机器学习产品宝典:这是谷歌内部总结的七大要点
李林 若朴 编译整理
量子位 报道 | 公众号 QbitAI
产品经理新入机器学习坑,应该注意什么?
Google的用户体验设计团队总结了7点,量子位编译如下:
在没有用上机器学习(ML)的时候,一个网站或者App有许多人为设定的规则。而机器学习,能让产品不依赖这些规则,从数据中发现模式和关系。
机器学习能够为用户创造个性化的动态体验,小到视频网站、新闻应用,大到无人车,都在使用这种技术。
于是,用户体验设计师,或者说产品经理,面临着一项重任:确保机器学习和用户体验的协调,让用户感受到自己掌控着技术,而不是被技术掌控。
和互联网、移动互联网两波浪潮一样,ML也让我们在建立每一项用户体验时,都需要重新思考、重组、置换,考虑新的可能性。
Google的用户体验设计团队为了应对机器学习带来的新问题,提出了一个努力方向:“以人类为中心的机器学习”(HCML)。
这个名字有点眼熟?量子位猜,大概是因为和“以用户为中心的设计”比较像。
我们从“以人类为中心”的角度去看产品,探索怎样从人类的需求出发,用只有通过ML才能完成的独特方式去解决这些需求。
如果你刚刚开始接触机器学习,可能会觉得信息量太大。
不要慌。
通过Google用户体验团队和AI团队的合作,以及试错的经验,我们列出了以下7点,帮用户体验设计师来熟悉“机器学习驱动的产品”这一新领域。
这些要点能帮你把用户放在第一位,快速迭代,并了解机器学习带来的独特机会。
开始吧。
1. 不要指望机器学习自己找出需要解决的问题
机器学习和人工智能炒作得太火热,很多公司和产品团队在制定产品策略的时候,甚至不管要解决什么问题,先确定了以机器学习作为解决方案。

如果只是纯粹的技术探索,这样没什么问题,可能还会激发产品设计灵感。
但如果是在设计产品,你不从人的需要出发,可能就会建立一个非常强大的系统来解决非常小、或者根本不存在的问题。
所以,我们要说的第一点是,那些挖掘用户需求的苦活累活,你还是得自己做。
那些情境调查、访谈、深入讨论、用户调查、日志分析统统不能简化,你需要接近用户,找出你是否解决了问题,或者找到了他们潜在的需求。
机器学习不能自己找出该解决的问题,这需要我们来定义。
作为用户体验设计师,无论哪种技术范式主导,我们指导团队的基本工具还是不变的。
2. 问问自己,机器学习能否以独特的方式解决问题
一旦你确定了需要解决的问题、需要满足的需求,就该评估机器学习能否以独特的方式解决这些问题了。
很多问题根本用不上机器学习。
在产品开发的这个环节,一个很大的挑战是去确定哪些用户体验需要ML,哪些功能用了ML会得到有意义的增强、哪些用不用都一样,甚至用了还不如不用。
