动态 | 谷歌 AI 最新博文:视频模型中的模拟策略学习

AI 科技评论按,深度强化学习(RL)技术可用于从视觉输入中学习复杂任务的策略,并已成功应用于经典的 Atari2600 游戏中。最近在这一领域的研究表明,即使在像 Montezuma s Revenge 这样的游戏所展示的具有挑战性的探索机制中,它也可能获得超人的表现。然而,目前许多最先进方法的局限之一是,它们需要与游戏环境进行大量的交互,且这些交互通常比人类去学习如何玩得好要多得多。
近日,谷歌 AI 发布了一篇博文,讨论了他们的视频模型中的模拟策略学习模型,雷锋网 AI 科技评论编译整理如下。
解释为什么人们能更有效地学习这些任务的一个假设是,他们能够预测自己行动的效果,从而含蓄地学习一个模型,其行动顺序将导致理想的结果。其一般思想是,建立所谓的博弈模型并用它学习一个选择行为的良好策略,这是基于模型的强化学习(MBRL)的主要前提。
在「基于模型的 Atari 强化学习」中,我们引入了模拟策略学习(SimPLe)算法,这是一个 MBRL 框架,用于训练 Atari 游戏机的代理,其效率显著高于当前最先进的技术,只需要使用与游戏环境的约 100K 交互(相当于真人 2 小时的游戏时间)就能显示出有竞争力的结果。此外,我们已经将相关代码作为 Tensor2Tensor 开源代码库的一部分进行了开源。这个版本包含了一个预训练的 world 模型,可以用一个简单的命令行运行,也可以使用类似于 Atari 的界面来播放。
学习 SimPLe world 模型
总的来说,SimPLe 背后的思想是交替学习游戏行为的 world 模型,并使用该模型在模拟游戏环境中优化策略(使用无模型强化学习)。该算法的基本原理已经很好地建立起来,并在许多基于模型的强化学习方法中得到应用。
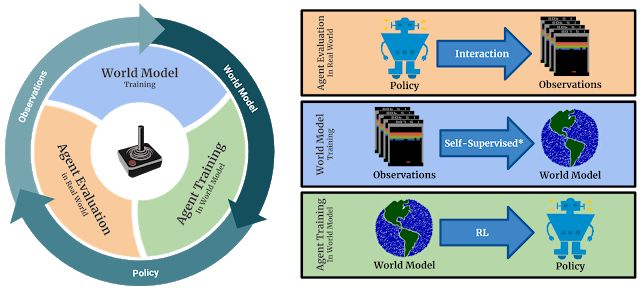
SimPLe 的主循环:1)代理开始与真实环境交互。2)收集的观测数据用于更新当前的 world 模型。3)代理通过学习 world 模型更新策略。
为了训练一个 Atari 游戏模型,我们首先需要在像素空间中生成合理的未来世界。换言之,我们试图通过输入一系列已经观察到的帧以及对游戏发出的命令(如「左」、「右」等)来预测下一帧将是什么样子。在观察空间中训练 world 模型的一个重要原因是,它实际上是一种自我监督的形式,其中,观察像素在我们的例子中形成密集而丰富的监控信号。
如果成功地训练了这样一个模型(例如视频预测器),那么一个人基本上拥有一个学习过的游戏环境模拟器,可以选择一系列行动,使游戏代理的长期回报最大化。换言之,我们通过来自 world 模型/学习模拟器的序列对策略进行训练,而不是对来自真实游戏的序列进行策略训练,因为后者在时间和计算量上花费都非常大。
我们的 world 模型是一个前馈卷积网络,它接受四帧数据,预测下一帧以及反馈(见上图)。然而,在 Atari 中,未来是不确定的,因为只知道前面四帧数据。在某些情况下,例如,在游戏中暂停超过四帧的时间、当乒乓球从帧中消失时,都可能导致模型无法成功预测后续帧。我们用一种新的视频模型架构来处理随机性问题,这种架构在这个环境中做得更好,这是受到先前工作的启发。

