ACL 2019 | 使用元词改进自然语言生成
本文将对 ACL2019论文《Neural Response Generation with Meta-Words》进行解读,这篇论文提出的方法可以“显式”地表示输入和回复间的对应关系,从而使得对话生成的结果变得可解释,同时使生成模型可以允许开发者能够像“拼乐高玩具”一样通过控制一些属性定制对话生成的结果。
论文地址:https://arxiv.org/pdf/1906.06050.pdf
源码地址:源码及数据集尚未公开
论文作者:Can Xu, Wei Wu, Chongyang Tao, Huang Hu, Matt Schuerman, and Ying Wang
人机对话是NLP领域一个基础的问题,传统的研究关注于构建任务导向的对话系统来实现用户在特定领域的特定任务,如餐馆预定等。最近,构建开放域的聊天机器人获得了越来越多的关注,这不仅归功于大规模的人人对话数据的出现,还因为一些真实的对话产品(如微软小冰)的成功。
一个聊天机器人通常是通过encoder-decoder框架的响应生成模型实现的[1],但其通常存在的一个问题就是容易产生平凡回复(safe response),如“I don’t know”和“me too”等。一般来讲,平凡回复的产生来源于开放域对话中存在的输入和回复间的 “一对多”关系,而传统的Seq2seq结构倾向于记住数据中出现频率高的词汇。
本文提出的模型可以对开放域对话中的一对多关系进行可解释性和可控制的建模。与隐变量方法不同的是,本文使用元词(meta-word)来明确地表示消息与响应之间的关系。给定一条消息,我们可以通过控制元词来控制生成的响应。

使用元词辅助响应生成有以下几个优点:1.使生成模型具有可解释性,用户可以在生成响应前就知道生成的响应类型;2.生成的过程是可以控制的,元词的接口允许用户定制响应;3.生成的方法是可泛用的,可以将行为、人物角色、情感等特征作为元词的属性与一些已有的工作进行结合;4. 基于生成的开放域对话系统现在变得可扩展,因为该模型支持元词的特征工程。
1. 论文模型
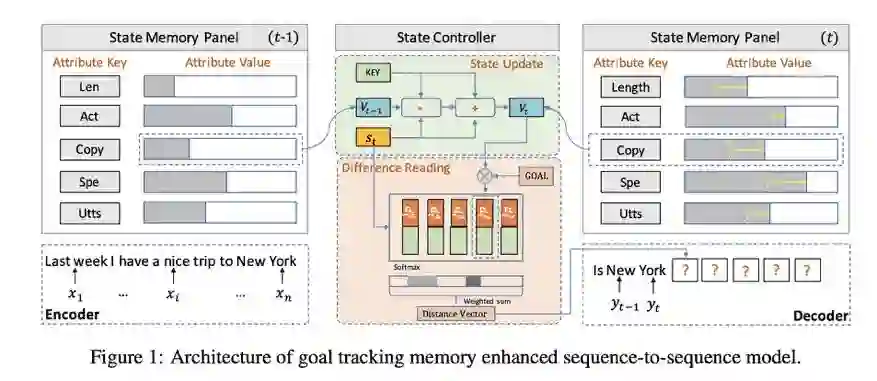
利用meta-word进行响应生成需要解决两个问题:1.如何确保回复和输入相关;2.如何确保回复能够如实地表达预先定义的元词。为了解决这两个问题,本文提出了一个目标跟踪记忆增强序列-序列模型,模型由编码-解码结构的状态记忆板和目标跟踪记忆网络的状态控制器组成。
在生成响应前,编码器通过一个双向GRU将输入信息表示为一个序列,目标跟踪记忆网络由元词初始化得到。然后在响应解码时,状态记忆板跟踪元词的表达并由状态控制器更新。状态控制器从状态记忆板读出元词表达的状态,并通过通知解码器元词表达的状态和目标之间的差异来管理每个步骤的解码过程。基于消息表示,状态控制器提供的信息和生成的字序列,解码器可以对响应的下一个字进行预测。在模型学习过程中,本文在传统的似然目标之外增加了一个状态更新损失,以使得目标追踪能够更好地利用训练数据中的监督信号。
不仅如此,本文还提出了一个元词预测方案,从而使得整个架构可以在实际中使用。
2. 论文实验
本文以MMI-bidi、SC-Seq2Seq、kg-CVAE、CT等多个Seq2Seq模型作为基线,在Twitter和Reddit两个大规模数据集上考察了GTMNES2S生成回复的相关性、多样性、“一对多“关系建模的准确性、以及元词表达的准确性。
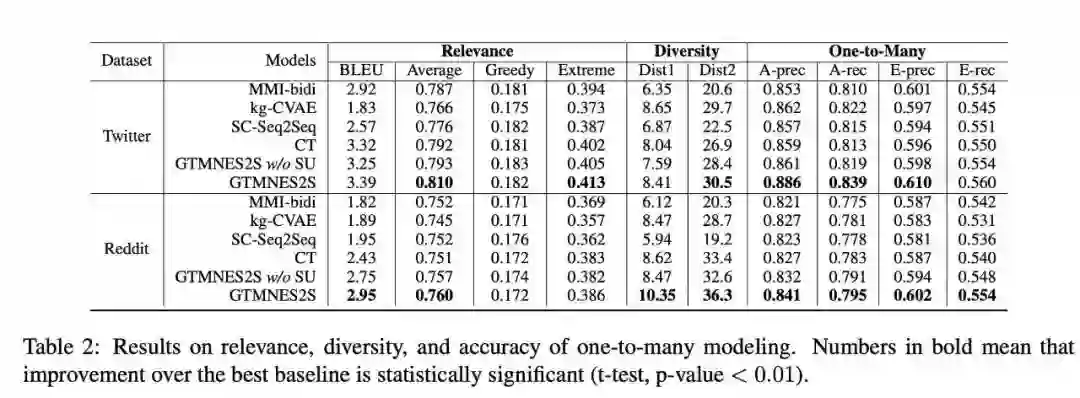
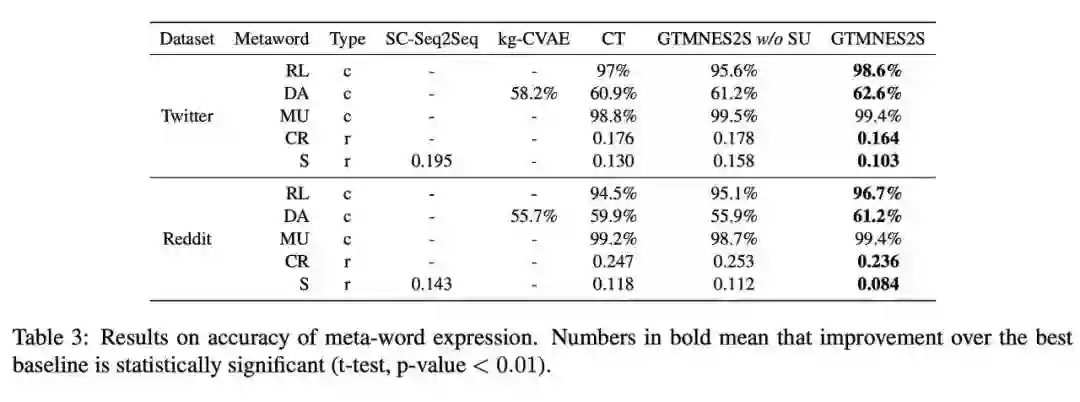