很多产品不需要ML就能给人“智能”或者“个性化”的感觉,不要以为只有机器学习才能救产品。
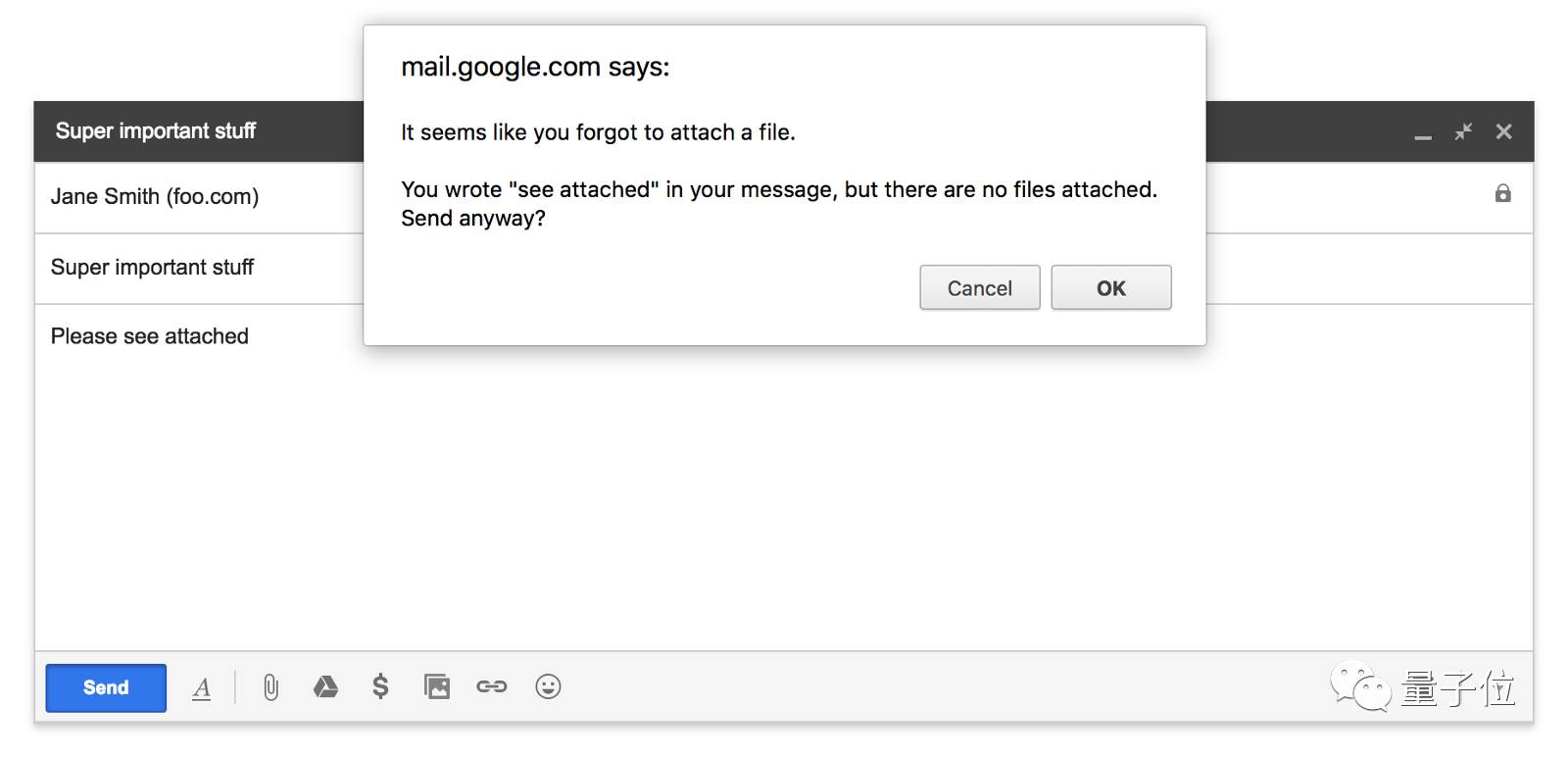
△ 忘了加附件的提示,就不适合用机器学习
我们创建了一组问题,来帮团队了解ML对其用例的价值。
这些问题,深入挖掘了用户与ML系统的交互可中可能有什么样的心理模型和期望,以及该系统需要哪些数据。
这里有三个例子,Google某团队想要用ML来解决一个用例时,就回答过这些问题:
描述理论上的人类“专家”现在可能怎样执行这个任务。
如果你的人类专家要执行这个任务,你会如何回应他们,以便下次改进?对混淆矩阵的四种情况(真正、真负、假正、假负)都做出说明。
如果一个人要执行这个任务,那么用户希望他们做出什么样的假设呢?
花几分钟时间回答这些问题,能帮我们了解用户会带着哪些预设去使用ML产品。在产品团队的讨论中,或者在用户研究的过程中都可以去问这些问题。
稍后我们讨论定义标签和训练模型时,还会再提到它们。
回答了这些问题,为特定的产品或者功能写了故事板,我们就可以将团队所有的产品想法都放进这四个象限中:

△ 横轴代表ML带来的影响,纵轴代表对用户的影响
通过这个坐标系,我们能找出哪些想法比较有影响力,哪些想法依赖于ML来实现。在前面的对话中,你就应该开始和开发人员合作了,如果还没有,从这里开始也不晚,让他们来衡量这些想法在实际中能否用机器学习解决。
在象限右上角的功能:也就是对用户有着最大的影响力,ML技术也能带来独特体验的那些,就是优先级最高的。
3. 原型设计:个人示例和Wizard of Oz
ML系统的一个重大挑战是原型设计。
如果产品的核心价值在于通过独特的数据来为用户定制个性化体验,你很难快速地设计一个具有真实感的原型。但是,如果你等ML系统建完再去测试它的设计,可能就没机会改了。
不过,有两种用户研究方法可以解决这个问题:使用参与者建立个人示例、Wizard of Oz研究。
在使用早期模型进行用户研究时,可以让参与者带一些他们自己的数据来,比如个人照片、通讯录、他们收到的音乐或电影建议等。当然,要让参与者完全明白他们的数据将被用来干什么、什么时候才会被删除。
对于参与者来说,这可能是一个很有意思的家庭作业。
通过这些示例,你可以模拟系统的正确、错误响应。比如说你可以模拟系统向用户返回错误的操作建议,查看用户的反应,了解他对错误原因的假设。
和虚拟示例或者概念描述相比,这可以帮你更可靠地评估各种可能性的成本和收益。
还没造出来的机器学习产品的第二种测试方法,是Wizard of Oz研究。过去20年间,Wizard of Oz研究在用户研究方法中的重要性越来越低,现在,它回归了。
Wizard of Oz?绿野仙踪?