当 SimPle 模型应用到功夫大师身上时,就会看到一个由随机性引起的问题的例子。在动画中,左边是模型的输出,中间是事实,右边的面板是两者之间的像素差异。
在每一次迭代中,在 world 模型经过训练后,我们使用这个学习过的模型来生成动作、观察和结果的样本序列,使用近端策略优化(PPO)算法改进游戏策略。其中的一个重要细节是,数据采样从实际的数据集帧开始。SimPle 只使用中等长度的数据集,这是因为预测错误通常会随着时间的推移而叠加,这使得长期预测非常困难。幸运的是,PPO 算法也可以从其内部数值函数中学习行动和反馈之间的长期关系,因此有限长度的数据对于反馈稀少的游戏(如高速公路)来说是足够的。
SimPLe 的效率
成功的一个衡量标准是证明模型是高效的。为此,我们评估了模型与环境进行 10 万次交互后的策略输出,这 10 万次交互相当于一个人进行大约两小时的实时游戏。我们在 26 款不同的游戏中比较了我们的 SimPLe 方法和两种最先进的无模型 RL 方法——Rainbow 和 PPO。在大多数情况下,SimPLe 方法的采样效率比其他方法高 2 倍以上。
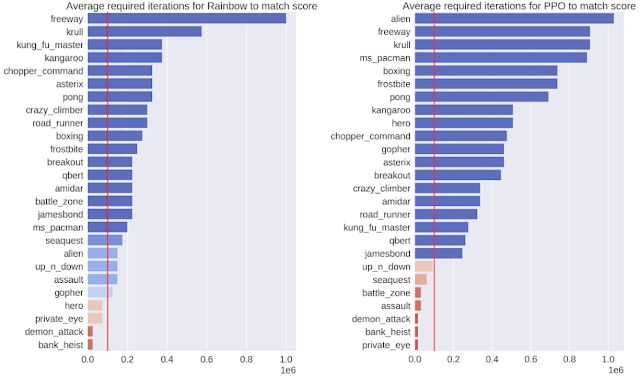
两个无模型算法(左:Rainbow,右:PPO)所需的交互次数,以及使用我们的 SimPLe 训练方法获得的分数。红线表示我们的方法使用的交互次数。
SimPLe 的成功
SimPLe 方法的结果令人振奋:对于其中两个游戏,Pong 和 Freeway,在模拟环境中训练的代理能够达到最高分数。
对于 Freeway、Pong 和 Breakout 来说,SimPLe 可以生成最多 50 步接近像素级的完美预测,如下图所示。
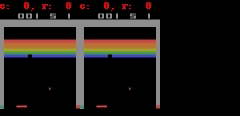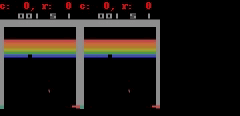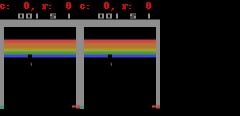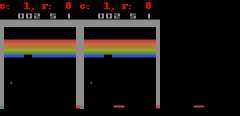
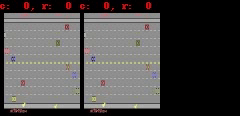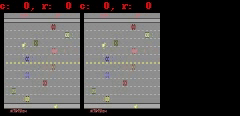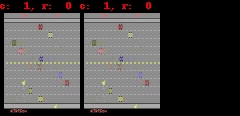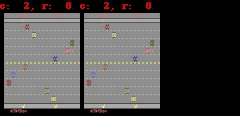
SimPLe 可以做出接近像素的完美预测。在每个动画中,左边是模型的输出,中间是基本事实,右边的窗格是两个动画之间的像素差异。
SimPLe 的惊喜
然而,SimPLe 并不总是做出正确的预测。最常见的失败是由于 world 模型不能准确地捕获或预测小的但高度相关的对象。比如,在 Atlantis 战区,子弹是如此的小,以至于它们往往会消失。

在战场上,我们发现模型难以预测小的相关部分,例如子弹。
结论
基于模型的强化学习方法的主要用在交互成本高、速度慢或需要人工标记的环境中,例如用在多机器人任务中。在这样的环境中,经过学习的模拟器能够更好地理解代理的环境,并能够为多任务强化学习提供更新、更好、更快的方法。虽然 SimPLe 还达不到标准的无模型 RL 方法的性能要求,但它实际上更有效,我们希望将来能够进一步提高基于模型的技术的性能。
如果你想开发你自己的模型和实验,请移步我们的知识库和 colab,在那里你可以找到关于如何使用预先训练过的 world 模型一起重现我们工作的说明。
相关论文地址:
https://arxiv.org/abs/1903.00374
via:
https://ai.googleblog.com/2019/03/simulated-policy-learning-in-video.html
点击阅读原文,查看 谷歌开源强化学习深度规划网络 PlaNet


