大会 | 还记得Wasserstein GAN吗?不仅有Facebook参与,也果然被 ICML 接收
AI 科技评论按:Facebook列出了自己的9篇 ICML 2017论文,Wasserstein GAN 赫然位列其中。

ICML 2017 仍然在悉尼火热进行中,Facebook 研究院今天也发文介绍了自己的 ICML 论文。Facebook有9篇论文被 ICML 2017接收,这些论文的主题包括语言建模、优化和图像的无监督学习;另外 Facebook 还会共同参与组织 Video Games and Machine Learning Workshop。
曾掀起研究热潮的 Wasserstein GAN
在9篇接收论文中,Facebook 自己最喜欢的是「Wasserstein Generative Adversarial Networks」(WGAN)这一篇,它也确实对整个机器学习界有巨大的影响力,今年也掀起过一阵 WGAN 的热潮。
Ian Goodfellow 提出的原始的 GAN 大家都非常熟悉了,利用对抗性的训练过程给生成式问题提供了很棒的解决方案,应用空间也非常广泛,从此之后基于 GAN 框架做应用的论文层出不穷,但是 GAN 的训练困难、训练进程难以判断、生成样本缺乏多样性(mode collapse)等问题一直没有得到完善解决。 这篇 Facebook 和纽约大学库朗数学科学研究所的研究员们合作完成的 WGAN 论文就是众多尝试改进 GAN、解决它的问题的论文中具有里程碑意义的一篇。
WGAN 的作者们其实花了整整两篇论文才完全表达了自己的想法。在第一篇「Towards Principled Methods for Training Generative Adversarial Networks」里面推了一堆公式定理,从理论上分析了原始GAN的问题所在,从而针对性地给出了改进要点;在这第二篇「Wasserstein Generative Adversarial Networks」里面,又再从这个改进点出发推了一堆公式定理,最终给出了改进的算法实现流程。
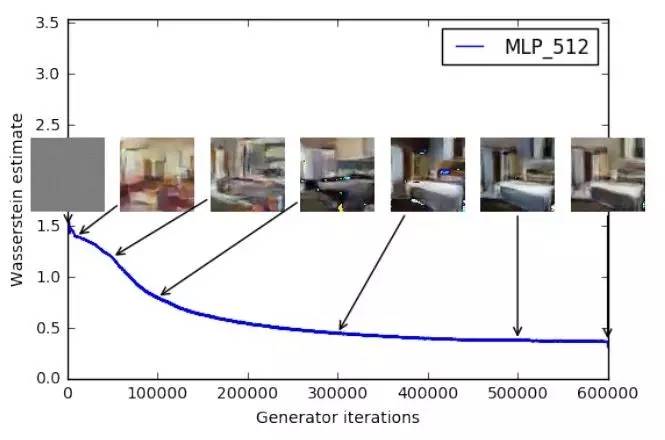
WGAN 成功地做到了以下爆炸性的几点:
彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
基本解决了collapse mode的问题,确保了生成样本的多样性
训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高(如题图所示)
以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
而改进后相比原始GAN的算法实现流程却只改了四点:
判别器最后一层去掉sigmoid
生成器和判别器的loss不取log
每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
所以数学学得好真的很重要,正是靠着对 GAN 的原理和问题的深入分析,才能够找到针对性的方法改进问题,而且最终的呈现也这么简单。( WGAN详解参见AI科技评论文章 令人拍案叫绝的Wasserstein GAN)
WGAN 论文今年1月公布后马上引起了轰动,Ian Goodfellow 也在 reddit 上和网友们展开了热烈的讨论。不过在讨论中,还是有人反映 WGAN 存在训练困难、收敛速度慢等问题,WGAN 论文一作 Martin Arjovsky 也在 reddit 上表示自己意识到了,然后对 WGAN 做了进一步的改进。
改进后的论文为「Improved Training of Wasserstein GANs」。原来的 WGAN 中采用的 Lipschitz 限制的实现方法需要把判别器参数的绝对值截断到不超过固定常数 c,问题也就来自这里,作者的本意是避免判别器给出的分值区别太大,用较小的梯度配合生成器的学习;但是判别器还是会追求尽量大的分值区别,最后就导致参数的取值总是最大值或者最小值,浪费了网络优秀的拟合能力。改进后的 WGAN-GP 中更换为了梯度惩罚 gradient penalty,判别器参数就能够学到合理的参数取值,从而显著提高训练速度,解决了原始WGAN收敛缓慢的问题,在实验中还第一次成功做到了“纯粹的”的文本GAN训练。(WGAN-GP详解参见AI科技评论文章 掀起热潮的Wasserstein GAN,在近段时间又有哪些研究进展?)
另外八篇论文
Facebook 此次被 ICML 2017 接收的9篇论文里的另外8篇如下,欢迎感兴趣的读者下载阅读。
High-Dimensional Variance-Reduced Stochastic Gradient Expectation-Maximization Algorithm
http://proceedings.mlr.press/v70/zhu17a/zhu17a.pdf
An Analytical Formula of Population Gradient for two-layered ReLU network and its Applications in Convergence and Critical Point Analysis
作者田渊栋
https://arxiv.org/abs/1703.00560v2
Convolutional Sequence to Sequence Learning
http://proceedings.mlr.press/v70/gehring17a/gehring17a.pdf
Efficient softmax approximation for GPUs
http://proceedings.mlr.press/v70/grave17a/grave17a.pdf
Gradient Boosted Decision Trees for High Dimensional Sparse Output
http://proceedings.mlr.press/v70/si17a/si17a.pdf
Language Modeling with Gated Convolutional Networks
http://proceedings.mlr.press/v70/dauphin17a/dauphin17a.pdf
Parseval Networks: Improving Robustness to Adversarial Examples
http://proceedings.mlr.press/v70/cisse17a/cisse17a.pdf
Unsupervised Learning by Predicting Noise
http://proceedings.mlr.press/v70/bojanowski17a/bojanowski17a.pdf
———————— 给爱学习的你的福利 ————————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

——————————————————————————






