神经网络剪枝技术研究指南(2019)
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Derrick Mwiti 译者:McGL
https://zhuanlan.zhihu.com/p/92123471
本文已由作者授权,未经允许,不得二次转载
剪枝是最常用的神经网络压缩方法。最近GitHub开源了不少YOLOv3剪枝实现,不过基本上都是基于2017年经典论文"Learning Efficient Convolutional Networks through Network Slimming", 2019年剪枝研究又有了什么新的进展?哪些会在工业界开花结果呢?
Research Guide: Pruning Techniques for Neural Networks
[Nearly] Everything you need to know in 2019 by Derrick Mwiti
https://heartbeat.fritz.ai/research-guide-pruning-techniques-for-neural-networks-d9b8440ab10d
剪枝(Pruning)是深度学习的一种技术,目标是为了开发更小、更高效的神经网络。 这是一种包括去掉权重张量中多余的值的模型优化技术。 压缩后的神经网络运行速度更快,还减少了训练网络的计算成本。 这在部署模型到手机或其它边缘设备时尤为关键。 在本篇指南中,我们将介绍神经网络剪枝领域的一些研究论文。
Pruning from Scratch (2019)
https://arxiv.org/abs/1909.12579
论文的作者提出了一个允许网络from scratch剪枝的流程。 对 CIFAR10和 ImageNet 数据集进行的压缩分类模型实验证明了这个流程减少了常规剪枝方法的预训练开销,并提高了网络精度。
下面是传统剪枝过程的三个阶段的说明。 这个过程包括预训练、剪枝和微调。
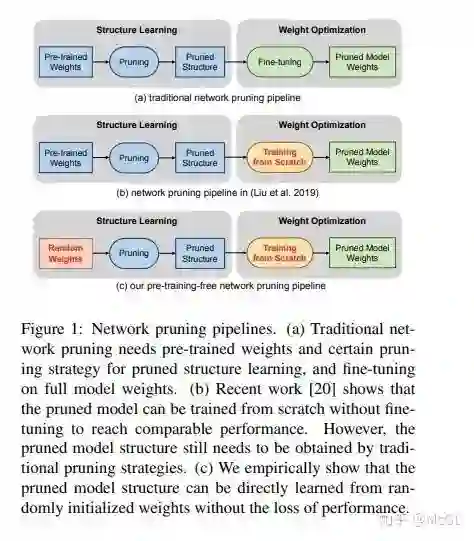
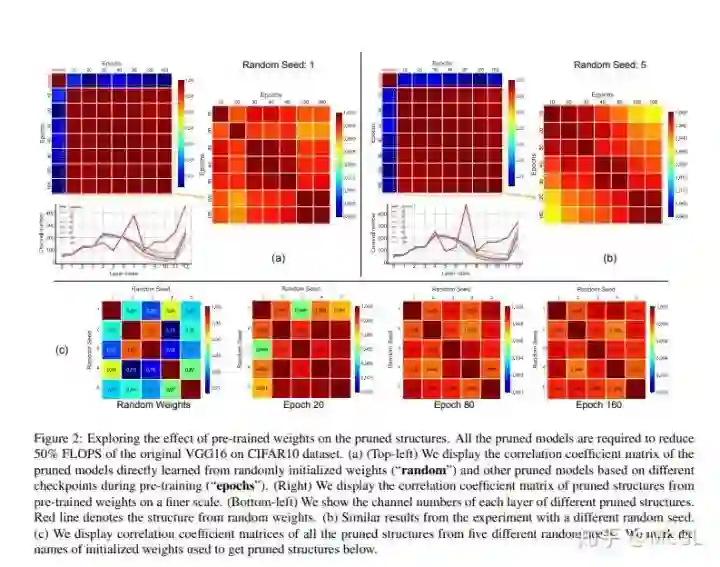
论文提出的剪枝技术包含了构建一个可以从随机初始权重中学习的剪枝流程。 通过将scalar gate值与每个网络层关联来学习channel的重要性。
