[IJCV 2020] 融合自下而上和自上而下处理的残差双尺度场景文本识读方法

本文简要介绍来自中国科学院自动化所近期的一篇论文“Residual Dual Scale Scene Text Spotting by Fusing Bottom-Up and Top-Down Processing”,此论文已被IJCV录用,它主要解决了自然场景图像中任意形状文本的端到端识别问题。
针对任意形状场景文本端到端识别的方法可以被大致分为自底向上和自顶向下两类。自底向上的方法[1]将文本行看作局部区域的组合,通过首先检测和识别局部区域,之后将结果融合的方式完成端到端识别。然而,其中的融合操作容易受到粘连问题的影响,如Fig.1 (a)所示。与自底向上的方法不同,自顶向下的方法[2,3]首先检测图中所有文本行感兴趣区域,之后在感兴趣区域内部进行多边形拟合以及文本识别。因此,这类方法可以直接检测文本行区域,而不需要对局部区域进行融合。然而,这些方法需要足够大的感受野来覆盖文本行区域。当文本行较长时,一个文本行容易被错误的分成几个独立的区域,如Fig.1 (b)所示。
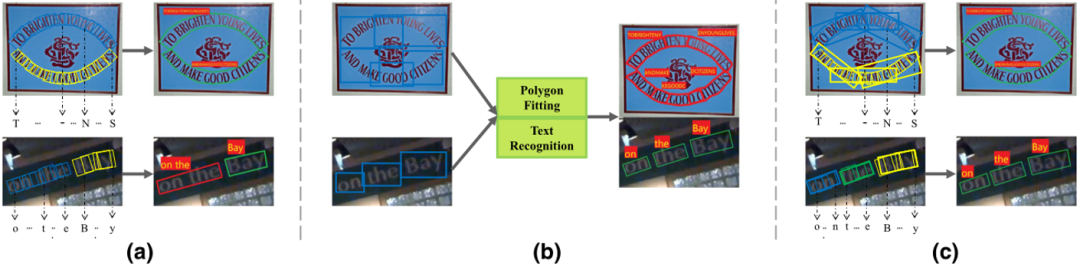
