在机器之心 SOTA!模型启动「虎卷er行动」的第五天,我们解锁最后一套「年度回顾」复习资料「刷爆基准的 SOTA 工作」,帮助老伙计们回顾12个在过去的2021年在国际上引起普遍反响的 SOTA 工作。
1、阿里达摩院提出半监督视频目标分割新算法 LCM,在 DAVIS 和 Youtube-VOS 基准实现最优性能
基准:DAVIS 2017( 83.5% )、DAVIS 2016( 90.7 %)、Youtube-VOS ( 82.0 %)
视频目标分割 (Video Object Segmentation,VOS) 是计算机视觉的基础任务,广泛应用于视频编辑、内容生产、自动驾驶等领域。
其中,半监督视频目标分割,是指给定一段视频和第一帧的目标物体,在视频的所有剩余帧中分割出该物体。在一个视频序列中,目标物体往往会因为连续运动和视角变化发生很大的外观改变,包括形变和遮挡。同时视频中往往会有和目标相似的其他物体存在,使得分辨目标更加困难。因此,视频目标分割是一个比较有挑战性的问题,至今还没有很好的解决。
从最近的研究成果来看,Memory-based 的方法是目前 VOS 领域性能表现最佳的一类方法。
为了进一步提升 Memory-based 的 VOS 方法,该研究提出从两个方面去改进:
一、位置一致性。目标物体在视频帧间的运动是遵循一定轨迹的,如果在某一帧的一些位置出现和目标物体相似的同类物体,如果其位置不合理,那么该物体是目标物体的可能性就会降低,不应该被分割。
二、目标一致性。视频目标分割本质上也可以理解为是一个像素级别的物体跟踪。虽然分割是像素级的任务,但 VOS 的处理对象是物体(object),需要有一个类似图像实例分割中对于物体级别的约束。显然那些错误的碎块分割结果是不满足一个目标物体整体的概念的。
阿里巴巴达摩院在此基础进行改进,提出的LCM在 DAVIS 2017( 83.5% )、DAVIS 2016( 90.7 %)、Youtube-VOS ( 82.0 %)数据集上取得了 SOTA 结果。
文献地址:https://arxiv.org/pdf/2104.04329.pdf
2、字节跳动提出 GLAT(Glancing Transformer),获 WMT 2021 大语种德英自动评估第一
基准/数据集:WMT14 EN-DE/DE-EN and WMT16 EN-RO/RO-EN
作为世界顶级的机器翻译比赛,WMT 大赛自 2006 年以来已经举办了 16 届,每年都会吸引来自世界各地的顶级企业、高校和科研机构参赛。历年参赛队伍来自微软、脸书、腾讯、阿里巴巴、百度、华为等。在 WMT 的各个翻译任务中,火山翻译团队挑战的德英翻译更是参赛队伍角逐的核心项目。
在德语-英语翻译方向上,火山翻译团队仅使用了官方提供的数据(受限资源),成功摘得桂冠。
在本次大赛中,火山翻译团队使用的并行生成技术完全基于自研的 Glancing Transformer 模型(GLAT)。GLAT 提出了一种为并行生成建模词之间依赖关系的有效训练方式,大幅提升了并行生成的效果。GLAT 的 paper 被 ACL2021 接收。
文献地址:https://arxiv.org/pdf/2008.07905.pdf
3、DeepMind 开源 AlphaFold2,预测出 98.5% 的人类蛋白质结构
基准/数据集:AlhaFold Protein Structure 数据集, CAID, CAMEO
