经典 | 三十年前的 AlphaGo:李开复经典论文重读

AI科技大本营此前曾全文刊发李开复博士1986年发表在 Artificial Intelligence 期刊上的论文《评价函数学习的一种模式分类方法》。在这篇论文里,作者详细介绍了黑白棋 AI 程序 BILL 的关键技术,该程序于1989 年获得了全美黑白棋大赛的冠军,可以说就是三十年的 AlphaGo。
这篇论文不但帮我们回顾棋类博弈 AI 走向辉煌,而且文章本身介绍的一些思想和技术,至今仍不过时。原论文篇幅浩大,为帮助读者把握要点,我们特意撰写了导读,并精心制作了 PDF 文档供感兴趣的小伙伴下载。
关注公众号:AI科技大本营,并回复关键字“李开复”,我们将把本论文连同作者 1990 年的另一篇重要相关论文的 PDF 版本推送给您。
导读
我们向读者推荐李开复先生这篇发表于1986年前的论文。这篇文章当然对于 AI 博弈竞技这一研究方向来说具有历史价值,其严谨完备的讨论和规范的学术论文写作也堪称典范,不过我们之所以时隔31年翻译和发表此文,主要是有感于其中领先时代的思想,即使对于今天的 AI 学习者来说,也具有跨越时空的启发,绝对值得品读。
李开复于1983年至1988年在卡耐基梅隆大学(CMU)计算机系攻读博士学位,读博期间他的主要研究方向是机器学习和模式识别,也就是今日大红大紫的人工智能之主流方向。
李开复的博士毕业论文是以统计学习方法来做语音识别,在当时是全球首屈一指的研究。他以及其同门师弟洪小文的研究,帮助其导师 Raj Reedy 于 1994 年获得图灵奖。
CMU 做机器学习和语音识别研究,是非常有渊源的。在人工智能学界,CMU 的名字与语音识别及自然语言理解密不可分。早在1960年代第一次AI热潮当中,CMU 就获得 DARPA 每年300万美元的拨款,荟集当时全球语音识别领域的顶级学者,投入语言理解研究项目(Speech Understanding Research, SUR)。然而在1974年 AI 寒冬中,DARPA 对 SUR 项目进展感到不满,停止拨款,遂致 SUR 项目半途而废。
但学者们在 SUR 研究期间取得的多项成果,例如隐马尔可夫模型,成为今日机器学习中多个分支的基础,亦奠定了 CMU 在语音及自然语言理解领域执牛耳的地位。而 DARPA 对于 SUR 项目的误伤,也成为 DARPA 历史上为数不多的遗憾之一。
SUR 虽去,但CMU在这个领域已经根深叶茂,此后人才辈出,群星璀璨。而那位今天在中国科技 VC 中以 All in AI 著称的投资大佬,那位在各种讲坛甚至娱乐节目中卖力甚至卖萌解说人工智能的开复老师,当年则是这群星中耀眼的一枚,是世界一流的人工智能专家。
上面这个故事是不少人都知道的。
但是关于李开复的 CMU 生涯,还有一个比较少人知道事情。李开复在读博期间,除了把统计学习方法开创性的用来进行语音识别,还把它用来搞了一个黑白棋(Othello)人工智能博弈程序 BILL,并且顺便拿了一个全美冠军。拿冠军这事发生在1989年,而这篇论文1986年表在AI领域顶级期刊 Artificial Intelligence 上,已经把日后冠军BILL 来了个CT式曝光,所以这篇文章的事后诸葛亮的标题可以是《一个国家冠军的诞生,以及一场事先声张的棋盘谋杀案》。
根据作者自己的评价,此论文以及围绕 BILL 的研究工作,“应该算是第一个用正统机器学习做得对弈软件。贝叶斯学习方法至今仍被很多人使用”。我们今天能够阅读这篇论文,一窥人工智能棋盘博弈的门径。
那么这篇论文有哪些穿越时空的闪光点呢?
首先,贝叶斯学习方法的应用。
在这篇论文写作的 1986 年,人工智能研究界的兴奋点仍然在基于规则的专家系统上,距离 CMU 另一位机器学习巨擘 Tom Mitchell 经典的机器学习教材出版还有十二年之遥,以统计学为基础的机器学习尚处幼年。
但这篇论文使我们看到,当时在 CMU 等世界顶尖的机器学习研究机构,对于相关理论的研究已经到了何等深度,实践中取得了何等突出的效果。在本文的第四部分,作者详细介绍了运用了贝叶斯方法的 BILL 3.0 如何在对抗评测中横扫人类冠军以及自己的上一代版本 BILL 2.0。
我想当年读到这篇文章的人工智能学者,都应该能够感受到这一新方法、新方向的巨大潜力。
对于搞机器学习的人来说,贝叶斯是一个绕不开的名字。贝叶斯原理以数学的形式归纳了理性人的决策过程:对一件事情事先有一个估计(先验概率),随着新的证据不断出现,不断的修正自己的估计,证据越多,估计越准。这一个简朴的思想衍生出一系列以贝叶斯为名的方法和算法,如“贝叶斯学习”、 “贝叶斯推断”、 “贝叶斯估计”、“朴素贝叶斯”、“高斯朴素贝叶斯”、“贝叶斯网络”等等。但与其说贝叶斯是诸多机器学习方法和算法中的一个,不如说它是理解机器学习的一个角度。
在机器学习领域的相当多的一部分学者,直接从贝叶斯定理出发,建构了整个机器学习领域。比如说广义线性模型,深度学习,你尽可以从几何的角度进行解释和推导,但贝叶斯学者们可以用贝叶斯概率论和统计参数估计来解释和推导整个体系,而且严丝合缝。
因此在《终极算法》一书中,贝叶斯与连接、类推、符号和进化并称机器学习五大学派。贝叶斯学派的代表人物有微软的David Heckerman,图灵奖得主Judea Pearl、伯克利大学的机器学习泰斗Michael Jordan等人。近年来贝叶斯学派势头很猛,出了几本高质量的著作,比如 Kevin Murphy的 Machine Learning: A Probabilistic Perspective,David Barber 的 Bayesian Reasoning and Machine Learning,Sergios Theodoridis 的 Machine Learning: A Bayesian and Optimization Perspective。
而早在 31 年前本文作者就将贝叶斯方法用在黑白棋博弈程序中,至少在这个领域中开了应用贝叶斯方法的先声。
评价函数的质量是棋类博弈 AI 程序的关键。一个好的评价函数,对于不同的棋盘形势和弈棋步骤能够给出靠谱的评分。以这个评分为导引,棋类博弈 AI 就能够展现出极高的水平。作者在这篇论文里详细考察了黑白棋 AI 程序的发展过程,并且点出传统 AI 的关键缺陷是线性的评价函数,进而用贝叶斯方法构建了一个非线性评估函数。
如前所述,这在当时是开创性的。显然在黑白棋的博弈中,一个优秀的评估函数理应是非线性的,因此 BILL 从基因里就优于当时其他的黑白棋 AI,也难怪三年之后能够横扫天下。
其次,开发一个博弈 AI,科学是其中一部分,工程的方面同样重要。
本文透露出来的工程细节也是令人饶有兴致的,作者使用多个 AI 程序相互对抗,并且将优胜者的参数权值拿出来增强对抗方的实力,重复多轮迭代,得到越来越强悍的 AI 程序。
如果你看到论文中的这一部分,会联想到当下火爆的生成式对抗网络 GAN 和迁移学习,内心定会有拈花一笑的喜悦。