融合自底向上和自顶向下的方法可以提升任意形状端到端识别结果,如Fig.1 (c)所示。一方面,自顶向下的方法中的文本行感兴趣区域可以提供文本行的边界信息。尽管相邻文本行间的局部区域距离很近,但是他们的文本行感兴趣区域有着很低的IoU。因此,自顶向下方法中的文本行感兴趣区域是区分相近文本行的有力依据。另一方面,自底向上方法中的局部区域不受感受野的限制。尽管感受野难以覆盖长文本行,但是通过聚合局部区域的方式,仍然可以获得完整的文本边框。因此,自底向上的方法能够更好地适应多种形状的文本行。
Fig.2是作者提出的端到端识别模型的整体结构。其中,两个端到端识别器在不同尺度的特征上工作,第二个识别器学习第一个的残差。在每个端到端识别器中,一个基于自底向上的检测器将文本行看作一系列旋转矩形的组合。此外,一个基于自顶向下的检测器用最小包围旋转矩形来表示感兴趣区域。通过利用两个检测器的互补信息,最终的文本检测结果融合自顶向下和自底向上的结果。之后利用[1]中提出的RoISlide特征提取器和文本识别器得到识别结果。
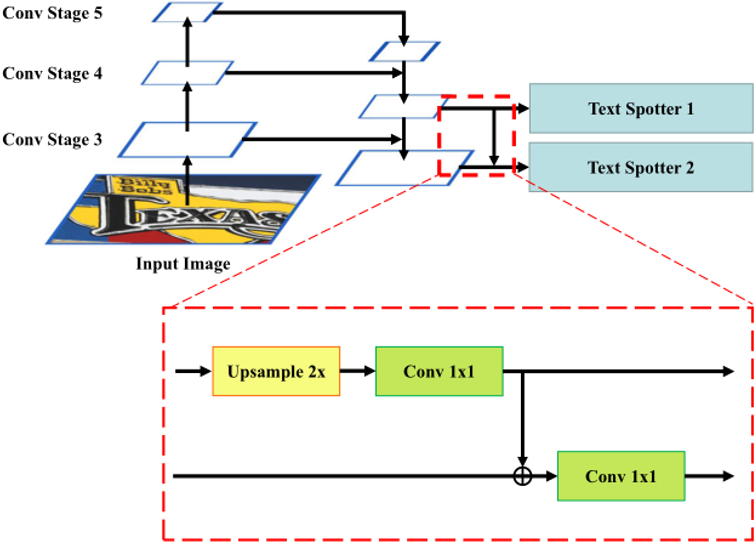
关于残差双尺度端到端识别机制,本文采用双尺度端到端识别器来处理场景文本中的尺度变化问题。其中第一个尺度的端到端识别器目的是最大化识别性能,之后第二个识别器能够更专注解决第一个识别器无法处理的文本行。