DeepMind 开源 AlphaFold2,预测出 98.5% 的人类蛋白质结构。同时,AlphaFold 2 在去年入选 Science 年度十大突破,被称作结构生物学“革命性”的突破、蛋白质研究领域的里程碑。
2018 年的 AlphaFold 使用的神经网络是类似 ResNet 的残差卷积网络,到了 AlphaFold2 则借鉴了 Transformer 架构。
AlphaFold2 利用多序列比对,把蛋白质的结构和生物信息整合到了深度学习算法中。它的出现,能更好地预判蛋白质与分子结合的概率,从而极大地加速新药研发的效率。
文献地址:https://www.nature.com/articles/s41586-021-03828-1
4、谷歌大脑提出全新图神经网络 GKATs,比 9 种 SOTA GNN 更强
Combinatorial Classification; ERDOS-RENYI RANDOM GRAPH WITH MOTIFS
D&D (Dobson & Doig, 2003), PROTEINS (Borgwardt et al., 2005), NCI1 (Wale et al., 2008) and ENZYMES,
IMDB-BINARY, IMDBMULTI, REDDIT-BINARY, REDDIT-5K and COLLAB
从社交网络到生物信息学,再到机器人学中的导航和规划问题,图在各种现实世界的数据集中普遍存在。人们对专门用于处理图结构数据的图神经网络(GNN)产生了极大的兴趣。
尽管现代GNN在理解图形数据方面取得了巨大的成功,但在有效处理图形数据方面仍然存在一些挑战。例如,当所考虑的图较大时,计算复杂性就成为一个问题。相反,在空间域工作的算法避免了昂贵的频谱计算,但为了模拟较长距离的依赖关系,不得不依靠深度GNN架构来实现信号从远处节点的传播,因为单个层只模拟局部的相互作用。
为解决这些问题,谷歌大脑、哥伦比亚大学和牛津大学的研究团队提出了一类新的图神经网络:Graph Kernel Attention Transformers(GKATs)。其结合了图核、基于注意力的网络和结构先验,以及最近的通过低秩分解技术应用小内存占用隐式注意方法的Transformer架构。
该团队证明GKAT比SOTA GNN(Erdős-Rényi随机图、检测长诱导循环和深度与密度注意力测试、生物信息学任务和社交网络数据测试等)具有更强的表达能力,同时还减少了计算负担。
文献地址:https://arxiv.org/pdf/2107.07999.pdf
5、Facebook 推出有史以来第一个赢得 WMT 的多语言模型,并击败了双语模型
在机器翻译(MT)研究领域中,构建一个通用的翻译系统来帮助每个人更好的获取信息和交流是其研究的终极目标。如今,大多数MT系统使用双语模型,这通常需要为每个语言对和任务提供大量标记示例。但是这种方法对于许多冷门的语言训练是有挑战的,例如冰岛语的语言数据集就比较少,从而训练出来的结果也不好,除此之外,即使所有语言的模型都训练出来了,全球有好几百种语言就有好几百个模型,单单考虑模型运行资源来说,这也是不小的成本。
为此Facebook就目前遇到的多语种翻译的问题,提出要构建出通用机器翻译模型。MT 领域应该从双语模型转向多语言翻译——其中一个模型可以同时翻译许多语言对,包括低资源(例如,冰岛语到英语)和高资源 (例如,英语到德语)。多语言翻译是一种特别好的方法——它更简单、更具可扩展性,并且更适合低资源语言。
