一文详尽系列之模型评估指标
准确率、精确率、召回率、F1值
-
准确率(Accuracy):正确分类的样本个数占总样本个数, -
精确率(Precision):预测正确的正例数据占预测为正例数据的比例, -
召回率(Recall):预测为正确的正例数据占实际为正例数据的比例, -
F1 值(F1 score):
| 实际正类 | 实际负类 | |
|---|---|---|
|
|
|
|
|
|
|
|
P-R、ROC、AUC
-
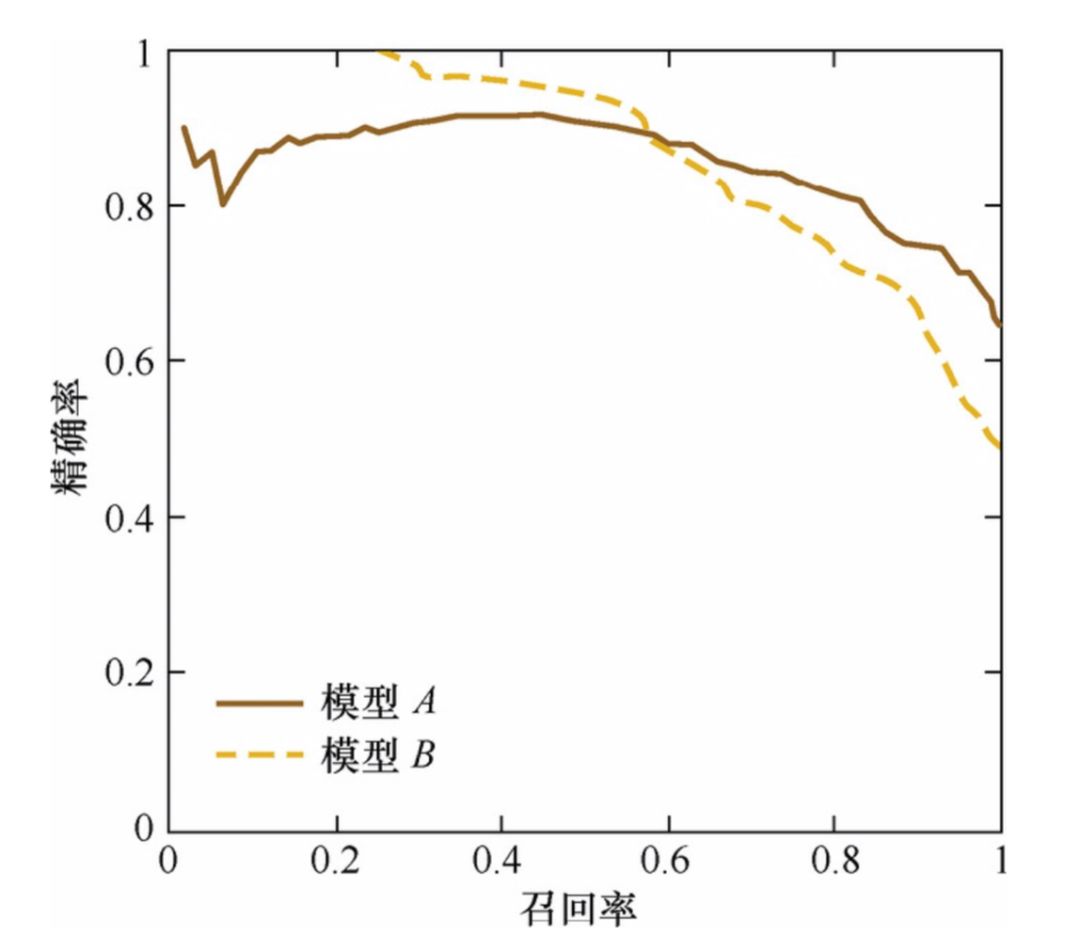
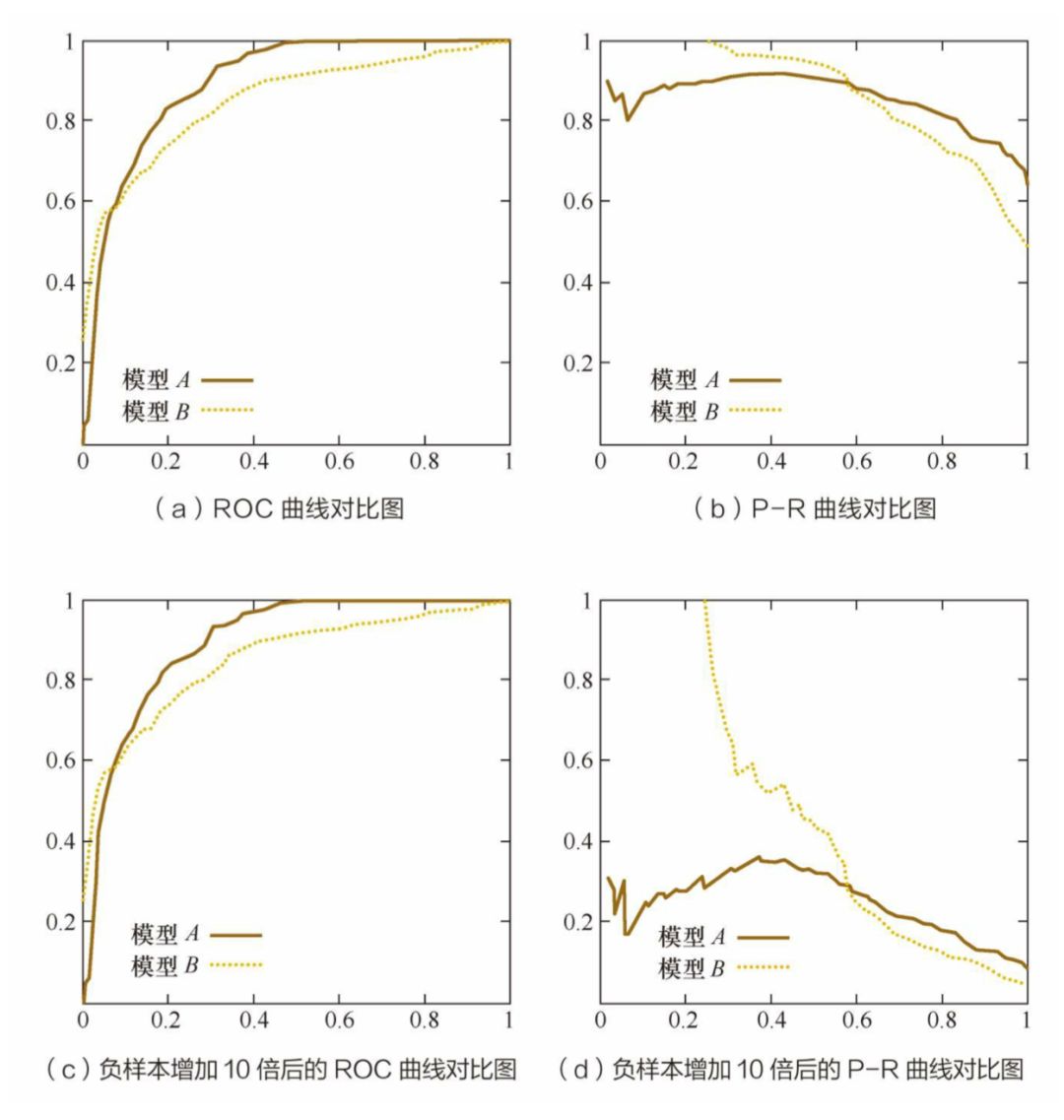
P-R 曲线:横轴召回率,纵轴精确率。 -
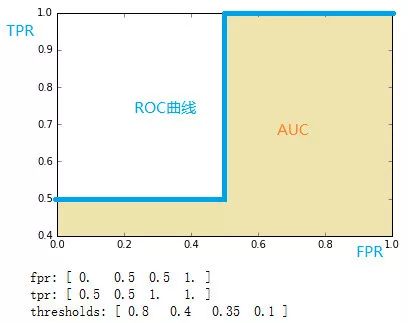
ROC(receiver operating characteristic curve接收者操作特征曲线):采用不分类阈值时的TPR(真正例率)与FPR(假正例率)围成的曲线,以FPR为横坐标,TPR为纵坐标。如果 ROC 是光滑的,那么基本可以判断没有太大的overfitting。 -
AUC(area under curve):计算从(0, 0)到(1, 1)之间整个ROC曲线一下的整个二维面积,用于衡量二分类问题其机器学习算法性能的泛化能力。其另一种解读方式可以是模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。
| 实际正类 | 实际负类 | |
|---|---|---|
|
|
|
|
|
|
|
|
| 阈值 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MSE、RMSE、MAE、R2
-
MSE(Mean Squared Error) 均方误差, -
RMSE(Root Mean Squared Error) 均方根误差, -
MAE(Mean Absolute Error) 平均绝对误差, -
,决定系数,
