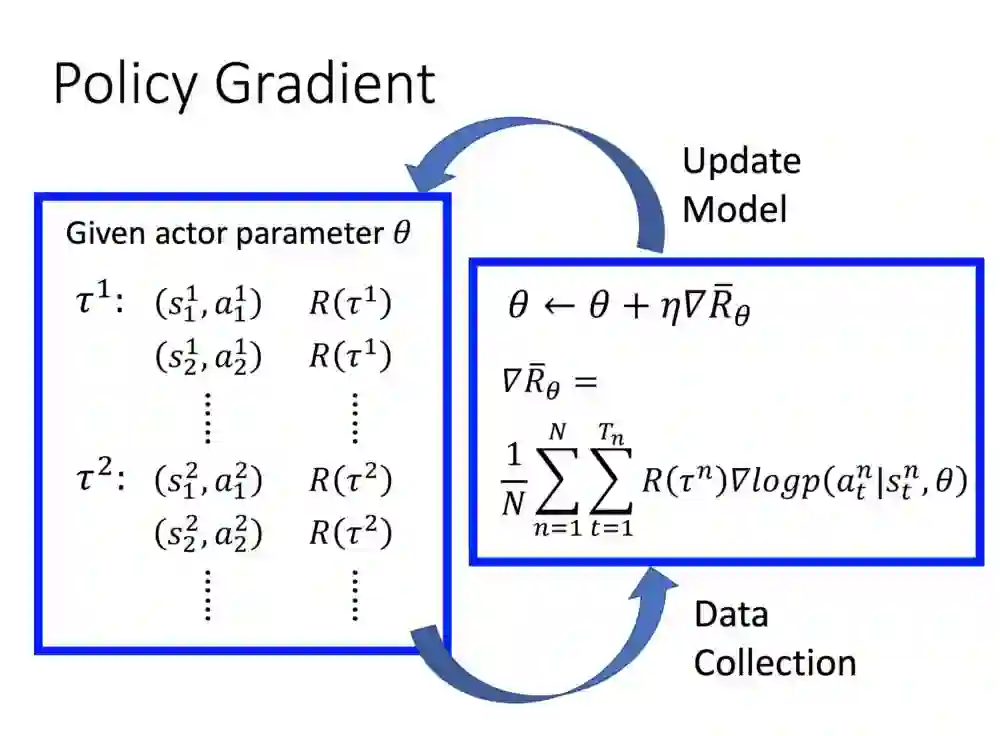
我们可以换个角度,用平常看到的分类模型来思考。
假设左边是游戏画面,输入到了神经网路中,输出了分别三个维度的动作,我们希望他这个画面产生的动作是往左边,值便给1。
过去的分类我们会用cross entropy计算,希望它最小化,这里的话则是希望这个机率最大化,针对状态采取的动作,便可以对参数做梯度修正。
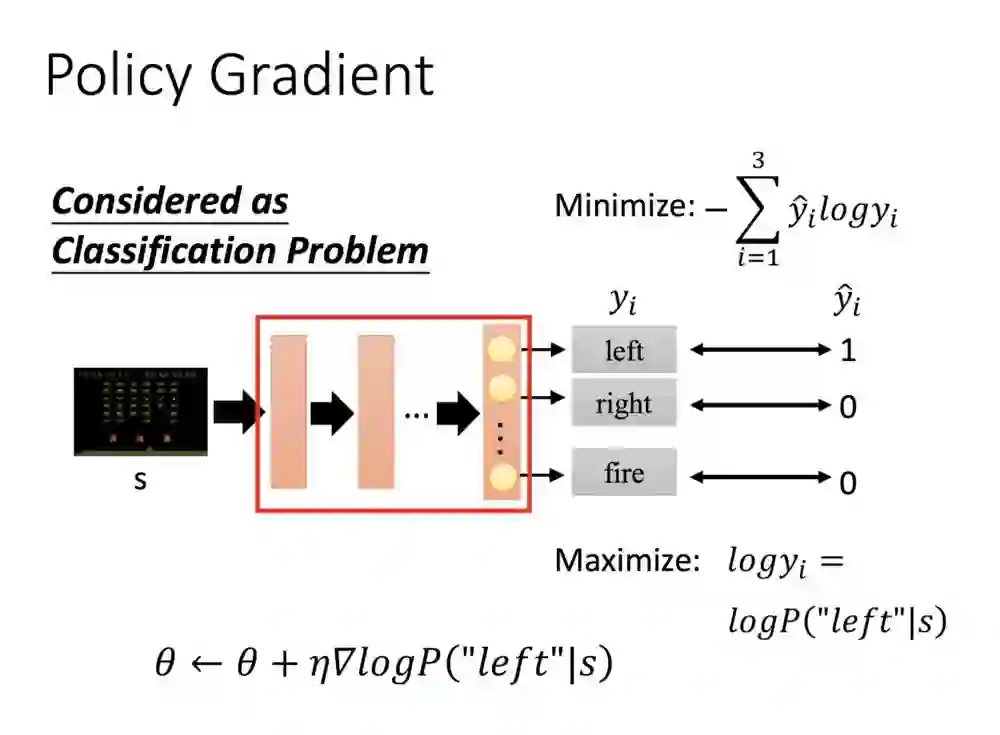
其实这个公式把奖励拿掉,会发现跟分类模型差不多,状态1进入NN输出三维的资讯,左边的值为1,状态2进入NN,也是输出三维的资讯,值为1。