在稀疏正则化条件下,通过优化channel重要性来提高模型的性能。 在此过程中,随机权重不更新。 然后,在给定资源约束条件下,采用二分搜索策略确定剪枝后模型的channel数配置。
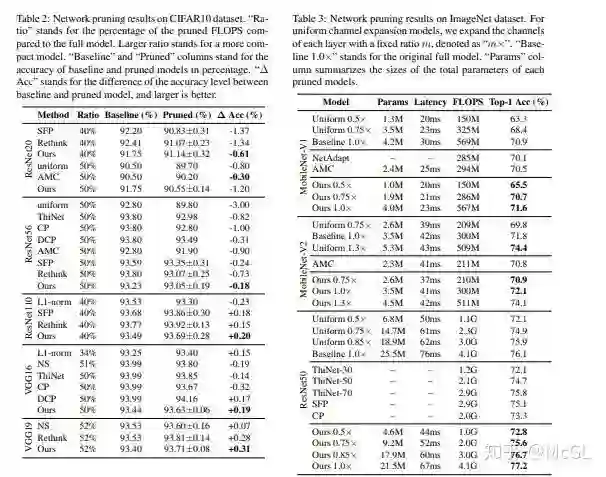
以下是不同数据集的模型准确率:
Adversarial Neural Pruning (2019)
https://arxiv.org/abs/1908.04355
本论文研究了网络潜在特征在对抗性扰动下的畸变(distortion)问题。 该方法通过学习贝叶斯剪枝mask来抑制较高畸变的特征,从而最大化对抗方差的鲁棒性。
作者考虑了深层神经网络中潜在特征的脆弱性。 该方法在保留鲁棒特征的同时,去除了易受攻击的特征。 这是通过在贝叶斯框架中对抗学习剪枝mask来完成的。
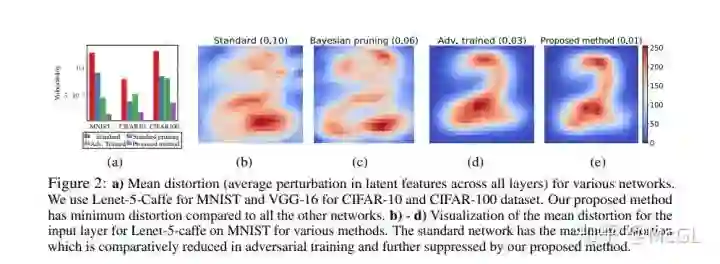
对抗神经剪枝(Adversarial Neural Pruningf/ANP)结合了对抗性训练的概念和贝叶斯剪枝方法。 这种方法的baseline是:
一个标准卷积神经网络
对抗训练的网络
用beta-Bernoulli dropout进行对抗神经剪枝
对抗训练的网络用vulnerability suppression loss 正则化
对抗神经剪枝网络用vulnerability suppression loss 正则化
下面的表格展示了模型的性能。
Rethinking the Value of Network Pruning (ICLR 2019)
https://arxiv.org/abs/1810.05270v2
本论文提出的网络剪枝方法分为两大类。 目标剪枝模型的结构由人或剪枝算法决定。 在实验中,作者还比较了预定义和自动方法下,from scratch训练剪枝模型和从继承的权重finetune的结果。
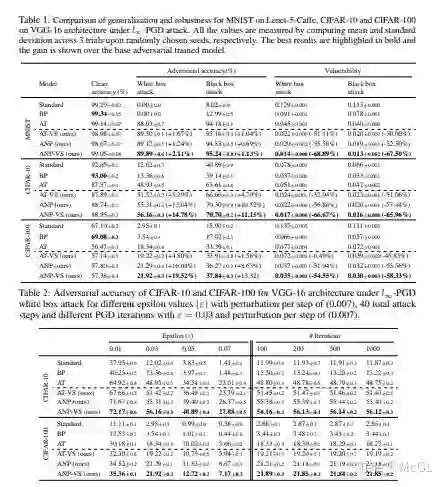
下图显示了使用基于 l1范数的filter剪枝实现预定义结构化剪枝的结果。 每一层涉及剪枝一定比例的l1范数较小的filter。 Pruned Model 列表示用于配置每个模型的预定义目标模型列表。 观察每一行的结果可以看到,从头训练的模型的准确率至少和微调的模型相同。
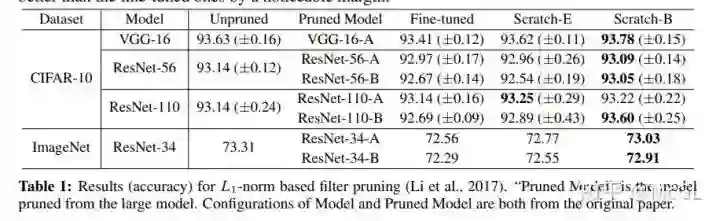
如下所示,ThiNet 贪婪地剪掉对下一层的激活值影响最小的channels。
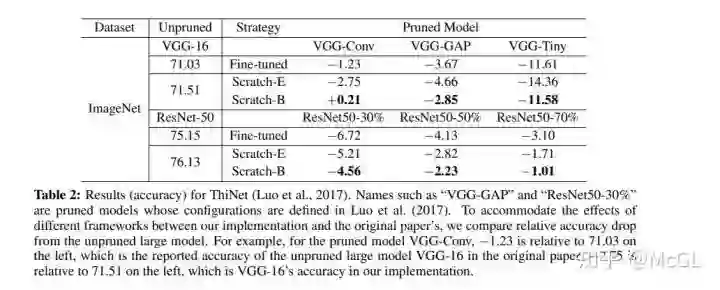
