写给想从事语音产品的人

作者:ArvinNing
全文共 4683 字 2 图,阅读需要 10 分钟
———— / BEGIN / ————
近几年,自然语言处理技术的飞速发展,把语音交互的话题再次引爆。甚至有的公司已经开始招聘语音产品经理和语音交互设计师。也有人判断,未来这将成为下一波热门岗位。
去年双十一,天猫精灵走进了千家万户。
刚开始的时候,大家都对这些语音交互类产品充满了期待;然而时隔一年多之后再看,这些产品似乎并没有如预料中的那样,改变人们的生活。
那些天猫精灵的用户们对产品的评价只有两个字:很笨!
如今,人工智能的技术早已经远远超过五年之前了,但是从Siri的出现一直到现在,大家对语音交互类的产品评价从来没有变过,那就是:很笨!
语音产品似乎总是处于一个尴尬的位置。
要理解这一点:我认为仅仅从技术角度分析是完全不够的,现在人工智能的技术,解决的只是语音识别的问题。
语音识别的技术是越来越强大了,甚至能听懂方言了;但是,“笨”是一个用户脑子里面的概念——就算听得懂方言了,语音产品仍然只是一个能听懂方言的“傻子”。
如果不能从哲学和认知科学的角度去分析用户为什么会认为这些产品笨,那么我们对语音交互的认知会掉进一个死胡同中。
为了说明这个问题,我们一步步来,先理解一个概念:交互的边界。
当我们与机器进行交互时,我们能对机器做的事情是限定在一个有限的范围之内的(也就是说指令是一个有限集合),我把这个范围定义为交互的边界。
传统的视觉交互界面,都是有边界的交互;并且,交互的边界需尽量明确。
交互设计有一条很重要的原则,叫做可视化原则,就是指需要把用户能够进行的操作都让用户看到——把交互的边界展示给用户,不要让用户去寻找边界。
视觉界面的交互下,用户所有的操作,都是设计者预先设计好的,用户做的只是“选择题”;并且用户也知道,只能做“选择题”。
语音交互对于计算机来说,只是信息的程现方式不同,其边界的性质并没有发生变化。
于是就有了最原始的、没有火起来的语音交互形式,选择题的形式:“个人服务请按1,公司服务请按2,人工咨询请按0”——这种语音交互是边界清晰,运作良好的,也从来没有用户会用“笨”来形容它们。
然而,语音交互就老老实实像视觉交互一样做选择题不好吗?为什么视觉交互人们从来不提到人工智能,而语音交互,人们总是把它和人工智能搞混在一起?
我们来看第二个概念:信息的维度。
听觉信息和视觉信息,在物理属性上面是完全不同的。
视觉信息,是空间二维的信息,且在时间这个维度上是可以持续的。
听觉信息,是空间零维的信息,其存在仅仅只能在时间这个维度上闪现。
于是,在呈现交互的边界时(也就是提供“选择题”的选项时),视觉界面可以在时间空间中呈现任意复杂的界面,完成复杂高效的操作;而语音界面,其选项在被呈现的同时也在消逝,必须依靠人的短时记忆把选项存储下来。
而人的短时记忆容量非常有限的,只能存储7个简单的信息模块。于是,传统语音界面的复杂程度,被限制在了人短时记忆容量的范围之内。这么小的信息量,注定了这种有边界的语音地位尴尬,只能“小打小闹”。不太可能成为一种重要的交互方式。
在反观我们现实世界,我们基于视觉信息所做的事情,都是类似于“选择题”。
比如看到一个按钮按下,看到一双筷子拿起——只有当空间中存在这个“选项”时,我们才能操作。
也就是说:我们基于视觉信息与现实世界进行的交互,依然类似于有边界的“选择题”。
然而,人与人进行语音交互的时候,却不是在做选择题,而是模糊边界的(我们可以理解为没有边界)。
你说话的内容,并不需要在对方提供的选项之中,你发出的信息可以是创造性的。
正是因为人与人之间的语音交互是边界模糊的,才使得语音沟通的信息量突破人类短时记忆的限制,成为人与人沟通最重要的方式。
所以,人机语音交互想要成为一种重要的交互方式,必然需要突破传统“选择题”的方式,成为一种没有边界的交互。
也就是说:用户可以随意发出符合场景的指令,而不能让机器告诉用户它听得懂什么。
然而,当你不知道机器能听懂什么的时候,你只能假象对方像一个人样,什么都能听得懂。
于是,语音交互一旦突破了传统的边界,就会一发不可收拾地朝着的方向发展。
当你听到电话语音给你选项边界的时候,你不会假想对方是人;但是对于Siri这种没有提供边界的交互,你很自然的就把对方假象成为一个有智能、有情感的生物。
很多人喜欢调戏Siri,正是因为你已经把他假象成了一个人;而当它远远没有达到一个正常人应该具备的决策和判断能力时,你就会形容它很笨。
语音交互在刚刚开始的时候,他对标的对象就已经是真实的人。只存在“像人”“不像人”两种状态,而不像视觉界面,人们或许还愿意去学习它的交互。
为了说明视觉交互和语音交互的这点不同,需要举一个例子:
——这就是语音交互的尴尬。
真正的语音交互要想发挥其价值,其最终的效果,就是像人与人语言交流一样的逻辑进行交流。所以语音交互的发展总是期待人工智能技术的突破。
然而,现在人工智的水平到底如何?是否真如大家所说的奇点临近?