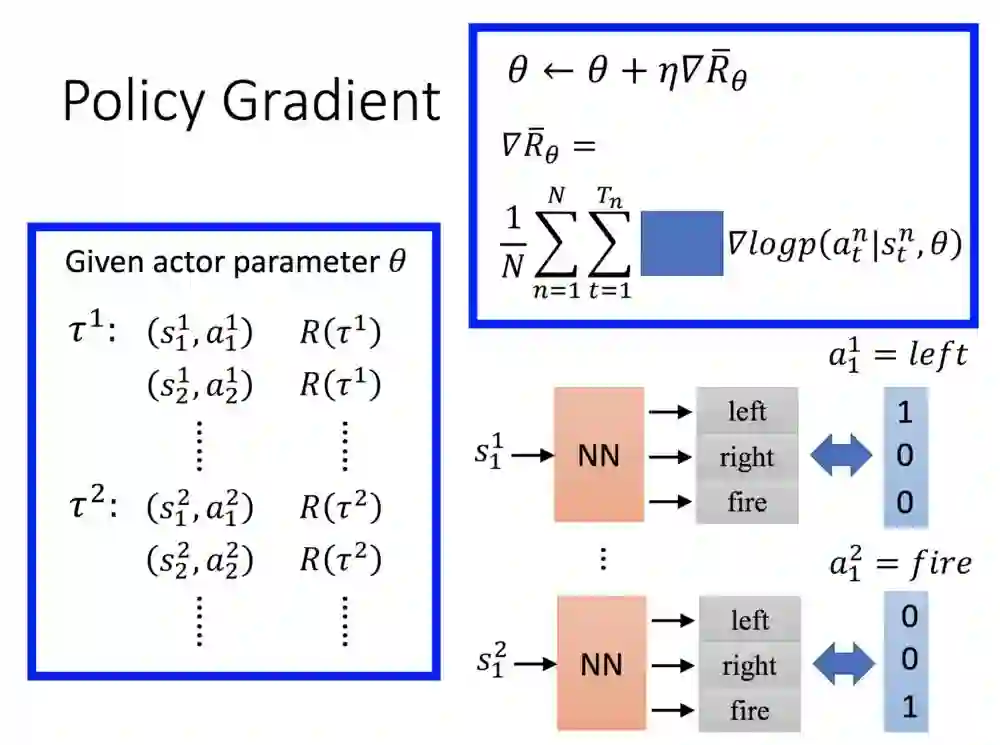
有无奖励的差别在哪里?
如果把奖励当作常数项,它实际上就是针对这个状态动作乘一个值,例如τ的奖励为2,则s1至a1就会产生两次,state2的奖励为1,则只会乘1。
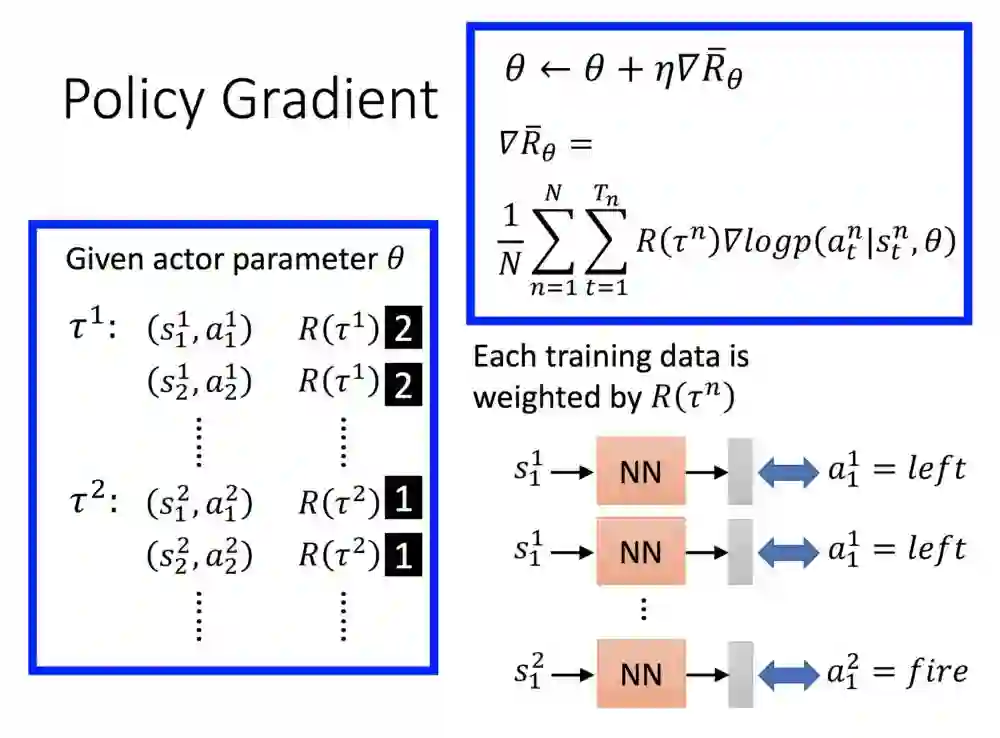
这边说明一个要注意的地方。理想上,A,B,C三个动作皆产生奖励然后修正。
你看到理想的地方,虽然幅度不一样,但其实都有调升,但因机率值关系,三者会再加起来当作分母,加起来总合一定会是1。
现在延伸的问题是,如果B,C有更新,但一个没有呢?