这种测试指的是由一名产品团队人员代替系统,向用户做出反馈。
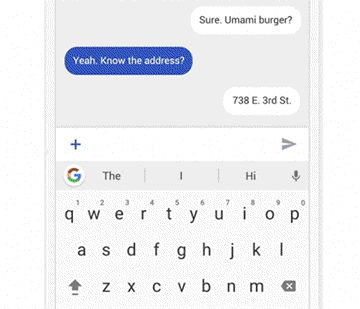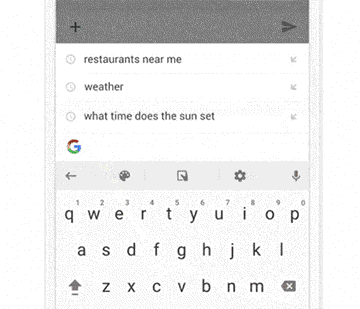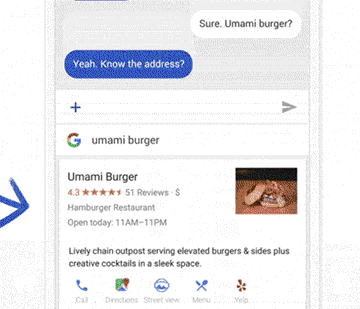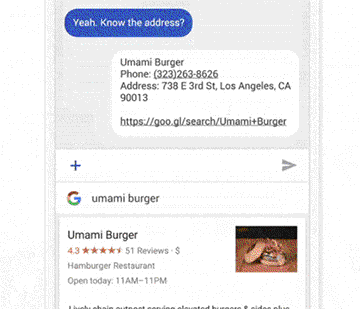
△ 聊天界面是Wizard of Oz测试最简单的方法之一,只要在另一端准备一名产品人员,假装“AI”来输入回复。
让产品团队人员模仿机器学习系统的行为,比如回复聊天信息、给出呼叫建议、电影建议,可以帮用户模拟体验与“智能”系统的交互。
这些交互可以为产品设计提供关键的指导,因为当参与者认真地与“AI”交互的时候,他们会自然形成系统的新力模型,根据模型来调整自己的行为。
观察他们的对系统的适应、与系统的二次交互,对于产品设计有重大的参考价值。
4. 衡量假正类和假负类的成本
你的机器学习系统会犯错。了解这些错误是什么样的,以及它们如何影响用户的产品体验很重要。
我们在第二点中提到了混淆矩阵。这在机器学习中是一个关键的概念,描述了当机器学习系统正确或者错误的时候是什么样子。
