短袖短裤识别算法冠军方案总结 | 极市打榜

极市导读
极市打榜目前正在火热的进行中!本文为短裤短袖识别算法的冠军tourist,总结了他当时参珠港澳人工智能算法大赛和最近参与打榜的一些技术细节和经验,希望能够给后续参加的朋友们一些参考,取得更好的成绩。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
短袖短裤识别最早是 2020首届珠港澳人工智能算法大赛 的一个赛题,而如今又在极市平台后来推出的“算法打榜”专栏中再次上线,目的在于持续激励开发者创造更好的成绩。同时本文也为了方便大家更好地了解这个题目,总结了当时竞赛和最近打榜的一些技术细节和经验,希望能帮助后来参与打榜和类似竞赛的大家取得更好的分数。
任务介绍
短裤短袖识别算法可以视为一个目标检测类型的算法,主要应用背景为建筑工地及工厂等作业区域,对进入作业区域的人员进行自动识别:若检测到人员穿着短裤短袖,可立即报警,报警信号同步推送至管理人员。该算法极大地提升了作业区域的管控效率,保障了作业人安全。
本算法打榜地址:https://cvmart.net/topList/10015?tab=RealTime&dbType=1-1-1&hasMT=1&hasBT=0
本榜和其他类型的目标检测打榜任务一样,最终得分采取准确率、算法性能绝对值综合得分的形式,具体如下:
| 指标 | 说明 |
|---|---|
| 算法精度分 | F1 Score |
| 算法性能分 | FPS / 100,如果 FPS > 100则按100计算 |
| 总分 | Score = 算法精度分 * 0.9 + 算法性能分 * 0.1 |
补充说明:
-
总分为本项目排行榜上的 Score,排名:总分值越高,排名越靠前; -