一个值会下降,因为他们最终会除总和的关系。那这应对的方法就是减去一个b值,这样奖励出来如果是正的,减去b值则有可能会变成正值,也可能是负值。
接下来开始介绍基于价值,怎么去训练一个Critic。

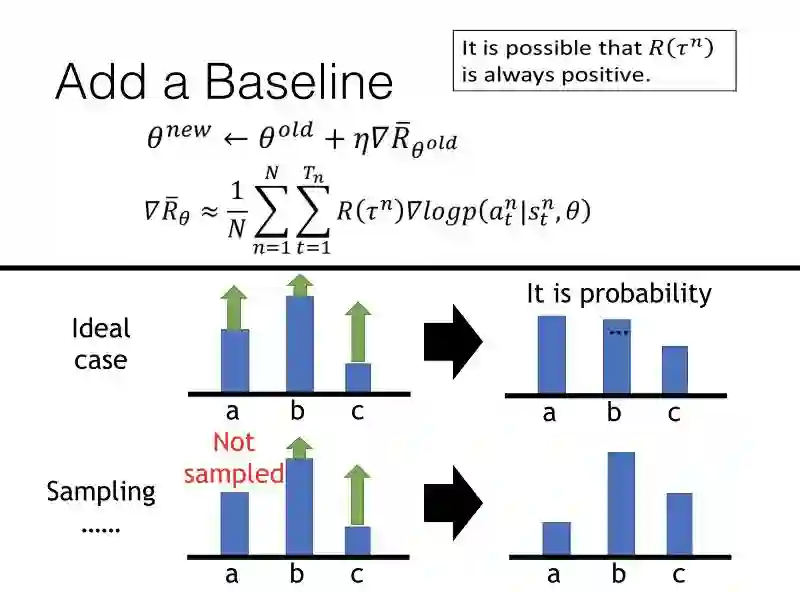
Critic是什么呢?Critic并不会跟你的训练过程有直接关系,它要做的是评估一个Actor的好坏,好的Actor会由Critic挑出,Q-学习就是这样的方法。

评论的价值函数V是怎么评估一个值的呢?
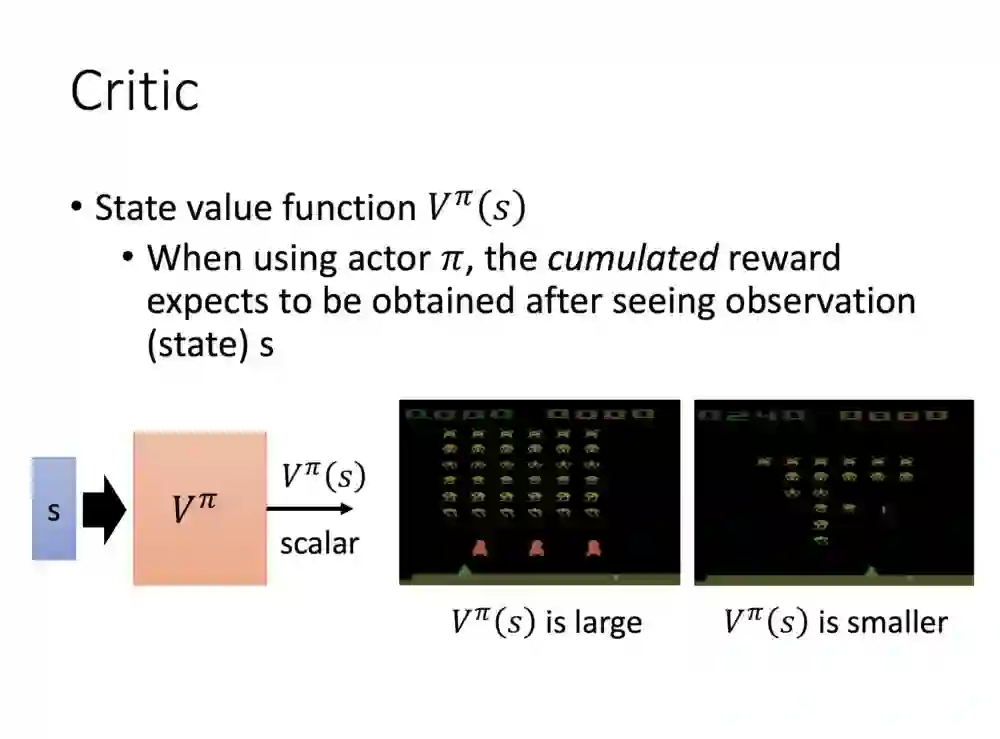
V评估的方法是输入进你的前状态,然后给出后面会累积奖励的值。可以看下图理解,如果是游戏还没开始多久,画面上可得分的目标还挺多,V产出的值便会很大。如果目标已经被击落的差不多了V值便会比较小。但这前提是你的Actor够强,如果Actor在前面阶段便被射中,当然V值也会较小。
