【AlphaGo Zero 核心技术-深度强化学习教程笔记06】价值函数的近似表示
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第六讲 价值函数的近似表示
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践一 迭代法评估4*4方格世界下的随机策略
强化学习实践二 理解gym的建模思想
强化学习实践三 编写通用的格子世界环境类
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天《强化学习》第六讲 价值函数的近似表示;
之前的内容都是讲解一些强化学习的基础理论,这些知识只能解决一些中小规模的问题,很多价值函数需要用一张大表来存储,获取某一状态或行为价值的时候通常需要一个查表操作(Table Lookup),这对于那些状态空间或行为空间很大的问题几乎无法求解,而许多实际问题都是这些拥有大量状态和行为空间的问题,因此只掌握了前面5讲内容,是无法较好的解决实际问题的。本讲开始的内容就主要针对如何解决实际问题。
本讲主要解决各种价值函数的近似表示和学习,下一讲则主要集中与策略相关的近似表示和学习。在实际应用中,对于状态和行为空间都比较大的情况下,精确获得各种v(S)和q(s,a)几乎是不可能的。这时候需要找到近似的函数,具体可以使用线性组合、神经网络以及其他方法来近似价值函数:
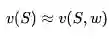
通过函数近似,可以用少量的参数w来拟合实际的各种价值函数。本讲同时在理论上比较了各种近似方法的优缺点以及是否收敛与最优解等。本讲将各种近似方法分为两大类,一类是“递增方法”,针对每一步,近似函数得到一些信息,立即优化近似函数,主要用于在线学习;另一类是“批方法”,针对一批历史数据集中进行近似。两类方法没有明显的界限,相互借鉴。
本节先讲解了引入价值函数的近似表示的重要性,接着从梯度开始讲起,使用梯度下降可以找到一个目标函数的极小值,以此设计一个目标函数来寻找近似价值函数的参数。有机器学习基础的读者理解本节会非常容易。本节的理论重点在于理解不同强化学习方法在应用不同类型的近似函数时的收敛性,能否获得全局最优解,以及DQN算法的设计思想及算法流程。本讲罗列了大量的数学公式,并以线性近似函数为例给出了具体的参数更新办法,这些公式在强大的机器学习库面前已经显得有些过时了,但对于理解一些理论还是有些帮助的。此外,在本讲的最后还简单介绍了不需要迭代更新直接求解线性近似函数参数的方法,可以作为补充了解。
简介 Introduction
大规模强化学习 Large-Scale Reinforcement Learning
强化学习可以用来解决大规模问题,例如围棋有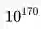
近似价值函数 Value Function Approximation
到目前为止,我们使用的是查表(Table Lookup)的方式,这意味着每一个状态或者每一个状态行为对对应一个价值数据。对于大规模问题,这么做需要太多的内存来存储,而且有的时候针对每一个状态学习得到价值也是一个很慢的过程。
对于大规模问题,解决思路可以是这样的:
1. 通过函数近似来估计实际的价值函数:
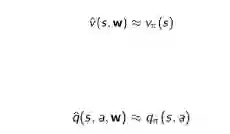
2. 把从已知的状态学到的函数通用化推广至那些未碰到的状态中
3. 使用MC或TD学习来更新函数参数。
近似函数的类型 Types of Value Function Approximation
针对强化学习,近似函数根据输入和输出的不同,可以有以下三种架构:

1. 针对状态本身,输出这个状态的近似价值;
2. 针对状态行为对,输出状态行为对的近似价值;
3. 针对状态本身,输出一个向量,向量中的每一个元素是该状态下采取一种可能行为的价值。
有哪些近似函数 Which Function Approximator
所有和机器学习相关的一些算法都可以应用到强化学习中来,其中线性回归和神经网络在强化学习里应用得比较广泛,主要是考虑这两类方法是一个针对状态可导的近似函数。
强化学习应用的场景其数据通常是非静态、非独立均匀分布的,因为一个状态数据是可能是持续流入的,而且下一个状态通常与前一个状态是高度相关的。因此,我们需要一个适用于非静态、非独立均匀分布的数据的训练方法来得到近似函数。
注:iid: independent and identically distributed 独立和均匀分布
下文将分别从递增方法和批方法两个角度来讲解价值函数的近似方法,其主要思想都是梯度下降,与机器学习中的随机梯度下降和批梯度下降相对应。
转自:专知
完整内容请点击“阅读原文”




