想成为下一个刷爆挑战赛榜单的冠军?这份复习材料涵盖 CVPR、ICCV 等顶会挑战赛的优胜算法方案,无论你是挑战赛老司机,还是新晋小白,相信对你参悟竞赛道路都会有所帮助。
本篇是机器之心「虎卷er行动 · 春卷er」的第三卷,为老伙计们汇总解读 9 个刷爆 AI 顶会挑战赛榜单的优胜算法方案。
1、CVPR 2021 NTIRE 2021 挑战赛多帧 HDR 成像冠军方案:使用新型的双分支网络结构 ADNet(旷视科技团队)
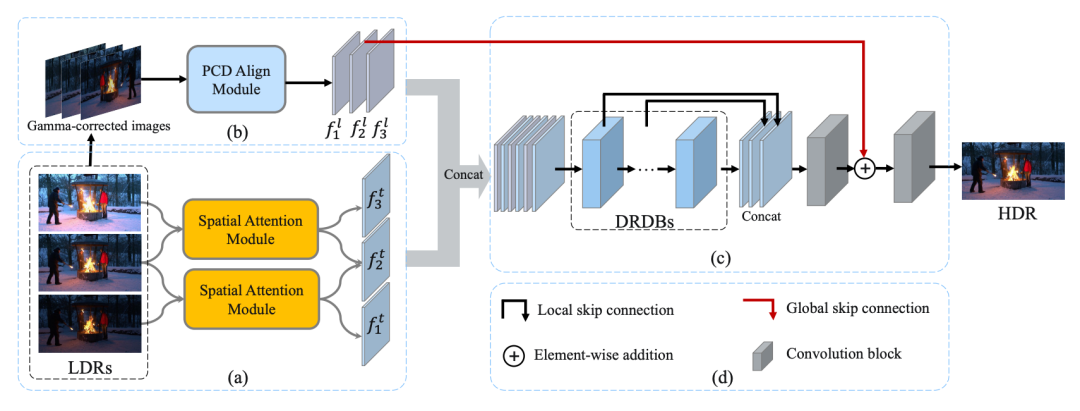
作为图像视频修复和增强领域极具影响力的国际竞赛, NTIRE(New Trends in Image Restoration and Enhancement, 即图像恢复与增强的新趋势)涵盖了从图像到视频几乎所有方向,一直备受工业界关注。在 NTIRE 2021 挑战赛上,旷视提出的双分支网络结构 ADNet 获得多帧 HDR 成像任务赛道的冠军。
目前动态场景下的多帧 HDR 成像任务主要包含两个难点:如何解决相机抖动和前景目标运动带来的对齐问题;以及如何在融合过程中有效恢复过曝/欠曝区域丢失的细节。
旷视提出的双分支网络结构 ADNet,获得 NTIRE 2021 挑战赛高动态范围图像赛道冠军。针对上述问题,旷视提出了一种新颖的双分支网络结构 ADNet,分别对原始 LDR 输入和对应 Gamma 矫正之后的图像进行处理。对于原始的 LDR 图像,旷视提出使用空间注意力模块来检测过曝/欠曝和噪声区域。对于对应的 Gamma 矫正图像,旷视首次在该任务中提出使用可变形对齐模块(PCD)来对齐动态多帧。
现有的方法通常使用相机响应函数(CRF)将非线性LDR图像线性化,然后在这些线性化的图像上应用伽马校正(例如,γ=2.2)来产生输入图像。然而,由于每台摄像机的 CRF 并不严格相同,一个固定的伽马值不一定是最合适的。针对此问题,旷视团队提出了一个伽马干扰策略,并不一直保持一个固定的伽马值,而是以 30% 的概率随机应用一个 2.24±0.1 的伽马值。通过采用这种策略,所提出的方法在 PSNR 方面获得了约 0.1dB 的增益。同时对于多帧 HDR 成像任务,旷视团队采用在色调映射域上优化网络的策略来训练 ADNet 。
旷视团队使用 NTIRE 2021 多帧 HDR 挑战赛提供的数据集进行训练。在排除了 31 个不完整的场景后总共包含 1463 个有效场景,同时选择 100 个场景作为验证集,其余的作为训练集。每个场景由三张不同曝光度的 LDR 图像和它们相应的 HDR 地面实景组成。在训练阶段,将输入的 LDR 图像裁剪成大小为 256x256 的块,步长为 128。
和目前较好的 AHDRNet 方法相比,旷视的方法可以更好地解决鬼影问题,获得噪声更少、图像细节更清晰的 HDR 结果,在NTIRE 2021 高动态范围图像赛道中取得了 39.4471 的 PSNR-l 和 37.6359 的 PSNRµ。