算法性能指的赛道标准值是 100 FPS, 如果所得性能值 FPS > 100,则赛道标准值 FPS 按 100 计算; -
评审标准:参赛者需要获得算法精度和算法性能值的成绩,且算法精度 >= 0.1,算法性能值 FPS >= 10,才能进入获奖评选.
值得注意的是算法性能分只占了总分一成的权重而算法的精度则占了总分的九成,常规的思想是需要优先保证算法模型的精度的同时进一步提升模型的速度,而这里算法性能这项指标只要算法在 GPU (NVIDIA T4)上平均推理速度快达 100 帧每秒(10ms 处理一张图像)则可以获取该项指标的满分,这并不难做到,所以后续模型选型考虑从一个足够快的小模型入手,在保持性能分刚好满分的前提下,优化模型的精度性能。
本榜也和其他类型打榜一样提供了丰厚的奖励:
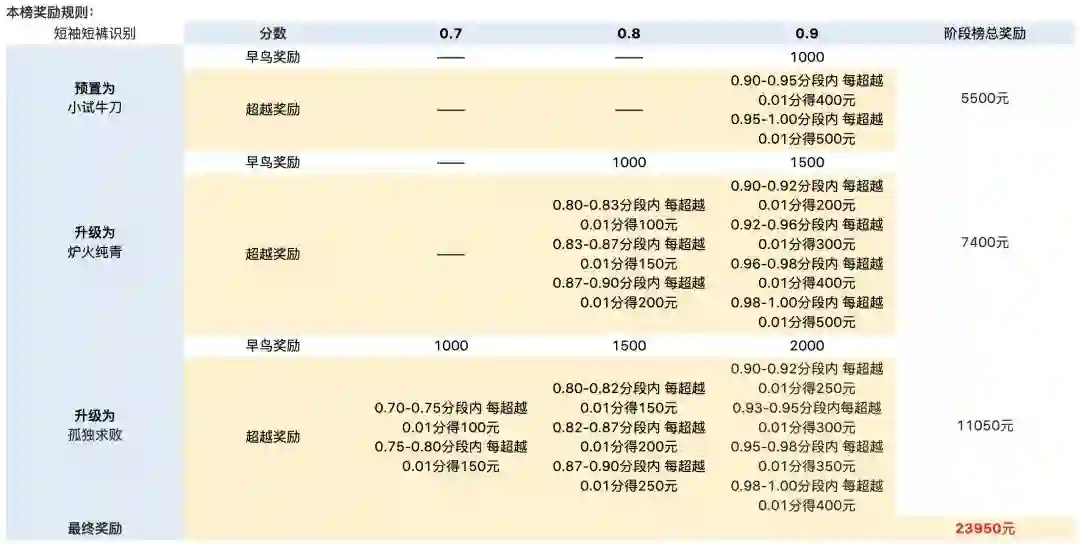
而目前本榜的上榜人数较少(截止 2022 年 3 月初只有 6 人上榜),相信下文提供的技术细节和经验会助力大家提分和上榜~
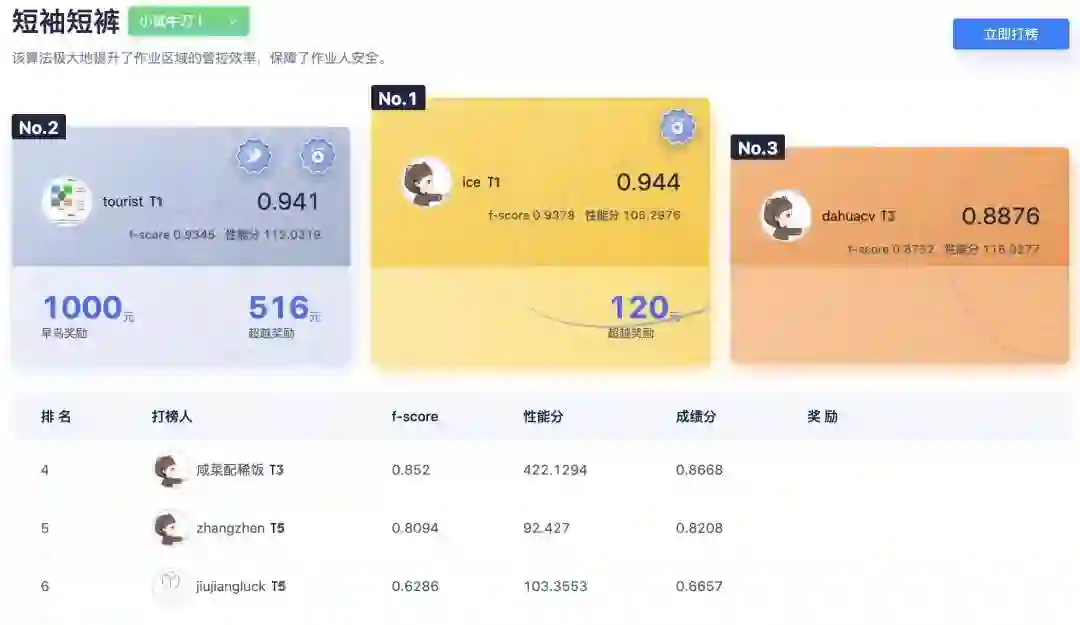
解决方案
1.数据分析
本榜提供的短袖短裤检测数据集(https://cvmart.net/dataSets/detail?detailTab=introduce&id=146&tabType=0)主要为监控设备在商场、道路、工地场景拍摄采集,多数为特写,小部分为远景。主要针对图像画面中出现的行人进行标注,标注其区域位置,并对其上下着装进行打标签。标签有 “短袖”("s_sleeve")、“长袖”("l_sleeve")、“短裤”("shorts")、“长裤”("trousers") 四种,每个行人最多只有两个标签(即目标的标签数不固定)。