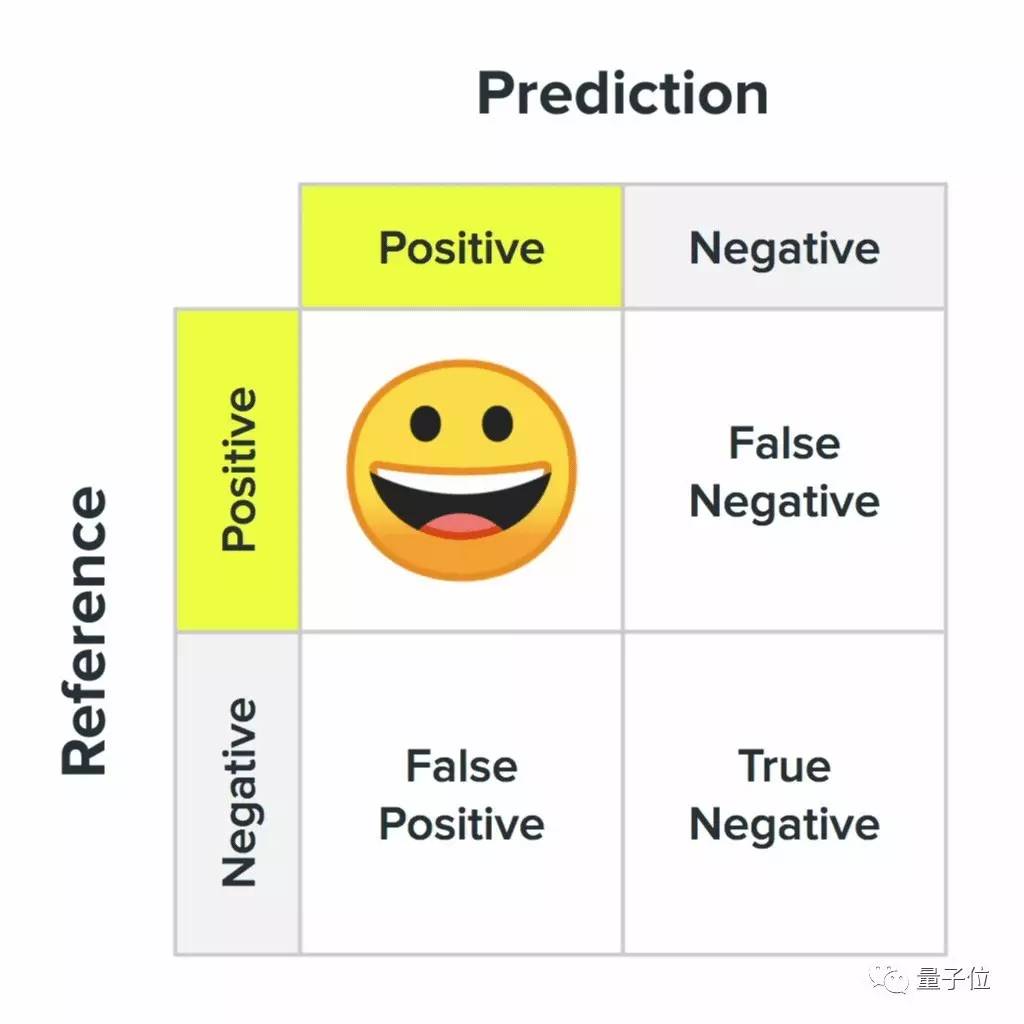
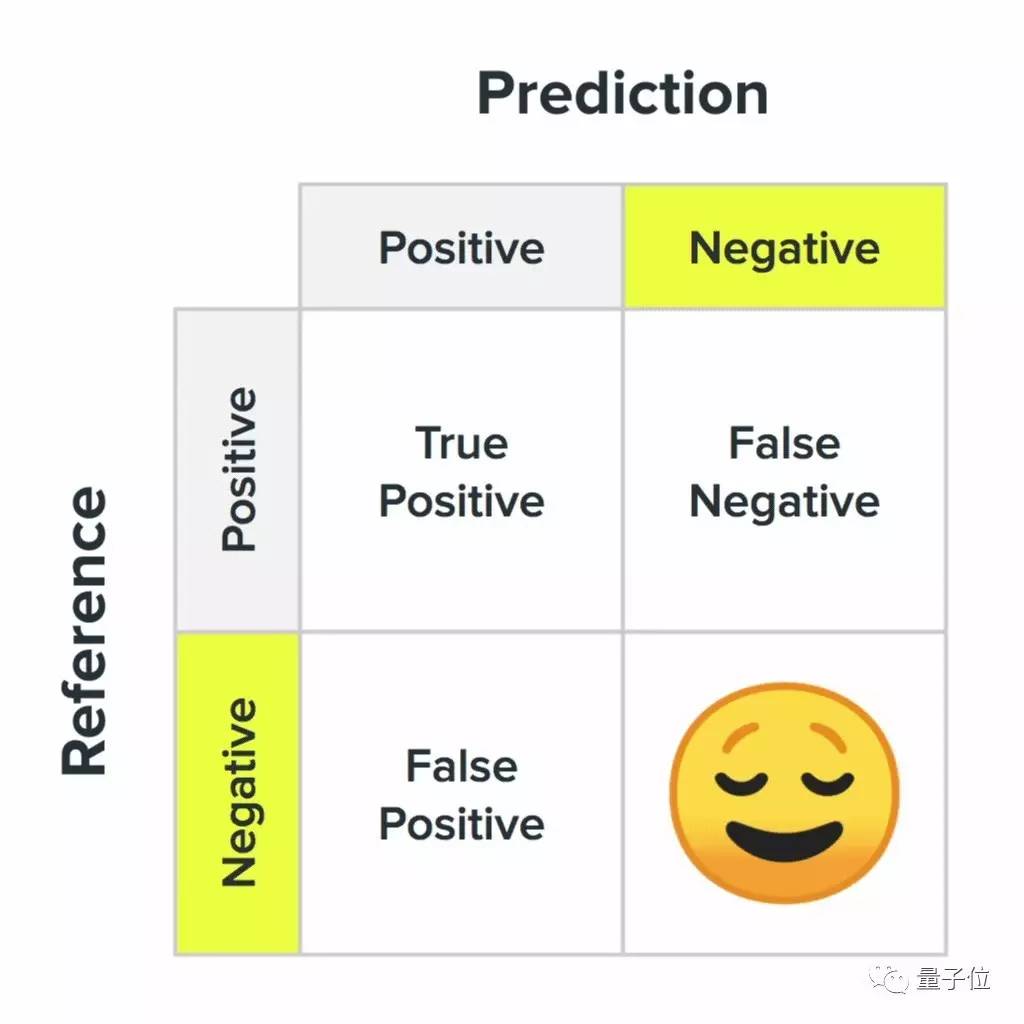
△ 混淆矩阵的四个状态,以及对用户意味着什么
对于机器来说,所有的错误都一样,但对人来说却不是这样。
例如,如果我们有一个“人类or魔怪”分类器,意外把人识别成魔怪。这只是系统的一个错误,不涉及侮辱或者文化因素考量。机器不会明白,人被错误的识别为魔怪带来的侵犯感,远大于魔怪被错误识别为人。这也许就是以人为本的偏见。:)
在机器学习中,需要有意识地在准确率和召回率之间进行权衡。
也就是说,如果你认为囊括所有的正确答案更重要,那意味着也会包含更多的错误答案(优化召回率);如果想让错误答案最小化,代价是舍弃一些正确的答案(优化准确率)。
例如,你在Google Photos中搜索操场,可能会看到如下结果:
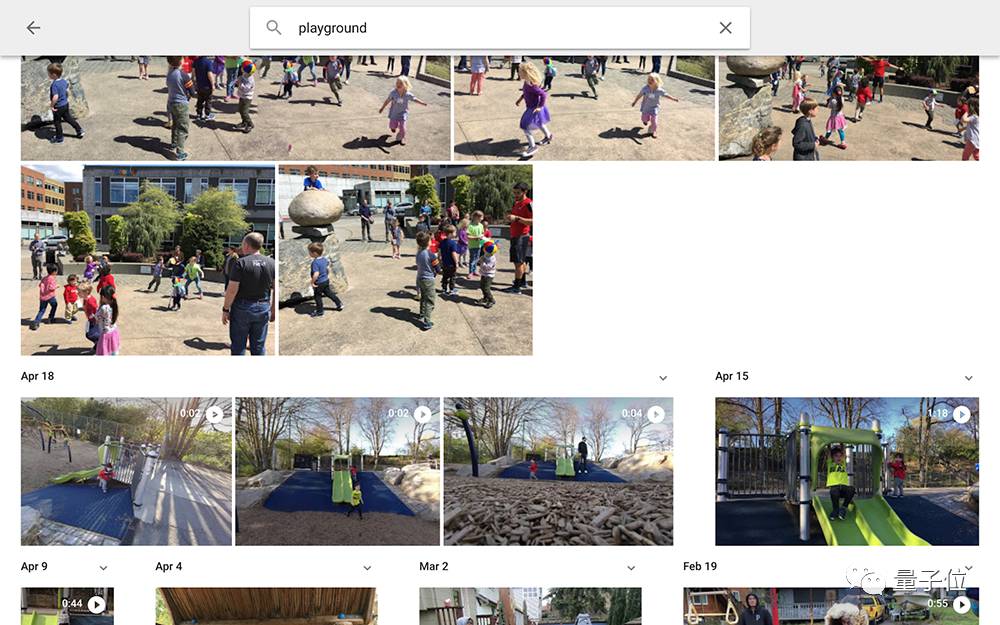
其中包括一些儿童玩耍的场景,但不在操场上。在这个案例中,召回率优先于准确率,找到所有的操场照片更重要。
5. 有计划的进化
最好的机器学习系统,应该随着用户的心智模型不断进化。