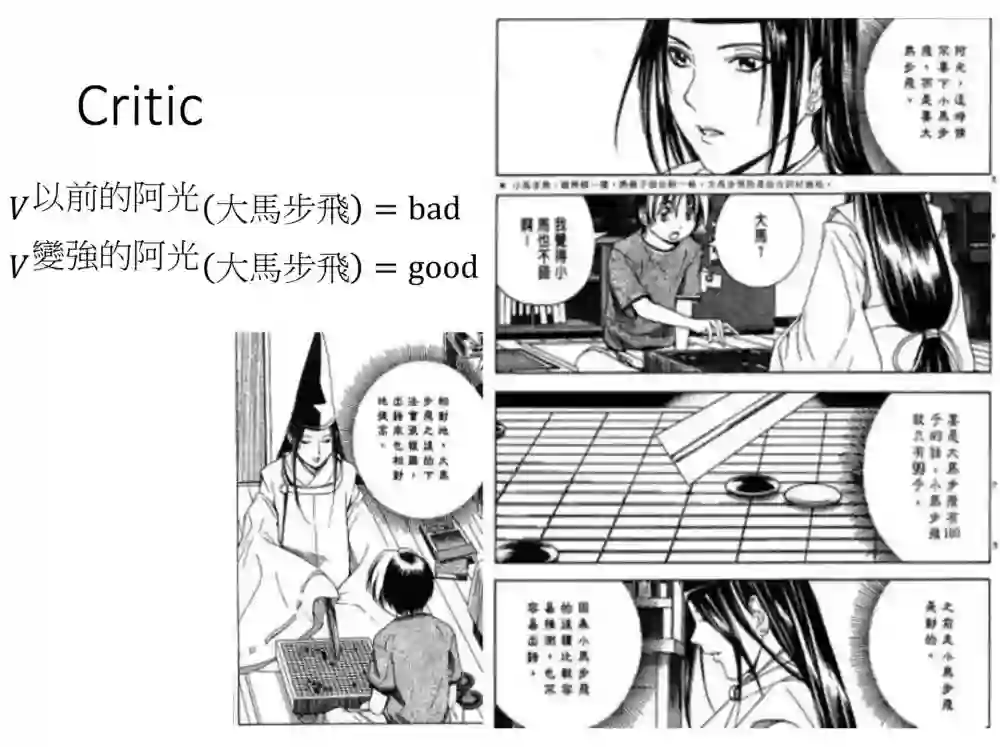
用棋灵王的故事举个例子。佐为(Critic)告诉阿光(Actor),这个大马步飞的棋步不好,理由是风险比较高。
但过了段时间阿光变强了,佐为反而告诉他是好的,因为现在阿光能力变好了,这棋步虽较有风险,但能带来好的获益。
关于V的评估有两种方法,第一种是Monte-Carlo,MC就是对于你输入的状态,会把未来积累的奖励输出来。
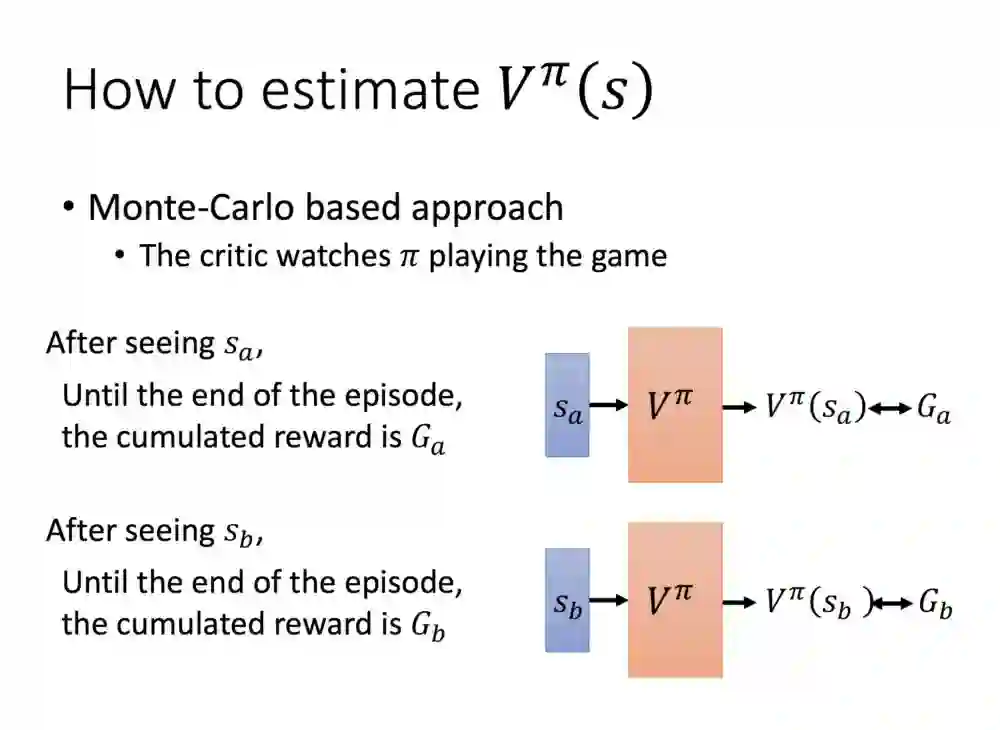
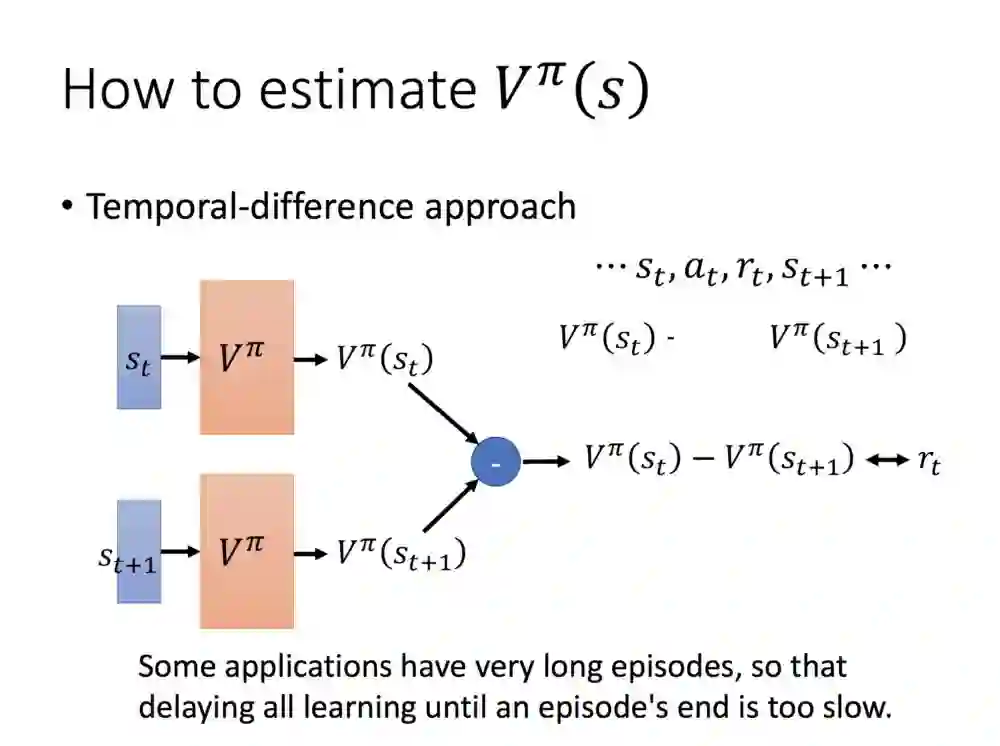
这里是第二个方法,Temporal-difference.
TD的做法是输入两个状态,接着从这两个状态中间求出reward。TD的场景比较偏重于,如果这个训练是较长比较少停止的,例如训练机器人走路,终局的奖励比较取得,便用这种取得两边输出的方法求奖励。