一共 14614 张图片,样本数量为 17170。其中 10207 张图片用于开发者训练,4407 张用于模型测试。图像数据均为 JPG 格式,标注类型为 CVAT,标注文件格式为 XML,标签类型 bounding box。

训练集中图片主要的分辨率大小有 312*796、500*750、1596*898、1728*1080、 1920*1080 等,其中 “瘦高” (宽 < 高)的图片为商城监控(有裁剪)、街拍的图像,行人相对于图像的占比较大,这类的数量为 8087 张,并且每张图像中普遍只有 1 个人;而 “矮胖” (宽 > 高)的图片为工厂监控摄像头的原图像,行人相对于原图像的占比较小,数量为 2120 张,图像中普遍不止 1 个人。由此不由地想到可以用一个输入尺度较小的网络模型用预处理 “瘦高” 类型的图像,而用一个输入尺度大的网络处理 “矮胖” 的图像,前者计算量较小,后者计算量大但对于小目标检测较友好,综合下来,速度和精度能得到进一步的权衡。
| 图片尺度 | 数量占比 |
|---|---|
| “瘦高” 类型 | 79.2% |
| “矮胖” 类型 | 20.8% |

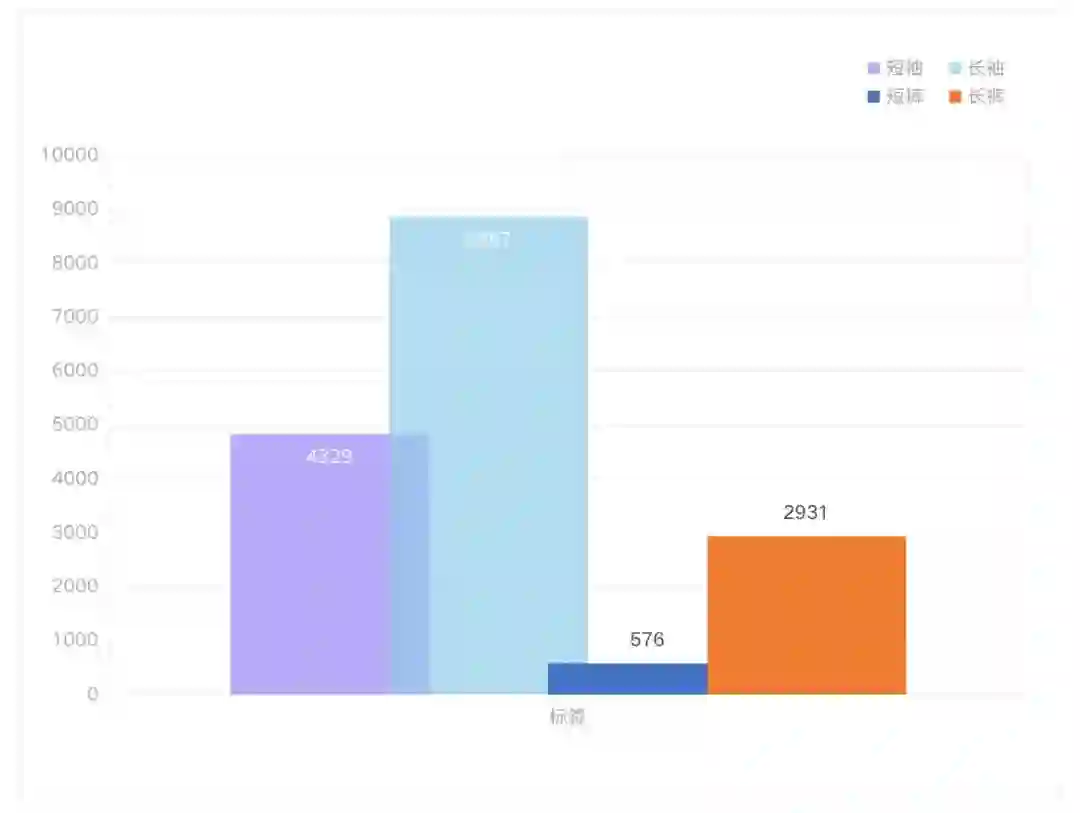
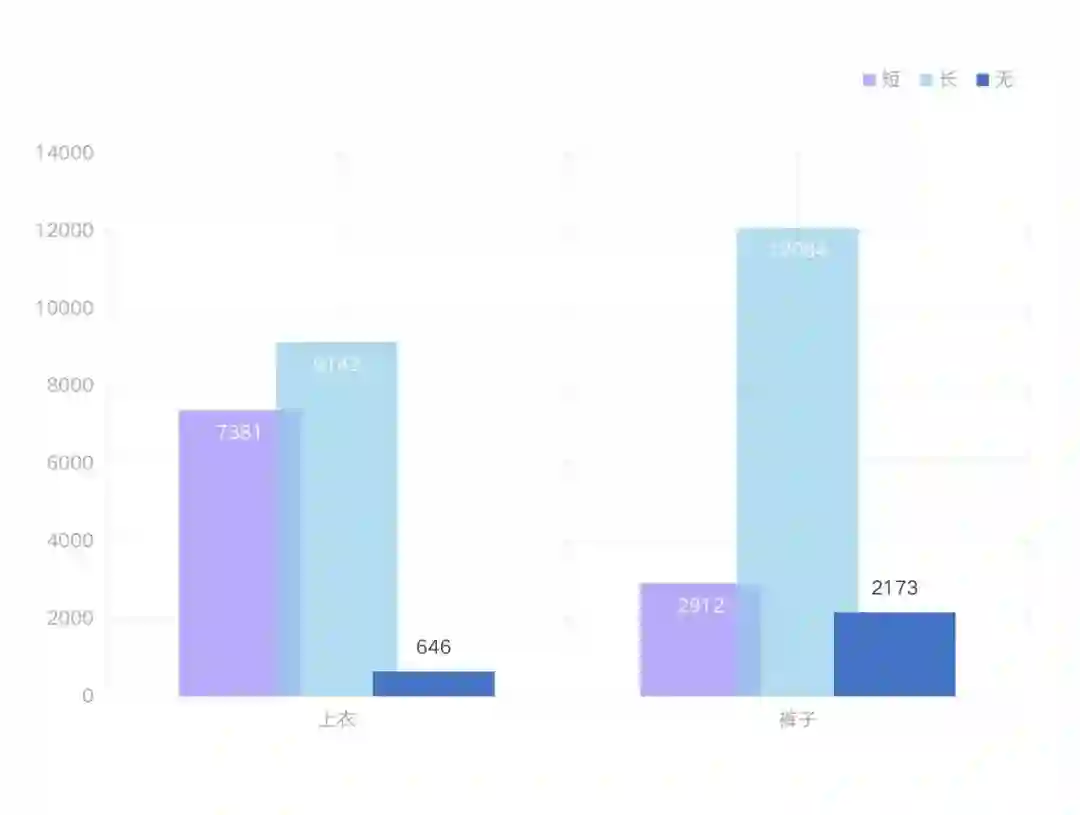
另外如果将任务从多标签图像分类的角度思考,可以统计训练集中目标的标签内容及数量如下:
当然也可以将该任务直接当做多目标检测问题,也即行人的不同穿戴状态视为不同的目标,那么总共的目标类型有:['短袖'、'短裤']、['短袖'、'长裤']、['长袖'、'短裤']、['长袖'、'长裤']、['短袖']、['长袖']、['短裤']、['长裤'] 八种,统计各种目标数量如下:
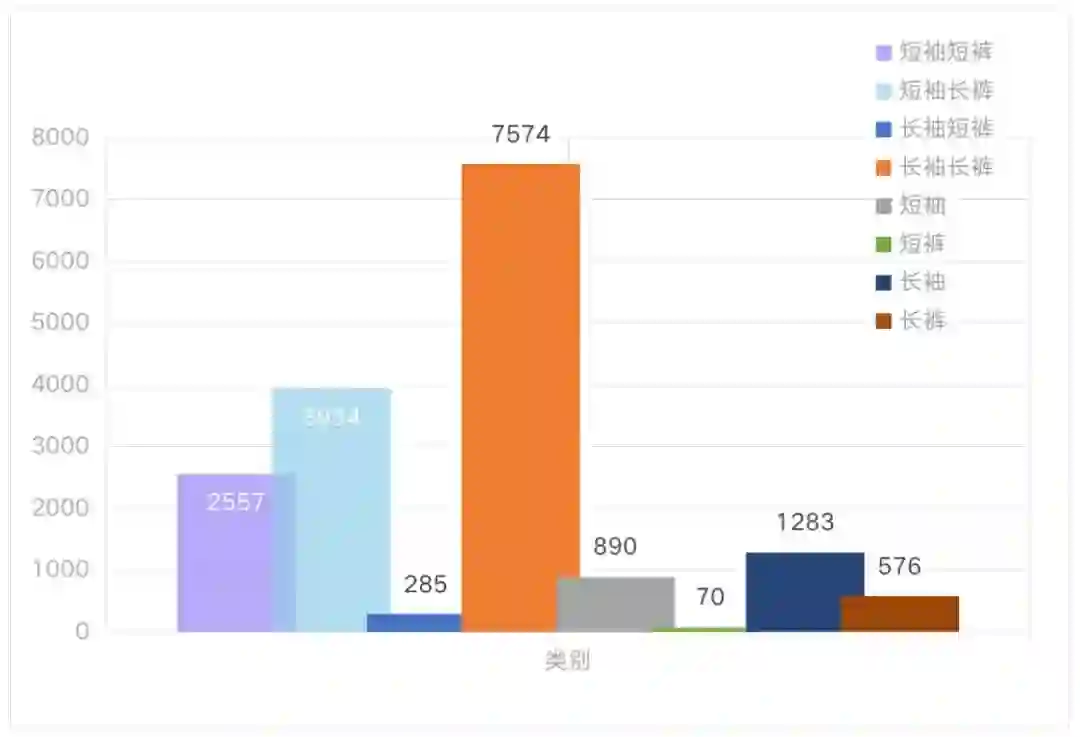
从上面两个条形统计图可见,将该任务视为一个行人检测 + 多标签分类(mult-label classification),即检测图像中的行人位置并给出该行人的属性标签,该属性标签在 ['短袖'、'长袖'、'短裤'、'长裤'] 中进行选择,样本的数量相对于多目标检测的方式会显得更均匀和聚拢一些,模型的召回率应该也会优于多目标检测的方式。
不过还有另外一种思路,就是将任务转为 行人检测 + 两组图像分类,两组分类指的是将行人的上衣属性视为一组分类,而裤子属性视为一组分类。这种方式相对直接多目标检测的方式样本的类别也会更聚拢一些,样本的分布也会更好一些,两个分类器相互独立,有利于提升模型的精确率。笔者采用的是这种方法,下面将围绕这种方法具体讲述。
打榜技巧:虽然平台中开发者可自由预览的数据只有 100 张,但是我们可以通过发起一次 “空训练”,编写相应的代码,对数据集中的某些关键参数进行统计和记录,为后续模型选型和设计提供参考。
2.模型选取与训练
基于 YOLOv5 目标检测框架:为了兼顾速度和性能,这里选择的也是开源社区内颇为流行的 YOLOv5 作为目标检测框架。在此基础上,主要修改 YOLOv5 的网络模型输出部分、loss 部分和训练数据的标签解析部分。
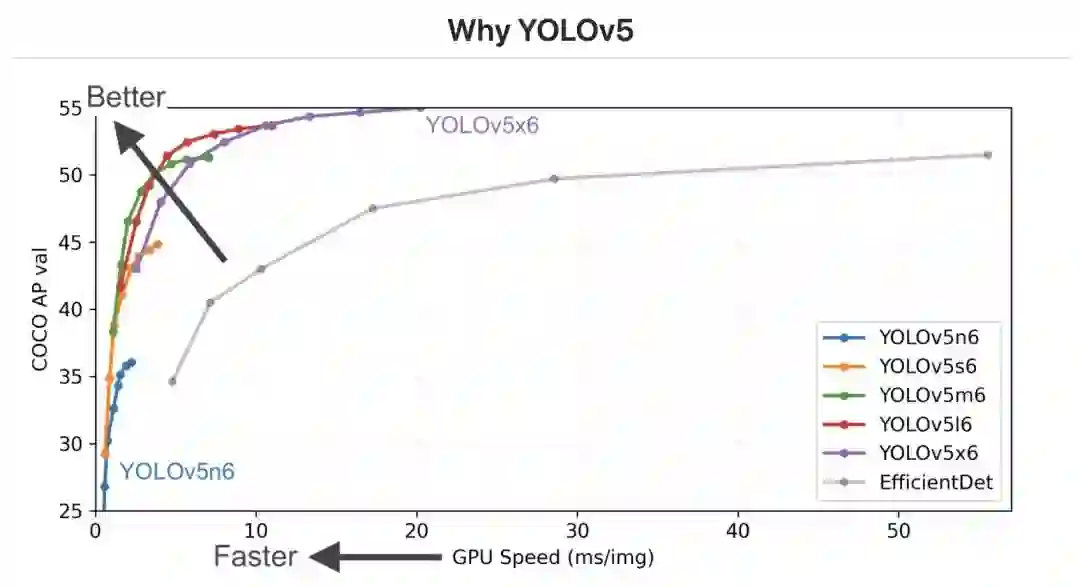
YOLOv5(https://github.com/ultralytics/yolov5) 代码主要修改细节:
-
