从ISCA论文看AI硬件加速的新技巧
总得来说,专门针对ML/DNN的硬件架构已经是ISCA连续几年的热点了,经过大家的努力,对相关问题的挖掘已经越来越深。而同时,在体系结构上的创新所带来的效率提升也逐渐放缓。之前一个新的专用架构的出现,可以带来10X甚至100X的提升,但现在已经很难做到。从我浏览的几篇ISCA2018文章来看,主要创新在于:根据数据和模型的特征动态优化硬件处理流程,尽量减少不必要的运算和访存。本文简单介绍一下这些文章的工作,希望能对大家有所启发。
ISCA主要反映学术界最新的研究工作。目前,对ML/DNN硬件加速技术的研究主要围绕提高Inference的处理效率展开。如果大家对背景知识不熟悉,建议先好好看看[1]这篇综述文章和相关的网站。
•••
SnaPEA: Predictive Early Activation for Reducing Computation in Deep Convolutional Neural Networks
Vahideh Akhlaghi (University of California, San Diego), Amir Yazdanbakhsh (Georgia Institute of Technology), Kambiz Samadi (Qualcomm Technologies), Rajesh K. Gupta (University of California, San Diego), Hadi Esmaeilzadeh (University of California, San Diego)
出发点:如果DNN的activation是ReLU,则其输入只要是负值,输出就是0。如果能判断Conv的计算结果小于0(或者很可能小于0),则可以提前结束计算,从而减少总的运算量。
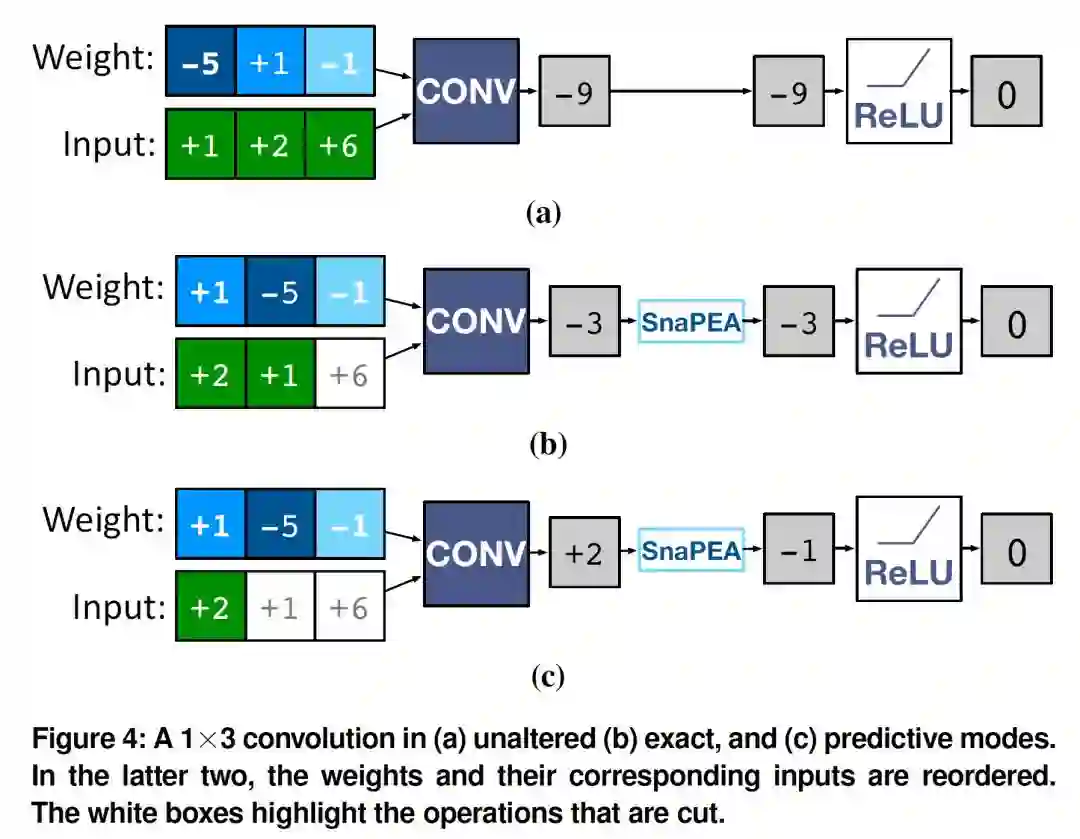
从上图可以看出该论文的基本处理思路。首先,根据数据的符号对weight进行一下整理,把正数放到前面;当处理到负的weight的时候,如果此时的部分和(partial sum)已经为负数,则最终的部分和肯定为负,则停止后续运算,此模式称为exact mode;另一种模式为predictive mode,差别在于,只要在经过了一定数量的MAC运算后,部分和小于一个门限值(不一定小于零)则“预测”最终的结果为零,停止后续运算。
•••
UCNN: Exploiting Computational Reuse in Deep Neural Networks via Weight Repetition
Kartik Hegde (University of Illinois at Urbana-Champaign), Jiyong Yu (University of Illinois at Urbana-Champaign), Rohit Agrawal (University of Illinois at Urbana-Champaign), Mengjia Yan (University of Illinois at Urbana-Champaign), Michael Pellauer (NVIDIA), Christopher Fletcher (University of Illinois at Urbana-Champaign)