论文所展示出来的严谨和渊博也是这篇文章的一大看点。我在论文的第五部分看到作者为了验证多元正态分布假设时,竟然不惜辛苦的将三千盘游戏当中四项特征的分布图形一一找出。这短短的一段话、几张图背后,是多大的工作量,是怎样认真的态度!反正我读到这一段时,内心是相当钦佩的,我相信读者应该也有同感。
单从本文来说,有一个不足之处,就是对于四项关键特征的交代不完整。这主要是限于篇幅和论文主题,而并非作者自珍其密。四年后在同一期刊上,作者发表了另一篇论文,题为 The Development of a World Class Othello Program,完整解释了四项关键特征及其背后的原理。我们也找到此论文的原文,并征得原作者同意,分享给为关注此话题的读者。
阅读一篇 31 年前站在世界之巅的论文,结合当前 AI 领域的巨大进展,遥想公瑾当年羽扇纶巾,这还是一个很有意趣的体验。我们将此文精心译出,正是为了让更多的机器学习爱好者一起体验这份意趣。
▼▼以下是完整论文▼▼
评价函数学习的一种模式分类方法
作者 | Kai-Fu Lee Sanjoy Mahajan
卡内基-梅隆大学计算机科学系
匹兹堡,宾夕法尼亚15213,美国
推荐人 | Paul Rosenbloom
摘要
我们提出了一种实现评价函数学习的新方法,即使用经典的模式分类法。不像其他使用ad hoc法生成评价函数的博弈法,我们的方法基于贝叶斯学习(Bayesian learning),遵循一定的规则。任何可以定义目标和应用评价函数的领域都可以应用这种方法。
这种方法有以下优点:
(1)自动并优化组合特征或评价函数的函数项(term);
(2)理解内部特征的相互关系;
(3)能够从错误特征中恢复;以及
(4)通过评价函数直接估计获胜的概率。我们用黑白棋(奥赛罗)游戏应用了这种算法,其结果与一种意境达到世界冠军水准的线性函数相比,取得了巨大的提升。
1. 简介
大多数成功的博弈程序都使用全广度搜索(full-width search),这种搜索在终端节点[1, 7, 11, 14]应用一个启发评价函数。典型评价函数的形式为:
Eval = C1 x F1 + C2 x F2 +-...+ CnxFn, (1)
其中Eval 是对棋盘局面的静态评价,它是若干特征(F1,F2 . . . . . Fn)经系数(C1, C2 . . . . . Cn)加权后的线性组合。每个特征都是对棋盘局势“优势”的明确估量。在国际象棋中,合理的特征可能为棋子数优势、中心控制以及兵形。在黑白棋游戏中,合理的特征可能为机动性、边位置和棋子中间位置。
上文公式揭示了改进全广度搜索博弈程序的三种方法:
(1) 寻找更好的搜索策略
(2) 选择更好的特征
(3) 更好地组合特征
我们认为前两种方法本身就很好理解。研究人员提出了几种新的全广度搜索策略,例如SCOUT [10]和零窗口搜索[1]。不幸的是,这些方法只有在指数搜索空间中才能恒定的性能提升[7]。选择好的特征至关重要。但是,从专业知识中导出好的特征通常并不是很难[1]。
现在,最厉害的博弈程序依赖于高速的硬件而不是新搜索算法[1,3],依赖于高效的特征分析而不是发现新的特征[1, 7]。因此我们建议,对全广度搜索和特征选择的研究已经达到饱和点,未来博弈程序的成果将在很大程度上依赖于特征组合的好坏。在本文中,我们将介绍一种基于贝叶斯学习的算法,这种算法自动组合特征。
和特征选择不同,特征组合是个非常不直观的过程。一方面,研究人员必须在多种策略之间建立一种不稳定的平衡(例如选择国际象棋中位置优势和棋子优势的权重)。另一方面,必须注意相关特征间的相互作用(例如国际象棋中的兵形和国王安全)。而且,研究人员总是会面临窘境,不是特征太少,就是特征太多(这其中包含相关特征和多余特征)。
可以自动组合特征的算法是由Samuel [12]首先提出的。他引入了一种线性评价函数学习算法,之后又设计了一种基于特征表(signature table)的非线性学习算法[13]。但是,他的算法遇到了一些问题。线性评价函数对特征间关系的理解不够充分。特征表出现由过度量化产生的平滑性问题。
这两种算法最大的问题是:虽然它们去除了调校系数的负担,但是却增加了新的负担,例如选择特征表结果、确定量化的范围和程度以及在学习期间选择函数调整的量和频率。调试程序所需的工作量远远超过了在专家帮助下对系数进行常规的试误法(trial-and-error)调校所需的工作量。最后,由于所需的工作量太过庞大,Samuel的算法高度领域相关。
在本研究中,我们报告一种新的学习算法。和一样,我们的算法学习将特征整合到评价中。但是,不像Samuel的算法那样,我们的算法没有平滑性问题,而且是全自动的,并且不需要进行任何调试。我们的算法基于贝叶斯学习[4]。
(1) 我们积累了大量的游戏作为训练数据。每个游戏由有两位专业玩家进行试玩。
(2) 我们根据某种标准将每个位置标记(手动或自动)为获胜或失败位置。本研究所使用的标准为游戏的实际结果。
(3) 训练程序从标记的训练数据中计算出一个贝叶斯判别函数。该函数试图识别出代表获胜或者失败位置的特征模式。已知某个位置的一组特征值,这个函数给出该位置是获胜位置的概率。
(4) 我们为游戏的不同阶段构建不同的分类器。
我们的算法有五个重要的优势:
(1) 学习过程是完全自动的。不需要调试任何系数或参数,也不需要对特征进行归一化。
(2) 假设多变量正态分布,事实证明,平方组合在训练数据上效果最佳[4]。
(3) 算法不仅考虑特征本身,还考虑他们互相之间如何共变。例如,如果使用的是两个相关特征,将不会同时把它们完全整合到评价中。
(4) 算法在评价中能够从错误信息中恢复。例如,加入一个随机特征并不会降低它的性能。
(5) 它返回获胜概率,并将其作为评价。这个评价是所有评价函数都试图模拟的评价。而且,这种评价可以确证搜索树不同层次上的数值间的比较。
我们在黑白棋游戏中测试了这个算法。我们改进了黑白棋游戏程序BILL 2.0 [7],使其使用相同的特征学习某一评价函数。由于BILL 2.0中的评价经过仔细调试,而且BILL 2.0是最优秀的黑白棋游戏玩家之一,我们预计性能只能获得适度的提升。但是结果表明,几乎从初始位置开始,BILL 3.0(使用贝叶斯学习)战胜BILL 2.0的次数是它战败次数的两倍多。
本试验的平均最后得分为37至27分。我们证明,性能的增加相当于额外使用了两层搜索。在另一个涉及黑白棋游戏问题解决的试验中,BILL 3.0比BILL 2.0多解决了11%的问题,两者都使用的是八层搜索。最后,作为衡量BILL 3.0性能的指标,BILL 3.0以56-8的分数大胜美国得分最高的黑白棋游戏玩家Brian Rose。
在第2部分中,我们将首先讨论构建评价函数的常规方法以及这些方法的缺点,重点介绍Samuel的成果。在第3部分中,我们将详细阐述贝叶斯学习和它在评价函数学习上的应用。在第4部分中,我们将提供黑白棋游戏的结果。第5部分的内容是对评价函数的贝叶斯学习的分析和讨论。最后,第6部分为一些结论性评论。
