DeepMind论文:多巴胺不只负责快乐,还能帮助强化学习
编者按:在过去的20年中,基于奖励学习的神经科学研究已经发展成了典型的模型,在这一模型中,神经递质多巴胺通过调节神经元之间突触连接的强度了解场景、行为和奖励之间的联系。然而,最近大量的研究使得这类标准模型渐渐“失宠”。
基于最近人工智能的发展,DeepMind的研究人员发现了一种有关基于奖励的学习的新理论。在这篇论文中,他们让多巴胺系统训练大脑的前额叶皮质层,使其学会独立学习。这一新观点不仅契合标准模型,更激发了新的发现,同时还有助于未来的研究。以下是论智对DeepMind博客的编译。

论文地址:arxiv.org/abs/1611.05763
最近,AI系统已经会玩许多电子游戏了,比如经典的雅达利游戏Breakout和Pong。虽然表现出色,AI仍然需要依赖数千小时的游戏训练才能达到甚至超越人类水平。相反,我们只需要几分钟就能学会一款新游戏的基本操作。
大脑为什么能在短时间具备这些能力即是元学习理论,或者说是“学习如何学习”的过程。一直以来,科学家认为我们在学习时遵循两个尺度:短期内,我们关注的重点在学习具体的例子上,长期来看,我们学习的是完成一项任务所需要的抽象技巧或规则。这两种学习方法的结合帮助我们高效地学习,并将这些知识快速、灵活地应用到新任务中。之后我们证明,在AI系统中创建这种元学习结构,对于让智能体具备快速、一次性成功的学习是非常有效的。然而,这种发生在大脑中的处理机制仍然很难完全用神经科学解释清楚。
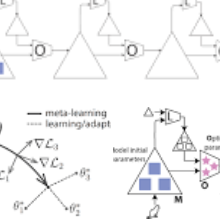
在我们新发表在《Nature》上的论文中,我们利用元强化学习框架,探究大脑中多巴胺在帮助我们学习时所起的作用,从而应用于AI上。
多巴胺,通常被人们看作是是大脑愉悦的信号,研究人员经常将其类比成强化学习算法中的“奖励”。这些算法通过不断试错、在奖励的激励下学习某种动作。我们认为,多巴胺的角色不仅仅是使用奖励学习之前的动作,而是有更内在的功能,尤其在大脑的前额叶皮质区,能让我们更快、更高效、更灵活地学习新任务。
多巴胺结构
为了测试我们的理论,我们重建了六个虚拟的神经科学元学习实验,每个实验都需要智能体用到相同的基础规则(或技能),但是它们在某些维度上是不同的。我们用标准的深度强化学习技术(模拟多巴胺的作用)训练了一个循环神经网络(表示前额叶皮质区),然后将循环神经网络生成的动态活动与在神经科学实验中得到的真实数据相对比。循环神经网络是元学习一个很好地代理,因为它们可以内化过去的行为和所观察到的动作,并且在不同任务上训练时会用上这些经验。
重建的实验中,有一项名为“恒河猴实验(Harlow Experiment)”的项目,这是上世纪40年代的一种心理学测试,用来探寻元学习的概念。在最初的测试中,科学家们给一群猴子两种不同的物品,让它们从中选择,只有其中一个物品会得到奖励。这一实验进行了六次,每次科学家都会交换左右两个物品,让猴子学会辨认哪种物品会得到奖励。之后他们又换了两种不一样的物品,同样只有其中一个会获得奖励。通过这次训练,猴子学会了挑选能得到奖励的策略:第一次,它们只是随机挑选,然后根据奖励反馈选择特殊的物品,而不是简单地挑选左右。实验表明,猴子可以将一项任务的基本规则内化,学习抽象的规则结构,也就是“学着学习”。
当我们用虚拟屏幕模拟类似的测试,并随机选择图片时,我们发现,我们的“元强化学习智能体”表现出“恒河猴实验”中动物的行为,即使我们提供的是完全陌生的图片。

事实上,我们发现,元强化学习智能体可以学着快速适应多种具有不同规则和结构的认为。而且由于网络学会了如何适应不同任务,它同样可以学会如何高效学习的基本通用原则。
重要的是,我们发现学习的大部分都发生在循环网络中,这也证实了我们的想法“多巴胺在元学习过程中的内部作用更重要”。传统观点认为,多巴胺是用来加强前额叶系统的突触连接、强化特定行为的。在人工智能中,这意味着类似多巴胺的奖励信号会调整神经网络中的人工突触权重,让它学习正确的解决任务方法。然而,在我们的实验中,神经网络的权重是固定的,也就是说它们无法再学习过程中进行调整。但是,元强化学习智能体仍然可以解决并适应新的问题。这就表明,多巴胺似的奖励并不仅仅用来调整权重,而且还蕴含了许多关于抽象任务和规则的重要信息,使其对新的任务适应得更快。
神经科学家们花了很长时间观察大脑前额叶皮质区的类似神经活动,即能够快速地适应,并且非常灵活。但是很难找到出现这种情况的原因。有观点这样认为:前额叶皮质区并不依赖缓慢的突触权重的改变学习规则结构,而是利用抽象的、基于模型的信息直接解码多巴胺中的信息。这一观点为前额叶皮质区的多功能性提供了令人满意的解释。
在探究AI和大脑中生成元强化学习的关键因素的过程中,我们提出的理论不仅适用于已知的多巴胺在前额叶皮质区的作用,而且还能解释神经科学和心理学中许多神秘的成果。特别是这项理论对于大脑中有结构的、基于模型的学习的产生、多巴胺为何自身具有基于模型的信息、以及前额叶皮质区的神经元是如何转换成与学习相关的信号的,都有了新的发现。用从人工智能系统中得到的发现探究神经科学和心理学的研究,表明两种不同领域之间的相互作用。未来,我们希望这一过程能反过来,用大脑中特殊组织来设计强化学习智能体学习的新模型。
原文地址:deepmind.com/blog/prefrontal-cortex-meta-reinforcement-learning-system/