出发点:在同一个Conv计算中,weight的数值可能相同。比如在一个filter中,w0=w1=w, 则原始运算 w0*d0 + w1*d1可以转化为 w*(d0+d1),从而减少运算和访存的数量。如下图。
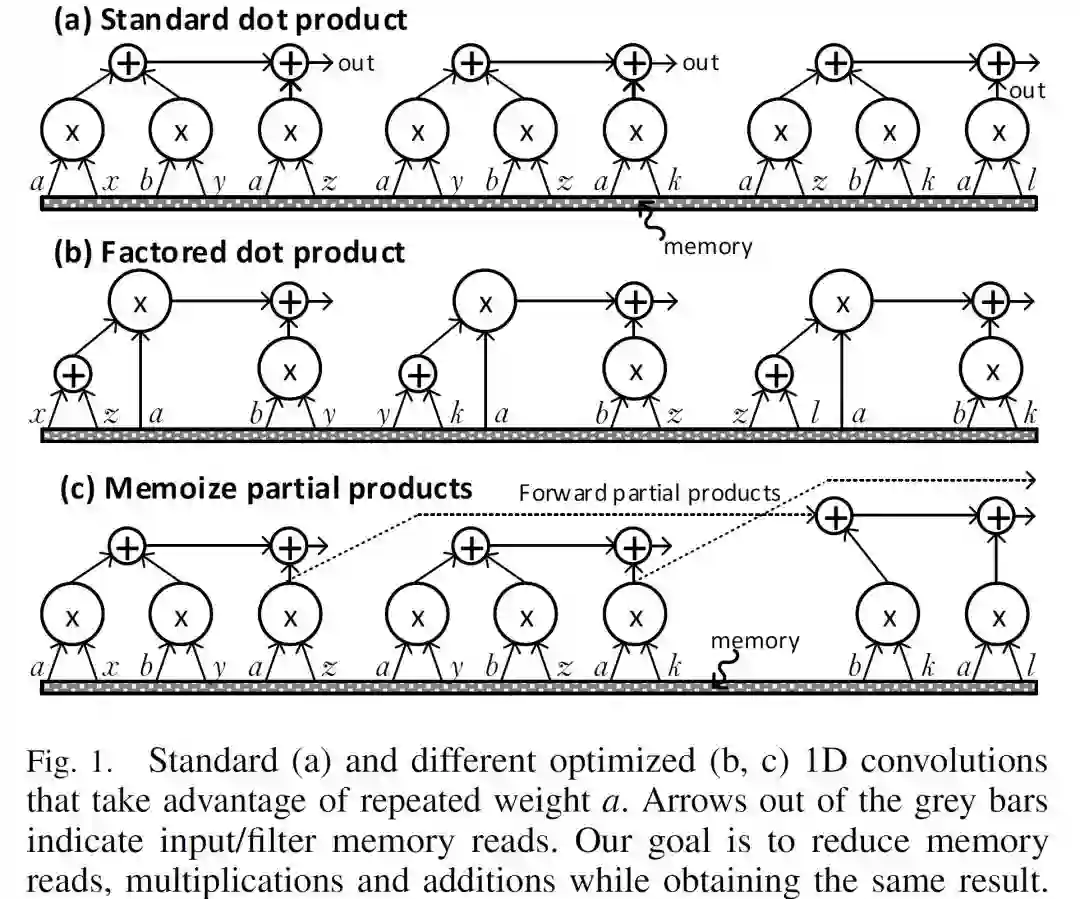
下图是一个具体的优化的实例。
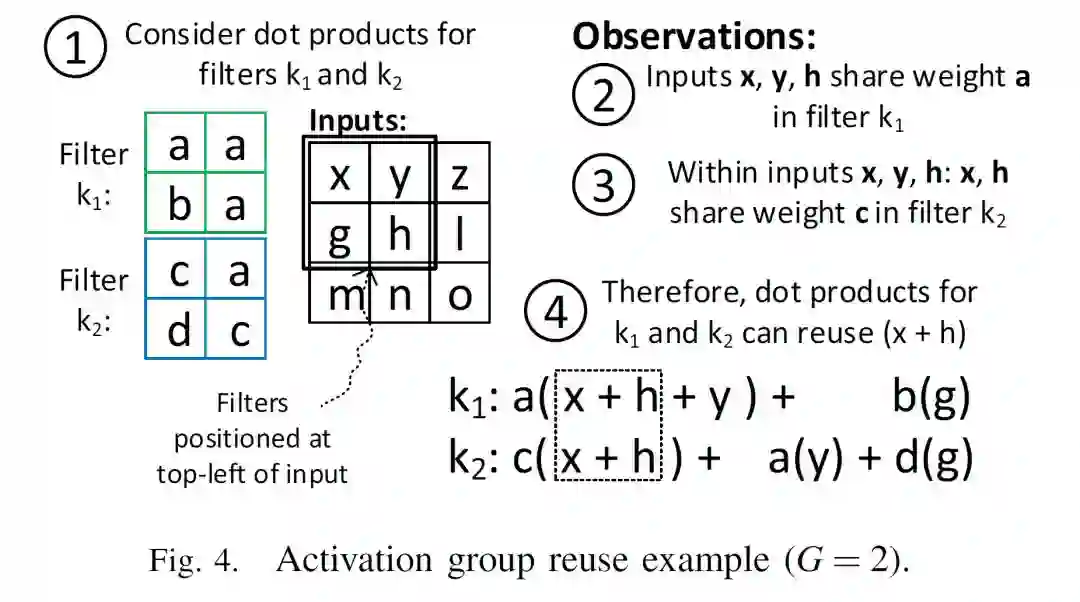
图中可以看出,除了重用了Filter K1中重复的weight a和K2中重复的weight c,在两次计算中还可以重用x+h这部分运算的结果。当然,要实现这样的优化,必须打乱原来的运行过程。如下图所示,硬件根据indirection table中的信息来执行操作:
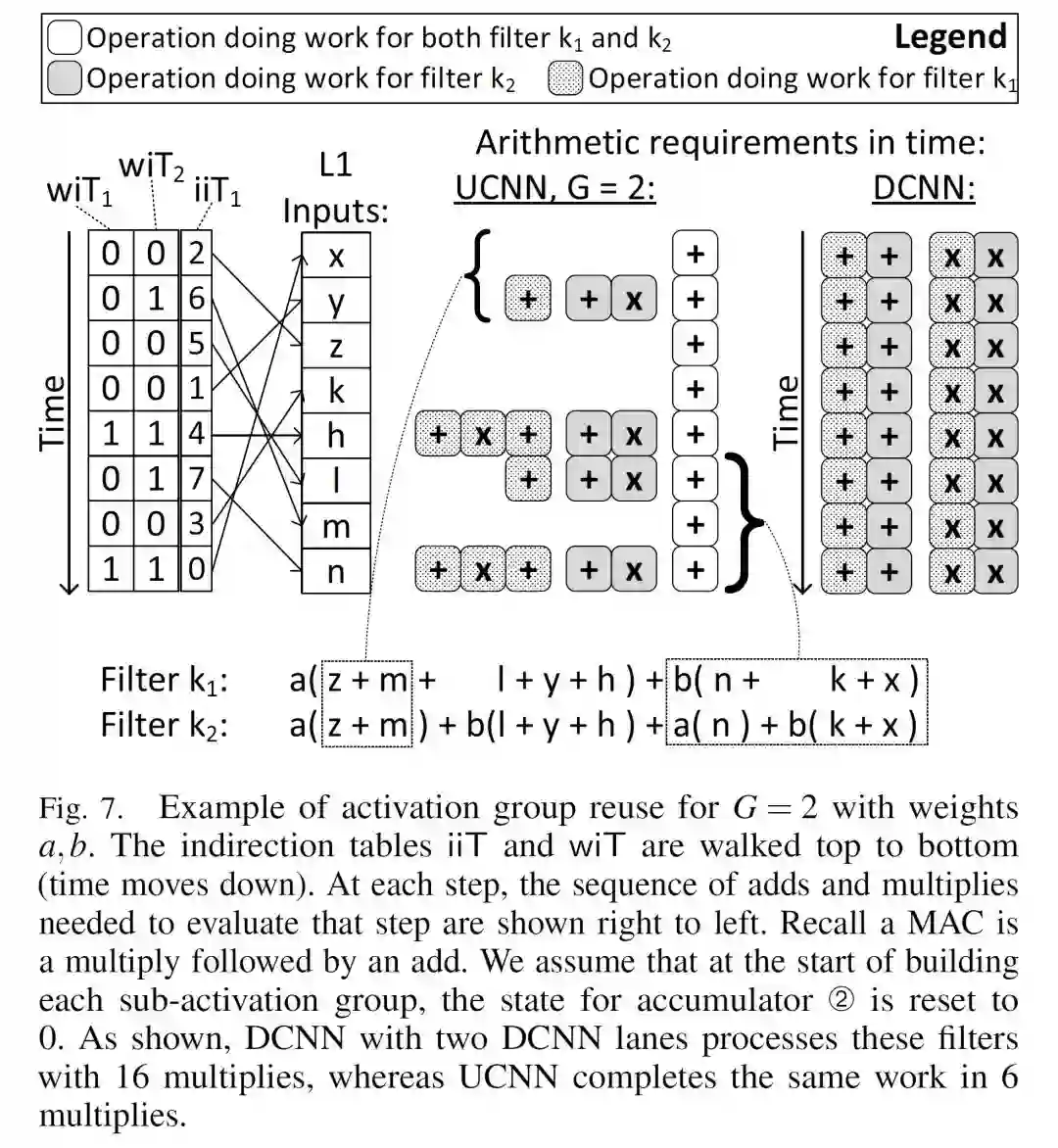
•••
Energy-Efficient Neural Network Accelerator Based on Outlier-Aware Low-Precision Computation
Eunhyeok Park (Seoul National University), Dongyoung Kim (Seoul National University), Sungjoo Yoo (Seoul National University)
出发点:提高inference实现效率的一个基本思路是使用低精度量化,比如4bit量化。但是有一部分数值(outlier,大约3%)如果能够使用更高的精度进行计算则更有利。
