论文浅尝 - AAAI2020 | 通过知识库问答改善知识感知对话生成
论文笔记整理:胡楠,东南大学博士。

来源:AAAI 2020
动机
现在的将外部知识整合到对话系统中的研究仍然存在一定缺陷。首先,先前的方法难以处理某些语句的主语和关系,比如当语句中的相关实体彼此相距较远时。其次,先前的基于生成的方法逐字生成响应,缺乏全局视角导致语句与潜在响应(实体展开)之间的知识联系被忽略了,使得响应中生成的知识(实体)相对于语句而言是不合理的。最后,大多数以前的研究仅通过合并知识库中来丰富实体或三元组以进行生成响应,但是在输入语句确实很短的情况下,很难检索相关事实并产生有意义的响应。
为了解决上述挑战,论文提出了一种知识感知对话生成模型TransDG,该模型可以将知识库中的外部知识有效地融合到seq2seq模型中,从而通过迁移问题建模和知识匹配能力来生成信息性对话。
贡献
文章的主要贡献:
(1)提出了一种新颖的知识感知对话生成模型TransDG,该模型将问题理解和事实提取能力从预先训练的KBQA模型中转移出来,以促进事后理解能力和KB事实知识选择能力。
(2)提出了一种多步解码策略,该策略可以捕获信息和响应之间的知识联系。第一步解码器生成的语句和草稿响应均与KB的相关事实相匹配,这使得第二步解码器生成的最终响应相对于语句更为合适和合理。
(3)提出了一种响应指导注意机制,该机制利用k-最佳响应候选项引导模型关注相关特征。
(4)在真实对话数据集上进行的大量实验表明,从定量和定性的角度来看论文的模型均优于比较的方法。
模型
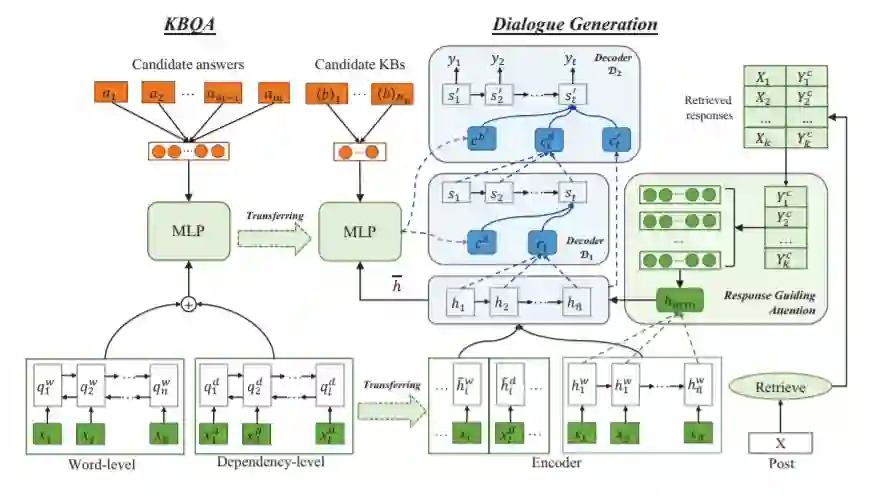
TransDG模型包含两个部分:KBQA模型和对话生成模型,其中从KBQA任务中学到的知识将在编码和解码阶段迁移到对话生成。
KBQA模型:
编码层
问题表示:采用BiGRU获取问题中单词的隐藏状态。同时为了更好地捕获单词的长期依赖关系,使用了依赖路径作为额外的表示,将单词和依赖项标签与方向连接起来,然后应用另一个BiGRU网络来获得依赖级别的问题表示。最后通过填充来对齐单词级和依赖级序列,并通过元素加来合并它们。
候选答案表示:KBQA任务中的候选答案表示为A = {a1, . . . , am},其中每个答案ai都是来自特定KB的事实,以三元组的形式存在。我们在字级和路径级对这些事实进行编码。
语义匹配与模型训练:通过多层感知器计算问题qi和候选答案aj之间的语义相似性评分,在训练过程中,采用hinge loss来最大化正答案集和负答案集之间的距离:
知识感知对话生成模型:
给定一个语句X = {x1, . . . , xn},对话生成的目标是生成一个适当的响应Y = {y1, . . . , ym},其中n和m分别表示语句和响应回答的长度。如模型图所示,对话生成模型从KBQA任务中传输知识,从而促进知识级别的对话理解和KB事实选择。