所提出的残差双尺度结构如Fig.3所示,对于第一个尺度的端到端识别器,输入的视觉特征是由Conv Stage 4到Stage 5融合得到的。第二个尺度的端到端识别器的输入特征是从Conv Stage 3到Conv Stage 5融合得到的。由于识别器需要更细粒度的特征,因此两个识别器的输入特征都上采样到原图的1/4大小。和之前的方法不同,本文使两个识别器不再独立工作,而是第二个识别器是基于第一个识别器的残差。
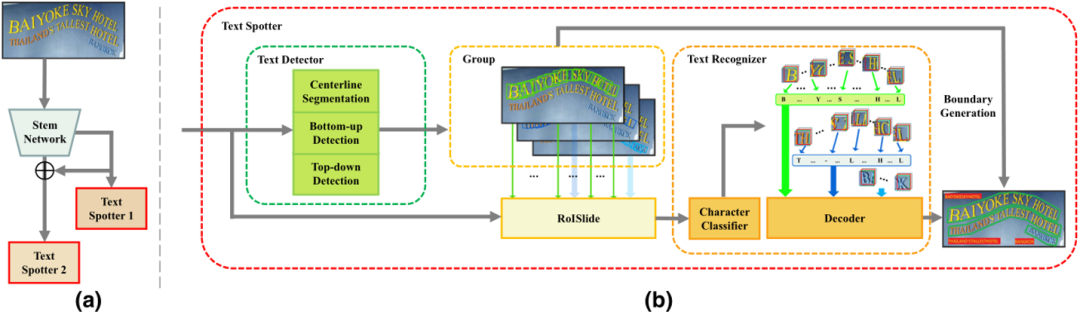
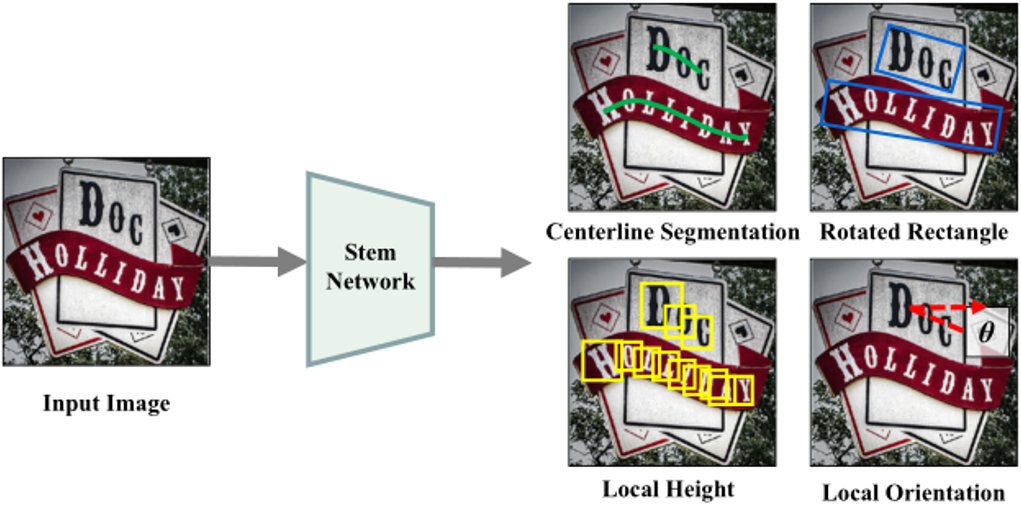
关于任意形状文本检测器,本文采用预测文本行局部几何特征的方式。并增加了自顶向下的检测器来解决相邻文本行的粘连问题。检测器的输出如Fig.4所示。检测器主要包含三个任务:第一个任务是中心线分割任务,这个任务可以被看作像素级别的分类任务。第二个任务是自底向上的检测任务,这个任务的目的是描述文本行的局部几何特征,包含局部高度和局部角度。最后一个任务是自顶向下的检测任务,这个任务用旋转矩形的形式来表示文本行感兴趣区域,被检测到的文本感兴趣区域将在推理阶段带来更好的分词效果。
关于RoISlide和识别器模块,本文采用和[1]中相同的结构和方法。联合检测和识别的损失,整个框架的损失函数可以写作:
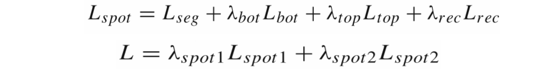
关于网络的推理部分,本文首先得到每个尺度的端到端识别器的检测和识别结果,之后对检测结果进行NMS,保留对应的检测结果和识别内容。在每个端到端识别器中,本文采用如Fig.5所示的推理流程。和[1]中的推理方法不同的是,在聚合操作中,本文没有采用连通域分离或者启发式的规则,而是采用了自顶向下检测器来聚合局部单元,这使得该方法融合了自顶向下和自底向上检测器的输出。给定两个像素点i和j,将他们对应的旋转正方形和旋转矩形表示为[Ri,Gi]和[Rj,Gj]。如果Gi和Gj的IoU超过了阈值Thg,就将Ri和Rj聚合成一组。当数据集按行级别标记时,Thg设为0.2。当数据集按词级别标记时,则将Thg设为0.5。这样的设定出于两点考虑,一方面相邻文本行的局部正方形很容易被错误地聚成一组,所以较高的阈值可以很好的解决词级别标注中的粘连问题;另一方面,长文本行的全局旋转矩形很可能被分割成多个独立的部分,因此对于行级别标注的数据,采用较低的阈值可以克服感受野的限制。
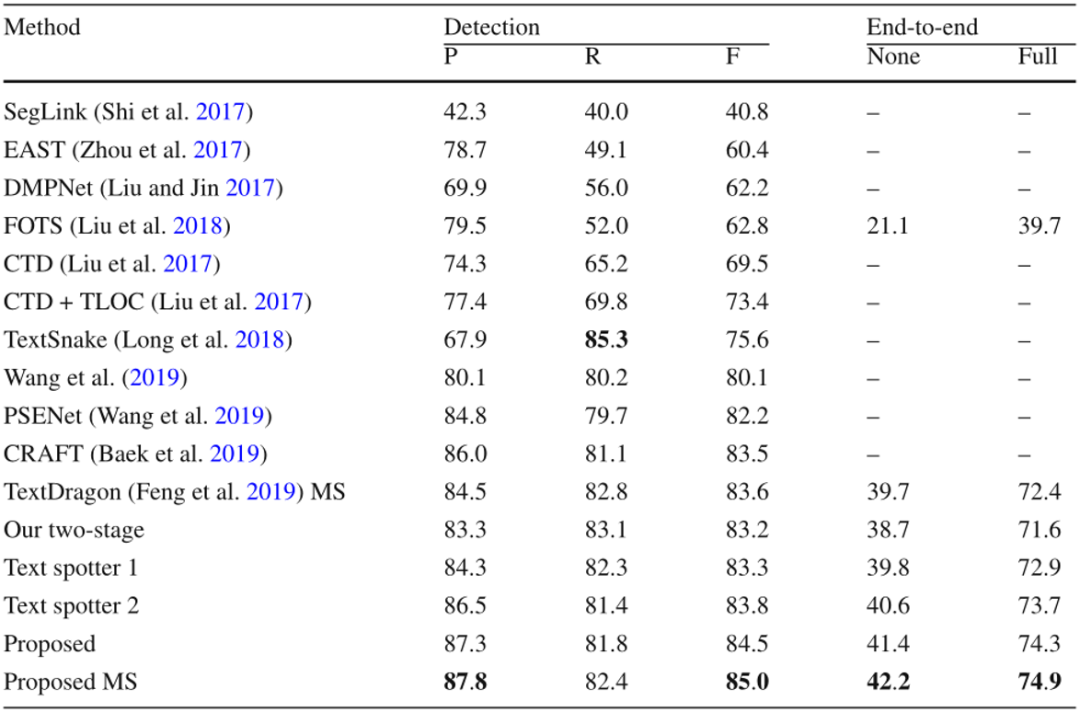