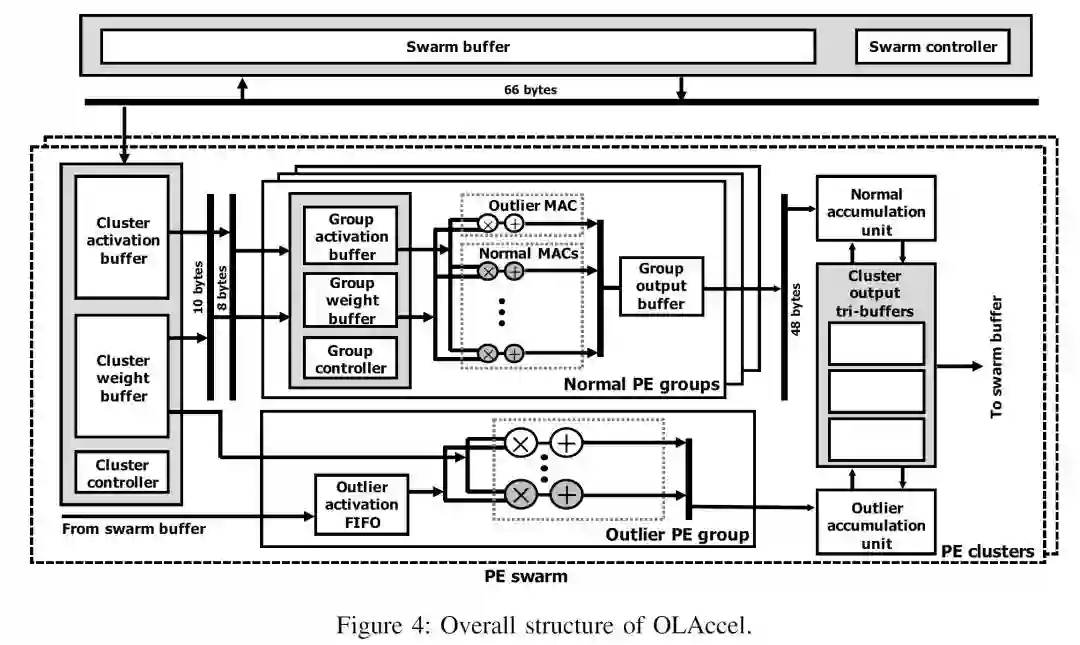
本文的贡献是提出一个outlier-aware accelerator。原理也比较直接,把datapath分成两套,实现不同的精度。大部分数据走低精度(4bit)的datapath,少数数据(outlier)走高精度datapath,如上图所示。整体上来讲,这种方式比都使用高精度有更高的效率,而比统一采用低精度又有更好的模型准确度。
•••
GANAX: A Unified MIMD-SIMD Acceleration for Generative Adversarial Networks
Amir Yazdanbakhsh (Georgia Institute of Technology), Kambiz Samadi (Qualcomm Technologies), Nam Sung Kim (University of Illinois at Urbana-Champaign), Hadi Esmaeilzadeh (University of California, San Diego)
出发点:在GAN中有一类新的卷积运算,transposed convolution,在做卷积之前会在数据中填充很多的零值。对于这种运算,如果用传统的卷积加速方法效率比较低。

这篇文章的工作算是靠上了GAN的热点,选题不错。具体的实现基本就是重新调整数据和filter的组织方式,从而避免不必要的运算。
•••
Computation Reuse in DNNs by Exploiting Input Similarity
