深度学习模型剪枝:Slimmable Networks三部曲
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Kylin
https://zhuanlan.zhihu.com/p/105064255
本文已由原作者授权,不得擅自二次转载
0.背景介绍
首先,我相信大家都见过不少效果惊人的深度学习模型了。但是在实际应用过程中,人们往往会发现这些效果很好的深度学习模型,对硬件的存储空间和算力都有较高的要求。但是绝大部分嵌入式设备的算力相对而言都十分有限。下面举例简单说明(为了合理比较,暂时不考虑其他加速手段,例如量化加速,GPU/NPU加速等等):
当前市面上比较强的几款手机芯片,A12 (6Core),麒麟980(4xA76+4XA53),高通骁龙855(4xA76+4XA53)。粗略的可以认为一颗核有2 GFLOPs的算力。所以一颗芯片的算力大致为12~16GFLOPs。
而主流的一些深度学习模型算力消耗如下:
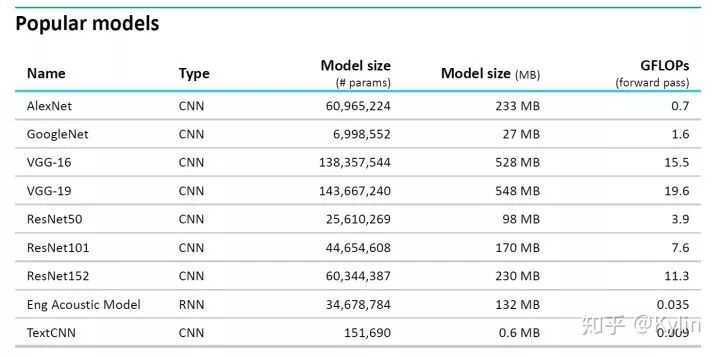
因此,即使在最简单的分类任务中,使用轻量级的MobileNet v2 1.0x(300MFLOPs 
正如前面限定的时候提到的,模型加速手段包括了模型量化和GPU/NPU加速。这些都是更偏向于工程的技术。本文介绍了一种在算法层面实现的加速手段,属于模型剪枝领域。模型剪枝是深度学习模型压缩的一个重要领域,这里不会展开细说。本文的主要目的是介绍Slimmable Networks的系列工作。
Slimmable Networks的相关工作主要由以下三篇论文展示出来:
【1】SLIMMABLE NEURAL NETWORKS
【2】Universally Slimmable Networks and Improved Training Techniques
【3】AutoSlim: Towards One-Shot Architecture Search for Channel Numbers