这点谁也没有办法判断。但是,从认知科学的角度,我能为你提供一些思路。
近年来,深度神经网络的快速发展确实非常恐怖。
理解神经网络算法的人应该都懂:神经网络算法的底层逻辑已经不同于传统机器逻辑判断的算法,而是类似于人类神经系统激活的方式工作——这是大家认为机器可能会超过人类的重要原因。
然而,从认知科学的角度来说,现在的人工智能依然非常初级。
人的认知分为:感觉,知觉,注意,记忆,表象,思维,想象,等等;而感觉知觉,是人类最低级别的认知,也是被研究的最多的认知现象。
表象、思维、想象等认知现象,现在科学研究得还不多,这也是人类认知最为神秘的地方,这也正是很多宗教或者迷信认为人类存在灵魂的原因。
而我们再来看看现在人工智能的前沿领域:图像识别,自然语言处理等等,从认知科学的角度来说,都相当于人类感觉知觉阶段,远远没有到达表象,思维,想象。
但是近年来,AlphaGo在围棋领域的表现让有些人开始怀疑:也许人类更高级的思维能力的机制和感知觉机制是一样的。
到底人工智能能否突破认知领域的研究,超越人类,或者也许人工智能的发展会像一座巴别塔,永远也无法到达目标,我们不做讨论。
此路我们看不到明确终点,也许可以换一个思路:
虽说人与人之间的交流是没有明确边界的交互,但是仍是有规律可循的。
最典型、最重要的一个特点,就是无意识推理:人与人沟通过程中,总是在不断地进行无意识推理,并且也假象对方能进行无意识推理。
绝大多数情况下,用户认为语音产品笨,就是因为语音产品缺少无意识推理这个认知逻辑。

一篇文章不可能道尽所有的无意识推理,只讲几个点,抛砖引玉。
1. 环境背景推理
我们常用的智能音箱和智能车载,都有一个激活指令。
你在家里,哪怕只有一个人的时候,你也需要呼叫:“天猫精灵”,它才能够激活。
——这种在连续对话中显得尤其不方便。
当我中间停了一会,再和它说话的时候,说完我才发现我白说了,又得重新呼叫名字激活。
——这是一种非常反人类的交互。
正常人与人语音交流时,并不是通过这种激活的逻辑,而是过滤的逻辑:人的听觉系统是随时在线的,我听到一句话,如果潜意识里我知道屋里就我们两个人,我就会立马处理这条信息,做出响应。
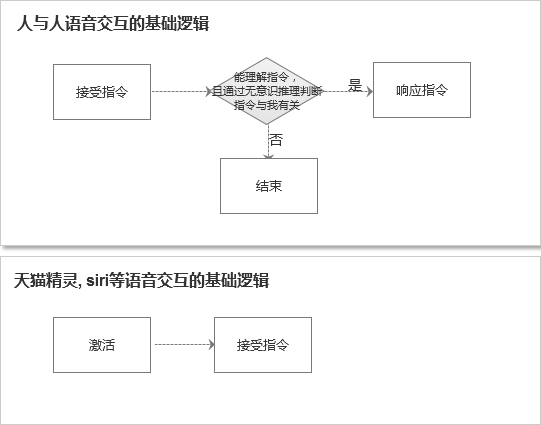
如上图所示,人与人交互的逻辑与语音产品交互的逻辑是不同的
人与人的交互是随时在线,然后过滤信息的;然而现在的语音产品,虽然技术本质上也是随时在线的,但是对用户来说,却多了一个激活的过程——相当于手动按下开关。
如果屋里有多个人会怎么样?