Marc Riera (Universitat Politecnica de Catalunya), Jose-Maria Arnau (Universitat Politecnica de Catalunya), Antonio Gonzalez (Universitat Politecnica de Catalunya)
出发点:在很多DNN应用中(如语音识别或视频分类)需要DNN的多次连续处理系列输入(例如音频帧,图像)。 而这些连续的输入表现出高度的相似性,导致不同层的输入/输出对于连续的语音帧或视频图像极其相似。实现中可以对比每次输入是否与上次相似,若相似则省去本次计算。
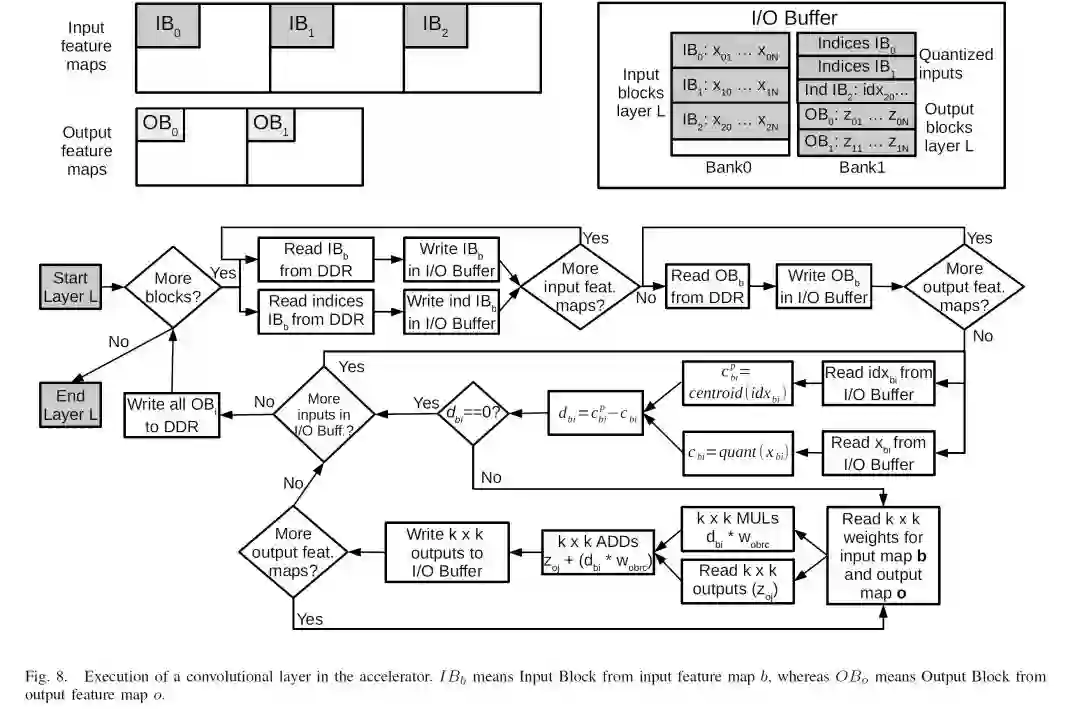
文章里还是比较详细的描述了针对全连接FC,Conv和RNN这些不同类型的layer不同的计算重用方式。上图是针对Conv层的。重点是判断输入和上次输入的相似程度,如果达到一定程度(negligible changes),则不用进行新的计算。具体的判断方法是对输入进行uniformly distributed linear quantization,然后据此分析连续两次DNN操作的相似度和量化误差。
•••
总结
ISCA2018除了上述文章,和ML/DNN加速相关的文章还有不少,也包括来自微软的“A Configurable Cloud-Scale DNN Processor for Real-Time AI”,介绍了Brainwave项目的NPU架构;清华大学的“RANA: Towards Efficient Neural Acceleration with Refresh-Optimized Embedded DRAM”,这篇文章相关的介绍已经比较多了,就不再赘述。另外一些则涉及存储和计算结合或是新型存储技术。