当人们与这些系统交互时,他们也在影响和调整着这个系统未来的输出;而这些调整反过来又将改变用户和系统交互的方式……(子子孙孙无穷匮也)
当然这种不断的反馈循环,既有可能是良性的,也有可能是恶性的。所以你需要注意引导用户,给出有利于自己和模型的反馈。
良性循环的一个例子就是谷歌输入法的Gboard,他能不断的进化并预测用户下一步要输入什么字,使用系统建议的人越多,给出的建议就越好。
△ Gboard示意图
机器学习系统都是用现有数据集训练而成,并会根据新的输入进行调整,但这些改变在发生之前都很难预测。所以我们需要同步调整用户研究和反馈策略。这意味着在产品周期中进行提前规划纵向、高个性化以及广泛的研究。
你需要规划出足够的时间,随着用户和用例的增加,对准确率和召回率进行量化测量,来评估机器学习系统的性能。当然还需要和用户坐在一起,了解他们如何使用系统,以及成功或者失败背后的心智模型。
另外,我们需要考虑如何在整个产品生命周期内,获得用户的真实反馈,以改进机器学习系统。能否设计出更好、更快的交互反馈模式,是良好的机器学习系统与优秀的机器学习系统之间的区别。
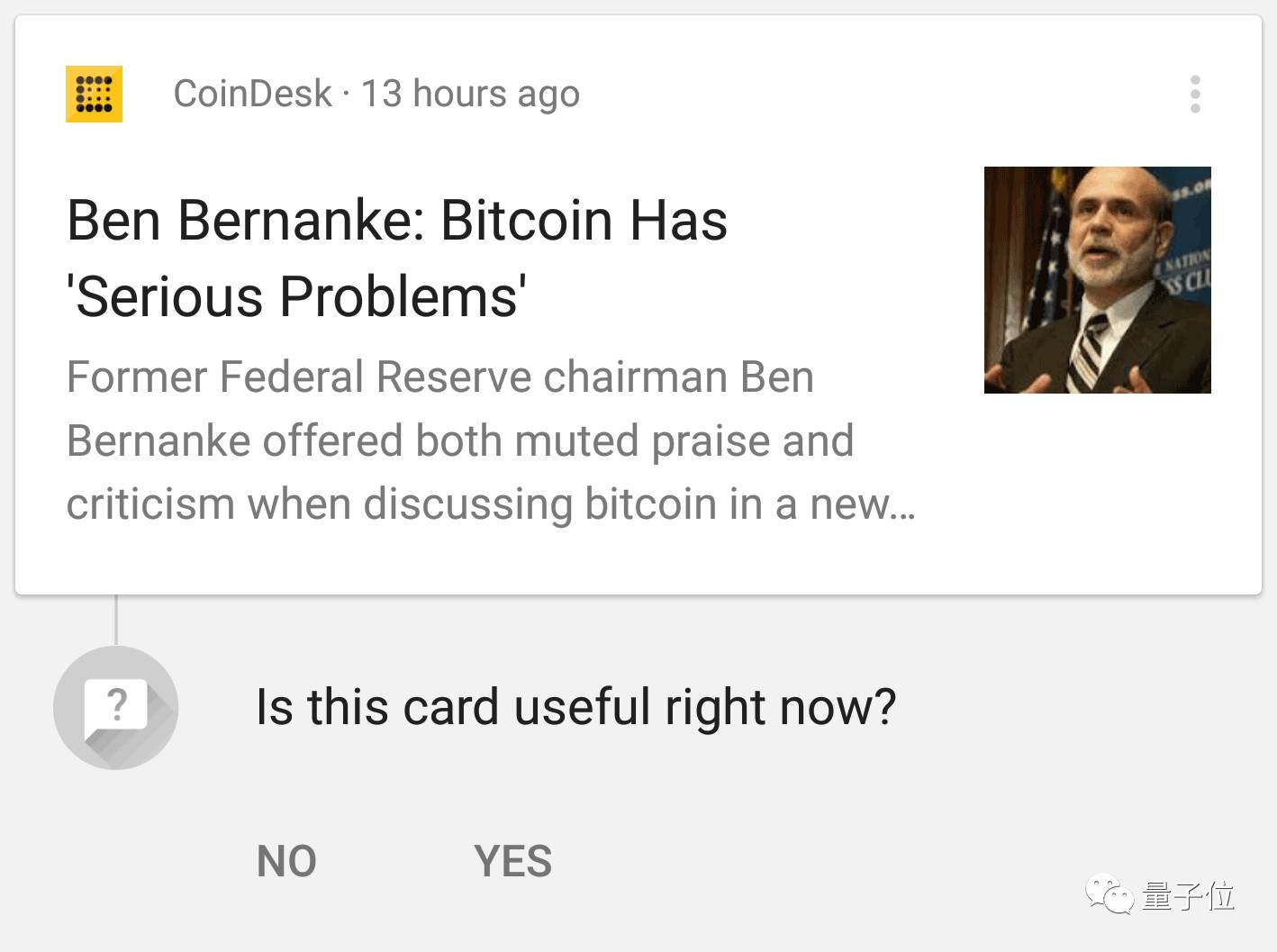
△ Google app隔段时间就会询问某个页卡是否有用,以获取相关的反馈意见