训练集标签转换和读入:原训练集中的标签为 XML 格式,此处可以编写相应的代码将标签转换为 YOLOv5 的输入格式( https://roboflow.com/formats/yolov5-pytorch-txt?ref=ultralytics),但是为了加入上衣和裤子的类别情况,需要在 YOLOv5 的数据格式基础上再次改动。笔者使用的数据格式为
...
class_id1 class_id2 center_x center_y width height
...
class_id1 和 class_id2 分别用来标识上衣的['短袖']、['长袖']、['无'] 三种类别和裤子的['短裤']、['长裤']、['无'] 三种类别
-
网络类别输出可以设置为 6,但实际前三位表示上衣的三种类别预测值,后三位表示裤子的三种类别与测试 -
loss 部分的代码改动: -
https://github.com/ultralytics/yolov5/blob/3752807c0b8af03d42de478fbcbf338ec4546a6c/utils/loss.py#L145-L149
...
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE
...
# 改为 =>
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:5+3], cn, device=device) # targets
t[range(n), tcls[i][0, :]] = self.cp
lcls += BCEcls(ps[:, 5:5+3], t) # 上衣分类 BCE
t = torch.full_like(ps[:, 5+3:5+3+3], cn, device=device) # targets
t[range(n), tcls[i][1, :]] = self.cp
lcls += BCEcls(ps[:, 5+3:5+3+3], t) # 裤子分类 BCE
FPS 超过 100 的同时 backbone 尽可能大:在 GPU 环境下很多轻量级、小模型的推理速度很容易达到 100 FPS,大于 100 FPS 即为性能分满分,但我们不需要追求更快的模型,应该兼顾模型的识别精度,所以还需要权衡模型的网络大小,此处选取的是足够大的 YOLOv5 Large 级别的模型,结合部署端的代码优化,可以刚好实现性能分满分。
打榜技巧:TensorRT 目前是公认的在 NVIDIA 显卡上深度学习模型推理速度最快的框架,测试时推荐使用 TensorRT 部署模型,可以收益更高的性能分。
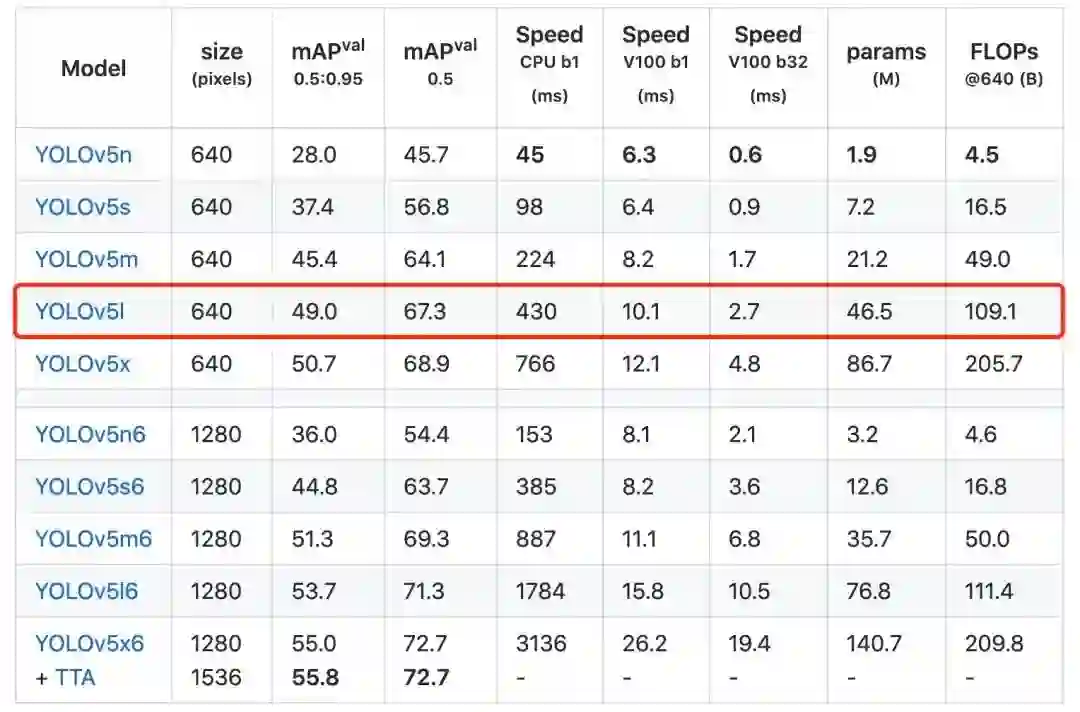
模型的训练:模型的训练沿用 YOLOv5 的默认配置即可,模型输入设定为 640。
3.推理部署
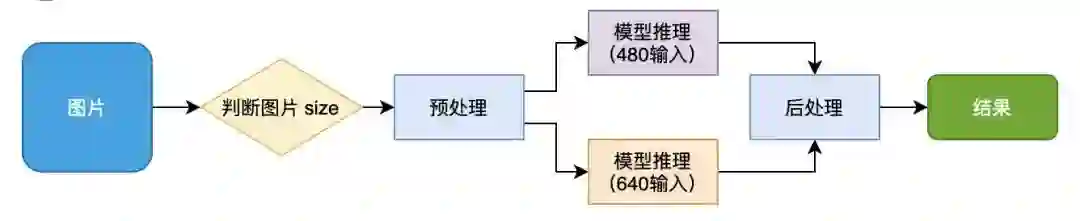
模型的推理用到了数据分析环节里关于 “瘦高” 和 “矮胖” 尺度图片的分析,将训练好的模型初始化为两个不同输入大小的模型,即 480 的输入用于处理目标数少且目标大的 “瘦高” 尺度图片,640 的输入用于处理目标数多且目标较小的 “矮胖” 尺度图片。最终部署阶段采用 TensorRT 框架进行部署加速
YOLOv5 的 TensorRT C++ 部署代码推荐参看 https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
4.结果展示