下表显示了基于回归的特征重建所得到的结果。 该方法通过最小化下一层feature map 的重建误差来剪掉channels。 这个最佳化问题是通过 LASSO 回归解决的。
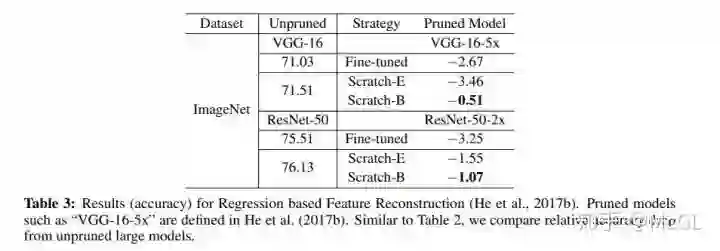
对于网络瘦身,在训练过程中,l1稀疏化施加在Batch Normalization的channel缩放因子上。 它会剪掉缩放因子小的channels。 因为channel缩放因子是跨层比较的,这种方法产生了自动发现的目标网络结构。
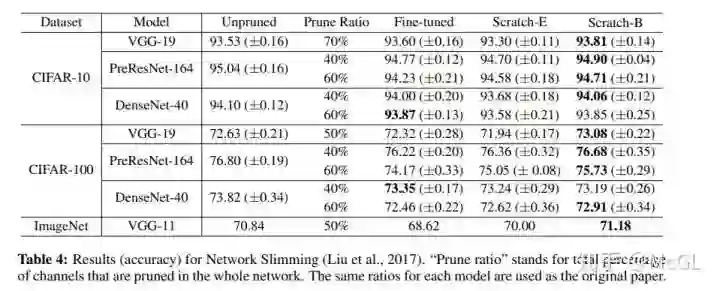
Network Pruning via Transformable Architecture Search (NeurIPS 2019)
https://arxiv.org/abs/1905.09717v5
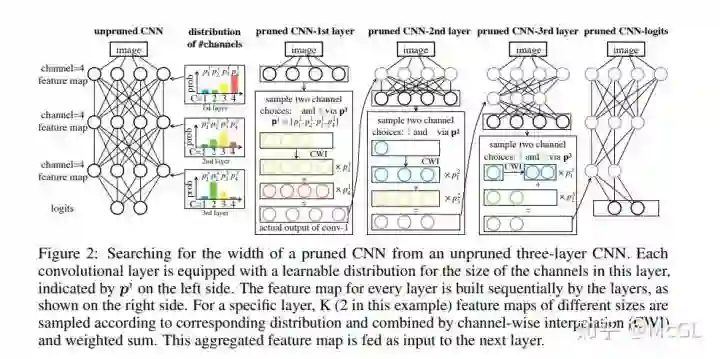
本论文提出将神经网络结构搜索(neural architecture search)直接应用于具有弹性channel和层尺寸的网络。 通过最小化剪枝后网络的损失来学习channel的数量。 剪枝后网络的feature map是由基于概率分布的 K个feature map片段组成的。 损失将反向传播到网络权重和参数化分布。
剪枝后网络的宽度和深度根据每个分布中网络大小的最大概率得到。 这些参数是通过knowledge transfer从原始网络中学习到的。 模型在 CIFAR-10、 CIFAR-100和 ImageNet 上进行了实验。
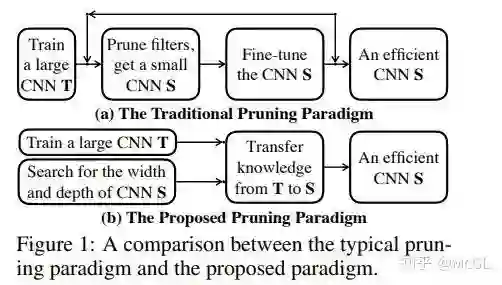
这种剪枝方法包括三个阶段:
用标准分类训练程序训练未剪的大型网络。
通过可变换结构搜索(Transformable Architecture Search/TAS)搜索小型网络的深度和宽度。 TAS 的目标是寻找一个网络的最佳规模。
利用简单的知识蒸馏(knowledge distillation)方法,将未剪枝网络中的信息传输到搜索到的小型网络中。
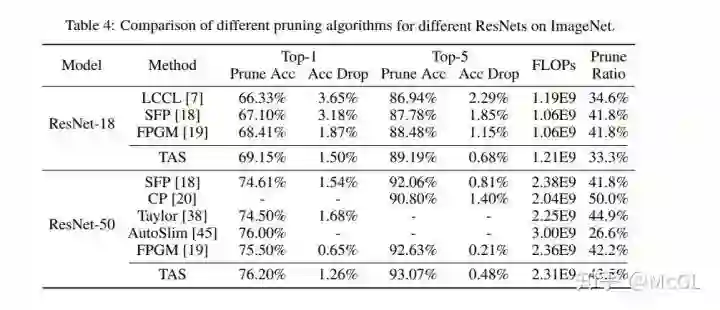
下面是 ImageNet 上不同 ResNets 的不同剪枝算法的比较:
Self-Adaptive Network Pruning (ICONIP 2019)