下面将这三篇论文称为Slimmable Networks三部曲。接下来会分别介绍三部曲的工作,给大家呈现整个完整的脉络。
1. SLIMMABLE NEURAL NETWORKS
1.1 SLIMMABLE NEURAL NETWORKS原理
三部曲里面的第一篇论文提出了一种在给定模型架构前提下,基于参数共享,同时训练不同宽度的模型的算法。对于普通的深度学习模型,为了适应不同的任务需求,可以通过一个全局参数,宽度乘子,来平衡模型的准确率和算力。
宽度乘子的方法非常粗糙。第一,宽度乘子的方法是一个全局参数,会把模型每一层的通道做成统一比例裁剪。然而实际上不同通道的裁剪比例是不一样的。这个观点在很多模型剪枝的工作里面都能得到印证。第二点,对于不同的宽度乘子的模型,都需要独立训练。即,model x1.0 和 model x0.75需要分别从头开始训练。这种训练方式不仅会需要更多的计算资源,各个模型的性能也还有比较大的提升空间。
针对宽度乘子方法的明显缺陷,SLIMMABLE NEURAL NETWORKS里面设计了一种通用的可瘦身网络层。相比于普通的网络层,可瘦身网络层的通道数量是可以根据预设的值变化的。对比如下图所示:
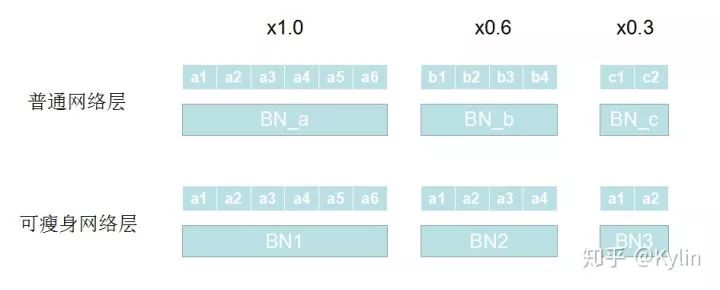
普通网络层对于不同的宽度乘子,分别对应不同宽度的网络层。不同宽度的网络层对应的不同的参数和BN层, 



1.2 训练方法
在训练过程中,基于给定的宽度乘子列表,分别对不同宽度的模型进行训练。整个过程中训练的模型参数都是共享的。详细步骤如下:

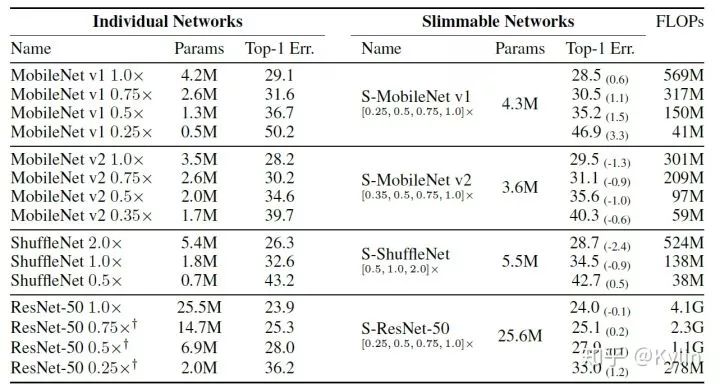
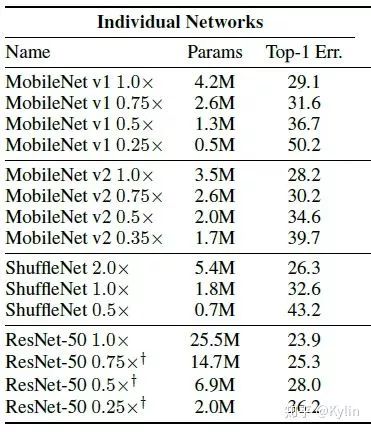
1.3 结果比较
1.3.1 图像分类任务
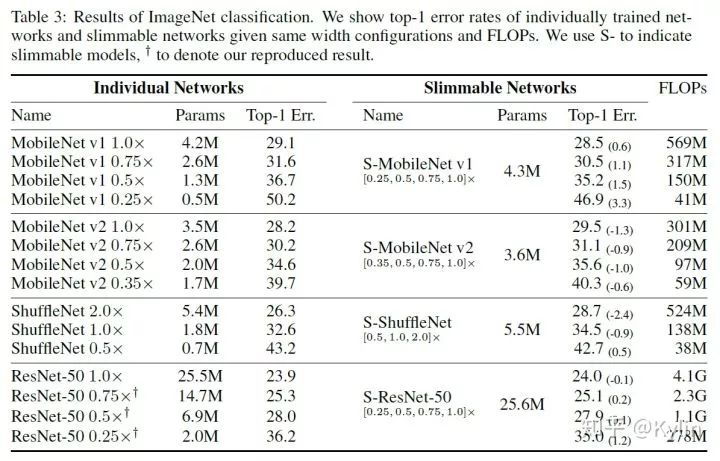
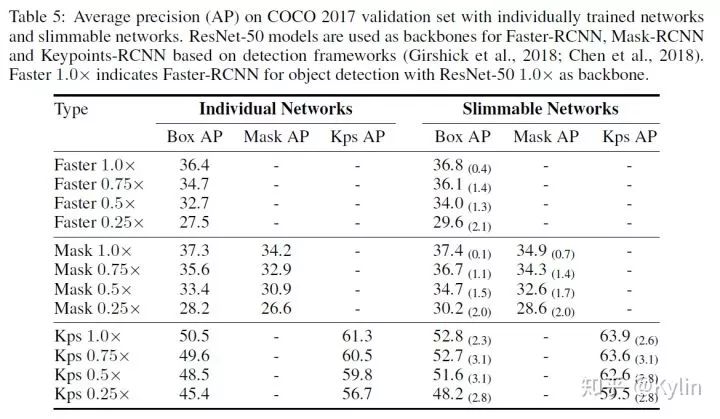
1.3.2 目标检测,语义分割和关键点检测