我会先等一会,发现没有人回应时,我就会确认:“是在和我说话吗?”然后继续这次对话。
以此类推,人每时每刻在利用环境信息进行无意识的推理的,模拟这一点,我们在做语音产品的时候,我们可以考虑把多个维度的环境信息的数据结构化,存储在一个缓存中,将用户发出指令与环境信息进行逻辑运算之后,再做出响应。
比如车载就特别容易做到这一点,通过座位的传感信息,很容知道车上有几个人。
2. 多通道(多模态)信息推理
一群熟人坐在一起的时候,没有谁说话之前总是要叫对方名字的。
我看你一眼再说话,就表示我在对你说。
——人的表情,动作等视觉信息,在语音沟通中也是非常重要的。
单纯的语言信息存在很多缺陷,于是人类在语言信息沟通的过程中,也需要借住视觉或其他通道收集到的信息来辅助理解判断,否则语言交流的难度会大很多。
在高级的语言沟通中,这些信息非常复杂,但是对于对于不太复杂的语音产品,最重要的就是”目光指向”。
别看这只是一个简单的逻辑,但是在人较多的环境下,能起到非常大的作用。
天猫精灵有个乌龙事件,当你把他音量调到最大播放热闹的音乐的时候,它就听不到你任何指令了。
但是在嘈杂的环境中,人与人是怎么沟通的呢?
我会看着你说一句话,然后你会表现出听不清的表情,然后把我拉到一个安静的地方沟通。
所有如果语音产品能够利用视觉通道的信息,对于语音交互的流畅度也是非常有帮助的。
比如说,在大声播放音乐的环境中,当天猫精灵“看到”了我转向它说话的时候,他应该自动将音量临时调小听我再说一遍。
再比如,如果你家里同一个房间有多个灯。如果你想通过智能音响关灯的话,你必须要给每个灯取一个名字,这种交互非常不自然,而且还容易忘记。但是如果能利用视觉通道的信息进行辅助判断,那么你只要用手指着这个灯说:“关这个灯”。
3. 上下文指代信息推理
人与人沟通过程中,上下文也是非常重要的。上下文信息最重要的作用在于代词的指代。要做到自然语言交互,指代信息必不可少。
linda说:“最近有哪里好玩吗?”
Alice说:“附近开了一个游乐场不错。”
Linda说:“我们就去那里吧。”
最后一句话的“那里”,是指代的“游乐场”。
这种使用代词的交互方式在人与人交互的过程中,是非常常见且重要的。
人与人交互的过程中,会在短时记忆里存储最近谈话中涉及到的对象。当对话中遇到代词时,会无意识地从短时记忆中提取对象代入语句,从而理解。
天猫精灵目前好像还完全不支持指代关系,显得非常笨。而最近几个版本的siri开始可以支持指代关系(以前的也不行)。比如说当你用Siri搜索过一个地点之后,你说:“去那里”。它会知道你是要去最近搜索的地点。说明他把最近搜索的对象存存起来了。使得上下文联系起来,而不是独立存在。
但是实际沟通过程中的指代关系远比这复杂——尤其是当人物、地点、事物等指代关系同时出现的时候,还需要更加深入理解人的认知模型,才让机器实现与人更流畅的交互。
语音产品虽然已经有很长的发展历史了,但是今天的语音产品仍然像是一个新的领域。
并且,当今的语音产品地位也比较尴尬:
一方面,语音识别技术快速发展,机器的语音识别能力已经超过人类;
但是另一方面,更高层次的语言认知模型并没有被计算机科学家考虑在内,使得语音产品实际使用起来的时候,总是显得很笨。
想要优化语音交互的体验,脚踏实地地让语音交互发挥更大的价值,释放语音交互的生产力,需要更深入的从认知科学的角度,理解人类对语言的认知模型,做到人与语音产品的自然交互。
———— / END / ————

———— / 推荐阅读 / ————

实战派产品大咖手把手带你
搭建产品经理必备知识体系!
告别野路子,做靠谱产品经理
点击“阅读原文”查看课程详情