-
论文地址:https://openaccess.thecvf.com/content/CVPR2021W/NTIRE/papers/Liu_ADNet_Attention-Guided_Deformable_Convolutional_Network_for_High_Dynamic_Range_Imaging_CVPRW_2021_paper.pdf
-
Github:https://github.com/Pea-Shooter/ADNet
2、ACM MM 2021 WAB 产品的识别冠军方案:采用两阶段 Pipeline 方法(中科院团队)
随着电子商务直播的快速发展,消费者可以在阿里巴巴的淘宝网直播平台上边看边购物。在直播过程中,直播者会介绍数百种衣服。如果能够实时识别并向消费者推荐具体的衣服,购物体验将得到极大改善。为了提高真实世界视频场景中的时尚识别性能,阿里巴巴、浙江大学等联合举办 ACM MM 2021 WAB 挑战赛,并在天池平台发布。该挑战赛吸引了来自亚洲、欧洲和北美的 587 个团队报名参加。
本次比赛的冠军获奖者是来自中科院的团队,他们提出的最佳模型的平均 F1 Score 为 0.69,比基线模型高 0.22;亚军团队则是来自北京大学、湖南大学、腾讯组成的团队,F1 Score 为 0.648。
在现实世界的应用中,时尚识别仍然是一个挑战,因为大的变形、遮挡、衣服之间的外观相似性以及直播和商店图像之间的跨域差异。
该赛事引入了一个大规模的多模态服装数据集,名为 Watch and Buy(WAB)WAB 。该数据集包含 70000 个视频片段和服装项目匹配对。对于每个视频片段,都有 10 个关键帧在实例层面上的注释,以及相应的语音识别文本。对于每件物品,图像都有注释,并提供物品的标题文本。总共有 1042178 张图片被注释了 1654780 个边界盒。训练数据集由 50000 个匹配的对子组成,其中包含从淘宝直播中提取的视频片段和产品商店图片。注释包括产品类别、边界框、视点类型、显示类型和实例 ID 、标题描述和语音识别文本。
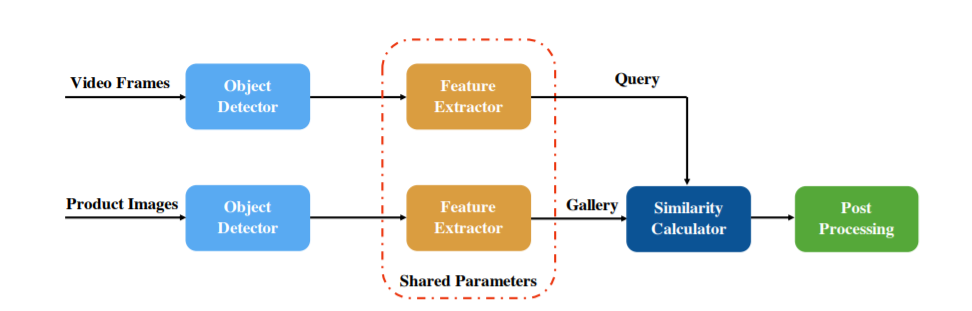
中科院团队设计了一个两阶段的 Pipeline 来解决 WAB 产品的识别问题。整个框架如上图所示。在第一阶段,采用物体检测器来检测视频帧和现场场景中的产品图像的服饰,检测结果包含 23 个类别。在第二阶段,将物体检测的结果输入到图像检索模型中,以提取每个服装项目的特征。最后,对现场视频中的服装和电子商店图像中的服装进行近邻搜索,然后对结果进行合并和后处理,得到每个现场视频对应的物品 ID 。
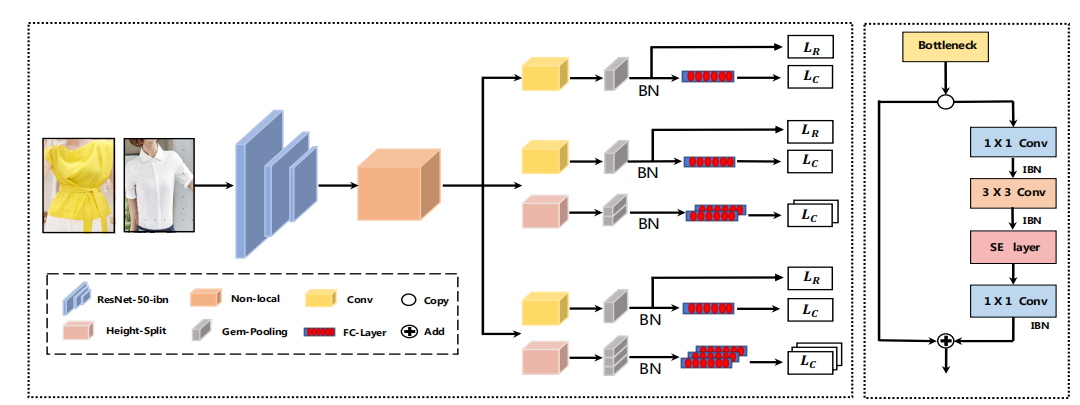