2. Universally Slimmable Networks and Improved Training Techniques
2.1 Universally Slimmable Networks 的背景和原理
作为三部曲里面的第二部,这篇论文提供了一个更灵活巧秒的通道剪枝算法。第一篇论文里面通过可瘦身网络层,基于参数共享,训练得到了三个不同宽度的模型。但是,这里还是有一个问题没有解决:即不同通道的裁剪比例应该是不一样的。第二篇论文主要创新点就是解决了这个问题,实现了在界定范围内,大批量的训练得到被剪枝后的模型。三部曲之二有两个基本的观点,用数学符号描述如下:
1.单个神经元的输出表示为: 




2. 对于 





第一个观点描述了网络层特征图聚集的基本规则。第二个观点中的不等式比较重要,可以拆分成两个部分分别理解:首先在剪枝过程中,自然的可以认为 



基于这些基本观点,论文里面将 slimmable networks 推广为 universally slimmable networks。universally slimmable networks 可以更加灵活的在每一个可瘦身网络层级别进行裁剪,真正解决了全局宽度乘子的遗留问题。到此为止,理论上都一帆风顺,但是实际在操作过程中还有很多问题要解决。
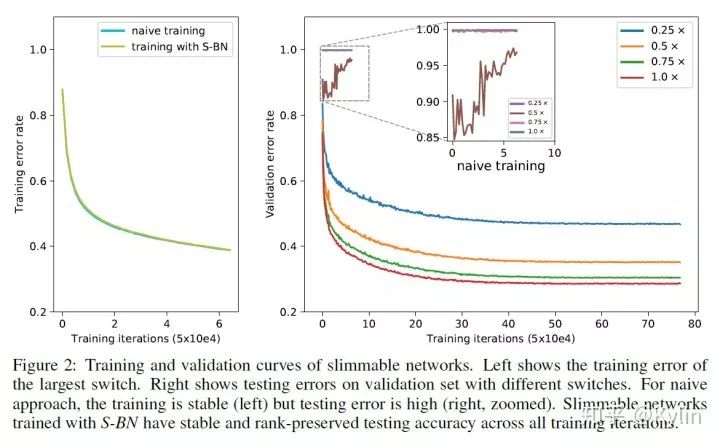
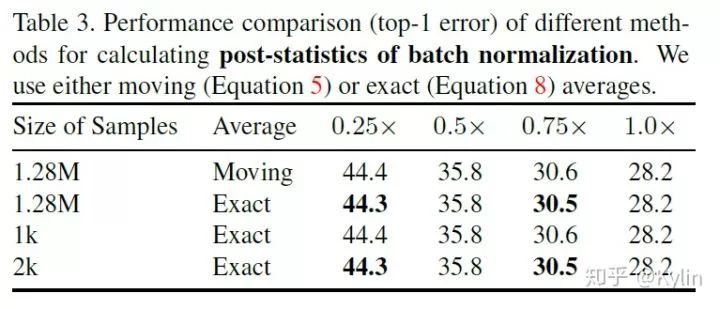
第一个问题,关于BN层统计means和variances。这个问题本质上还是第一篇文章里面的问题,对于不同宽度的网络层需要单独配置对应的可切换BN。但是在 universally slimmable networks 里面问题变得更加复杂了。首先,每个 universally slimmable networks 的子网络都需要一组新的可切换BN,这样效率太低下了并且会消耗额外的计算资源。其次,对于每个 universally slimmable networks采样得到的子网络计算更新BN的means和variances的次数很可能不够,导致累计结果偏差。