知识感知编码器:对话生成使用基于Seq2Seq的方法来生成给定语句的响应。Seq2Seq的编码器逐字读取语句 X,通过GRU生成每个单词的隐藏状态。此外,为了促进对语句的理解,通过迁移KBQA任务中的问题表示能力,来获得语句的多层语义理解(即单词级别和依赖级别)。即使用KBQA任务学习到的预训练双向GRU作为附加编码器。
响应指导注意机制:为了丰富语句表示以更好地理解,提出了一个响应引导注意机制,它使用检索到的类似语句的响应来引导模型只关注相关信息。
知识感知多步解码器:知识感知解码器采用多步解码策略,将从预先训练的KBQA模型中学习到的知识选择能力转化为响应。第一步解码器通过整合与语句相关的外部知识来生成草稿响应。第二步解码器通过参考第一步解码器产生的语句、上下文知识和草稿响应来生成最终响应。这样,多步译码器就可以捕捉到请求和响应之间的知识连接,从而产生更连贯、信息量更大的响应回答。
模型训练:模型以端到端的方式进行优化。 我们使用D表示训练数据集,并使用Θe,Θ1和Θ2分别表示编码器、第一步解码器和第二步解码器的参数。第一步解码的训练是为了最大程度地减少以下损失:
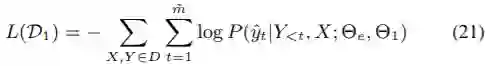
同样,通过最小化以下损失来优化第二步解码器:
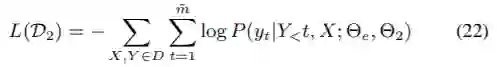
最后,总损失为L(D1)和L(D2)之和。
实验
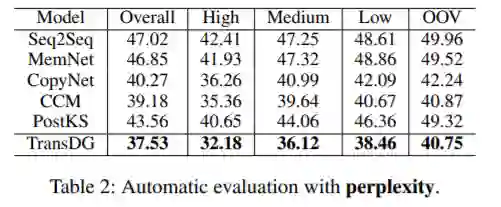
如下表2所示,TransDG在所有数据集上都实现了最低的困惑度,表明生成的响应更具语法性。
下表3证明,利用外部知识的模型在生成有意义的实体词和不同响应方面比标准Seq2Seq模型具有更好的性能,尤其是论文的模型以最高的实体得分明显优于所有基线。这验证了从KBQA任务迁移知识以进行事实知识选择的有效性。
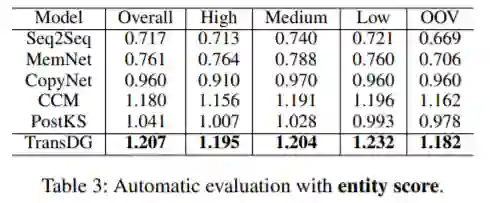
表4中显示的BLEU值表明了字级重叠的比较结果。
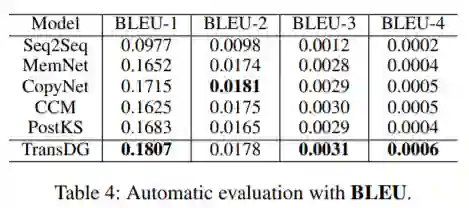
表5列出了人类评估的结果,这表明TransDG倾向于在人类注释方面产生更适当的信息,即由TransDG生成的响应比其他模型具有更高的知识相关性,表明TransDG可有效地整合适当的常识知识。
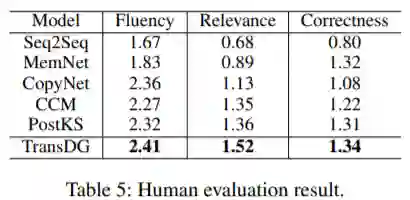
表6展示了TransDG和基线方法生成的一些响应。

总结
本文提出了一种新的知识感知对话生成模型TransDG,一个迁移KBQA任务的话语表示和知识选择能力来整合常识知识的神经对话模型。此外还提出了一种响应引导注意机制,以增强编码器对输入后的理解,并通过多步解码来优化知识选择,以生成更适当和更有意义的响应。最后大量实验证明了该模型的有效性。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