https://arxiv.org/abs/1910.08906
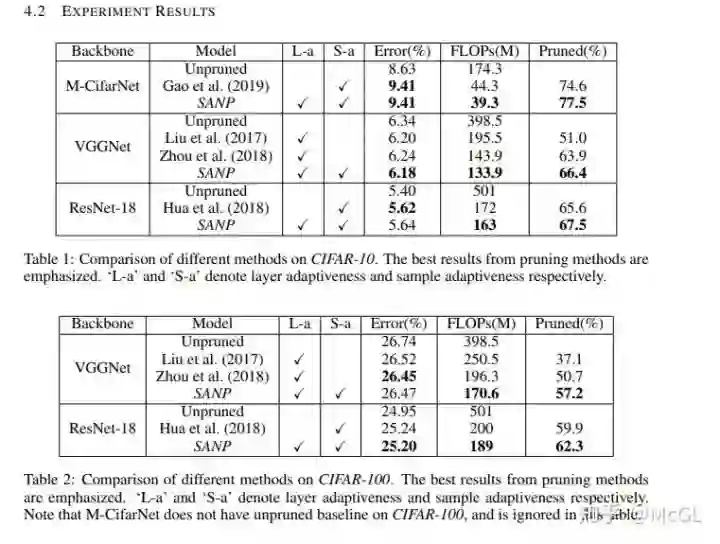
本论文提出了一种自适应网络剪枝方法(SANP)来降低 CNNs 的计算量。 该方法通过为每个卷积层引入一个显著性剪枝模块(SPM)来实现。 这个模块学习预测显著性分数,并应用剪枝到每个channel。 SANP 决定了每个层和每个样本的剪枝策略。
如下面的结构图所示,显著性和剪枝模块(SPM)嵌入在卷积网络的每一层中。 该模块可以预测channels的显著性评分。 这是基于输入特性完成的。 之后生成每个channel的剪枝决策。
对于相应剪枝决策为0的channels,跳过卷积操作。 backbone网络和SPMs根据分类和cost目标进行联合训练。 计算成本会根据每一层的剪枝决策来估计。
这种方法的一些试验结果如下:
Structured Pruning of Large Language Models (2019)
https://arxiv.org/abs/1910.04732
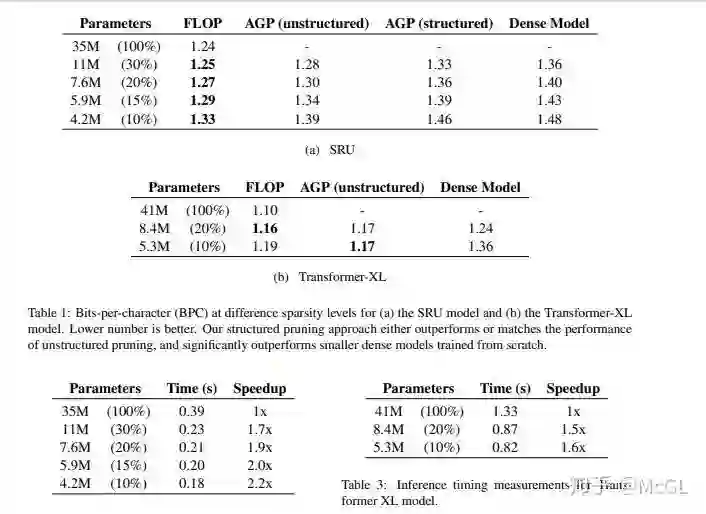
本文提出的剪枝方法是基于低秩分解(low-rank factorization)和增强的拉格朗日10范数正则化(augmented Lagrangian 10 norm regularization)。 10正则化方法放宽了结构化剪枝带来的约束,而低秩分解方法保证了矩阵的稠密结构。
正则化使网络能够选择要移除的权重。 权重矩阵被分解成两个较小的矩阵。 然后在这两个矩阵之间设置一个对角线mask。 在训练期间通过10正规化修剪mask。 采用增强拉格朗日方法控制模型的最终稀疏度。 作者称他们的方法为 FLOP (Factorized L0 Pruning)。
使用的字符级语言模型是 enwik8数据集,其中包含来自 Wikipedia 的100M 字节数据。 在 SRU 和 Transformer-XL 上对 FLOP 进行了评估,得到的结果如下所示。
总结
我们现在应该已经了解了一些最常见,最新的剪枝技术。
上面提到的论文大部分包含代码实现。 希望能看到你们测试后的结果分享。
重磅!CVer-模型剪枝交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如模型剪枝+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