怎么解决这些看似很难的问题呢?论文的作者其实是非常聪明的。还记得上文Fig.2的探究结果吗?Fig.2表明,普通训练和加入了可切换BN的训练过程是几乎一致的,差别在于训练结束后,普通训练方式得到的BN层统计means和variances存在偏差,直接导致结果崩坏。基于这个观察,作者提出了对应的解决方案:先进行训练,等到模型收敛之后,将参数固定,再统计universally slimmable networks子网络的可切换BN的means和variances。并且,这种训练后再统计方法甚至可以随机采样训练子集来一次性完成,同时保证性能几乎没有损失。下图的探究结果展示了这种方案的可靠性。
关于universally slimmable networks实现过程中的第二个问题是如何进行训练?基于上面提到的基本观点,作者设计一种训练方式叫做The Sandwich Rule。The Sandwich Rule 训练方式就是说,先训练没有任何裁剪的网络,我在这里称为max model, 然后再训练随机采样的模型,称为random model,最后训练min model。训练max model和min model是非常有必要的。因为基本观点里面告诉我们,模型性能是被界定了的,训练max model和min model实际上是在提高整个模型界定区间的性能。同时使用随机采样的方式训练其他子模型可以在保证收敛的前提下,大大减少计算量。下表中的探究结果也证实了这个结论:
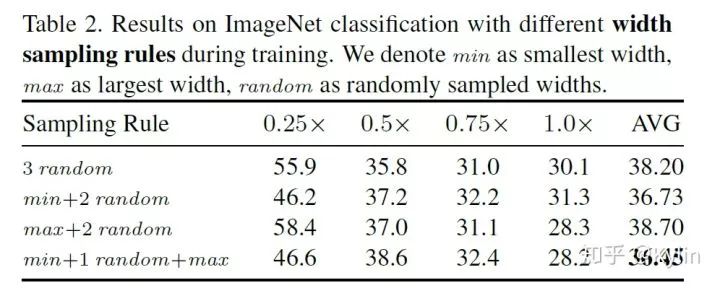
最后,论文中还提到了一种提升模型性能的方法,叫做Inplace Distillation。这个方法将训练过程中参数共享和知识蒸馏的思想结合了起来,对模型有一定的提升,但是通用性有一定局限性,不多做叙述,感兴趣的小伙伴们可以看看原文。
2.2 算法流程

2.3 结果比较
文章里面主要在分类任务和图像超分任务上做了验证对比。
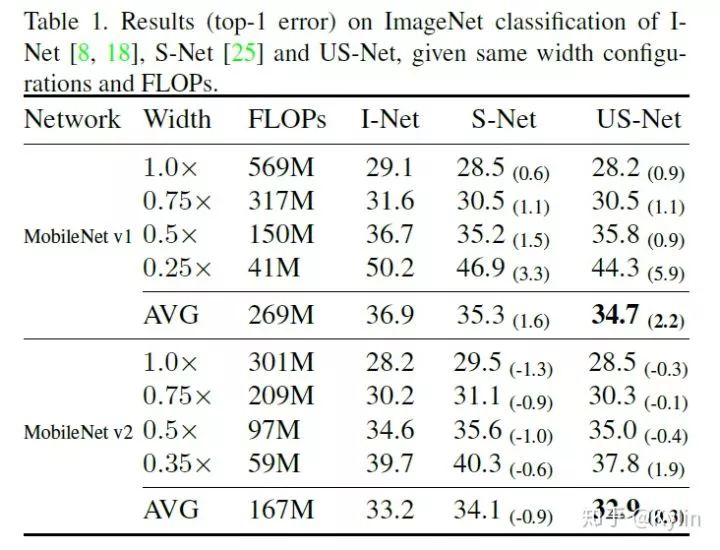
2.3.1 图像分类