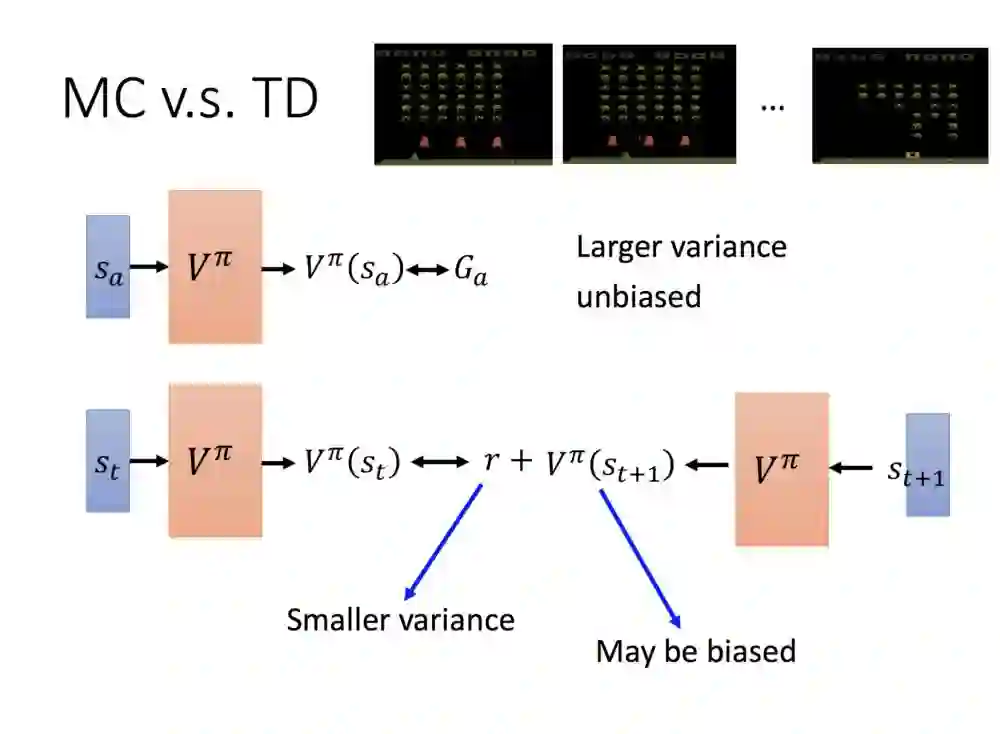
MC跟TD的差别在于,MC的方法因为是累积的奖励,奖励本身因跟环境互动,与自身随机策略因素关系,较有不确定性,间接有着高方差。但相对的会有无偏的特性。
TD的方法因为直接求出𝓡值,得到的方差会较小,但因为TD的V较为不确定的关系,值有可能是有偏也可能是无偏的。
比较两者。先忽略动作,假设第一次的τ是状态a,奖励= 0,接着状态b,奖励= 0,结束。
另外有七次的τ,都是状态b ,六次的奖励= 1,一次的奖励= 0。
这里评估V(状态b)可以很快地得出6/8 = 3/4的值,但V(状态a)可以得出两个值,这就基于看是哪种评估方法。
如果是MC的话,V(状态a)最直接看出来就可求得为0.但如果是TD的话,可以看到下面公式V(状态b)+奖励= V(状态a),V(状态b )= 3/4,奖励是0,那个V(状态a)不就也等于3/4了吗?