在 WAB 产品识别任务中,中科院团队发现物体的定位性能是次要的,而服装类别的分类则更为重要。服装的位置信息只为检索模型提供了位置信息,而检索模型的稳健性使得物体的定位不那么重要。另一方面,由于该指标按类别计算 F1 得分,因此服装的标签非常重要,特别是在样本很少的类别上。中科院团队采用 Cascade R-CNN 作为物体检测的解决方案,并以 ResNet50 为骨干。为解决衣服的不同形状的问题,采用了 DCN-V2,而非原来的卷积算子。此外,还将分类的损失权重增加了一倍,以提高服装类别的识别精度。以及还尝试采用 Seesaw Loss 来进一步提高样本少类别的准确性,这有助于提高 F1 得分。
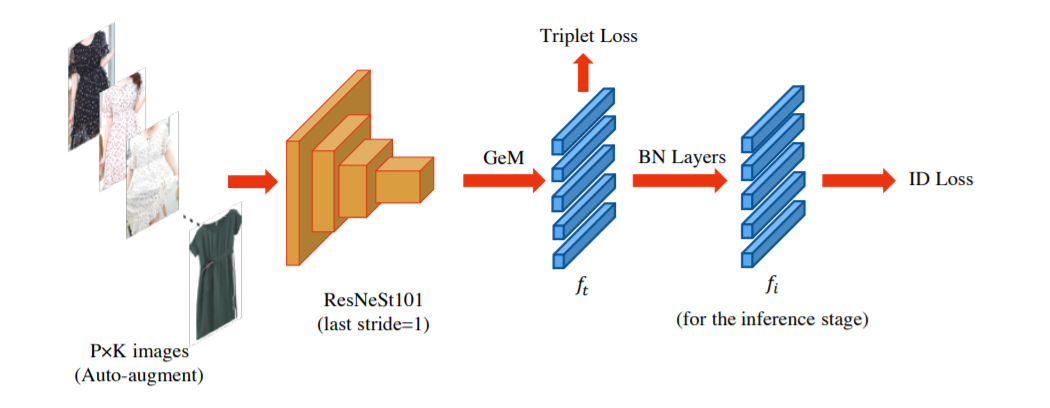
在特征提取部分,为了识别细粒度的服装,中科院团队尝试将行人重新识别任务中的工作作为基线模型。整个图像检索模型的结构如图所示。在基线的基础上,使用在ImageNet 上预训练的 ResNet101 和 ResNeSt101 作为骨干,并通过 IBN 结构来增强模型对不同领域的适应能力,步长设置为1,以增强特征图的大小,提取更多细粒度的特征。在最终的特征向量获得上,采用广义平均法(GeM),这在服装检索任务中显示出很大的优势。损失函数方面采用了 ID loss 和 Triplet loss。此外中科院团队为跨域检索问题提出了一种 DB-PK 抽样方法,它能最大限度地减少多个域之间的变异性,提高检索模型的稳健性。
最终中科院团队取得了 69.2% 的 F1 成绩,并以 4.3% 的优势赢得了比赛。
-
论文地址:https://dl.acm.org/doi/pdf/10.1145/3475956.3484483
在亚军方案中,来自北京大学、湖南大学、腾讯组成团队使用一个三阶段的框架来解决 WAB 产品识别问题,即产品检测、检索和分类。对于产品检测,利用级联 R-CNN 和可变形卷积的性能来减轻图像失真的影响。在产品检索方面,通过 IBN、SE 和非本地块来增强多粒度网络(MGN)的 Global 和 Local 背景。产品分类的任务受到时尚变化的影响。为此,该团队建议融合整体图像的全局特征和产品的局部特征。
产品检测的目标是在现实世界的视频帧和电子商店的图像中准确定位所有产品,以供后续使用。与大多数最先进的方法不同,亚军团队没有采用 Faster R-CNN 或特征金字塔网络作为骨干模型。相反增加了带有可变形 RoI 池的调制可变形卷积(DCNv2)并使用级联 R-CNN 作为检测头以提高性能。DCNv2 可以自适应地改变卷积核的位置偏移和权重,以专注于检测对象的特定内容和形状。此外,来自骨干网络的全局平均集合特征被添加到拟议网络区域(RPN)的输出特征中,以利用全局背景信息,这构建了一个更强大、更有辨识度的特征表示。在模型推理过程中,采用 Soft-NMS 来代替传统的NMS,处理高遮挡度的密集场景。