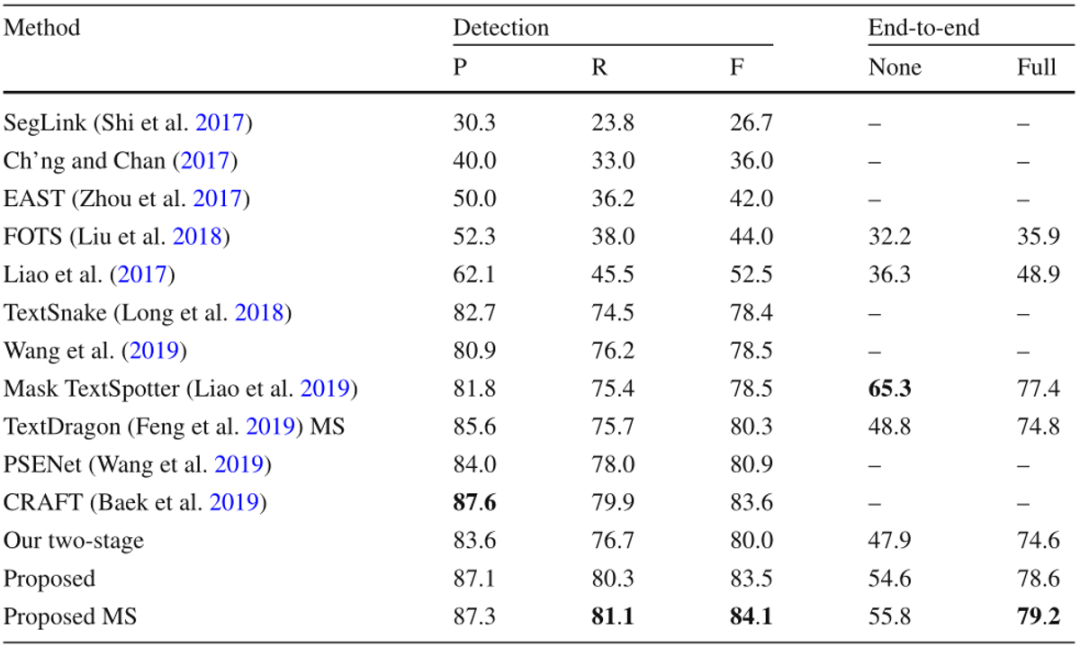
本文在五个公开数据集上评价了提出的方法,包含两个任意形状文本数据集和三个多方向数据集,其中四个是英文数据集,另一个数据集主要包含中文。如Table 1所示,文中的方法在CTW1500上达到了最佳的性能,尽管CTW1500包含很多长文本行,但是所提出的自底向上检测器不受感受野的限制。这使得该方法相对于基于自顶向下的方法有明显的优势。文中的方法同样在Total-Text达到了最佳性能,如Table 2所示。由于Total-Text要求词级别的检测,所以这个数据集的难点在于区分相邻的文本行。受益于所提出的自顶向下检测器,该方法可以很容易的区分相邻的文本行,使该方法不受粘连问题的影响。如Table 3,4,5所示,该方法同样在三个多方向数据集上获得了最佳的性能。尽管该方法是针对任意形状文本行设计的,但是和之前针对四边形文本设计的方法相比,该方法取得了更佳的性能。此外在中文数据集CASIA-10K上,尽管中文文本行尺度变化更为丰富,所提出的残差双尺度机制使该方法对尺度变化更鲁棒,结果显示该方法可以同时处理中文和英文。
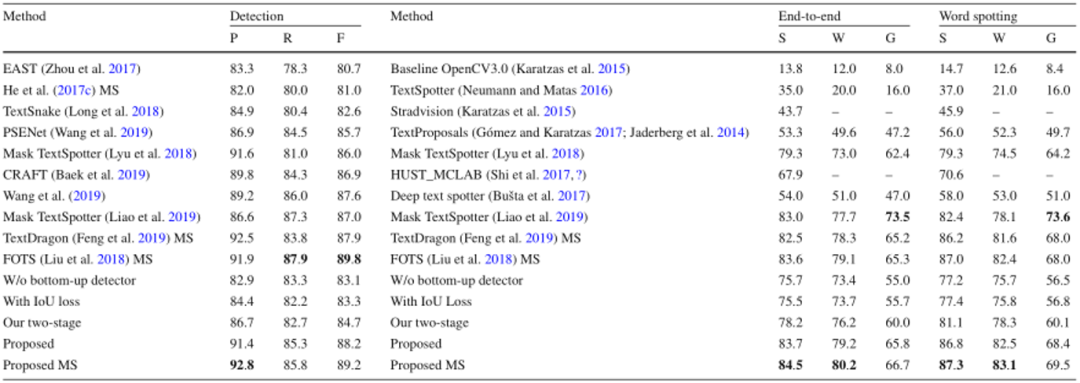
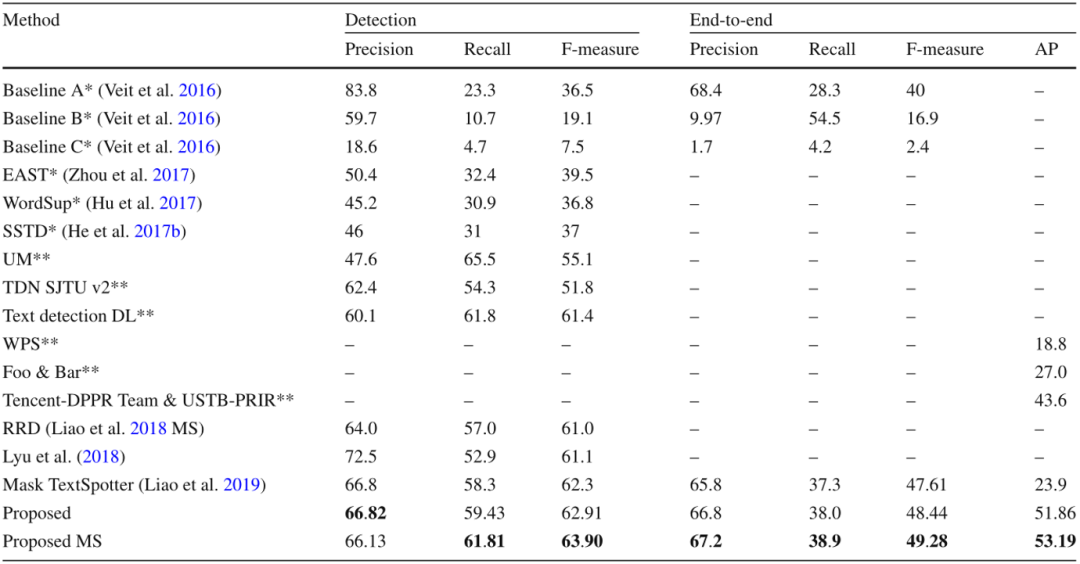