此次研究成果取得了突破性的进展:在 14 个语言翻译方向:英语往返捷克语、德语、豪萨语、冰岛语、日语、俄语和中文,有10中往返语言翻译,单个多语言模型的表现首次超过了经过专门训练的最佳双语模型,赢得了著名的 MT 竞赛 WMT。Facebook单一多语言模型为低资源和高资源语言提供了最佳翻译,表明多语言方法确实是 MT 的未来。
此次获胜的关键点是,通过大规模数据挖掘、扩展模型容量和更高效的基础设置方面的新进步——多语言模型有可能在高低级别上实现高性能资源语言。它使我们更接近于构建一个通用翻译器,无论存在多少翻译数据,都可以连接世界各地所有语言的人。
文献地址:https://arxiv.org/pdf/2108.03265.pdf
6、百度提出跨模态文档理解模型 ERNIE-Layout,登顶 DocVQA 榜首
方法:跨模态通用文档预训练模型 ERNIE-Layout
对文档理解来说,文档中的文字阅读顺序至关重要,目前主流的基于 OCR(Optical Character Recognition,文字识别)技术的模型大多遵循「从左到右、从上到下」的原则,然而对于文档中分栏、文本图片表格混杂的复杂布局,根据 OCR 结果获取的阅读顺序多数情况下都是错误的,从而导致模型无法准确地进行文档内容的理解。
人类通常会根据文档结构和布局进行层次化分块阅读,受此启发,百度研究者提出在文档预训模型中对阅读顺序进行校正的布局知识增强创新思路。业界领先的文档解析工具能够准确识别文档中的分块信息,产出正确的文档阅读顺序,将阅读顺序信号融合到模型的训练中,从而增强对布局信息的有效利用,提升模型对于复杂文档的理解能力。
基于布局知识增强技术,同时依托文心 ERNIE,百度研究者提出了融合文本、图像、布局等信息进行联合建模的跨模态通用文档预训练模型 ERNIE-Layout。
ERNIE-Layout 创新性地提出了阅读顺序预测和细粒度图文匹配两个自监督预训练任务,有效提升模型在文档任务上跨模态语义对齐能力和布局理解能力,在 4 项文档理解任务上刷新世界最好效果,登顶 DocVQA 榜首。。
文献地址:https://openreview.net/pdf?id=NHECrvMz1LL
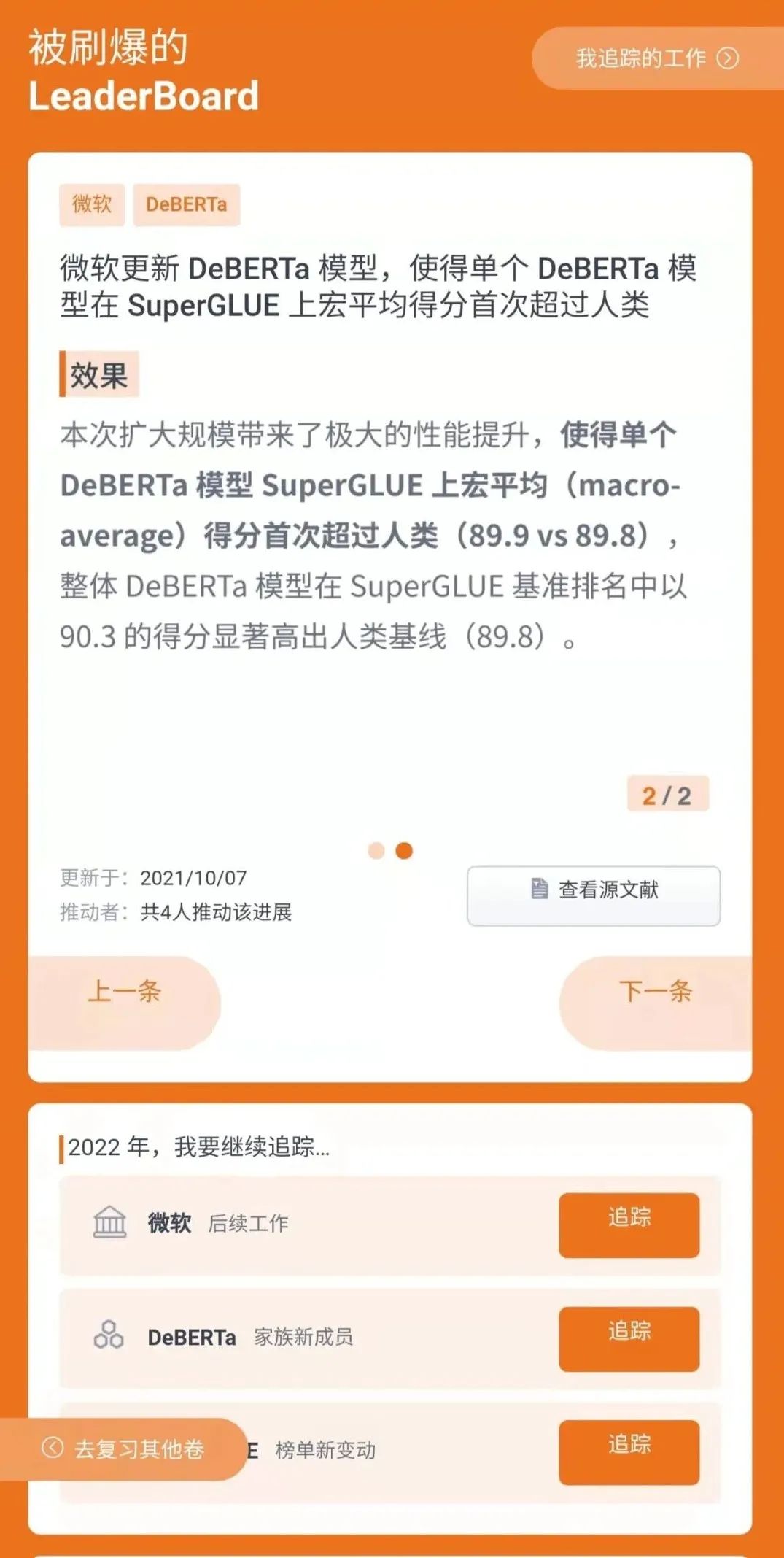
7、微软更新 DeBERTa 模型,使得单个 DeBERTa 模型在 SuperGLUE 上宏平均得分首次超过人类
2020年 6 月,来自微软的研究者提出一种新型预训练语言模型 DeBERTa,该模型使用两种新技术改进了 BERT 和 RoBERTa 模型。2020年8 月,该研究开源了模型代码,并提供预训练模型下载。
2021年1月在这项研究又取得了新的进展:通过训练更大的版本来更新 DeBERTa 模型,该版本由 48 个 Transformer 层组成,带有 15 亿个参数。
本次扩大规模带来了极大的性能提升,使得单个 DeBERTa 模型 SuperGLUE 上宏平均(macro-average)得分首次超过人类(89.9 vs 89.8),整体 DeBERTa 模型在 SuperGLUE 基准排名中居于首位,以 90.3 的得分显著高出人类基线(89.8)。
文献地址:https://arxiv.org/pdf/2006.03654v2.pdf
8、微软提出新 CV 基础模型 Florence,打破分类、检索等多项 SOTA
任务:分类、检索、目标检测、视觉问答(VQA)、图像描述、视频检索和动作识别
方法:Florence(Foundation Model)
面对多样化和开放的现实世界,要实现 AI 的自动视觉理解,就要求计算机视觉模型能够很好地泛化,最小化对特定任务所需的定制,最终实现类似于人类视觉的人工智能。