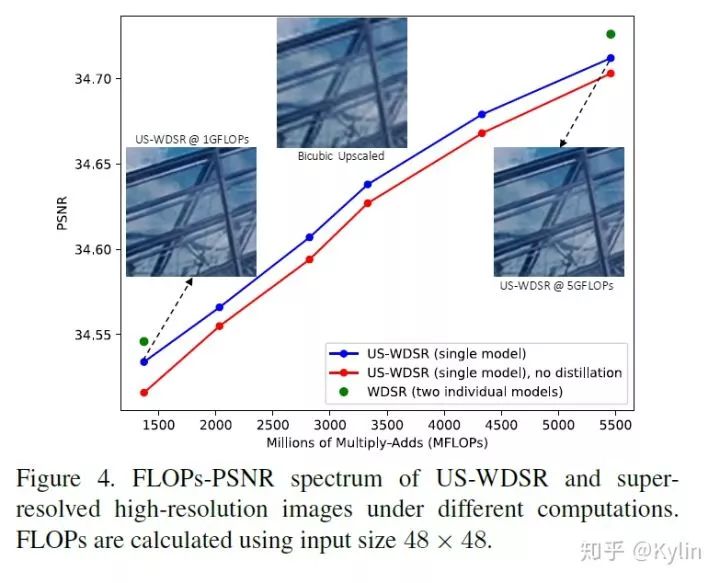
2.3.2 图像超分
3. AutoSlim: Towards One-Shot Architecture Search for Channel Numbers
3.1 AutoSlim 的背景和原理
三部曲的最后一部,将universally slimmable networks 进一步推广到了神经网络架构搜索(NAS)领域。在 universally slimmable networks 这个工作里面,最后给出的是一个网络池。下一个问题就是,我们应该怎样从这个池子里面,选出我们想要的那一个网络模型?AutoSlim 就是解决了这么一个问题。
在此之前,利用下图[3]简单的说明一下NAS和model prune这两个不同的任务。
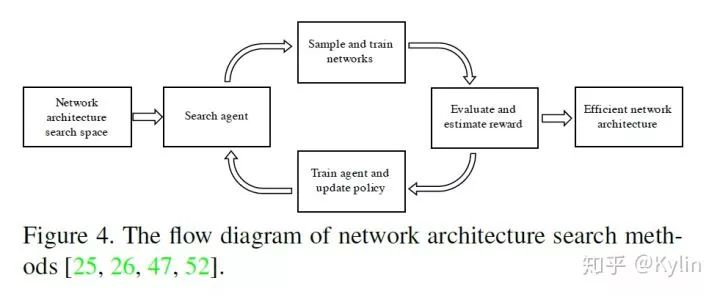
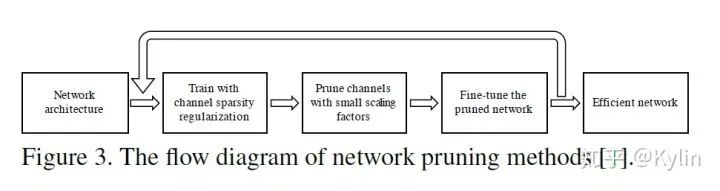
对比NAS和model prune,model prune其实可以认为是更细粒度的NAS。因为NAS的本质是搜索得到最优的网络结构。现在的大部分NAS算法,考虑到搜索空间和算力的平衡,都只能做到固定模块粒度的搜索。如果算力资源允许,完全可以做到对每一个网络层的通道连接方式进行搜索。这一步的工作,其实就是model prune在做的事情。这是我个人对这两个任务的理解。而 AutoSlim 在一定程度上将这两者关联了起来。下面我们看一下 AutoSlim 是怎么做的:
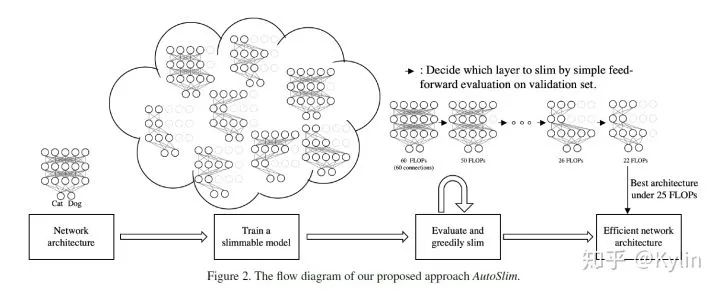
AutoSlim 1)首先在给定的网络架构下,利用 universally slimmable networks 的训练方式,得到了一个模型池。这里跟 universally slimmable networks 不同的是max model 的宽度乘子为 x1.5,扩大了搜索空间,任务更接近于NAS。