2. 评价函数的构建
2.1.评价函数在搜索中的作用
自从纽威尔(Newell)、肖(Shaw)和西蒙(Simon)发现阿尔法--贝塔(alpha-beta)关系后,博弈程序的基本模型就几乎没有发生变化[9]。几乎所有的模型仍然依赖全广度阿尔法--贝塔搜索,而且程序仍然在终端节点使用静态评价。
由于大多数程序使用的是类似的搜索策略,评价函数在博弈程序中起着最为关键的作用。评价函数体现程序的智慧,负责区分好的棋步和坏的棋步。而且,由于大多数程序依赖评价函数进行棋步排序,所以好的评价函数得出的搜索就更加高效。
静态评价包括两个阶段:(1)评价棋盘局势的特定特征,和(2)将这些特征分数整合到评价中。特征选择是一个域依赖的任务,并且无法对其进行系统的研究。在本研究中,我们将着重探讨将特征整合到评价中这一论题。特别地,我们将在后文介绍一种自动完成该任务的算法。
通常,静态评价是一个特征的线性组合
EvaI=C1×F1+C2×F2+...+Cn×Fn (2)
其中Eval是对棋盘配置的静态评价,它是若干特征(F 1,F2 . . . . . Fn)经系数(C1, C2 . . . . . Cn)加权后的线性组合。
这个表达有两个问题。首先,它假设特征是独立的,可以将他们进行线性组合。这明显就是一个错误假设。虽然线性关系可以作为一个合理的一级近似,但是我们会在后面证明,列入非线性关系可以大幅提升性能。
事实上,我们还将证明,每对特征都在某种程度上是互相关联的。而且,通常使用ad hoc法得出系数。在很多情况下,构建函数的人借助他的领域知识猜测这些函数。即使他们的确懂行,但是由于人类从阿尔法--贝塔搜索和静态评价的角度进行思考。当构建函数的人不那么懂行时,他就会毫无思绪。这就是西洋跳棋新手Arthur Samuel编写西洋棋学习程序的最初动机。
2.2. Samuel的评价函数学习试验
1947 年到1967年期间,Arthur Samuel在西洋跳棋上对机器学习进行了一些最早、最深入的研究[12, 13]。他的目的和本研究的目的十分类似,即已知某一棋盘局势的一组特征,给出衡量棋子位置好坏的分数。虽然他进行了很多试验,但是我们将着重介绍最为重要的两个试验:(1)通过自我模拟进行多项式评价学习,以及(2)通过book moves互相非线性特征表评价学习。在接下来的两部分中,我们将对这两个过程进行描述和评价。
2.2.1.通过自我模拟进行多项式评价学习
在多项式评价学习中[12],Samuel安排了西洋跳棋程序的两个副本进行对抗,学习线性评价函数中每个特征的权重。其中一个程序副本Beta自始至终使用一个固定的函数。另一个副本Alpha则不断改进它的评价函数。Alpha通过将它所作的评价与更加准确的评价作对比来进行学习,后者是使用极小极大搜索得出的。如果搜索返回的数值比静态评价高得多,那么就假设静态评价出现了错误。通过减小权重来惩罚静态评价中的每个消极特征。
Alpha和Beta原本是完全相同的,Alpha不断提高自己的权重。在每场游戏结束后,如果Alpha打败了Beta,那么就假设Alpha更好,Beta采用Alpha的评价函数。相反,如果Alpha在某三场游戏中都败给了Beta,那么就假设Alpha出现了错误,然后将它首项的系数设置为0,使它恢复正常。而且,如果“Alpha的学习过程明显运行不正常”,则需通过手动干预来使它恢复先前状态。
当Alpha在多场游戏中连续战胜Beta时,这个学习算法得出的评价函数似乎趋于稳定。最终程序试玩西洋跳棋游戏的表现出优于平均水平。这个学习过程是机器学习的早期范例之一。但是,它的正确性是以几个错误假设为依据的。
这些假设中的第一个就是:好的评价函数可以定义为独立特征的线性组合。
这个假设是不可靠的,而且在其中显得尤其错误,因为他有目的性地收集多余特征。例如,如果Samuel的学习过程考虑了两个完全相同的特征,那么就会给定这两个特征相同的权重,这会导致特征值的高估。而且,线性评价函数无法采集特征间的关系。通过重复Samuel的试验,Griffith [5]证明,通过一个极其简单的启发式棋步排序过程可以提升性能。
第二个假设是:当搜索和静态评价不一致时,那么静态评价一定出现了错误。
虽然深度搜索一般比浅搜索更加准确,但是这种假设在几种情况下会不成立。如果某个位置出现问题,那么可能只有通过向前搜索若干层才能发现这个问题。在这种情况下,则应容许静态评价维持错误状态,因为通常我们无法将这种向前搜索的知识编码到静态评价中。而且,搜索可能会受到“地平线效应”(Horizon Effect) [2]的影响,导致生成不准确的评价。
第三个假设是:如果发现评价函数过度乐观,则假设任何积极成分都出现错误。
这明显是错误的,因为在大多数位置上,每位玩家都在某些特征上领先对手,但是却在其他特征上落后于对手。错误的评价可能是由消极成分导致的,但是这些成分并不足够消极。仅仅检查记号是不够的。
最后,这个过程假设:如果玩家A战胜玩家B,一定是因为玩家A的评价函数优于玩家B。
这个假设可能对于专业玩家而言是合理的,但是当新手程序互相对抗时,获胜的原因可能是:
(1)更加优秀的评价函数;
(2)运气(当两个玩家都不理解局势时);或者
(3)对手失误。由于Samuel的程序的游戏水平相当于新手,那么它获胜的原因通常是因为运气或者对手的失误,从而导致错误的信度分配。由于多项式学习涉及爬山法(hill-climbing),所以信度错误分配的问题尤为严重。
2.2.2.通过棋谱走法(book moves)进行特征表学习
Samuel认识到了这些问题,因此他设计了另一个学习过程,这个过程纠正了大部分问题[13]。为了处理特征间的非线性相互作用,他引入了特征表;为了处理自我模拟中的错误假设,他使用了棋谱走法。
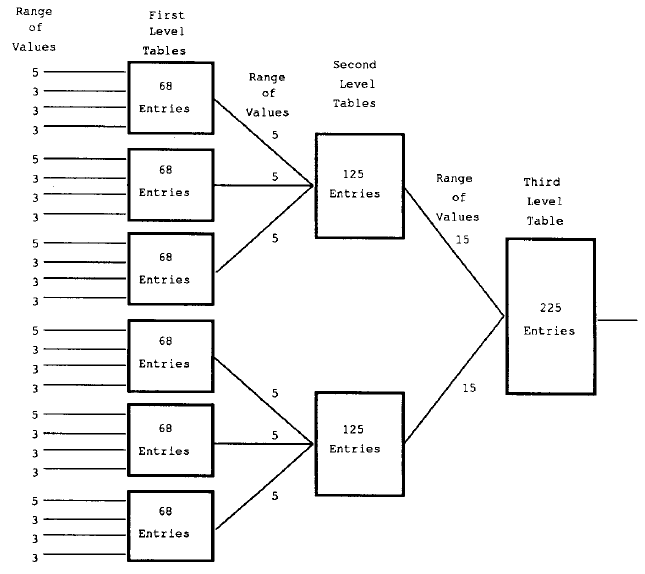
特征表是非线性组合特征的多量纲表。每个量纲代表某种特征。在评价某一棋盘局势时,每个特征的值都用来将索引编入特征表中,对应这个索引的单元格包含评价。这个方法最明显的问题在于表会变得非常大。Samuel通过使用分层结构解决了这个问题,并且将特征分为四个一组的集合。
仅考虑内部集合间的相互作用。然后每个集合从索引单元格中生成一个数值,这个单元格的索引由四个特征值创建而成。下个更高的层级中的表使用这些数值,就好像它们是特征一样。共有四级。但是这样仍然会生成非常大的特征表,因此Samuel对特征值进行了量化。在每个最低层级的特征表中,其中三个特征的数值限制在(-1,0,1)间,剩下的那个特征的数值则限制在(- 2 , - 1 , 0 , 1 , 2)间。
这就得出了图1中的最终结构。这个结构包含883个单元格,这对于存储和训练来说都是合理的。
