为什么聊天机器人从业者都很委屈?

“深度学习”推动了第三波人工智能浪潮,但在对话领域却几乎“寸功未立”。
如今,研发聊天机器人依然要靠大量人工标注,甚至“花在请人标数据的钱,比花在研发人员上的钱都多。”比如,Siri里有趣的回答,很多都是人写的,和机器智能无关。
李开复早在34年前就投入AI科研,但在回顾自己的研究经历时,因为无法达到大众可用的“心理阈值”,研究出的人工智能更像“人工智障”,曾感叹“生不逢时”。

那么这一代研究者,会不会仍然生早了?
这篇文章,来自一位聊天机器人方向的博士,你会在她略带委屈的表达中看到:
1、聊天机器人做的这么烂的根本原因是什么?
2、目前市面上绝大多数智能助理,其内核都相当地“不智能”,更像是“人工智障”。
3、苹果和谷歌的聊天机器人,一个是产品驱动,一个是数据驱动,谁会做到最好?
4、寸功未立的深度学习到底work还是不work?
5、聊天机器人没有捷径,“胜利美人”这一天何时到来?
下文转自甲子光年(ID:jazzyear),作者施晨。
“现在的聊天机器人为什么做得这么烂?”
自从读了聊天机器人方向的博士,这是我最常被问到的问题。
这个世界上的科技进步有两类,一类是委屈的,一类是不委屈的。
委屈和不委屈的区别在于:前者是大众期望走在科技进步前面;后者是大众期望走在科技进步后面。
比如,最初的汽车行业就一点都不委屈。亨利福特曾说:“如果我最初问消费者们想要什么,他们只会告诉我想要一匹更快的马。”——对于那个时候的福特而言,他只需要发明一辆低级的老爷车就可以创造历史。
而现在的自动驾驶从业者开始委屈了。人们早已想象好了一个无人汽车甚至飞行汽车应该长什么样子,站在终点看起点,怎么看,现在的状态都让人觉得“傻大笨粗”。
而聊天机器人也属于很委屈的一类。它的委屈在于——世界上所有人都知道一个好的聊天机器人应该是什么样的。自1950年被图灵提出,聊天机器人就成为了人类对于人工智能的“终极想象”。从《星球大战》里可爱而话痨的C-3PO,到《钢铁侠》里堪称全能助手的Javis,再到两年前的电影《Her》中有着寡姐声线和近乎完美设定的Samantha——人类对于聊天机器人一开始就直盯着结局,相比之下,现实中无论哪款聊天机器人都越看越像“人工智障”。
当大众期望走在科技进步后面时,研究者们就像是航海家,每到一处都是新的成就,掌声与鲜花闻风而来;当大众期望走在科技进步前面时,研究者们就像是马拉松跑者,你在漫长的跑道上汗流浃背,而路的尽头,却是一个早已预设好的了无新意的终点。
作为一个聊天机器人专业博士,这个现实一开始的确令人有点无fuck说。然而,慢慢地我却意识到,我们其实并没什么抱怨的资格。
在过去,回答开篇那个问题,我总会以“大众心理阈值过高”之类的理由来搪塞。可当我深入了解这个领域之后,我意识到,这怪不得别人——目前这个领域的从业者,我们自身做得并不好。
现在让我回答这个问题,我一般会以下面这句话开始:
“因为聊天机器人领域,目前还不是一个well-defined question。”
聊天机器人不是一个well-defined question
什么是一个well-defined question?
对于机器学习领域来说,刨去对于问题本身insight的深入理解不谈,首先,你至少需要一套被大家广泛使用的标准数据集,这样人们每提出一个新的模型,便可以在同一套数据集上进行实验和比对;
然后,你还需要一套行之有效的Metric,即自动评测方法,这样便可以对不同实验结果使用统一标准进行打分。
以“标准数据集+评测方法”为机制,才能够保证学术层面的公平性与透明性,这大大利于复现他人的实验,并在此基础上进行改进与提高——以此迭代下去,优秀的方法才会不断出现。
然而,聊天机器人领域的现状是:既没有一套统一的数据集,也没有一个统一的Metric。
学术界发论文时,往往每个组自己搞一套数据集,然后借隔壁领域的各种Metric(如机器翻译的BLEU,语言模型的ppl)来凑活着用,甚至很多时候直接进行人工评测。这样,不仅使得实验结果十分主观,也使得不同模型方法之间不具备任何可比较性——这就相当于一个人在水泥地上跑步,另一个人在橡胶地上练跳高,他们本身运动的环境就不一样,而你没法去比谁跑得快或谁跳得高,只能简单地看谁更“好”。
为什么标准的数据集和统一的Metric对于聊天机器人领域这么难?