2)然后根据人为指定的budget(FLOPs或CPU latency限制等等),在保证精度的前提下,采用贪心的方式,逐层裁剪网络层的通道(Greedy Slimming)。这里进行 Greedy Slimming 的时候是不需要进行训练的,利用Large Batch Size 来进行推理计算。所以 AutoSlim 是一个 One-Shot Architecture Search 的方式。3)最后,拿到选择出来的最优模型,再做一遍train from scratch 即可。(NAS 对最优模型常用的处理方式)
所以,AutoSlim 不仅仅是一个model prune算法,也是一个NAS算法。AutoSlim 的优点在于非常的快,缺点也很明显,网络架构限定太严格了,很难搜索出亮眼的模型。如果能选择一个好限定范围,我相信还能做出更多的有趣的工作。
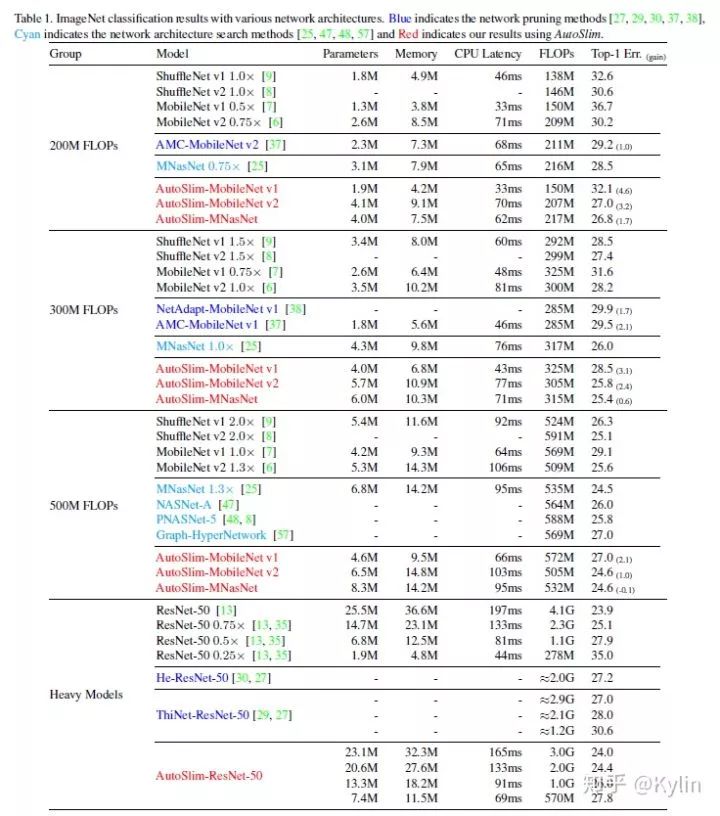
3.2 结果比较
作者在分类任务上做了比较详细的比较
至此,三部曲全部介绍完了。希望这些总结记录能对大家有所帮助!:)
参考文献:
[1] SLIMMABLE NEURAL NETWORKS
[2] Universally Slimmable Networks and Improved Training Techniques
[3] AutoSlim: Towards One-Shot Architecture Search for Channel Numbers
[4] https://www.hpcuserforum.com/presentations/Wisconsin2017/HPDLCookbook4HPCUserForum.pdf
重磅!CVer-模型剪枝微信交流群已成立
扫码添加CVer助手,可申请加入CVer-模型剪枝交流群。同时还可以申请加入大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如模型剪枝+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


