拥有时空注意力机制的光流相关滤波跟踪方法
CVPR2018论文,原文链接:
https://arxiv.org/abs/1711.01124
1.摘要
判别式跟踪方法近来取得了很大的进步,但是判别式方法都是使用当前帧来获取特征,没有充分利用目标的运动信息和帧间信息。所以本文作者使用包含了丰富信息的光流特征来进行目标跟踪。
本文主要贡献有三点:
a)设计了一个端到端地使用光流和相关滤波方法的跟踪框架
b)设计了一个新颖的时空注意力机制,自适应地将当前帧和之前帧特征结合起来
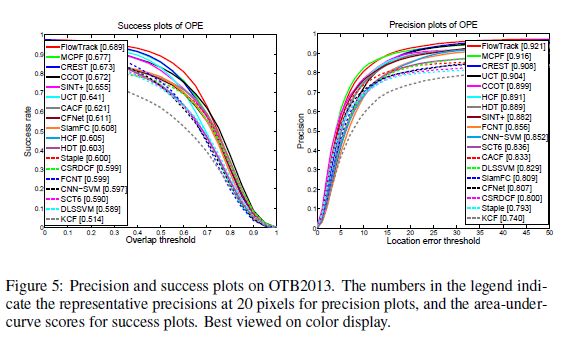
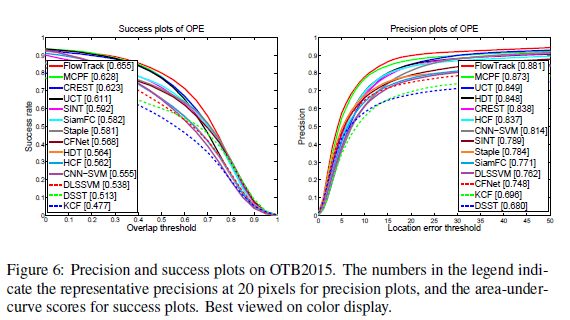
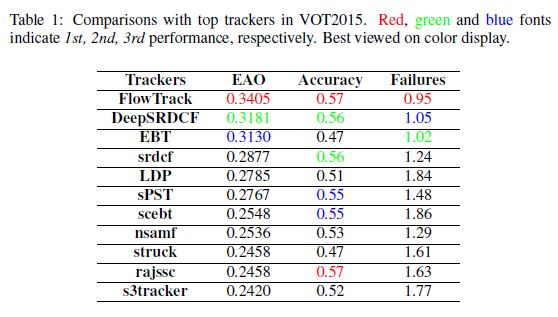
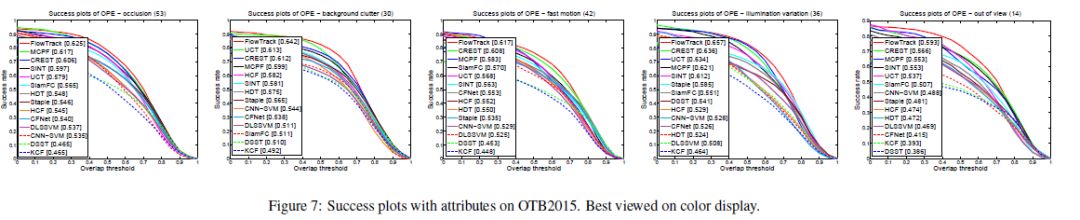
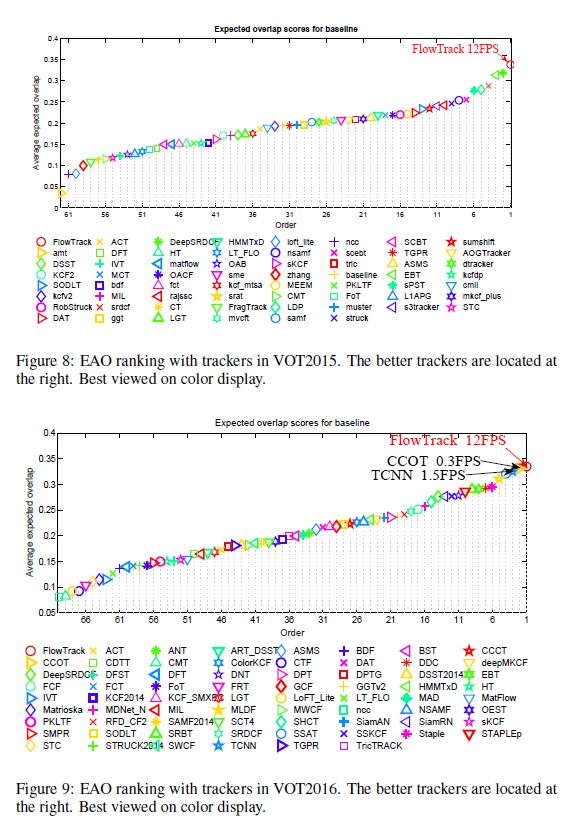
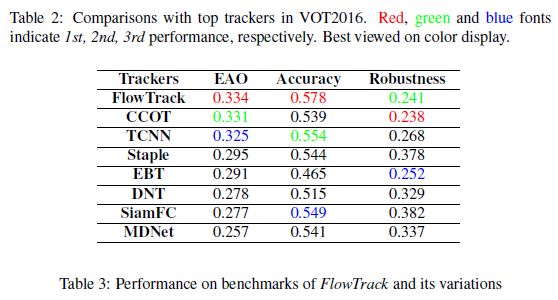
c)在OTB2013、OTB2015、VOT2015、BOT2016实验效果最好
2.具体方法
2.1总体网络框架
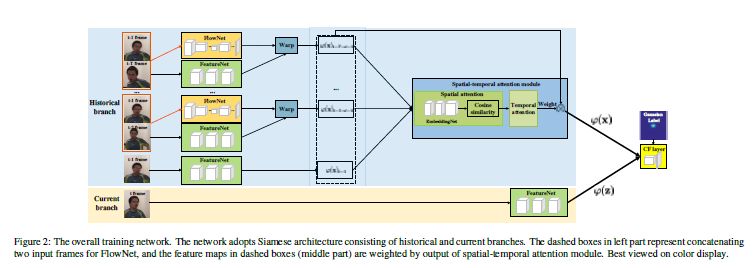
总体框架是一个双胞胎网络。然后将前T(实验中,T=6)帧的信息整合起来,最后使用相关滤波方法,计算最终响应值。
2.2光流特征与深度特征缠绕(warp)
如示意图所示,分别将第t-1帧和第t-i帧(i=2,3,4,5,6)送到一个光流网络当中,提取5次光流特征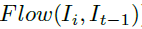
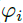
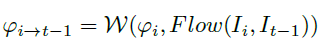
融合后的第i个特征的、第m个通道的、位置p上的数据为
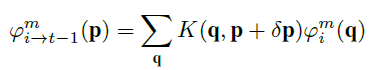
其中,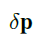
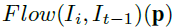
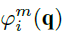
用上面的方法,就可以把光流特征和其对应的深度特征进行数据缠绕,获得5个缠绕后的特征。而第t-1帧的特征直接保留下来,作为第6个特征。这6个特征一起,进行下一步的操作。