| 模型 | 召回率 | 精确率 | F1-Score | FPS |
|---|---|---|---|---|
| YOLOv5s(Python) + 14class | 0.6723 | 0.9968 | 0.803 | 85.97 |
| YOLOv5s(Python) + 8class(两组分类) | 0.78 | 0.9767 | 0.8686 | 85.25 |
| YOLOv5l(TensorRT C++) + 8class | 0.8546 | 0.9467 | 0.8983 | 93.21 |
| YOLOv5l(TensorRT C++) + 8class + (640 + 480) | 0.8735 | 0.9547 | 0.9123 | 108.5 |
注:此处的结果是笔者所在团队在 2020首届珠港澳人工智能算法大赛 短袖短裤识别竞赛中使用本文的方法测试记录的部分结果,因为竞赛中的数据标签还有一类 unsure 的情况,而打榜中的数据集去除了 unsure 的情况,故此处的 14class 对应本文中直接用多目标检测的方法中的 8 个类别数的情况,8class 对应的是本文中分为两组分类的目标检测方法,这里附上的结果仅供参考。
讨论与总结
短袖短裤识别任务和其他榜单的目标检测任务稍有不同,在于每个目标的标签数是可变的,而本文的方法依然基于传统目标检测的思想,只不过在目标的分类阶段,划分了两个独立的分类器依次对上衣和裤子的类别进行识别,取得了较好的性能。另外在部署阶段,使用两个不同输入大小的模型,针对性地处理两种尺度的图像,进一步优化了整体的推理速度,在其他的打榜过程中也值得思考和使用。
算法(项目)打榜实战训练营4期【免费】 正在进行中(3.1-3.30)!
