教程 | 如何使用TensorFlow构建、训练和改进循环神经网络
选自SVDS
作者:Matthew Rubashkin、Matt Mollison
机器之心编译
参与:李泽南、吴攀
来自 Silicon Valley Data Science 公司的研究人员为我们展示了循环神经网络(RNN)探索时间序列和开发语音识别模型的能力。目前有很多人工智能应用都依赖于循环深度神经网络,在谷歌(语音搜索)、百度(DeepSpeech)和亚马逊的产品中都能看到RNN的身影。
然而,当我们开始着手构建自己的 RNN 模型时,我们发现在使用神经网络处理语音识别这样的任务上,几乎没有简单直接的先例可以遵循。一些可以找到的例子功能非常强大,但非常复杂,如 Mozilla 的 DeepSpeech(基于百度的研究,使用 TensorFlow);抑或极其简单抽象,无法应用于实际数据。
本文将提供一个有关如何使用 RNN 训练语音识别系统的简短教程,其中包括代码片段。本教程的灵感来自于各类开源项目。
本项目 GitHub 地址:https://github.com/silicon-valley-data-science/RNN-Tutorial
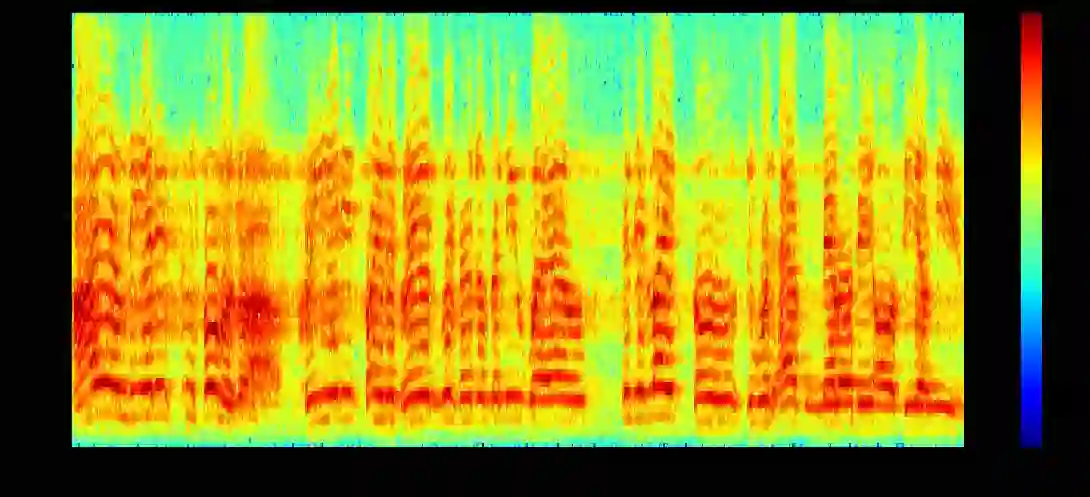
1906 年爱迪生留声机广告的语音识别事例,其中包括声音幅度的运行轨迹,提取的频谱图和预测文本
首先,在开始阅读本文以前,如果你对 RNN 还不了解,可以阅读 Christopher Olah 的 RNN 长短期记忆网络综述:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
语音识别:声音和转录
直到 2010 年时,最优秀的语音识别模型仍是基于语音学(Phonetics)的方法,它们通常包含拼写、声学和语言模型等单独组件。不论是过去还是现在,语音识别技术都依赖于使用傅里叶变换将声波分解为频率和幅度,产生如下所示的频谱图:
在训练语音模型时,使用隐马尔科夫模型(Hidden Markov Models,HMM)需要语音+文本数据,同时还需要单词与音素的词典。HMM 用于顺序数据的生成概率模型,通常使用莱文斯坦距离来评估(Levenshtein 距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。可以进行的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符)。
这些模型可以被简化或通过音素关联数据的训练变得更准确,但那是一些乏味的手工任务。因为这个原因,音素级别的语音转录在大数据集的条件下相比单词级别的转录更难以实现。有关语音识别工具和模型的更多内容可以参考这篇博客:
https://svds.com/open-source-toolkits-speech-recognition/
连接时间分类(CTC)损失函数
幸运的是,当使用神经网络进行语音识别时,通过能进行字级转录的连接时间分类(Connectionist Temporal Classification,CTC)目标函数,我们可以丢弃音素的概念。简单地说,CTC 能够计算多个序列的概率,而序列是语音样本中所有可能的字符级转录的集合。神经网络使用目标函数来最大化字符序列的概率(即选择最可能的转录),随后把预测结果与实际进行比较,计算预测结果的误差,以在训练中不断更新网络权重。
值得注意的是,CTC 损失函数中的字符级错误与通常被用于常规语音识别模型的莱文斯坦错词距离。对于字符生成 RNN 来说,字符和单词错误距离在表音文字(phonetic language)中是相同的(如世界语、克罗地亚语),这些语言的不同发音对应不同字符。与之相反的是,字符与单词错误距离在其他拼音文字中(如英语)有着显著不同。
如果你希望了解 CTC 的更多内容和百度对它最新的研究,以下是一些链接:
http://suo.im/tkh2e
http://suo.im/3WuVwV
https://arxiv.org/abs/1703.00096
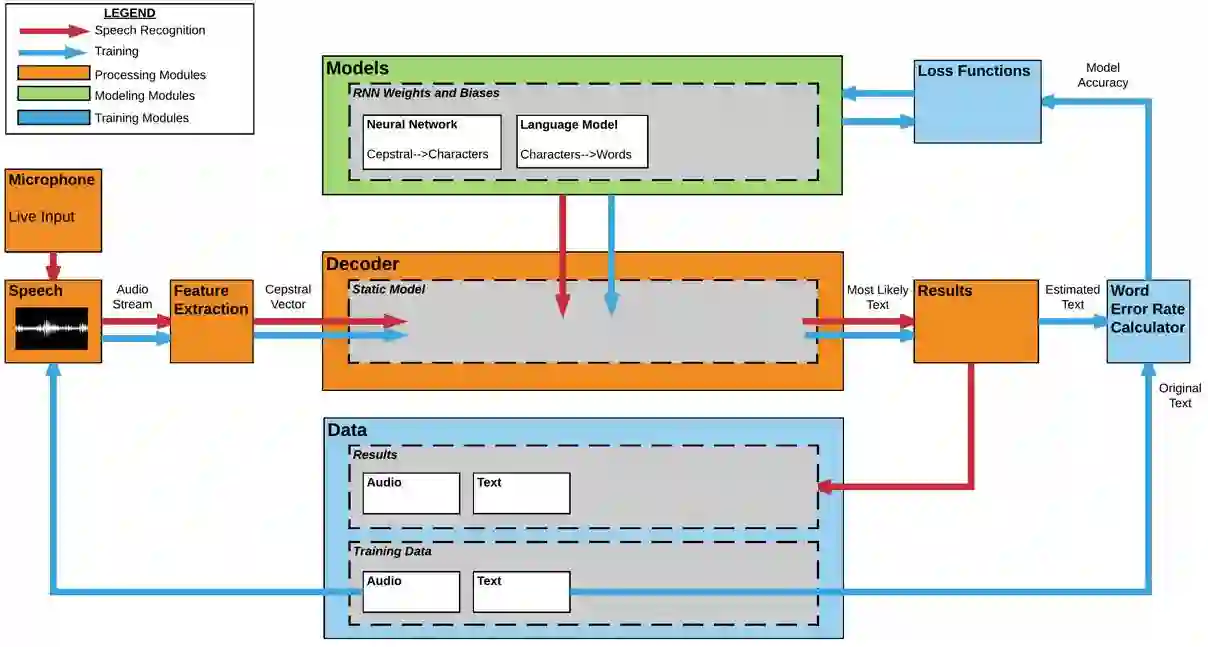
为了优化算法,构建传统/深度语音识别模型,SVDS 的团队开发了语音识别平台:
数据的重要性
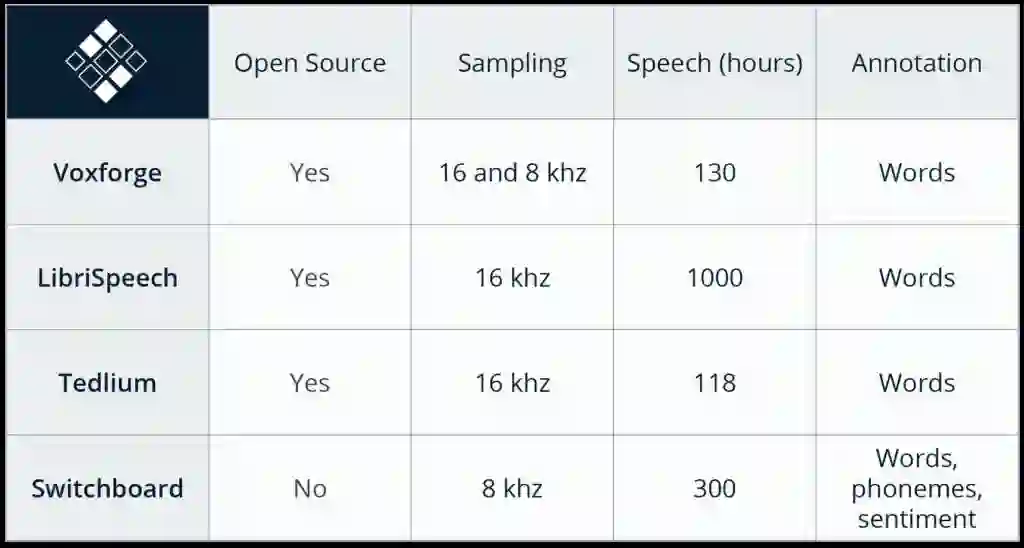
毫无疑问,训练一个将语音转录为文字的系统需要数字语音文件和这些录音的转录文本。因为模型终将被用于解释新的语音,所以越多的训练意味着越好的表现。SVDS 的研究人员使用了大量带有转录的英文语音对模型进行训练;其中的一些数据包含 LibriSpeech(1000 小时)、TED-LIUM(118 小时)和 VoxForge(130 小时)。下图展示了这些数据集的信息,包括时长,采样率和注释。
LibriSpeech:http://www.openslr.org/12/
TED-LIUM:http://www.openslr.org/7/
VoxForge:http://www.voxforge.org/
为了让模型更易获取数据,我们将所有数据存储为同一格式。每条数据由一个.wav 文件和一个.txt 文件组成。例如:Librispeech 的『211-122425-0059』 在 Github 中对应着 211-122425-0059.wav 与 211-122425-0059.txt。这些数据的文件使用数据集对象类被加载到 TensorFlow 图中,这样可以让 TensorFlow 在加载、预处理和载入单批数据时效率更高,节省 CPU 和 GPU 内存负载。数据集对象中数据字段的示例如下所示:
class
DataSet:
def
__init__(
self
, txt_files, thread_count, batch_size, numcep, numcontext):