更有意思的是,如果逐渐增加元词中的属性变量,验证集上的PPL会逐渐降低,这也印证了“通过调整元词可以不断提升模型性能”的论断。
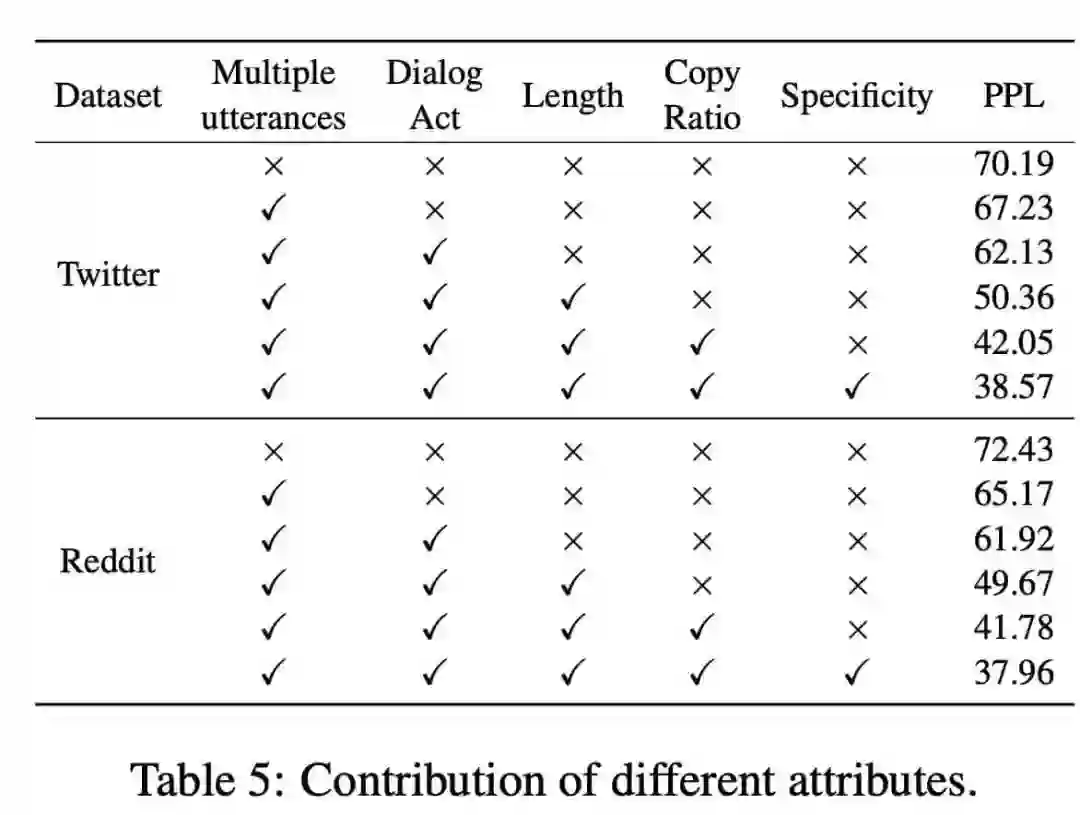
下图的两个例子也表明,通过本模型生成的响应具有更多的信息以及更好的连贯性。

3. 结论
本文提出了一个目标跟踪记忆增强的序列到序列模型,用于使用元词明确定义响应的特征进行开放域的响应生成。两个数据集的评估结果表明,本文的模型在响应质量和元词表达的准确性方面明显优于几个最先进的生成架构。
参考文献
[1] Iulian Vlad Serban, Alessandro Sordoni, Ryan Lowe, Laurent Charlin, Joelle Pineau, Aaron C Courville, and Yoshua Bengio. 2017. A hierarchical latent variable encoder-decoder model for generating dialogues. In AAAI, pages 3295-3301.