MSE 和 RMSE 可以很好的反应回归模型预测值和真实值的偏离成都,但如果存在个别离群点的偏离程度非常大时,即使其数量非常少也会使得RMSE指标变差(因为用了平方)。解决这种问题主要有三个方案:
如果认为是异常点时,在数据预处理的时候就把它过滤掉;
如果不是异常点的话,就提高模型的预测能力,将离群点产生的原因建模进去;
-
此外也可以找鲁棒性更好的评价指标,如: ,
余弦距离的应用
-
非负性:
-
对称性: -
三角不等式: 给出反例: 因此有:
A/B测试
-
离线评估无法消除模型过拟合的影响,因此得出的离线评估结果无法完全替代线上评估结果; -
离线评估无法完全还原线上的工程环境,如:数据丢失、标签缺失等情况; -
某些评估指标离线状态下无法评估,比如:用户点击率、留存时长、PV 访问量等。
-
提出问题(给出零假设和备选假设,两个假设互补); -
收集证据(零假设成立时,得到样本平均值的概率:p 值); -
判断标准(显著水平 ,0.1% 1% 5%); -
做出结论(p<= ,拒绝零假设,否则接受)。
-
已知一个总体均数; -
可得到一个样本均数及该样本标准差; -
样本来自正态或近似正态总体。
-
建立假设 ,即先假定两个总体平均数之间没有显著差异; -
计算统计量 T 值,对于不同类型的问题选用不同的统计量计算方法; -
根据自由度 ,查 T 值表,找出规定的 T 理论值并进行比较。理论值差异的显著水平为 0.01 级或 0.05 级; -
比较计算得到的t值和理论T值,推断发生的概率,依据给出的T值与差异显著性关系表作出判断。
-
建立虚无假设 ,即先假定两个平均数之间没有显著差异; -
计算统计量 Z 值,对于不同类型的问题选用不同的统计量计算方法; -
比较计算所得 Z 值与理论 Z 值,推断发生的概率,依据 Z 值与差异显著性关系表作出判断。
-
设 A 代表某个类别的观察频数,E 代表基于 计算出的期望频数,A 与 E 之差称为残差; -