# ...
def
from_directory(
self
, dirpath, start_idx
=
0
, limit
=
0
, sort
=
None
):
return
txt_filenames(dirpath, start_idx
=
start_idx, limit
=
limit, sort
=
sort)
def
next_batch(
self
, batch_size
=
None
):
idx_list
=
range
(_start_idx, end_idx)
txt_files
=
[_txt_files[i]
for
i
in
idx_list]
wav_files
=
[x.replace(
'.txt'
,
'.wav'
)
for
x
in
txt_files]
# Load audio and text into memory
(audio, text)
=
get_audio_and_transcript(
txt_files,
wav_files,
_numcep,
_numcontext)
特征表示
为了让机器识别音频数据,数据必须先从时域转换为频域。有几种用于创建音频数据机器学习特征的方法,包括任意频率的 binning(如 100Hz),或人耳能够感知的频率的 binning。这种典型的语音数据转换需要计算 13 位或 26 位不同倒谱特征的梅尔倒频谱系数(MFCC)。在转换之后,数据被存储为时间(列)和频率系数(行)的矩阵。
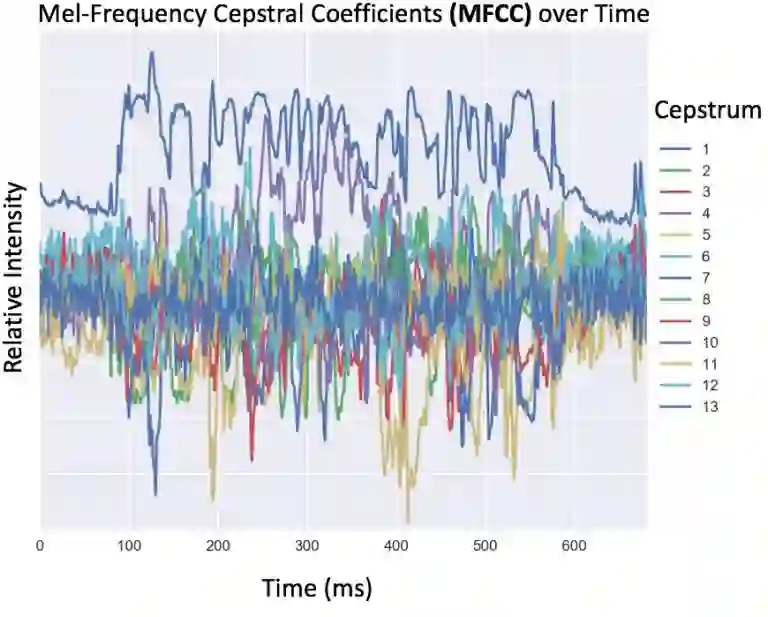
因为自然语言的语音不是独立的,它们与字母也不是一一对应的关系,我们可以通过训练神经网络在声音数据上的重叠窗口(前后 10 毫秒)来捕捉协同发音的效果(一个音节的发音影响了另一个)。以下代码展示了如何获取 MFCC 特征,以及如何创建一个音频数据的窗口。
# Load wav files
fs, audio
=
wav.read(audio_filename)
# Get mfcc coefficients
orig_inputs
=
mfcc(audio, samplerate
=
fs, numcep
=
numcep)
# For each time slice of the training set, we need to copy the context this makes
train_inputs
=
np.array([], np.float32)
train_inputs.resize((orig_inputs.shape[
0
], numcep
+
2
*
numcep
*
numcontext))
for
time_slice
in
range
(train_inputs.shape[
0
]):
# Pick up to numcontext time slices in the past,
# And complete with empty mfcc features
need_empty_past
=
max
(
0
, ((time_slices[
0
]
+
numcontext)
-
time_slice))
empty_source_past
=
list
(empty_mfcc
for
empty_slots
in
range
(need_empty_past))
data_source_past
=
orig_inputs[
max
(
0
, time_slice
-
numcontext):time_slice]
assert
(
len
(empty_source_past)
+
len
(data_source_past)
=
=
numcontext)
...