计算机视觉基础模型在多样化的大规模数据集上进行训练,可以适应各种下游任务,对于现实世界的计算机视觉应用至关重要。现有的视觉基础模型,如 CLIP、ALIGN 和悟道 2.0 等 ,主要侧重于将图像和文本表征映射为跨模态共享表征。
本文出自于微软研究团队,该团队另辟蹊径提出了一种新的计算机视觉基础模型 Florence,将表征从粗粒度(场景)扩展到细粒度(对象),从静态(图像)扩展到动态(视频),从 RGB 扩展到多模态。通过结合来自 Web 规模图像 - 文本数据的通用视觉语言表征, Florence 模型可以轻松地适应各种计算机视觉任务,包括分类、检索、目标检测、视觉问答(VQA)、图像描述、视频检索和动作识别。
此外,Florence 在许多迁移学习中也表现出卓越的性能,例如分类、检索、目标检测、视觉问答(VQA)、图像描述、视频检索和动作识别,这些对于视觉基础模型用于通用视觉任务至关重要。
Florence 在 44 个表征基准测试中多数都取得了新的 SOTA 结果,例如 ImageNet-1K 零试分类任务,top-1 准确率为 83.74,top-5 准确率为 97.18;COCO 微调任务获得 62.4 mAP,VQA 任务获得 80.36 mAP。
文献地址:https://arxiv.org/pdf/2111.11432v1.pdf
9、微软亚研院、北大提出多模态预训练模型 Nüwa,在 8 种包含图像和视频处理的下游视觉任务上具有出色的合成效果
任务:文字转图像,草图转图像,图像补全,文字指示修改图像,文字转视频,视频预测,草图转视频,文字指示修改视频
基准:MSCOCO(256×256), Kinetics, BAIR(64×64)等
微软亚研院、北大提出多模态预训练模型 Nüwa。相比于 GauGAN,「女娲」的生成模式更加多样,不仅有文本涂鸦生成图像,还能从文本生成视频。
「女娲」是一个统一的多模态预训练模型,在 8 种包含图像和视频处理的下游视觉任务上( Text-to-Image 、 Text-to-Video 、 Video Prediction 、 Sketch-to-Image 、 Image Completion zero-shot 、 Text-Guided Image Manipulation (TI2I) zero-shot 、 Sketch-to-Video 、 Text-Guided Video Manipulation (TV2V) zero-shot )具有出色的合成效果。
文献地址:https://arxiv.org/pdf/2111.12417.pdf
10、字节跳动提出适用于视觉任务的大规模预训练方法 iBOT,刷新十几项SOTA,部分指标超 MAE
任务:分类、目标检测、实例分割,语义分割,迁移学习等
基准/数据集: IMAGENET-1K ; COCO ; ADE20K
MAE让人们看到了 Transformer 扩展到 CV 大模型的光明前景,给该领域的研究者带来了很大的鼓舞。
本文提出了适用于视觉任务的大规模预训练方法 iBOT,通过对图像使用在线 tokenizer 进行 BERT式预训练让 CV 模型获得通用广泛的特征表达能力。该方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。
在 NLP 的大规模模型训练中,MLM(Masked Language Model)是非常核心的训练目标,其思想是遮住文本的一部分并通过模型去预测这些遮住部分的语义信息,通过这一过程可以使模型学到泛化的特征。