模型结构上,为了处理产品检索的任务,亚军团队使用多粒度网络(MGN)作为基线。MGN 是一个多分支网络,由一个全局特征表示的分支和两个局部特征表示的分支组成。为了获得全局和局部背景,在瓶颈层增加了IBN块和SE块,并在骨干层的最后一层增加了非局部模块,如图所示。这可以提高模型对产品外观变化的适应能力,并缓解现实世界的视频帧和电子商店图像之间的大域转移问题。
损失函数由两部分组成:分类损失和排名损失。分类损失用于加速训练收敛,以产品 ID 作为基础真实标签,而排名损失用于优化相同产品样本之间的相似性和不同产品样本之间的区别。
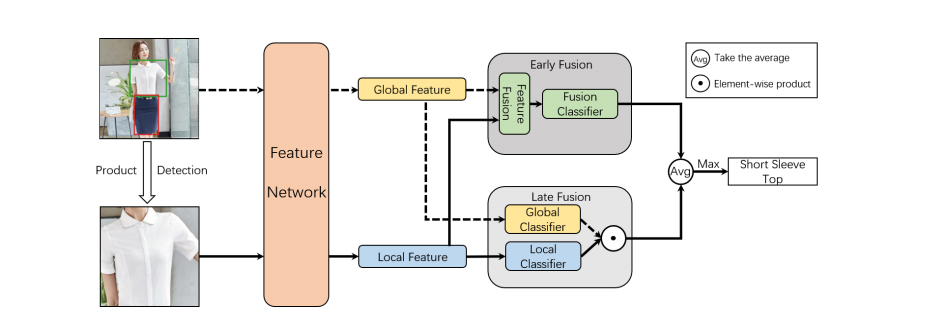
产品分类网络的目标是结合产品检测结果,对产品图像中的所有服装进行细粒度的分类。由于检测到的产品边界框通常只包含服装,而缺乏人的穿着位置信息,因此我们需要将整个图像叠加起来,以获得全局性的背景信息。为了有效利用产品图像的全局和局部信息,亚军团队提出了一个新颖的双分支融合网络(DBFN)。提出的 DBFN 模型结构如图所示。首先,使用一个深度网络从整个产品图像和检测到的产品区域中提取特征,以获得全局背景和局部细粒度的特征。然后,使用两个分支,早期融合分支和后期融合分支分别学习产品类别。最后,输入产品的类别由这两个分支共同预测。DBFN 的骨干为 EfficientNet ,它使用神经结构搜索来获得更有效的网络。该模型的损失由四部分组成,融合分类器的焦点损失,全局分类器,局部分类器和最终的合并分类器。
-
论文地址:https://dl.acm.org/doi/10.1145/3475956.3484486
-
https://tianchi.aliyun.com/competition/entrance/531893/introduction
3、ACM Multimedia 2021 挑战赛冠军方案:使用多模态多头注意的变换器编码器(TEMMA)模型融合各种特征预测 MuSe-Physio 的 anno12_EDA(中科院智能交互团队)
MuSe 2021 是 ACM Multimedia 2021 会议的特别挑战赛,
该赛事
由英国帝国理工学院、德国奥斯堡大学以及新加坡南洋理工大学等高校共同举办,吸引了来自全球的 61 支队伍参赛。
中科院自动化所模式识别国家重点实验室智能交互团队在本次挑战赛中取得多模态生理唤醒分析(MuSe-Physio)等子任务冠军。
MuSe-Physio 任务的目标是对处于压力状态的人进行连续的情绪预测。
在竞赛中,自动化所智能交互团队利用循环神经网络和自注意力机制进行时序建模,结合多模态注意力机制等多种融合策略抽取跨模态信息, 并借助于数据增广和一致相关系数损失函数有效解决了小样本和稳健性问题。
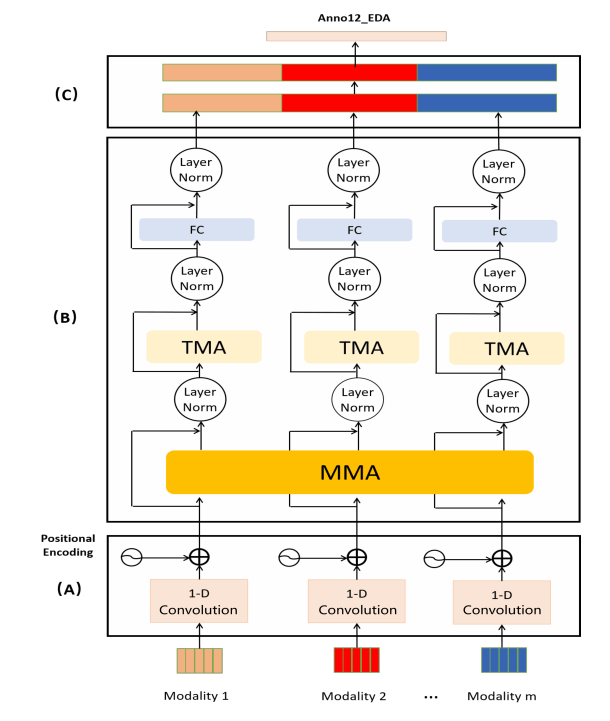
其中 MuSe-Physio 挑战的目标是对处于压力状态的人进行连续的情绪预测。中科院团队使用带有多模态多头注意的变换器编码器(TEMMA)模型来融合各种特征并预测 MuSe-Physio 的 anno12_EDA 。