-
“ 烟雾识别、快递爆仓识别、客流统计、打架识别”4个项目-3位冠军导师群内 提供1对1算法开发指导+冠军方案(源码)教程输出。 -
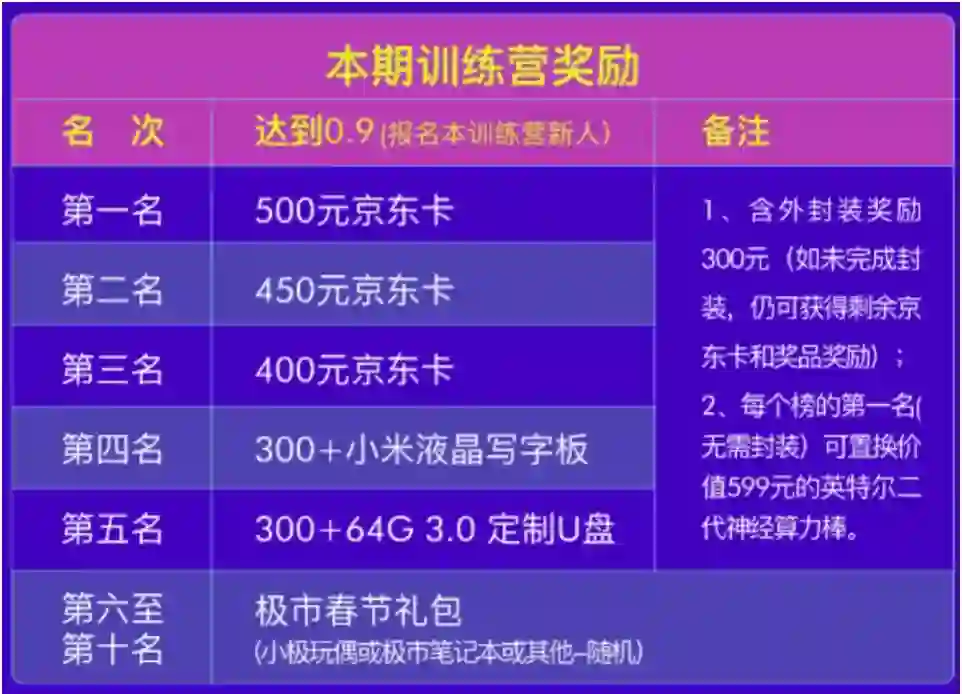
每个榜新增10个奖励名额(奖励如下图)。 -
每个入围且打榜分数位于排行榜前3的开发者,均可优先获得2022年度的打榜分成订单。
目前客流统计、快递爆仓各剩余10个新人奖励名额;打架识别剩余8个新人奖励名额;烟雾识别剩余6个新人奖励名额

扫码,选择自己感兴趣的算法报名,&进入学习群


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