从棋谱走法开始训练这些单元格。我们将高手下棋所用的棋局输入到程序中。目的是使特征表学习模仿高手下棋。记下与高手所选走法的特征组合相一致的单元格的数量(用A表示),以及与高手所未选的合理走法的特征组合相一致的单元格的数量(用D表示)。实际的单元格数值通过计算(A- D)/(A + D)进行周期性更新,我们用这个数值衡量单元格遵从棋谱走法的程度。
特征表方法成功地添加了非线性学习;棋谱学习法成功地消除了自我模拟的错误假设。所得程序的性能远远优于用棋谱学习训练的线性函数的性能。
但是,特征表方法仍有一些新的问题。首先,这种方法作出两种假设:(1)棋谱走法总是最佳走法;以及(2)无任何同样好的其他走法。由于这些游戏的玩家都为高手,因此不采用失败一方的走法。
它们都是合理的假设,但是肯定不是绝对可靠的假设。通过使用足够大的训练数据集,我们可以将这些问题减至最少。
一个主要问题是,特征表在量化过程中会丢失相当多的准确性。过度量化的风险很大。例如,如果某人要将国际象棋中的实质性差异量化为3个或5个数值,那么在失去“象”和失去“后”等同时,他又怎么能预期作出正确的走法?而且,过度量化违反了Berliner的平滑性原则(smoothness principle)[2],因此引入了瑕癖效应 (Blemish Effect)。在Berliner的书中,某个特征的数值即使发生很小的改变也会导致函数的值发生非常大的改变。当程序有能力操控这样一个特征时,它就会就会运用这种能力,从而给自身带来伤害。
将特征表过度量化到少数层级也正好有这个问题。
虽然损失了平滑性,但是特征表学习仍然没有提供线性问题的通解。例如,当两个特征完全一样(或者高度相关)时,如果这些特征(F1和F2)的组合方式如图2(a)所示,那么它们在表1中的冗余度就会被成功消除。但是,如果它们的组合方式如图2(b)所示,那么F1就会编入表1,F2则会编入表2。但是,表3并不能消除它的冗余度,因为它无法知道它的两个输入是否受F1和F2或者其他特征的影响。这就导致了对这个特征的效用的高估。由于同样的原因,我们认为高层级的特征表并没有多少用处,因为它们无法识别出自身输入的贡献特征,因此也就无法处理特征表之间的关联。
因此,谨慎安排特征表的结构是很重要的,这样才能捕捉共变。而且,必须确定各级量化的范围和层次、单元格中的初始值和这些数值更新的频率以及许多其他要素。
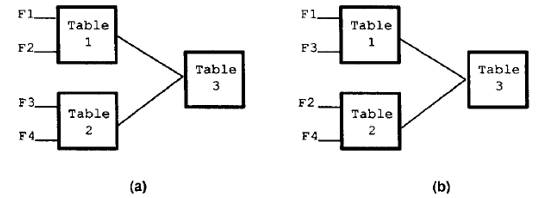
图2.如果F1和F2为相同特征,(a)中的特征表结构将会消除它们的冗余度,但是(b)中的特征表不会这样做。
这就是我们所认为的这两个过程的最大缺点,即需要进行过多的人为设定初值和干预。每个参数都增加了出现影响学习过程的人为误差的可能性,还增加了得出并测试这些数值所需的时间。结果,学习效果要么由于人为误差而很差,要么就是由于过度的人为干预而差强人意。
所有这些启发式调试使Samuel 的学习过程受领域限制。如果某人想在另一领域应用这个学习过程,那么他必须在学习算法中使用相当多的该领域的知识,并且必须在对参数进行试误法修正上花费相当大的精力。这明显很不理想。
最终,Samuel 的算法学习的概念并不理想他的自我模拟算法根据搜索学习区分好特征和坏特征。他的棋谱算法学习区分专家所选的走法和专家未选的走法。但是,在博弈游戏领域,最优的概念是学习区分获胜位置和失败位置。
总之,Samuel的研究是早期机器学习研究中的一个里程碑,我们认为,大量的监督使他的研究变得不实际并且受限于领域。这些主要缺点加上Samuel问题重重的假设、平滑性问题以及不理想的学习共同严重限制了他的学习过程的可行性和应用性。
2.3.针对自动组合特征的其他研究
Griffith最先想到特征表这个方法,他报告了大量的国际象棋评价函数学习结果[5]。他比较了线性评价函数学习、特征表学习的两种变形以及一种启发式棋步排序算法。他证明了,虽然启发式棋步排序算法只有极其基础的国际象棋知识,但这种算法的性能优于线性评价函数,却差于非线性特征表算法。
Mitchell [8]进行了另一项研究,他使用回归分析法在黑白棋游戏中创造了一个线性评价函数。得出的程序并未达到预期的游戏水平。我们猜想,这是由于(1)他的程序未使用搜索;(2)他的程序缺乏非线性特性。
这些结果都证明线性评价函数有缺陷。但是,由于平滑性问题和需要进行过多调试,特征表方法也存在缺陷。
3.评价函数的贝叶斯学习
在本部分中,我们将介绍一种自动组合特征的算法。首先,我们先向不熟悉贝叶斯学习的读者介绍这个概念,接下来再简短介绍一下黑白棋游戏和黑白棋程序BILL。最后,我们将介绍基于贝叶斯学习的评价学习算法,这种算法适用于黑白棋游戏。
3.1.贝叶斯学习
判别函数的贝叶斯学习是一种用在模式识别中的标准方法。通常,它被用于识别和分类具体对象,例如字符、图像、语音和震波。假设采用多元正态分布,判别函数定义类别间的判定边界。在双类别问题中,这条边界上的所有点属于每一类别的可能性都相同。这条边界是由训练数据的特征向量自动计算出的, 它考虑特征的方差和协方差。该边界由两个阶段构成,即训练阶段和识别阶段。
3. 1. 1.训练阶段
该训练阶段是一个简单的参数估计阶段。需要一个已标记训练数据的数据集。每个训练样本包含一个特征向量和一个表明特征向量所属类别的标记。训练阶段的任务是估计训练数据的每个标记(或类别)的均值特征向量和协方差矩阵。
类别c的均值向量(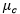

其中,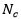
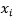
类别c的协方差矩阵(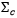
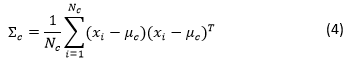
其中T是矩阵转置操作。
3.1.2.识别阶段
推导均值向量和协方差矩阵的逆矩阵公式,可得出某一分布的一般多元正态密度函数p的计算公式,如图(5)所示:
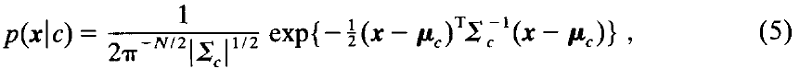
其中x是N-元特征向量,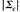
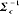
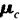
贝叶斯法则表明,使用判别函数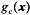

其中P(c)是类别c的先验概率。用(5)替代(6),我们可得出:
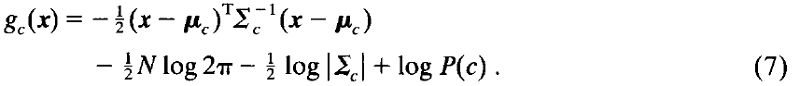
为了判别某一新特征向量属于哪一类别,计算每个类别的g,将新的输入特征向量分配给g值最大的类别。另外,如果优先使用概率(P)作出困难的决策,那么可通过归一化 g(x) 得出概率(P):
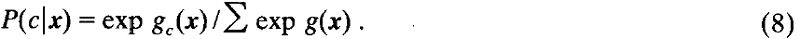
