干货:142页"ICML会议"强化学习笔记整理(2018 & 2019年)-值得细读
来源:David Abel
编辑:DeepRL
ICML 是 International Conference on Machine Learning的缩写,即国际机器学习大会。ICML如今已发展为由国际机器学习学会(IMLS)主办的年度机器学习国际顶级会议。其中强化学习便是该会议很重要的一个话题,每年都有非常多的投稿。本文整理了David Abel总结的ICML2018,2019两年的深度强化学习笔记,详看正文。
ICML-2019-RL-Note



前言
作者整理简介: 我在本次会议的RL分场上度过了大部分时间(可惜错过了所有主题演讲), 所以我的大部分反思(和笔记)都集中在RL:
关于非策略评估和非策略学习的大量工作(例如,参见Hanna 等人[35],Le等人[49],Fujimoto等人[26],Gottesman等人的工作)等[32]
探索再次成为一个热门话题(参见Mavrin等人[57],Fatemi等人[25],Hazan等人[37],Shani等人[76]的工作)。除了策略评估(以及其他一些评估),这也是RL中的基本问题之一。
一些非常好的工作继续澄清分布式RL [10](参见[74,57,67]的工作)。
作者认为我们需要标准化RL中的评估。并不是说我们只需要一个单一的方法或一个域,而是目前评估协议中有太多差异。
元学习&元强化学习
元学习算法通用方法
Choose a form of Pr(φi | Dtrain i , θ).
Choose how to optimize θ with respect to max-likelihood objective using Dmeta-train.
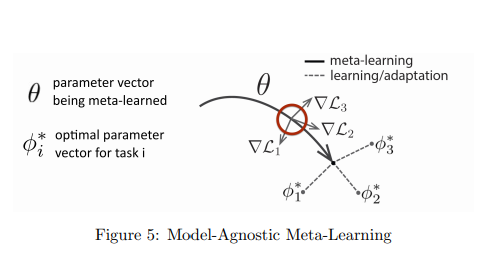
为什么元强化学习有用?
几乎所有问题都与现有方法的样本效率低下有关。将TRPO应用于真正的机器人时,机器人需要花费数天或数周的时间才能开始取得任何进展(学习步行)。
通常情况下,智能体的目标是学习一个策略最大化累计期望奖励
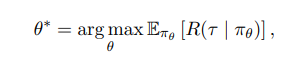
而且,RL目标的元学习问题是学习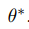

其优化过程如下:

当然元学习有它的优势,也有对应的挑战
挑战1:超量配置:元学习需要任务分配,一些元学习方法可能会过度适合这些任务分配。
挑战2:任务设计:通常必须手动选择这些任务分配,或者它们的多样性不足以鼓励正确的行为。很难以正确的方式选择任务分配!
挑战3:了解哪种算法过度拟合:许多不同的方法(黑盒,基于优化的非参数方法),但是我们不知道哪种算法最容易遭受元过度拟合。
图强化学习
图模型最近在深度学习中特别的人们,然而在强化学习中也是独领风骚:TibGM: A Graphical Model Approach for RL
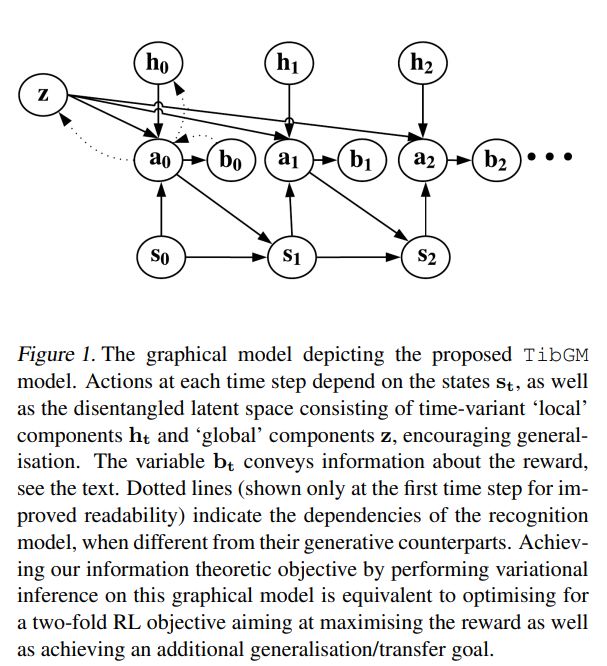

还有包括分布式强化学习,理论等相关内容,详见文末PDF2019
ICML-2018-RL-Note


Github查看(欢迎star仓库):
https://github.com/NeuronDance/DeepRL/tree/master/DRL-ConferencePaper/ICML/Source
百度云:关注公众并回复:icml

深度强化学习实验室
算法、框架、资料、前沿信息等
GitHub仓库
https://github.com/NeuronDance/DeepRL
欢迎Fork,Star,Pull Request
第1篇:通过深度强化学习实现通用量子控制
第2篇:《深度强化学习》面试题汇总