其实这两个都是对的,仅是方式不一样而已,再来也有可能样本不够充足,或许V(状态a)是等于3/4。
这边要注意的是,或许看到第一个τ会怀疑V(状态b)是因为前面有状态a的关系,但TD的特性是前后不会受到影响的。

再来介绍另一个Critic,这就是有众所皆知的Q函数。跟前面两者的差别是,在输入的部分会加一个动作去计算值,右下角也是一样,只是在输出改成三维的资讯去求值,左右道理其实一样。
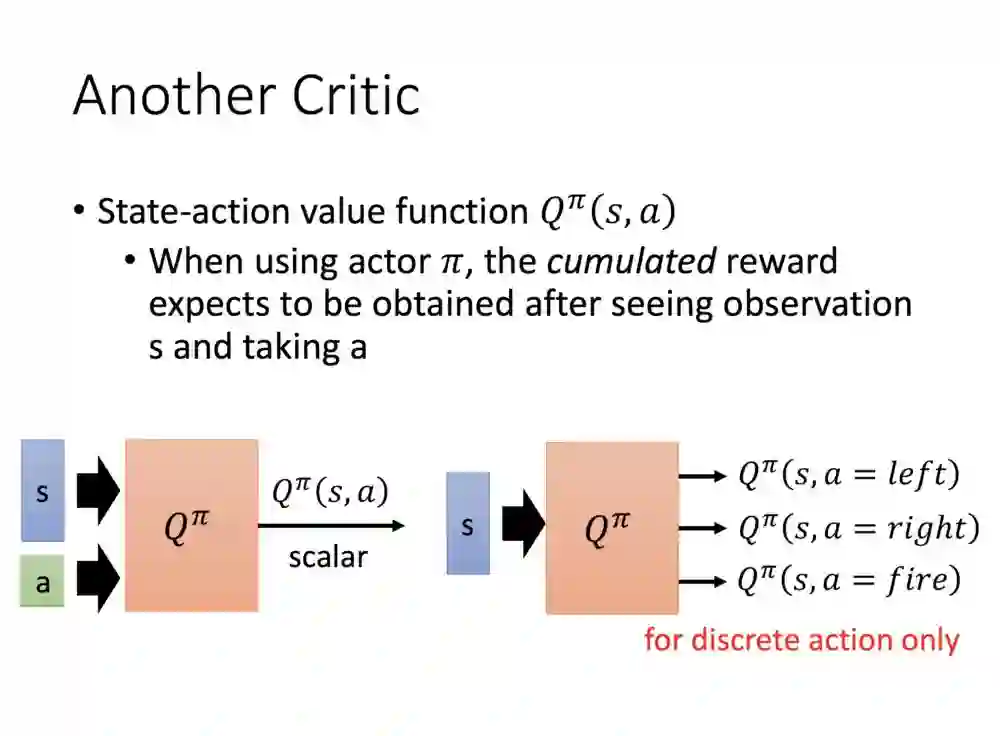
这边Actor指π。首先让π玩N次游戏,接着由TD或MC的方式求Q函数,然后在找从里面找一个好的π',更新原本的π。
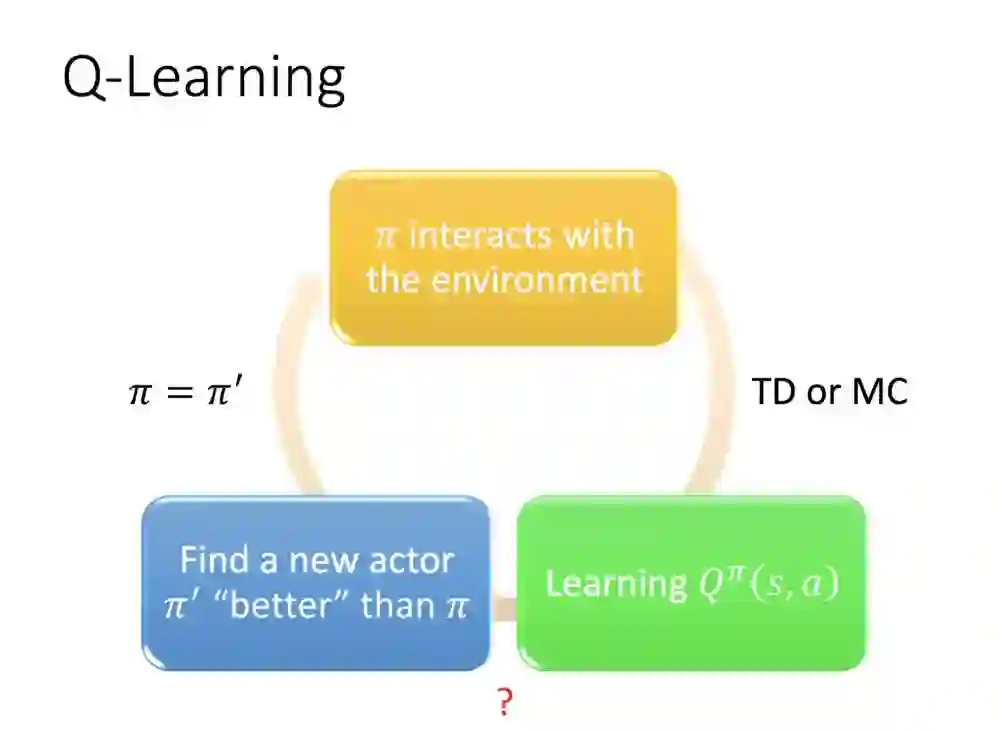
首先我们要定义,什么是更好的π?包括所有的状态,只要你V大于等于原本的,就是更好的演员。