3.2.黑白棋游戏和BILL
在解释如何将贝叶斯学习应用于评价函数学习前,我们先简要介绍一下我们的试验领域,黑白棋游戏。
黑白棋游戏是一种二人(黑棋和白棋)对弈的游戏,它使用的是8 x 8的棋盘。游戏开始前先按图3布置棋盘。黑棋先在棋盘的任一格子上走一步黑色棋子(黑色面向上的棋子),黑棋可以使白棋翻转。这个黑棋与任何其他黑棋之间的每个被俘获的白棋都要翻转为黑棋。双方交替在棋盘上落子,直到一方无棋步可下。棋盘上棋子最多那一方的就为获胜方。
黑白棋游戏一直都是一种非常适合计算机实现的游戏,因为它相对较小的分支因子,以及游戏规则的编程较为容易。这种容易是由于黑白棋游戏对于人类玩家较为难玩。黑白棋游戏难玩是因为每走一步后棋盘局势会发生非常大的改变,某些策略是违反直觉的。
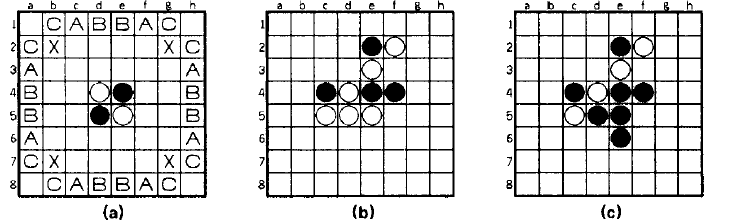
图3(a)显示了黑白棋棋盘的初始布置以及格子的标准名称;图(b)显示了一个简单的棋局中,移动黑棋到c6、d6、d2、e6和g2的合规走法;图(c)显示了黑棋走到e6后的棋局。
1981年,Rosenbloom [11]证明了编写世界冠军水平的黑白棋游戏程序的可能性。IAGO的评价包含边稳定性、机动性和潜在机动性。在1986年,Lee和Mahajan [7]编写的另一个程序BILL连续战胜了IAGO。BILL在1986年北美锦标赛中获得了第二名的成绩,它是世界上最优秀的黑白棋玩家之一。BILL的游戏水平归功于它使用的评价函数高效且准确,这个评价函数利用预先编辑的知识使用特征表。BILL 2.0使用四组特征表,也就是四个特征。这些特征为:
(1) 加权当前机动性衡量玩家每一步棋的数量和质量。所有的棋步都使用特征表,对较差的棋步进行适当的惩罚。
(2) 加权潜在机动性衡量玩家未来棋步的优胜程度。使用考虑各棋子周围棋子的特征表。
(3) 加权格子衡量玩家每个棋子占据的格子的优胜度。使用静态衡量标准(中心格子好于靠边格子)和动态衡量标准(围住的棋子好于外围棋子)。
(4) 边位置使用包含每一边上的特征组合的特征表衡量玩家的边位置。这个特征表由概率极小极大过程生成[7]。
感兴趣的读者可查看[11]或[7]了解黑白棋策略分析。
BILL 2.0将这些特征线性组合在一起。通过创建十个不同的版本并在这十个版本间举行比赛,决定线性组合中的权重。将赢得比赛的版本选为最终的系数集。我们将在相同的四个特征上应用贝叶斯学习,通过将所得程序与BILL 2.0作对比来衡量该程序的性能。
3.3.评价函数学习
我们现在将介绍一种评价函数学习算法,这种算法使用的是第3.1节中所描述的贝叶斯学习。我们的应用和典型应用的关键区别在于:
学习(训练)
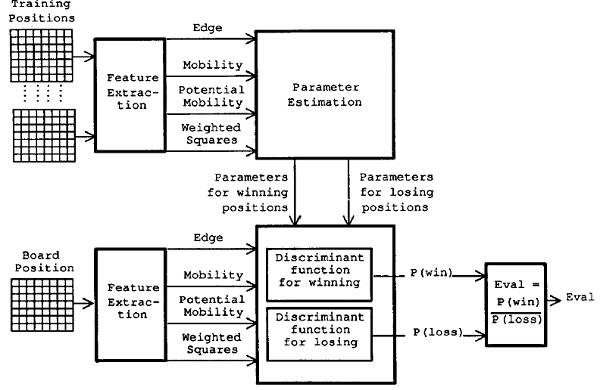
评价(识别)
图4. 提出的基于贝叶斯学习的评价函数学习算法的学习和评价过程
我们试图将棋盘位置识别并分类为获胜位置或失败位置,而不是识别具体对象。我们算法的基本思路如图4所示。和贝叶斯学习类似,这个算法包含两个阶段,即训练(学习)阶段和识别(评价)阶段,我们将在接下来的两部分中阐述这两个阶段。
3.3.1.训练阶段
为了训练贝叶斯判别函数,我们需要一个位置数据集,这个数据集中的每个位置都被标记为“获胜位置”和“失败位置”。获取这个数据集的方法有很多种。在本研究中,我们从两位专家进行的实际比赛中获取训练数据,获胜方的每个棋子位置都被标记为“获胜位置”,失败方的每个棋子位置则都被标记为“失败位置”。尽管这是一个简单且一致的方法,但是它存在一个严重的问题:获胜位置可能因为之后的棋步较差而丢失,并且会被错误地标记为“失败位置”。
我们可以通过两种方法解决这个问题:第一种方法需要可靠的黑白棋专家。由于BILL 2.0是一个世界冠军级别的玩家,我们只需从初始位置起使它进行自我模拟来生成训练数据。第二种方法:为每场比赛生成20个初始棋步,在下完这20个随机棋步后开始进行训练(或者在棋盘上摆有24个棋子之后)。通常,在下完20步后其中一位玩家便会领先,并且他会在最后赢得这场比赛。在位置真正均衡时,充足的训练数据应该得到相同数量的获胜标记和失败标记。
为了生成训练数据,在以下情况中须设置BILL 2.0进行自我模拟:开始的20半步随机生成,然后BILL 2.0的每一方有15分钟的时间走完剩下的40半步[2]。当只剩下15半步时,执行终局搜索,寻找获胜方,前提假设双方发挥完美水平。终结比赛并将其记录为训练数据。再通过进行3000场比赛来预测参数。
众所周知,黑白棋游戏的不同阶段需要不同的策略 [2]。因此,我们为每个阶段生成一个判别函数,其中每个阶段由棋盘上的棋子的数量定义。N个棋子的阶段的判别函数由共有N-2、N-1、 N、N+ 1和N+ 2个棋子的训练位置生成[3]。由于每场黑白棋游戏中几乎总是进行60步,通过统计棋子数量可以准确估计游戏的阶段。通过合并相邻数据,判别函数进行缓慢变化,这类似于Berliner提出的应用系数[2]。
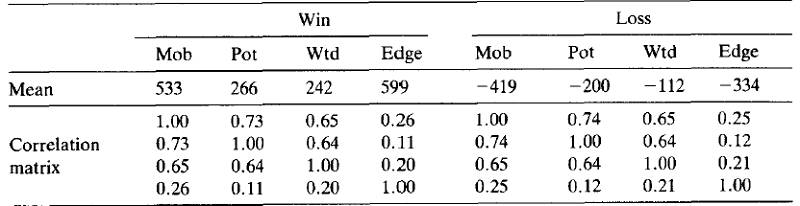
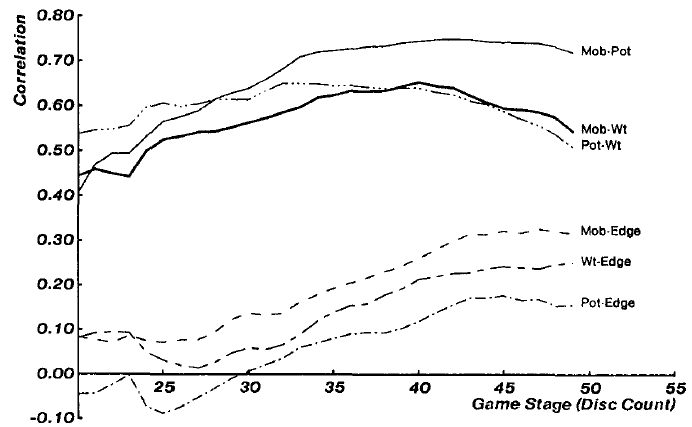
在生成训练数据后,从数据集中的每个位置中提取四个特征。然后,估计“获胜”和“失败”这两个类别中的特征间的均值特征向量和协方差矩阵。表1在N = 40显示获胜和失败位置的均值向量和相关矩阵。它们显然支持我们先前的说法,即每对特征都在某种程度上相互关联,并且非线性关系对评价函数的成功至关重要。
表1:获胜和失败类别在第36步的均值向量和相关矩阵;Mob:机动性;Pot:潜在机动性;Wtd:加权格子;Edge:边位置
3.2.2.评价阶段
棋盘位置的评价涉及特征的计算,以及将特征向量x整合到最终评价中。在第3.1.2节中,我们已知“获胜”和“失败”类别的两个判别函数分别为:
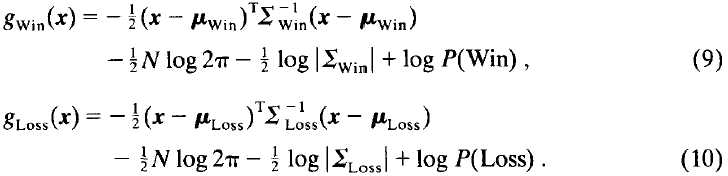
评价函数应该估量棋盘位置属于获胜类别的概率,或者:

我们将(9)和(10) 代入到(11)中。消除常数。另外,我们假设“获胜”和“失败”类别的先验概率相等,并消除log P(Win) 和 log P(Loss)。这就得出了最终的评价函数:
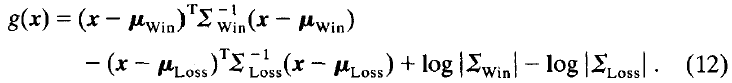
是一个用于对数量进行归一化的常数,如果所有评价使用相同的常数,那么就不一定要有这个常数。但是如上所述,须为游戏的每个阶段估计不同的参数集;因此,消去这个常数项会导致搜索树的不同层级有不同的评价范围。这样的话会很不方便,因为我们的搜索中的某些界限要求一个一致的范围[7]。因此,保留这个常数项。而且,通过保留这个常数项,当程序报告它的评价时,我们也许可以直接从g(x)中计算出获胜的概率:
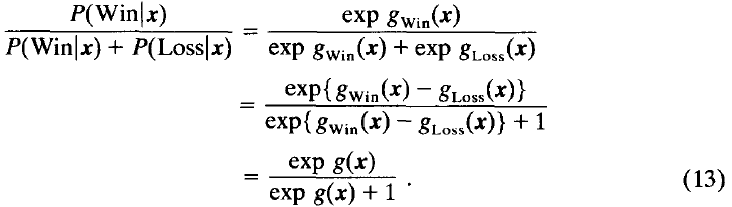