拿数据集来说,对话语料在自然场景下本就很难获取,天然有标注的语料更是无迹可寻。限于高昂的标注费用,现在各组大多只能通过与企业合作来借取对话语料,但涉及到企业隐私规定,语料往往无法开源,因此很多时候别组想要复现时很难拿到最初的语料数据。这是对话领域的标准数据集至今难产的一大原因。
这个问题,其实和十几年前的视觉图像领域(CV)有些类似。曾经CV领域也极度缺乏标准数据集,直到斯坦福大学的李飞飞教授领导小组发布了ImageNet,之后吸引了越来越多的人来贡献数据,问题也就迎刃而解了。
而对于评测Metric,到处借用隔壁领域并不十分合适的Metric,其背后深层次的原因,其实是学界对于对话任务本身的理解还并不透彻。
要想构建一个适合该领域的Metric,首先需要学术界对这个领域有一个较为全面深入的理解,在此基础上才能提出更有针对性也更为科学的Metric。联想到专为机器翻译任务核心特点“word-level alignment”设计的BLEU,目前我们似乎还没有找到对话任务相对别的任务最核心的特点。
“手标数据花的钱比给研发人员的钱还多”
一般而言,一个真正有价值的学术成果,从被学界认可,到在工业界的产品中实际落地,总要有几年的技术沉淀期。
工业界已有产品一般都经过较长的研发周期,无论组织架构还是代码都已相对成型且具备一定规模,这个时候如果下定决心上一套新方法,将面临着巨大的维护与调整开销,有些部分甚至需要推倒重来,涉及很多人力物力与可兼容性的问题。因此,工业界对于新技术的态度一向审慎,就算被证明work,也倾向于再等一段时间。更何况,从决定使用新成果,到完全调试成功真正上线,又要很长一段时间。
换句话说,学术界画饼画得再美好,工业届真的能吃到饼也得等到几年以后了。更别说聊天机器人这个领域,学术界的饼究竟要怎么画,现在还是没谱的事。
事实上,现在市面上绝大多数智能助理或者类似的聊天机器人系统,其内核都相当地“不智能”。
和任何领域一样,一旦技术从学术界走向工业界,系统的技术性与智能性往往就会降低一档。就像搜索引擎与机器翻译等再成熟的产品,最好效果的高频内容永远“靠手标”——以人工来辅助智能。
一位从事聊天机器人开发的工程师就曾向我调侃:
“现在研发聊天机器人的成本,花在请人标数据的钱,比花在研发人员上的钱都多。”
当有时社会舆论出现热点问题,或是聊天机器人要新上一个skill时,一般从纯技术层面上是来不及保证效果与coverage的。这时,工程上采取的方法一般是手工开一个白名单,人工地“调大”某些回答被触发的概率——比如那些Siri里有趣的回答,很多都是人写的,和机器智能无关。
目前市场上一些主流聊天机器人的内核,很多时候都是用大量相对“暴力”的code“堆”起来的。
从另一个角度来看,一个公司开发的聊天机器人效果好不好,很大程度依赖于你有没有自己的数据。
有的数据来自搜索引擎。有些大公司的聊天机器人项目最初就是host在公司旗下的搜索项目上的。所以理论上讲,如果一家公司没有自己的搜索引擎,只能去借别家的凑活着用,搜索部分的许多质量会打折扣,聊天机器人就很难玩得转。
从这个角度来看,Google无愧是当前聊天机器人在技术层面上的翘楚,其它各家,Cortana的背后有Bing,度秘的背后有Baidu,连Alexa背后的Amazon其实也有自家的搜索引擎系统。
不过,有趣的是,唯一一家没有自己搜索引擎的巨头,因为拥有手机入口“强推”,反而占据了聊天机器人领域最大的市场。更有趣的是,这一点和十年前互联网时代的浏览器的格局简直一模一样,彼时微软靠windows操作系统强行捆绑,和现在情况如出一辙,可看看十年后的今天浏览器的结局,也许会对当前各家巨头聊天机器人的未来产生一些有趣的预测。
另一些数据来自手工建立的知识库。闲聊场景之外,工业应用落地,几乎靠的都是规则方法。
很赞同文因互联创始人鲍捷之前在文章《八一八聊天机器人》的观点:
“能做好的最后必然是拥有数据的公司。制造设备的公司会有幻觉,以为自己有用户数据,其实此数据非彼数据。自然语言理解虽然是语义搜索的重要辅助工具,但是当前阶段还不应是Value Proposition或者Key Technology。浅而高质量的数据关系才是。”
深度学习到底work还是不work?