对于这个 RNN 例子来说,我们在每个窗口使用前后各 9 个时间点——共 19 个时间点。有 26 个倒谱系数,在 25 毫秒的时间里共 494 个数据点。根据数据采样率,我们建议在 16,000 Hz 上有 26 个倒谱特征,在 8,000 Hz 上有 13 个倒谱特征。以下是一个 8,000 Hz 数据的加载窗口:
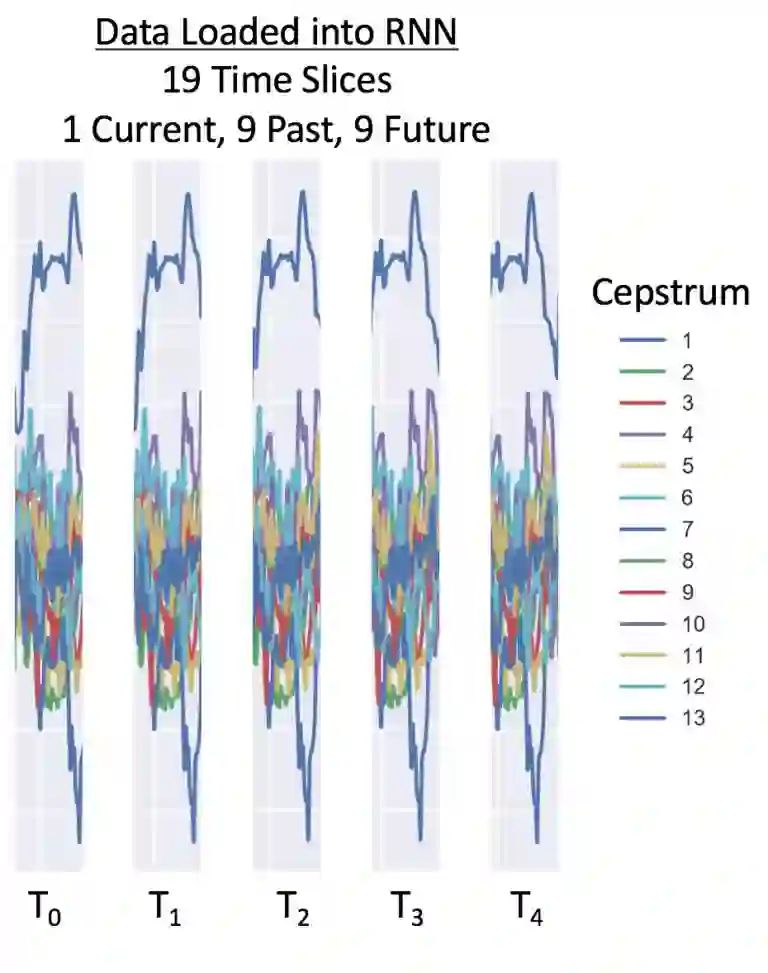
如果你希望了解更多有关转换数字音频用于 RNN 语音识别的方法,可以看看 Adam Geitgey 的介绍:http://suo.im/Wkp8B
对语音的序列本质建模
长短期记忆(LSTM)是循环神经网络(RNN)的一种,它适用于对依赖长期顺序的数据进行建模。它对于时间序列数据的建模非常重要,因为这种方法可以在当前时间点保持过去信息的记忆,从而改善输出结果,所以,这种特性对于语音识别非常有用。如果你想了解在 TensorFlow 中如何实例化 LSTM 单元,以下是受 DeepSpeech 启发的双向循环神经网络(BiRNN)的 LSTM 层示例代码:
with tf.name_scope(
'lstm'
):
# Forward direction cell:
lstm_fw_cell
=
tf.contrib.rnn.BasicLSTMCell(n_cell_dim, forget_bias
=
1.0
, state_is_tuple
=
True
)
# Backward direction cell:
lstm_bw_cell
=
tf.contrib.rnn.BasicLSTMCell(n_cell_dim, forget_bias
=
1.0
, state_is_tuple
=
True
)