让我们总结一下我们的评价过程。在搜索的每个终端节点上,算法计算出四个特征并将它们整合到g(x)中,g(x)如图(12)所示。由于协方差矩阵用于确定最终函数,因此不必手动对特征进行归一化。实际上,乘以逆协方差矩阵就是归一化过程。在完成每次迭代加深的搜索后,g(x)都被转化为 ,如图(13)所示,是一个对人类而言更有意义的衡量标准。
4. 结果
在本部分中,我们将阐述分别用两个版本的黑白棋程序(BILL)进行的两个试验。第一个版本是BILL 2.0,这个程序线性组合四个特征,并且其游戏水平为世界冠军级别。另一个版本BILL 3.0使用相同的四个特征,但使用上一部分所描述的贝叶斯学习组合这些特征。
评价和比较博弈程序的方法有很多种,包括:
(1) 让程序相互对弈;
(2) 给程序设定有已知解决方法的问题;
(3) 让程序与人类专家对弈。我们将介绍分别使用这三种方法的评价。
4.1. BILL 2.0对抗BILL 3.0
比较两个程序的最明显的方法就是安排这两个程序相互对弈。我们在下列条件下安排BILL 2.0对战BILL 3.0:棋盘上20个棋子所走的100个几乎均衡的位置选自BILL 2.0的开局书。BILL 2.0在每个位置上与BILL 3.0对弈两次,一次作为黑棋一次作为白棋。每一方都在25分钟内走完所有棋步。BILL 3.0在200局比赛中共赢了139局,平6局,败55局。平均分数为36.95到27.05。
结果表明,贝叶斯学习明显优于调校后的线性评价函数。实际差异可能甚至更大,因为尽管所有初始位置都接近,但是某一种颜色可能注定取得胜利。这样,每个程序在用那种颜色的棋子进行比赛时都会取得胜利。我们还将贝叶斯学习与使用回归生成的线性函数作对比。正如预期的那样,结果显示贝叶斯非线性更好,尽管双方差距很小。
为了探明贝叶斯学习究竟起了多少效用,我们使用不同版本的BILL 2.0从相同的初始位置起开始相互对弈,各版本的程序搜索的深度不同。结果如表2所示。由于上述条件使BILL搜索6-8层,如果BILL 2.0多搜索两层,那么它的水平就会与BILL 3.0大概相当。黑白棋中的有效分支因子在3.4和3.7之间,这意味着如果BILL 2.0的时间是BILL 3.0的13倍,那么的水平就会和BILL 3.0一样好。13这个因子使非线性函数损失了更多的性能。每个版本的程序都在相同的规定时间走完自己所有
表2:两个版本的BILL对弈的结果
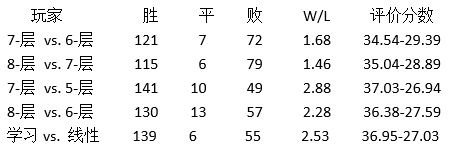
的棋步,通常为25分钟。由于非线性版本的程序拥有更复杂的特征组合过程,因此它搜索的节点较少,但是它相较于其他版本仍然多出2层(或13因子)的性能。如果每个版本都搜索相同数量的节点,而不是使用相同的时间,那么非线性版本的性能将会获得更大的提升。
4.2.终局问题
由于黑白棋在距离游戏结束还有很多棋步可走时可以达成终局,我们可以根据某一程序选择(无需搜索到最终节点)得出最佳结果的棋步的频率,来推断出该程序的性能。这个方法存在一个问题:当达到终局时,已知的黑白棋策略会变得不再那么适用,而且有时还需走出违反直觉的棋步。为了尽可能减小这个问题,我们获取了一个有63个获胜位置并且剩余20-24步可走的棋局数据库,剩下的每个棋步都可以得出领先最多分数的获胜结果。这个数据库是由Clarence Hewlett建立的硬件终局搜索器生成的[6]。
BILL的线性版本个贝叶斯学习版本都设定了这些问题,每个版本都使用3-8层的搜索得出最佳棋步。它们同意选择最佳棋步的频率如表3所示。在进行比赛的情况下,BILL可以在游戏的这个阶段大概搜索8层。因此如果问题出现在实际比赛中,那么BILL 2.0和BILL 3.0将分别解决55%和64%的问题。
表3:两个版本的BILL同意最佳棋步的概率以及确保得出最大胜出差距的棋步
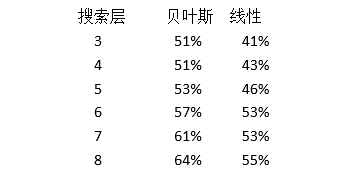
为了评价这些数字,我们应知道某些最佳棋步可能仍然是违反直觉的。更为重要的是,很多棋步通常仍保留一个获胜位置,这些位置的胜出差距可能相同。不幸的是,我们没有足够的信息来估计差棋步导致失败的频率。但是上述统计数据表明,贝叶斯学习毫无疑问更好。
4.3. BILL对弈人类专家
将BILL与人类专家作对比的一种方法是在最后比较他们解决终局问题的性能。这些位置中有19个取自世界顶级高手间的六场比赛。我们发现,人类专家的棋步中正确的有九步,错误的有十步,准确率为47.36%。借助8层搜索,BILL 2.0和BILL 3.0分别破解了63%和68%的位置。这表明,两个版本的BILL的水平都高出人类专家很多。
由于上述样本太小,无法得出BILL与人类专家比较游戏水平的结论,因此我们邀请了美国排名最高的黑白棋玩家Brian Rose与BILL 3.0进行一场比赛。结果,BILL 3.0以56比8的成绩大胜Rose。
Jonathan Cerf曾在1982年表示,IAGO即使比不过最优秀的人类玩家,也与他们不相上下。由于BILL的性能要比IAGO高出很多,因此我们对BILL战胜Rose并不感到意外。
5.讨论
5.1.贝叶斯学习的优点
在本部分中,我们将通过对比贝叶斯学习和Samuel的算法来讨论贝叶斯学习的优点。表4显示了Samuel的两种算法与贝叶斯学习算法的对比情况。
表4:Samuel的算法与贝叶斯学习算法的对比
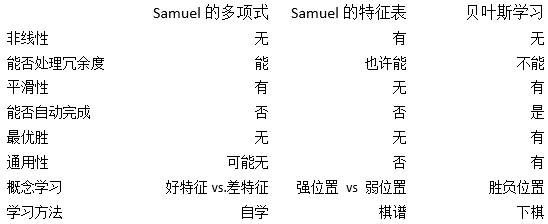
尽管这三种算法都用来解决相同问题,但是它们之间存在许多较大的差异。
第一个较大的差异就是线性。Samuel的多项式学习算法学习的是线性函数。这种算法假设所有的特征都是相互独立的,我们已经证明这种假设是不成立的。如果将两个完全相同的特征输入到他的算法中,这个算法会向这两个特征分配相同的权重,这样就会导致效用在总体上被高估。特征表表学习是一种合理的非线性近似法。
但是,正如第2.2.2小节所述,只有在对特征表的结构进行仔细安排后,特征表学习中的非线性才会发挥作用。即使这样,不同特征表的特征之间的相互关系也会丢失。如果没有为两个完全相同的特征正确安排位置,那么它们的效用仍会被高估。正因为如此,需要通过人为干预来估计冗余度和确定特征表结构。
在最糟糕的情况下,所有的特征都将在很大程度上相互关联,并且必须放在相同的特征表中。显然,这种算法并不理想,因为这个特征表将会扩大到不合理的程度。但是,贝叶斯学习方法可以通过考虑特征对之间的协变来理解非线性关系。这种算法总是能够发现冗余特征并解释特征间的所有交叠。
在上一部分中,我们在非线性评价函数的使用中看到了巨大的性能提升。为了说明线性评价函数不够理想的原因,图5显示了每对特征间的相互关系。尽管这四个特征分别取自于棋盘的不同特性,但是我们发现它们高度相关,尤其是机动性、潜在机动性和加权格子。如果对这些高度相关的特征进行线性组合,后果将会不堪设想。