MuSe-Physio 数据集是 Ulm-TSST 的子集。除了音频、视频、文本特征外,Ulm-TSST 还包括以1kHz的采样率捕获的四种生物信号;EDA、心电图(ECG)、呼吸(RESP)和心率(BPM)。69名参与者(其中49名是女性)的年龄在18至39岁之间,共提供了约6小时的数据。该数据集由三位注释者以 2Hz 的采样率对情感维度的价值和唤醒进行连续评分,并通过融合注释者的评分,利用 RAAW 方法获得一个黄金标准。
它由一维卷积和位置编码组成,将嵌入的特征序列输出到下一个模块。由于我们的特征是一维的特征序列,一维的时间卷积网络被用来编码输入特征序列的时间信息。并采用因果卷积来计算某一特定时间步长不依赖于未来时间步长。考虑到特征向量的时间顺序,位置编码被添加到一维时间卷积网络的输出中。
它由N个相同的编码器块组成。对于每个块,有多模态多头注意(MMA)和时间多头注意(TMA),分别用于模拟模态间的相互作用和模态内的依赖关系。
来自不同模态的编码高级表征被串联成一个特征向量,输入到两个完全连接层以估计情感状态。TEEMA 的输入是不同的特征,中科院团队使用 DeepSpectrum, IS09, MFCCs, SENet, ECG 输入 TEMMA 来预测 anno12_EDA 。
-
论文地址:https://dl.acm.org/doi/10.1145/3475957.3484454
4、ICCV 2021 UVO Challenge 双赛道冠军方案 :针对开放世界分割 (Open-world Segmentation) 提出两阶段分割框架(巴黎高科路桥学校等组成的团队)
基于 UVO 数据集,Facebook 于 ICCV 2021 举办了 UVO (Unidentified Video Objects) Challenge ,比赛分为两个赛道,第一个为基于图片的开放世界实例分割,第二个为基于视频的开放世界实例分割。来自巴黎高科路桥学校等组成的团队获得 ICCV 2021 的 UVO Challenge 双赛道冠军。
现有数据集只标注属于某些类别的物体,导致现今所有实例分割数据集均为部分标注(partially annotated),来自未定义类别的物体均未标注。这样导致了如果想要测量实例分割算法的在新类别物体上的表现,在这些数据集上测出来的结果不准确,会存在检测出来的物体因为没有标注而被当作 False Positive 的情况。
针对以上的问题,Facebook 提出了 UVO 数据集。此数据集以 Kinetics400 为基础,对视频中的所有物体进行标注 (exhaustively annotated) ,而对物体的类别并不加以区分,所有被标注的物体均属于 "object" 类别。
比赛对训练集不设限制,只要为开源数据集即可,同时主办方提供了 UVO v0.5 数据集,包含训练集、验证集和测试集,可用于模型训练与微调。数据集采用 COCO 的metric,同时以 AR@100 作为主要 metric 。