2.3自适应权值求解(也就是空间注意力机制和时间注意力机制)
2.3.1空间注意力机制
将上一步得到的6个特征,分别进行一定步骤的bottleneck子网络映射(可以理解为用来缩小数据量的全卷积),得到映射后的特征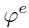
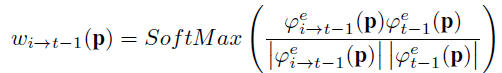
其中softmax相当于把权重归一化一下。这里i取t-1到t-6。此处操作,相当于所有特征和t-1帧特征计算一次cos距离,与t-1帧越相似,则权重越大。显而易见,第t-1帧和第t-1帧肯定是最相似的,因为他们完全一样。
这个步骤得到的w,相当于根据位置信息来计算w,所以叫做空间注意力机制。此时此刻,每个特征的每个通道的每个位置上的值,都有一个属于它的权重w。
2.3.2时间注意力机制
上面求得的特征肯定是不完全合理的,因为t-1帧的权重最大,而t-1可能是被遮挡的帧,这样的特征权重不应该是最大的。所以本文使用时间注意力机制来进行调整。如下:
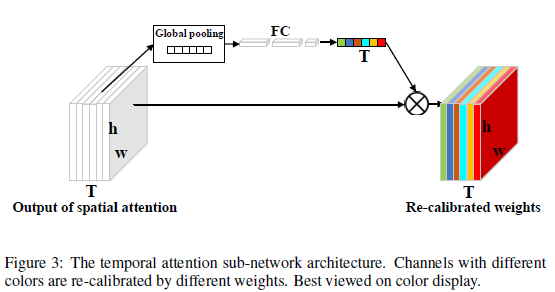
如图,T是我们上个步骤获得的所有w组成的数据块。从左往右一共6大份,因为每个特征得出来一份。h为特征的高,w为特征的宽。我们对数据块T从逐通道做一次平均值pooling。这个操作叫做全局平均pooling(global average pooling)。得到的pooling值送入一个三层的全连接网络中,最终得到6个数字。6个数字再分别与上面提到的6大份权重相乘,得到经过时间注意力机制调整之后的最终权重T。
下图展示了时间注意力机制下得到的6个权重的可视化结果,有遮挡的帧权重就比较低。

2.4求解响应值
上面的操作得到了权重w,然后求解一个平均特征
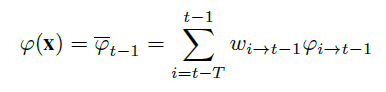
接下来利用得到的特征进行典型的相关滤波计算。
响应值计算:
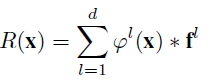
l表示特征的第l通道。f是学习到的该通道的相应的滤波器。
简单说一下计算方法。
损失函数如下:
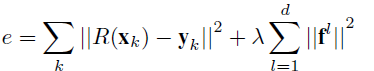
相应的解为
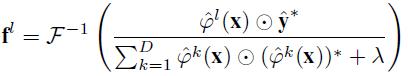
3.实验
3.1网络设置细节


3.2实验结果