另一个差异是平滑性。Samuel的多项式算法很流畅,因为它使用的是自然特征。但是特征表学习中的过度量化使会这种算法失去平滑性。平滑性的缺失会导致这样一种结果:搜索空间中某一特征只要发生微小变化,评价就会发生明显改变。相比之下,贝叶斯学习学习的是一个平滑函数,这个函数对某一位置属于获胜类别和失败类别的可能性进行估量。
Samuel的这两个算法还存在一个严重的问题:它们都需要进行额外的调校和监督。而贝叶斯学习则是完全自动的。由于对特征组合的调校非常不直观,因此自动化是一个非常必要的属性。而且,贝叶斯学习在假定多元正态分布的情况下可提供最优的正交组合。[4]
获胜位置
失败位置
图5.获胜位置和失败位置的每对特征间的相互关系作为游戏阶段的函数
Samuel的过程的另一个问题在于它们没有充分说明游戏的各个阶段。
我们在图6中估量了每个特征的效用,该图显示,如果孤立地使用特征,那么每个特征的训练因子都被正确地归类为获胜位置或失败位置。显然,游戏的阶段会对特征的相对重要性造成影响。图5显示的相互关系的改变进一步证明了对游戏阶段进行精确却缓慢变化的估量的必要性,我们通过为每个阶段生成一个判别函数来进行这种估量。注意,我们可以通过修改
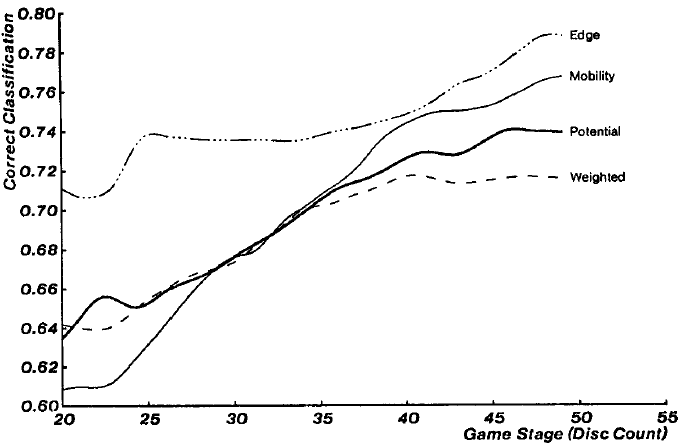
图6.经每个孤立使用的特征正确分类的训练位置所占的比例作为游戏阶段函数
Samuel的学习过程生成了很多学习阶段;但是,这会增加早已非常庞大的训练位置数(180000)。
Samuel的学习过程和我们的学习过程有个有趣的差异:学习的概念不同。Samuel的多项式学习试图通过惩罚导致失误决策的特征来区分好坏特征,在这种学习中,特征的好坏由它与深层搜索是否一致决定。特征表学习试图区分强位和弱位,在这种学习中,强位来自于专家所走的棋步,弱位来自于专家未选择的合规棋步。贝叶斯学习试图学习获胜位置和失败位置的概念,在这种学习中,获胜位置指的是达成最终胜利的位置,失败位置则指的是那些造成最终失败的位置。由于任何游戏的目的都是赢,因此模拟获胜位置对比失败位置要比构建好特征对比坏特征更合理。
最后,三种方法的训练方法都各不相同。Samuel的多项式学习算法使用自我模拟生成训练数据。由于这是一个渐进式爬山算法的过程,该算法可能很可能会聚集到局部最大值。特征表学习则更加全面;但是,源自棋谱棋步的训练会受到限制的影响。首先,虽然专家的棋步通常提供好的正面范例,但是使用专家未选择的所有棋步作为负面范例的做法具有误导性。其次,通过学习来模拟专家的棋步,这样评价函数在理论上则不可能会超过专家的下棋水平(不借助搜索)。在本研究中,获胜位置和失败位置的使用提供了很好的正面范例和反面范例。
而且,通过构建“达成胜利的棋步”(而不是“专家选择的棋步”),我们的评价在理论上就可以优于完成训练游戏的专家。
5.2.贝叶斯学习的问题
5.2.1.多元正态分布假设
贝叶斯学习的简单和高明在很大程度上是由于对数据潜在分布的假设。为了使我们的算法能正常运作,特征的分布必须为多元正态分布。为了验证这个假设,我们在图7中显示了3000个训练游戏中的四个特征的分布。粗曲线是获胜位置的分布,细曲线是失败位置的分布。这些位置取自于棋盘上有24个格子的位置。这些数字清楚地表明,这个假设是合理的。
5.2.2.标记的准确性
另外还有这样一个问题,获胜/失败位置的标记过程可能不是很准确,标记错误很可能会给贝叶斯学习的性能造成消极影响。由于BILL的终局求解能力,有15个格子的位置一向都很完美,但是更早的位置可能会出现错误。但是,我们认为我们的标记方法是合理的,因为:
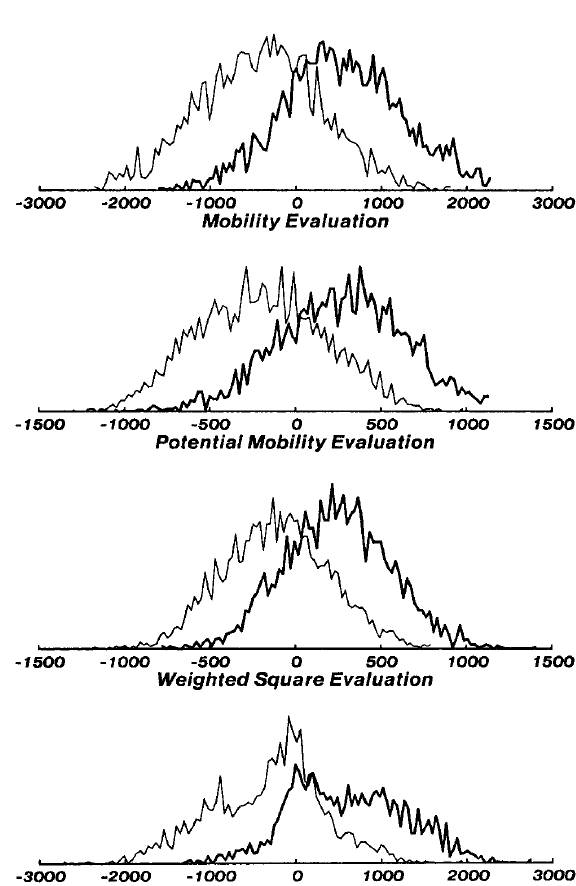
图7.所使用的四个特征的获胜/失败位置分布
(1) 许多模式分类过程使用手动标记的训练数据,由于人为误差或偏向,这些数据未必准确。
(2) 由于BILL 2.0下黑白棋的水平可能胜过任何专家,这是可用的最好的标记方法。
(3) 前20步随机棋步应该会生成许多不是很接近的位置,在这20步内领先的一方几乎总能获胜,因为BILL的下棋水平非常高。
(4) 几乎均匀的位置很难标记;但是,假设拥有足够的训练数据,这些位置就会形成一条界线,在这条界线上很难区分获胜位置和失败位置。
5.2.3.贝叶斯学习的效率
评价函数贝叶斯学习的最大的问题可能就是效率问题。每个评价函数都需要计算逆协方差矩阵乘以特征向量四次。由于矩阵都是对称的,组合特征需要的浮点相乘次数为2N(N + 1),其中N为特征数量。这样,特征数量很多就会严重拖慢程序的运行速度。而且,如果特征数量很多的话,准确估计参数就需要更多的训练数据。
我们可以使用主成分分析法(Principal components analysis)[4]减少特征空间的维度,从而解决这个问题。这种分析将特征空间转为一个有独立特征的空间,我们可以舍弃不重要的特征(那些方差较小的特征)。另一种类似的方法是使用费雪线性判别(Fisher's linear discriminant)[4],这种判别使用标记的训练数据将类别间方差和类别内方差之比降至最低。
5.3.对其他领域的适用性
贝叶斯学习早已被应用到语音识别、视觉识别和字符识别以及许多其他领域中。本研究首先使用贝叶斯学习学习评价函数中的特征组合。使这项应用成为可能的关键概念是:我们使用贝叶斯学习最大限度地对获胜位置和失败位置进行分类。
这个算法适用于任何其他游戏以及任何其他基于搜索且使用静态评价的应用:
(1)必须使用好的特征;
(2)必须能够对类别定义目的;
(3)多元正态分布必须提供合理的拟合。
任何成功的程序都须具备第一个条件。在计算机游戏程序中,满足第二个条件很容易,因为获胜类别和失败类别是学习的理想概念。在其他领域可能就较为困难。大多数领域都能满足第三个条件。
虽然我们使用不同版本的BILL生成训练数据,但是这种做法不一定可取。在计算机很难理解的游戏中,例如围棋,自我生成训练数据将会造成许多位置标记不当。但是如果是那样的话,使用水平更高的玩家间的游戏应该会实现更好的性能;但是,在这种情况下是不可能的,因为在黑白棋领域未必存在这样的玩家。但是在围棋领域,人类的水平要比程序高得多,使用专家完成的游戏进行训练将会更大地提升程序的游戏水平。
6.总结
在本论文中,我们介绍了一种组合评价函数的项或特征的新算法。这种算法基于贝叶斯学习。首先须获取一个训练数据库,再将每个位置标记为“获胜位置”或“失败位置”。用这些位置训练一个判别函数,这个函数通过估计某一位置是获胜位置的概率来评价这个位置。
虽然有人曾研究过评价函数的机器学习,但是他们的算法,例如Samuel的算法,都存在以下缺陷:缺乏平滑性、过多的人为调校和缺乏普遍适用性。贝叶斯学习解决了这些问题并且还具有一些理想的特点:
(1) 完全自动地学习训练数据;
(2) 最佳正交组合;
(3) 理解特征协方差;
(4) 能从错误特征中恢复;
(5) 直接估计获胜概率的评价。
我们证明了贝叶斯学习能大幅提高黑白棋程序的游戏水平——早已是世界冠军水平。我们认为这种算法可以应用到任何需要进行静态评价的领域中,并且它不仅会大幅减少调校时间,而且还会大幅提高程序的性能。