# Now we feed `layer_3` into the LSTM BRNN cell and obtain the LSTM BRNN output.
outputs, output_states
=
tf.nn.bidirectional_dynamic_rnn(
cell_fw
=
lstm_fw_cell,
cell_bw
=
lstm_bw_cell,
# Input is the previous Fully Connected Layer before the LSTM
inputs
=
layer_3,
dtype
=
tf.float32,
time_major
=
True
,
sequence_length
=
seq_length)
tf.summary.histogram(
"activations"
, outputs)
关于 LSTM 网络的更多细节,可以参阅 RNN 与 LSTM 单元运行细节的概述:
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
此外,还有一些工作探究了 RNN 以外的其他语音识别方式,如比 RNN 计算效率更高的卷积层:https://arxiv.org/abs/1701.02720
训练和监测网络
因为示例中的网络是使用 TensorFlow 训练的,我们可以使用 TensorBoard 的可视化计算图监视训练、验证和进行性能测试。在 2017 TensorFlow Dev Summit 上 Dandelion Mane 给出了一些有用的帮助:https://www.youtube.com/watch?v=eBbEDRsCmv4
我们利用 tf.name_scope 添加节点和层名称,并将摘要写入文件,其结果是自动生成的、可理解的计算图,正如下面的双向神经网络(BiRNN)所示。数据从左下角到右上角在不同的操作之间传递。为了清楚起见,不同的节点可以用命名空间进行标记和着色。在这个例子中,蓝绿色 fc 框对应于完全连接的层,绿色 b 和 h 框分别对应于偏差和权重。
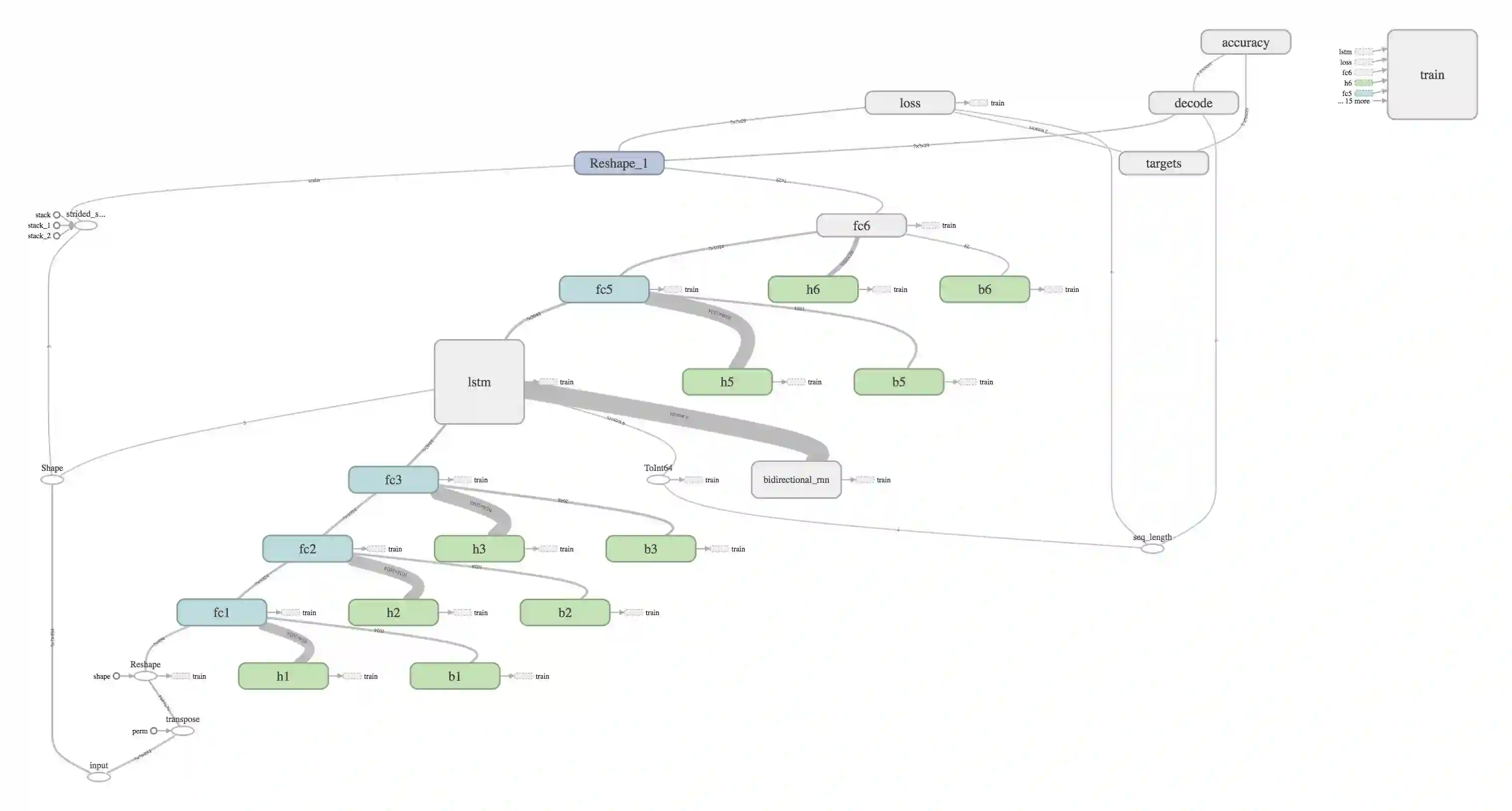
我们利用 TensorFlow 提供的 tf.train.AdamOptimizer 来控制学习速度。AdamOptimizer 通过使用动量(参数的移动平均数)来改善传统梯度下降,促进超参数动态调整。我们可以通过创建标签错误率的摘要标量来跟踪丢失和错误率:
# Create a placeholder for the summary statistics
with tf.name_scope(
"accuracy"
):
# Compute the edit (Levenshtein) distance of the top path
distance
=
tf.edit_distance(tf.cast(
self
.decoded[
0
], tf.int32),
self
.targets)
# Compute the label error rate (accuracy)
self
.ler
=
tf.reduce_mean(distance, name
=
'label_error_rate'
)
self
.ler_placeholder
=
tf.placeholder(dtype
=
tf.float32, shape
=
[])
self
.train_ler_op
=
tf.summary.scalar(
"train_label_error_rate"
,
self
.ler_placeholder)
self
.dev_ler_op
=
tf.summary.scalar(
"validation_label_error_rate"
,
self
.ler_placeholder)
self
.test_ler_op
=
tf.summary.scalar(
"test_label_error_rate"
,
self
.ler_placeholder)
如何改进 RNN
现在我们构建了一个简单的 LSTM RNN 网络,下一个问题是:如何继续改进它?幸运的是,在开源社区里,很多大公司都开源了自己的最新语音识别模型。在 2016 年 9 月,微软的论文《The Microsoft 2016 Conversational Speech Recognition System》展示了在 NIST 200 Switchboard 数据中单系统残差网络错误率 6.9% 的新方式。他们在卷积+循环神经网络上使用了几种不同的声学和语言模型。微软的团队和其他研究人员在过去 4 年中做出的主要改进包括:
在基于字符的 RNN 上使用语言模型
使用卷积神经网络(CNN)从音频中获取特征
使用多个 RNN 模型组合
值得注意的是,在过去几十年里传统语音识别模型获得的研究成果,在目前的深度学习语音识别模型中仍然扮演着自己的角色。
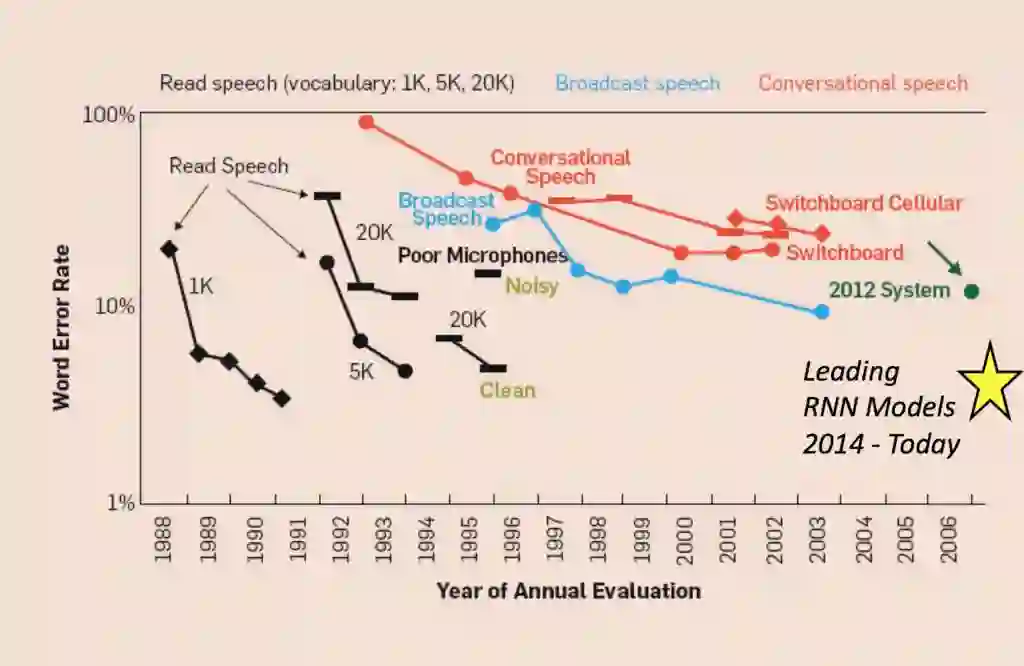
修改自: A Historical Perspective of Speech Recognition, Xuedong Huang, James Baker, Raj Reddy Communications of the ACM, Vol. 57 No. 1, Pages 94-103, 2014
训练你的第一个 RNN 模型
在本教程的 Github 里,作者提供了一些介绍以帮助读者在 TensorFlow 中使用 RNN 和 CTC 损失函数训练端到端语音识别系统。大部分事例数据来自 LibriVox。数据被分别存放于以下文件夹中:
Train: train-clean-100-wav (5 examples)
Test: test-clean-wav (2 examples)
Dev: dev-clean-wav (2 examples)
当训练这些示例数据时,你会很快注意到训练数据的词错率(WER)会产生过拟合,而在测试和开发集中词错率则有 85% 左右。词错率不是 100% 的原因在于每个字母有 29 种可能性(a-z、逗号、空格和空白),神经网络很快就能学会:
某些字符(e,a,空格,r,s,t)比其他的更常见
辅音-元音-辅音是英文的构词特征
MFCC 输入声音信号振幅特征的增加只与字母 a-z 有关
使用 Github 中默认设置的训练结果如下:
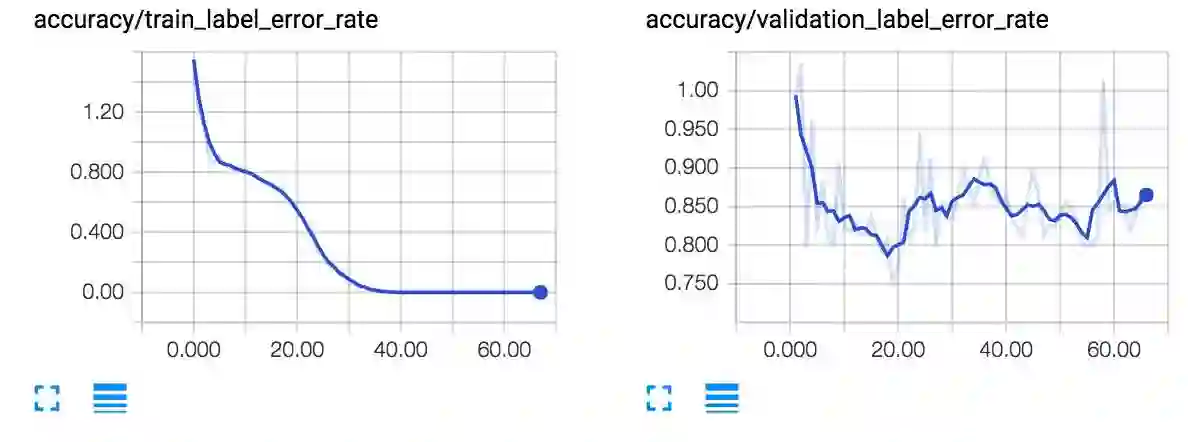
如果你想训练一个更强大的模型,你可以添加额外的.wav 和.txt 文件到这些文件夹里,或创建一个新的文件夹,并更新 configs / neural_network.ini 的文件夹位置。注意:几百小时的音频也需要大量时间来进行训练,即使你有一块强大的 GPU。

原文链接:https://svds.com/tensorflow-rnn-tutorial/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com