残差可以表示某一个类别观察值和理论值的偏离程度,但如果将残差简单相加以表示各类别观察频数与期望频数的差别,则有一定的不足之处。因为残差有正有负,相加后会彼此抵消,总和仍然为 0,为此可以将残差平方后求和; -
另一方面,残差大小是一个相对的概念,相对于期望频数为 10 时,期望频数为 20 的残差非常大,但相对于期望频数为 1000 时 20 的残差就很小了。考虑到这一点,人们又将残差平方除以期望频数再求和,以估计观察频数与期望频数的差别。
-
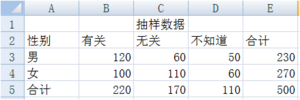
零假设 H0:性别与收入无关。 -
确定自由度为 (3-1)×(2-1)=2,选择显著水平 α=0.05。 -
求解男女对收入与性别相关不同看法的期望次数,这里采用所在行列的合计值的乘机除以总计值来计算每一个期望值,在单元格 B9 中键入“=B5*E3/E5”,同理求出其他值。
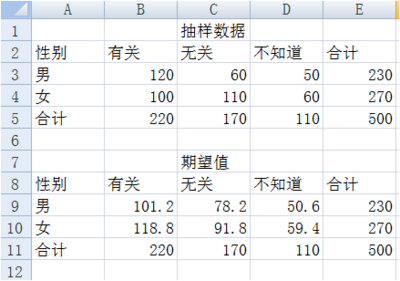
-
利用卡方统计量计算公式计算统计量,在单元格 B15 中键入 “=(B3-B9)^2/B9”,其余单元格依次类推,结果如下所示:
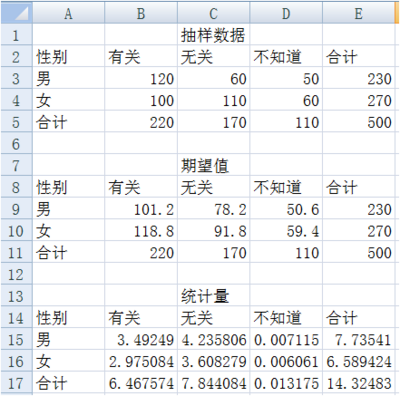
-
最后得出统计量为 14.32483,而显著水平为 0.05 自由度为 2 卡方分布的临界值为 5.9915。 -
比较统计量度和临界值,统计量 14.32483 大于临界值 5.9915,故拒绝零假设。
https://wiki.mbalib.com/wiki/%E5%8D%A1%E6%96%B9%E6%A3%80%E9%AA%8C
推荐阅读
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。

登录查看更多
相关内容

专知会员服务
28+阅读 · 2020年2月18日
Arxiv
4+阅读 · 2018年4月26日


相关VIP内容
专知会员服务
28+阅读 · 2020年2月18日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年4月26日