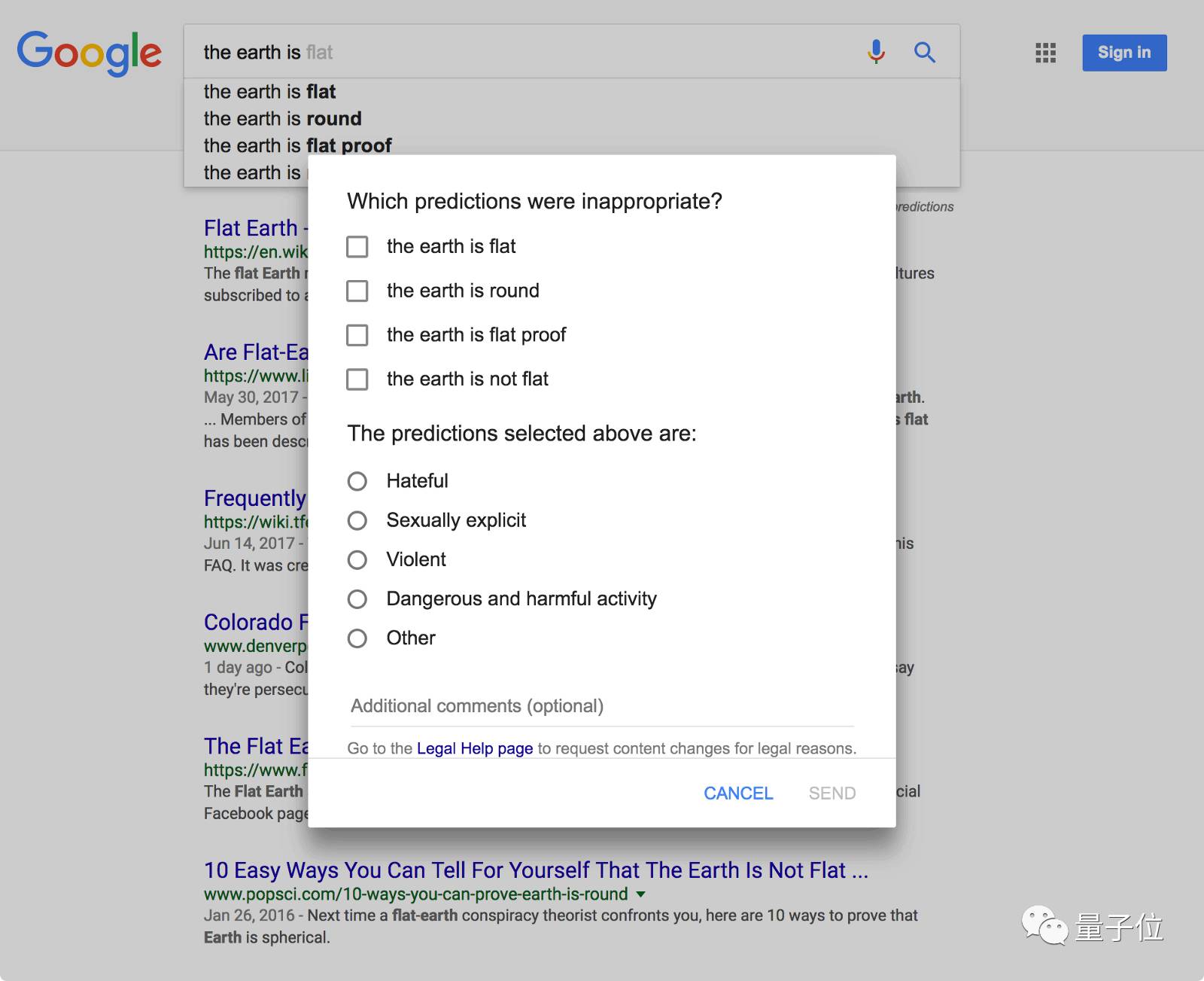
△ 用户可以对Google搜索自动完成功能提供反馈,包括为什么预测的结果不合适等
6. 用正确的标签训练算法
当我们谈交互时,已经习惯于把线框、mockup、原型和红线作为标志可以交付的成果。
然而,当我们谈到机器学习增强的交互时,还得指定更多,因为“标签”来了。
标签是机器学习的重要组成部分。
很多人的工作就是查看大量的内容,然后打上标签,例如标注出一张图片上是否有猫。一旦有足够的照片被标记为“猫”或者“非猫”,就形成了一个数据集,可以用来训练模型识猫。更准确一点说,是让模型以一定的置信水平预测一张照片中是否有猫。
很简单,是吧?

△ 你能通过这个测验么?
真正的挑战在于,让模型预测对于用户来说非常主观的东西,例如是否对一篇文章感兴趣或者提供电子邮件的回复建议。
而且模型训练需要很长的时间,获得一个完全标记的数据集可能非常昂贵,而错误的标签还会给产品带来巨大的负面影响。
该怎么办?
可以先从合理的假设开始,并且对这些假设进行广泛的讨论。
这些假设通常采用这样的形式:“对于在(某)情境下的(某)用户,我们假设用户更喜欢(这个)而不是(这个)”。然后尽快把这些假设放到原型里,收集反馈进行迭代。