这两年,人工智能重新走向历史前台,和深度学习的崛起密不可分,一片“奇点将至”的论断下,与人工智能相关的一切似乎都搭上了一条通向未来的快车道。
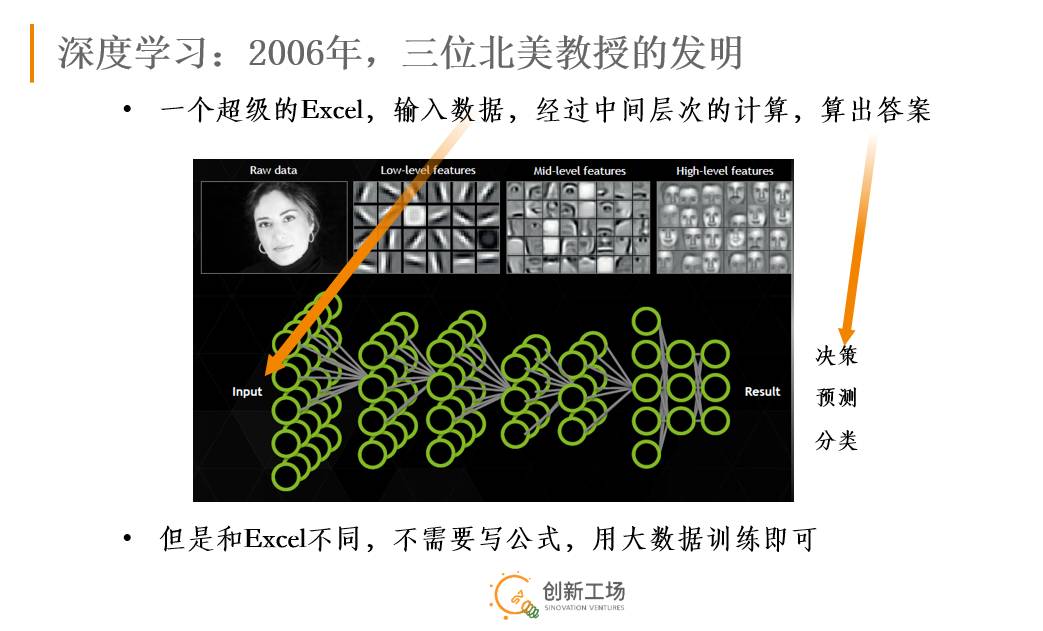
作为人工智能肇始的聊天机器人领域,有借着这波东风一举取得突破性进展么?
似乎并没有。
严格来说,深度学习在对话领域至今几乎“寸功未立”。
从学界角度看,聊天机器人按照功能可以分为两类:一类以闲聊为目的,比如微软小冰;另一类则以完成任务、解决实际问题为导向,比如各类智能助手。
对于闲聊来说,对话的通顺连贯与“有趣”是关键,专业性似乎不重要;而对智能助手来说,解决问题是第一要务,因此系统需要能很好地利用相关数据库与外部知识。相比之下,前者对于深度学习技术的运用相对更好。但在大多数场景里,人们还是希望聊天机器人能解决一些实际问题,要为用户完成任务,这通常需要在结构化数据上做答案生成,很大程度依赖知识库应用和规则方法——在这个过程中,深度学习,乃至机器学习起的作用都不大。
事实上,在过去,对话领域的学界基本不用深度学习。这两年由于深度学习火了,很多人尝试把深度学习用在任务型助手上,但尚未有大突破。
未来,深度学习这条路究竟work还是不work,学术界也有争议,甚至不乏看衰之声。从一个本专业博士的角度,我也对此持谨慎态度,不过我同时觉得,现在就看衰深度学习似乎也还为时尚早。
想当初,在sequence-to-sequence模型诞生之前,也没人会想到深度学习在机器翻译领域能work,以那时机器翻译领域的一贯做法,似乎也看不到太多深度学习可以插手的空间。革命性技术的意义就在于,它可能会完全颠覆行业现有的做法,就像sequence-to-sequence模型之于机器翻译一样——而当这种革命性技术被提出之前,没有人知道它会是什么样的,经验总会让你觉得它并不存在。
学界尚无定论,当我们把目光投向工业界,从业者们更是“戴着镣铐起舞”了。
由于死磕技术链太难,很多从业者开始绕道前行:把软件做成各式各样的机器人、音箱,靠外观征服用户,靠设计征服用户——好看固然有利于user acquisition,但user retention还是要靠真本事。
考虑到对话领域当前还不是一个well-defined question,我认为,当前聊天机器人的战场更多还是在学界和巨头公司的战略布局,离独立商用还有一段距离。Timing很重要,标准的数据集与评测方法就绪了,一些方法论上的惊喜出现了,工业界的春天才会真正到来。
“胜利美人”何时胜利?