根据π求得Q函数,输入一个S,穷举所有的动作,找寻使之最大值的动作求得π '。实际上π' 就是由原本的π而来,没有额外的参数。
需要注意的是,更新π'如果是连续不断的动作,会让Q函数在计算上非常消耗时间,所以Q会比较适合在可穷举action的案例上。

最后要介绍的是Actor和Critic的结合。

跟上一个部分相比,找寻π'的会有Q 函数(Q function)跟V函数(V function)功能,π'部分不再是依靠π产生Q function穷举动作找出来的,而是会有个实质的数去最大化求值,因此便可以对应可连续动作做应用。
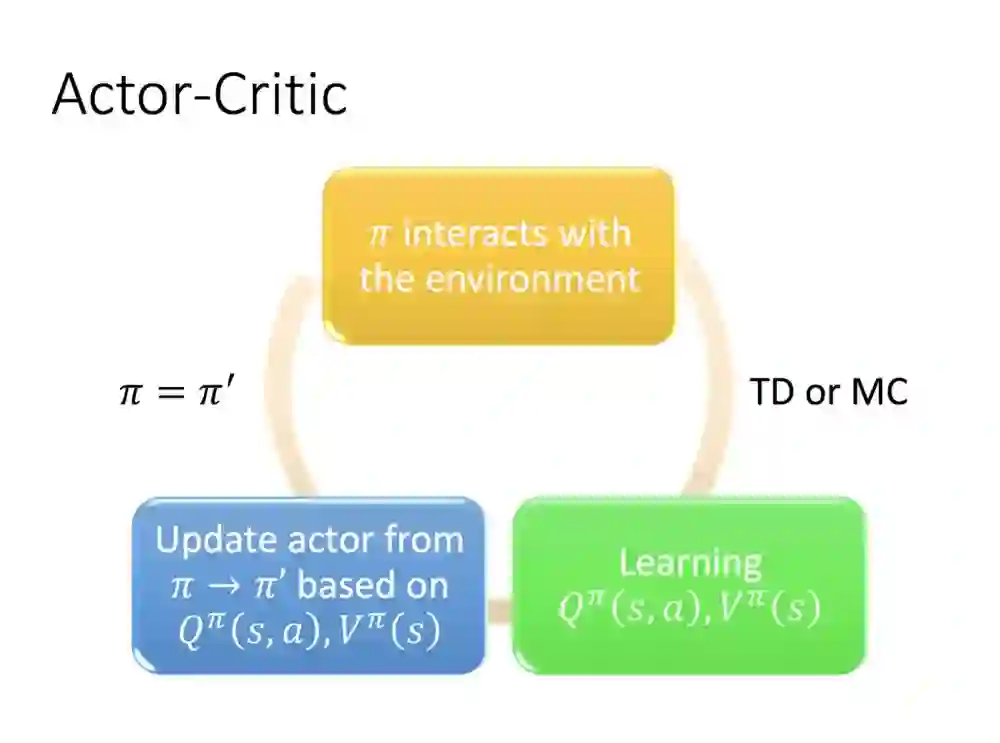
(这里没有李宏毅老师的讲解,作者猜测是π跟V function可以共享,把输出的值最大化。)
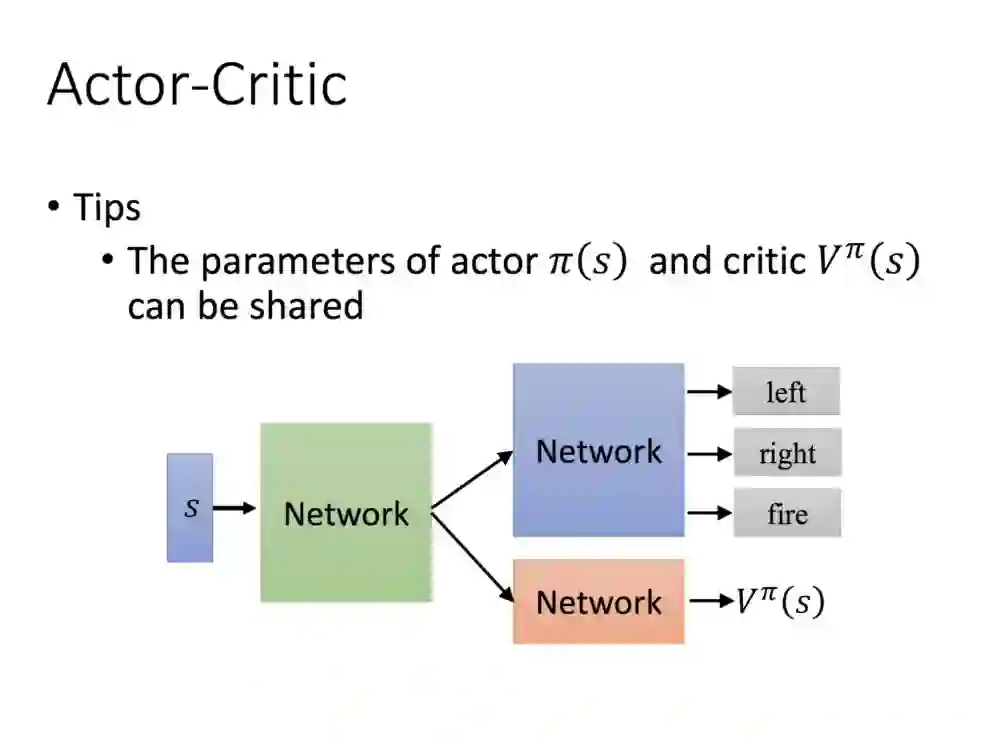