建议为你的机器学习找一个外援,例如在相关领域有深入研究的专家。
接下来,你会发现哪些假设看起来更加“真实”。但是在大规模收集数据和打标签之前,最好让专家挑选一些真实用户数据进行关键的第二轮验证。
用户应该测试一个高保真的原型,感觉到在与一个AI进行交互。
通过这些实操验证,可以让专家创建一个AI功能的示例组合。然后把这些案例作为后续收集的路线图,进而生成一套强大的训练数据集,以及大规模的标签协议框架。
7.扩展思维,发挥创意
作为一个产品经理,可能都会得到一些令人抓狂的微调反馈,可能都有一些你再也不想打交道的工程师。
具体到机器学习这件事上,有一些微小的建议供参考。
对于一个机器学习的产品经理来说,规范太多可能会导致无意的锚定,进而束缚了工程师的创造力。要相信他们的直觉,鼓励他们不断试验,即便整个框架还不完整也可以开始用户测试。
机器学习是一个更具创造力和表现力的工程。但训练一个模型可能很慢,可视化的工具还不是很好,所以工程师在最终调整算法时,经常需要靠想象力……
所以产品经理需要一直帮助工程师走在以用户为中心的道路上。

△ 携手合作,共创未来
要用不同的方法给工程师以启迪,要温和的给出批评意见,要帮助他们深入的理解产品原理和目标。
工程师越早展开迭代,机器学习体系的鲁棒性可能越好,你就越有可能推出具有影响力的AI产品。
结论
以上是我们在Google内部强调的七个要点。希望对于正在或者想要开发机器学习产品的你有所帮助。随着机器学习开始驱动越来越多的产品,我们更应该以人为中心,为人们提供独特、有价值、极好的产品体验。
作者:
Josh Lovejoy,Google研究和机器学习小组UX设计师
Jess Holbrook,Google研究和机器学习小组UX经理和UX研究员
插图 by Akiko Okazaki
【完】
一则通知
量子位读者5群开放申请,对人工智能感兴趣的朋友,可以添加量子位小助手的微信qbitbot2,申请入群,一起研讨人工智能。
另外,量子位大咖云集的自动驾驶技术群,仅接纳研究自动驾驶相关领域的在校学生或一线工程师。申请方式:添加qbitbot2为好友,备注“自动驾驶”申请加入~
招聘
量子位正在招募编辑/记者等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。

△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容