NLP 中的经典方法 BERT 就是采用了 MLM 的预训练范式,通过 MLM 训练的模型已经被证明在大模型和大数据上具备极好的泛化能力,成为 NLP 任务的标配。
本文主要探索了这种在 NLP 中主流的 Masked Modeling 是否能应用于大规模 Vision Transformer 的预训练。作者给出了肯定的回答,并认为问题关键在于 visual tokenizer 的设计。
不同于 NLP 中 tokenization 通过离线的词频分析即可将语料编码为含高语义的分词,图像 patch 是连续分布的且存在大量冗余的底层细节信息。而作者认为一个能够提取图像 patch 中高层语义的 tokenizer 可帮助模型避免学习到冗余的这些细节信息。作者认为视觉的 tokenizer 应该具备两个属性:
(b) 像 NLP 中的 tokenizer 一样具备高层语义。
文献地址:https://arxiv.org/pdf/2111.07832.pdf
11、FAIR 等提出能用于视频模型的自监督预训练方法 MaskFeat,MaskFeat 的 MViT-L 在 Kinetics-400 上的准确率超过 MAE,BEiT 等方法
任务/类别:视频识别,迁移学习(动作监测,人物互动分类),图像识别
基准:Kinetic-400, Kinetics-600, Kinetics-700, ImageNet-1K
MAE最大的贡献,可能就是将NLP领域和CV两大领域之间架起了一座更简便的桥梁:把NLP领域已被证明极其有效的方式:「Mask-and-Predict」,用在了计算机视觉(CV)领域,先将输入图像的随机部分予以屏蔽(Mask),再预测(Predict)丢失的像素(pixel)。
「Mask-and-Predict」总要有个可以「Predict」的特征来让模型学习到东西。
MaskFeat最核心的改变就是将MAE对图像像素(pixel)的直接预测,替换成对图像的方向梯度直方图(HOG)的预测。方向梯度直方图(HOG)这个点子的加入使得MaskFeat模型更加简化,在性能和效率方面都有非常出色的表现。
文献地址:https://arxiv.org/pdf/2112.09133.pdf
12、谷歌、罗格斯大学提出 NesT,超越 Swin Transformer
尽管分层结构在Vision Transformer领域非常流行,但它需要复杂设计以及大量的数据才能表现够好。
本文是谷歌&罗格斯大学的研究员在Vision Transformer的一次尝试,对ViT领域的分层结构设计进行了反思与探索,提出了一种简单的结构NesT:它在非重叠图像块上嵌套基本transformer,然后通过分层方式集成。
所提方法不仅具有更快的收敛速度,同时具有更强的数据增广鲁棒性。更重要的是,所提方法凭借68M参数取得了超越Swin Transformer的性能,同时具有更少(仅43%)的参数量。
文献地址:https://arxiv.org/pdf/2105.12723.pdf
在SOTA!
模型推出的「虎卷er行动」中,我们基于2021年度国际AI顶会「Best Papers」、重要SOTA工作,形成总计五十道年度大题。
具体分布如下:
答题通道现已开启!扫描下方二维码,进入「机器之心SOTA!模型」服务号,点击菜单栏即可开始答题。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com