前面粗略介绍的几篇文章,基本上是抓住DNN处理的相关数据和模型(输入,weight,中间结果)的某些特征,通过预测等方法,避免不必要的运算,或者不必要的精度。在获得了一定的收益的同时,这些方法也都增加了处理和控制的复杂度和开销。大部分方法都需要在正常数据之外,额外保存处理相关的信息,比如用来指示数据的特征的index table。另外,这些方法对于数据特征和算法流程是有预设条件的,比如前后输入数据的相似性,weight的重复性,ReLU处理的特点等等。如果数据特征或算法流程不同,则这些方法的有效性也会打折扣。
简单浏览过这些论文,感觉在经过了几年对ML/DNN加速器的密集研究后,已经很难再看到Diannao/DaDiannao, Eyeriss和TPU这类开创性的工作了。从另一个角度来说,接力棒已经迅速的从学界传递给业界。而在未来的实践的过程中,我们可能会看到新的问题(比如算法的跳跃),或者新的机遇(比如新的器件和材料),成为下一次创新高潮的起点。
参考:
1.Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S Emer. Efficient processing of deep neural networks: A tutorial and survey. Proceedings of the IEEE, 105(12):2295–2329, 2017.
- END-
题图来自网络,版权归原作者所有
本文为个人兴趣之作,仅代表本人观点,与就职单位无关