致谢
作者希望感谢Hans Berliner为本文提供了有用的讨论并且阅读了本文的草稿;感谢Roy Taylor和Beth Byers阅读本文的草稿。
国家科学基金会(National Science Foundation)研究生奖学金为本研究提供了部分赞助。本文中所表达的纯属作者的观点和结论,不应被明示或暗示地解释为代表美国国家科学基金会的官方政策。
参考文献
1. Berliner, H. and Ebeling, C., The SUPREM architecture: A new intelligent paradigm, Artificial Intelligence 28 (1986) 3-8.
2. Berliner, H., On the construction of evaluation functions for large domains, in: Proceedings IJCAI-79, Tokyo, Japan (1979) 53-55.
3. Condon, J.H. and Thompson, K., Belle chess hardware, in: M.R.B. Clark (Ed.), Advances in Computer Chess 3 (Pergamon Press, Oxford, 1982).
4. Duda, R. and Hart, P. Pattern Classification and Scene Analysis (Wiley, New York, 1973).
5. Griffith, A.K., A comparison and evaluation of three machine learning procedures as applied to the game of checkers, Artificial Intelligence 5 (1974) 137-148.
6. Hewlett, C., Report on a hardware computing system dedicated to the game of Othello, Othello Q. 8 (2) (1986) 7-8.
7. Lee, K. and Mahajan, S., BILL: A table-based knowledge-intensive Othello program, Carnegie-Melon University, Pittsburgh, PA (1986).
8. Mitchell, D., Using features to evaluate positions in experts' and novices' Othello games, Master Thesis, Northwestern University, Evanston, IL (1984).
9. Newell, A., Simon, H. and Shaw, C., Chess playing programs and the problem of complexity,
in: E.A. Feigenbaum and J. Feldman (Eds.), Computers and Thought (McGraw-Hill, New
York, 1963).
10. Pearl, J., Heuristics: Intelligent Search Strategies for Computer Problem Solving (Addison- Wesley, Reading, MA, 1984).
11. Rosenbloom, P.S., A world-championship-level Othello program, Artificial Intelligence 19 (1982) 279-320.
12. Samuel, A.L., Some studies in machine learning using the game of checkers, IBM J. 3 (1959) 210-229.
13. Samuel, A.L., Some studies in machine learning using the game of checkers, II, IBM J. 11 (1967) 601-617.
14. Slate, D.J. and Atkin, L.R., CHESS 4.6---The Northwestern University Chess Program, in:
Chess Skills in Man and Machine (Springer, Berlin, 1977) 101-107.
[1] 自动寻找好的特征是个非常棘手的问题,但是这不再本论文的讨论范围内。
[2] 每场游戏通常刚好进行60半步。唯一的例外是当双方都无合规棋步可走时。
[3] 由于随机初始化和终局搜索,算法未训练N < 24 和N > 49的位置。我们可以通过将N = 24的位置的参数复制到N < 24的位置上,将N = 49的位置的参数复制到N > 49的位置上。
[4] 我们将在第5.2.1小节证明这个假设是正确的。
关注福利
关注AI科技大本营,进入公众号,回复对应关键词打包下载学习资料;回复“入群”,加入AI科技大本营学习群,和优秀的人一起成长!
回复:CCAI,下载 CCAI 2017嘉宾演讲干货(PPT)
回复:路径,128篇论文告诉你深度学习Paper阅读路径
回复:法则,《机器学习的四十三条经验法则》帮你踩坑
回复:美团,美团干货分享《深度学习在美团外卖的应用》、《NLP在美团点评的应用》
回复:沙龙,关于程序员转型AI这件事,三位老炮从产业、人才和实操跟你聊了这么些干货(PPT)
回复:对抗,李宏毅老师教你学生成式对抗学习(视频教程+PPT)
回复:AI报告,麦肯锡、波士顿、埃森哲等知名咨询公司专业解读AI行业
回复:银行,下载银行和证券公司的AI报告
回复:人才, 2017 领英《全球AI领域人才报告》告诉你AI人才的价值
回复:发展,下载2017 全球人工智能发展报告
回复:设计,帮你了解《人工智能与设计的未来》
回复:1986,重温李开复老师经典论文:1986年《评价函数学习的一种模式分类方法》和1990年《The Development of a World Class Othello Program》
回复:中美,腾讯研究院为你解读《中美两国人工智能产业发展全面解读》

人类感知外界信息,80%以上通过视觉得到。2015年,微软在ImageNet大赛中,算法识别率首次超越人类,视觉由此成为人工智能最为活跃的领域。为此,AI100特邀哈尔滨工业大学副教授、视觉技术研究室负责人屈老师,为大家介绍计算机视觉原理及实战。扫描上图二维码或加微信csdn02,了解更多课程信息。