2011年10月4日,苹果在加州的库比提诺总部发布了它们的新一代智能手机。这是蒂姆·库克首次作为苹果CEO亮相,一天之后,乔布斯与世长辞。
这本该是一场极其特别的发布会,但新推出的iPhone4s却有点配不上这个时刻:它和被视为经典产品的前作iPhone4太像了,以至于刚出来那会儿,如何区分4和4s,几乎成了果粉论坛里的找茬游戏。
但苹果敢把4s和4做得那么像,不是毫无理由,他们对4s一个内在突破寄予厚望——全新的语音助手Siri。库克后来解释,4s里的“s”正是指Siri。
在这部乔布斯生前留下的最后一部作品中,Siri被他视为最主要的创新点。在All Things Digital大会上被问及Siri是什么时,他曾斩钉截铁的说Siri“不是搜索公司,是人工智能公司”,在那个人工智能从业者多在孤独中前行的年代,这样的远见着实令人佩服。
Siri在挪威语中的含义是“引导你走向胜利的美人”。六年过去,我们果真如帮主预言跨入了人工智能时代,但恐怕,Siri还没有完成他生前设想的使命——人们还没有真的开始使用siri,只是偶尔调戏它。
如今,自阿兰图灵第一次提出“图灵测试”已过去六十余载,距第一个聊天机器人Eliza的诞生也已有整五十年。半个世纪几经起落,时有高潮,但人类似乎始终没有停止对于完美人工智能的幻想与渴望。
从哲学层面来讲,人类对于聊天机器人的痴迷其实是有内在逻辑的。
在茹毛饮血的蛮荒时代,手无寸铁的原始人要想获取信息,靠的只有“眼观六路耳听八方”;后来人类有了语言与文字,信息获取终有了正轨渠道;随着书籍逐渐增多,人类获取信息需要在汗牛充栋的图书馆中漫长耐心地检索与查找;互联网的到来解放了这一切,搜索引擎的轻轻一点带来了前所未有的便捷,但互联网同时也带来了信息量指数级的增长;再后来,当人们终于对从庞杂的网页结果中搜寻信息也感到厌倦时,直接给出回答的聊天机器人作为下一代解决方案,自然成为了大家的期待。
“心理阈值”,看起来是个和技术毫不相关的话题,但在科技史上却多次影响了技术从业者的命运。
李开复在回顾自己的研究经历时,曾感叹“生不逢时”。他对人工智能领域的主要贡献在语音识别技术上,摒弃了依靠语言学家的专家系统,开始使用统计模型方法,大大提高了语音识别的效率。

但当时,这个学术成果,尚无法达到大众可用的“心理阈值”。识别准确率从50%到80%也许从技术上看是很大提升,但人们能够接受的心理阈值却要求准确率至少达95%——在达到这个临界点之前,人们总会觉得人工智能是“人工智障”,无法满意,于是技术从业者总要坐在冷板凳上前行,并不能构成新的产业机会。
李开复遗憾自己当时没有遇上“深度学习”,他曾说:如我生在今天,我所开发的技术和产品一定会被亿万人使用,并深刻改变人们的生活方式。
作为一个研究对话系统的人,我有时也忍不住想:我们这一波,是不是还是生早了?依然没赶上聊天机器人和对话系统技术突破人们“心理阈值”的临界时刻。
按照大家心中所想,一个真正走向胜利的聊天机器人,所承载的,应该是越过信息的海啸、代替上一代搜索引擎“把网页摆到用户面前让用户自己找”的方式,给用户以直接的回应,可想而知,如果对话系统真的胜利了,其前景,理应是一个与互联网量级相当的东西。
这一天何时到来?
Siri的CEO Dag Kittlaus有一篇文章Siri Is Only The Beginning,也聊起过这种真正的胜利,文章里说,“when our kids are our age”。
等我们的孩子都长大,20-30年吧。
爬科技树,绝非一朝一夕。聊天机器人真的没有捷径。

推荐阅读:

欢迎关注创新工场微信公众号:chuangxin2009。创新工场拥有强大的投资和投后团队,持续输出关于创业投资、投后的真知灼见~ 还有机会参与到创业培训、沙龙和其他各类活动中。