(这边老师也没说明,不过给了有关A3C部分的链接,有兴趣的朋友可以看看)
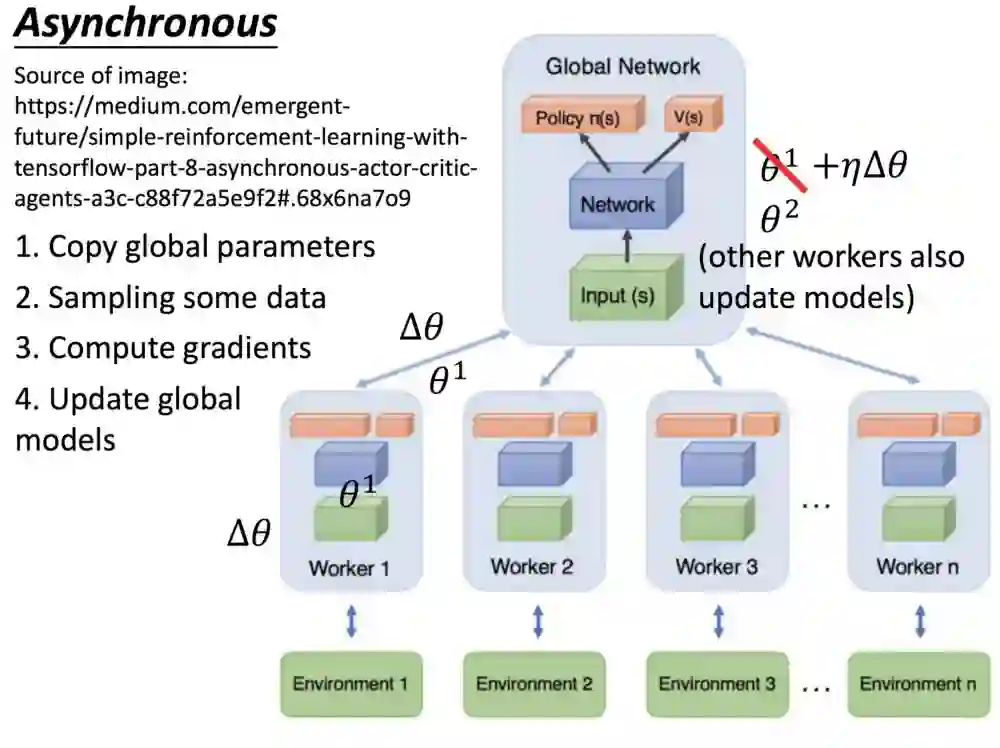
A3C演示:
李宏毅老师PPT网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/RL%20(v4).pdf
本文经授权转载自Medium,感谢作者Ivan Lee授权。点击可阅读原文:
https://medium.com/@ivanlee_10237/%E6%9D%8E%E5%AE%8F%E6%AF%85%E8%80%81%E5%B8%AB-deep-reinforcement-learning-2017-spring-%E7%AD%86%E8%A8%98-3784ddb23e0
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。