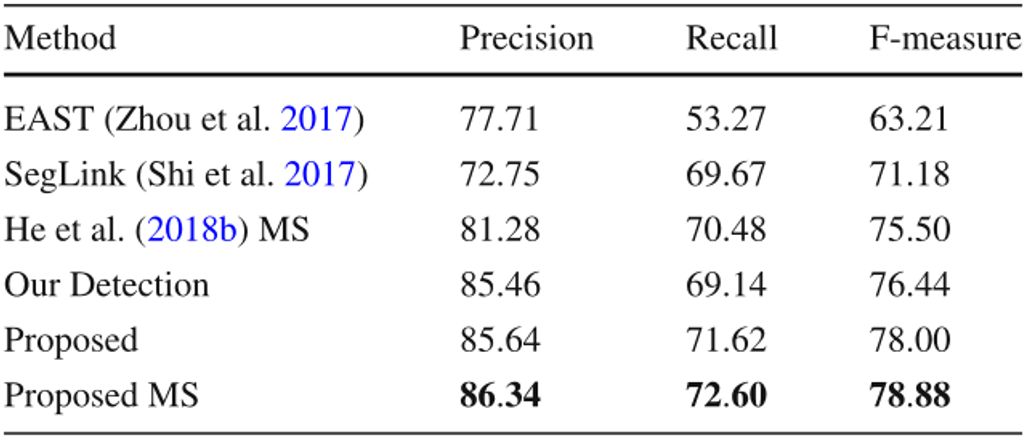
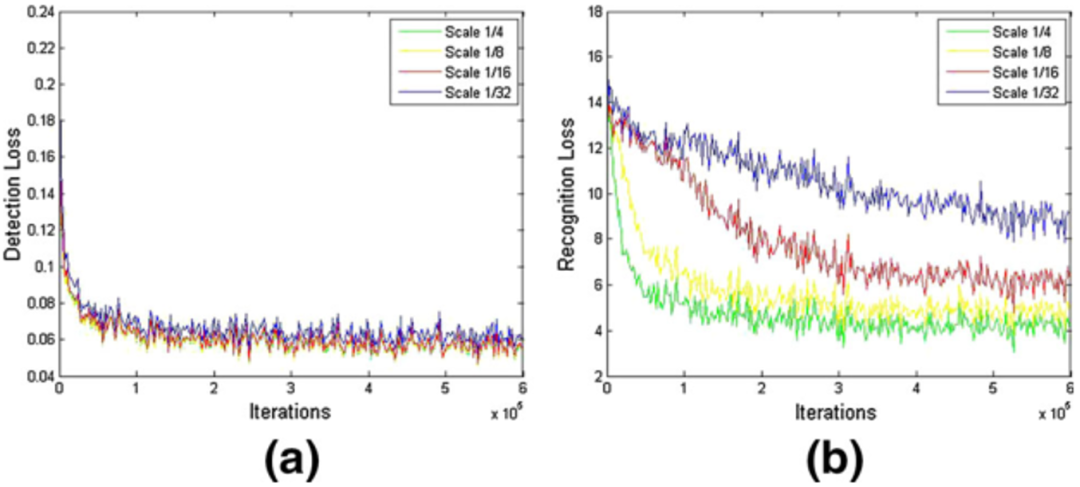
为了验证融合自底向上和自顶向下的优势,还有残差双尺度机制的有效性,本文做了一些消融实验如Table 6所示。结果表明,本文所提出的自顶向下检测器和自底向上检测器可以很好的相互促进,联合训练两种检测器使得该方法不受感受野的限制,同时避免了粘连问题。本文也验证了所提出的残差双尺度机制优于并行的双尺度机制,也优于人工设定的尺度分配机制,证明了双尺度机制的优越性。同时,为了验证尺度大小对检测和识别的影响,本文评估了该方法的一个变种,包含了1/4到1/32的四个尺度,检测和识别的损失函数曲线如Fig 6所示。可以看出每个尺度检测损失差别不大,但是识别任务的损失差距很大。同时,本文还衡量了不同尺度的识别器的行正确率,1/4和1/8尺度的行正确率差别小于2%,但是1/4和1/32的行正确率差距大于25%。这证明了文本识别任务需要更高分辨率的特征,因此本文仅仅采用双尺度端到端识别。

原文作者:Wei Feng, Fei Yin, Xu-Yao Zhang, Wenhao He, Cheng-Lin Liu
审校:连宙辉
发布:金连文