本次比赛该团队没有采用常用的 end-to-end 实例分割算法,相反地,采用了两阶段实例分割框架,第一阶段将图片输入目标检测网络,由目标检测网络预测图片中可能包含物体的边界框;第二阶段先将上阶段预测的边界框包含的图片内容抠出,调整到固定大小之后再输入分割网络,由分割网络预测边界框中物体的 mask 。
目标检测网络训练所用数据集:ImageNet22k,COCO;分割网络训练所用数据集:ImageNet22k,OpenImage,COCO,Pascal VOC。
所有网络在训练时均采用了Class-agnostic 的方式,即训练时不区分物体的具体类别,将所有物体类别标签合为一个标签训练。
当给定一个预测边界框时,该团队训练的分割网络输出:可以看出在有极端角度,遮挡严重,运动模糊等情况下时,依然可以得到很好的结果。
-
论文地址:https://arxiv.org/abs/2110.10239
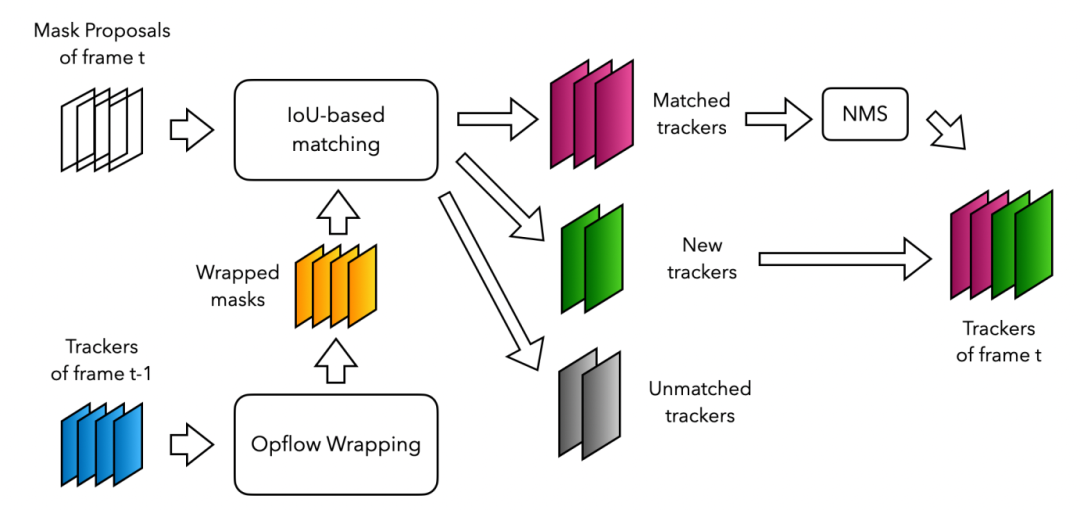
作者基于 Track1 的方法,得到了很多高质量的 mask。他们选择采用一个极简的跟踪算法 (embarrassing simple),算法核心思想与 IoU-tracker 基本一致:利用光流一帧一帧地将实例分割结果穿起来,从而得到 video instance segmentation 结果。
-
论文地址:https://arxiv.org/abs/2110.11661
5、ICCV 2021 MFR 口罩人物身份鉴别冠军方案:结合自学习数据清洗框架+基于NAS的骨干网络(阿里云多媒体 AI 团队,由阿里云视频云和达摩院视觉团队组成)
MFR 口罩人物身份鉴别全球挑战赛是由帝国理工学院、清华大学和 InsightFace.AI 联合举办的一次全球范围内的挑战赛,主要为了解决新冠疫情期间佩戴口罩给人物身份鉴别算法带来的挑战。竞赛期间,共吸引了来自全球近 400 支队伍参赛,是目前为止人物身份鉴别领域规模最大、参与人数最多的权威赛事。
阿里云多媒体 AI 团队(由阿里云视频云和达摩院视觉团队组成)在 ICCV 2021 MFR 口罩人物身份鉴别 WebFace260M SFRs 赛道中获得冠军。
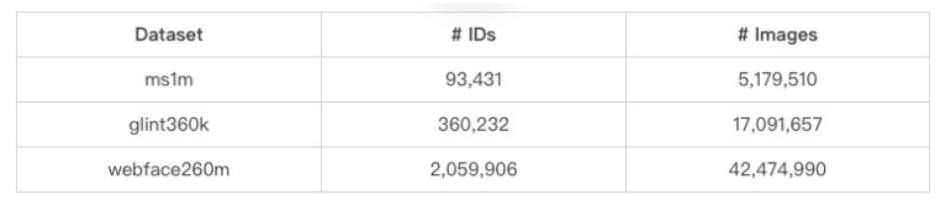
此次竞赛的训练数据集只能使用官方提供的 3 个数据集。官方提供的 3 个数据集,分别是 ms1m 小规模数据集、glint360k 中等规模数据集和 webface260m 大规模数据集。
阿里云多媒体团队在MFR 口罩人物身份鉴别竞赛中基于数据、模型、损失函数等方面设计了一套高效的解决方案。
人物身份鉴别相关的训练数据集中广泛存在着噪声数据,为此阿里云多媒体 AI 团队提出了基于自学习的数据清洗框架,如下图所示:
首先,使用原始数据训练初始模型 M0 ,然后使用该模型进行特征提取、ID合并、类间清洗和类内清洗等一系列操作。对于每个人物 ID ,使用 DBSCAN 聚类算法去计算中心特征,然后使用中心特征进行相似度检索,这一步使用的高维向量特征检索引擎是达摩院自研的 Proxima ,它可以快速、精准地召回 Doc 中与 Query 记录相似度最高的topK 个结果。紧接着,使用清洗完成的数据集,训练新的模型 M1 ,然后重复数据清洗及新模型训练过程,通过不断进行迭代自学习方式,使得数据质量越来越高,模型性能也随之越来越强。
为解决戴口罩数据不足的问题,阿里云多媒体 AI 团队借鉴 PRNet 的思路,采用一种图像融合方案来获取更符合真实情况的戴口罩图像,如下图所示
该方案的原理是将口罩图像和原图像通过 3D 重建分别生成 UV Texture Map ,然后借助纹理空间合成戴口罩图像。
骨干网络
在此次竞赛中,阿里云多媒体 AI 团队采用达摩院提出的 Zero-shot NAS (Zen-NAS) 范式,在模型空间搜索具有更强表征能力的骨干网络。Zen-NAS 区别于传统 NAS 方法,它使用 Zen-Score 代替搜索模型的性能评测分数,值得注意的是 Zen-Score 与模型最终的性能指标成正比关系,因此整个搜索过程非常高效。Zen-NAS 的核心算法结构如下图所示:
损失函数
阿里云多媒体 AI 团队为解决数据不均衡带来的长尾问题,将Balanced Softmax Loss的思想引入Curricular Loss中,提出一个新的损失函数:Balanced Curricular Loss,其表达式如下图所示:
1)采用知识蒸馏的方式缩短推理时间。具体,知识蒸馏将大模型强大的表征能力传递给小模型,然后使用小模型进行推理,以满足推理时间的要求。
2)采用Partial FC,同时使用模型并行与数据并行,使得之前无法训练的大模型可以正常训练,另外可采用负样本采样的方式,进一步加大训练的batch size,缩短模型训练周期。
竞赛结果
此次竞赛阿里云多媒体 AI 团队在InsightFace和WebFace260M共5个赛道中获得1个冠军(WebFace260M SFR)、1个亚军(InsightFace unconstrained)和2个季军(WebFace260M Main和InsightFace ms1m)。其中,WebFace260M赛道官方排行榜的最终结果截图如下所示:
-
官方地址:https://ibug.doc.ic.ac.uk/resources/masked-face-recognition-challenge-workshop-iccv-21
6、ACM MM2021 电商标识检测比赛冠军方案:结合基于梯度均衡的方法和大量的模型训练和数据增强策略,解决中的小目标、长尾分布、对抗样本攻击等问题(华中科技大学冷福星同学)
![]()
ACM MM2021 Robust Logo Detection Challenge 由阿里安全、中科院计算所、清华大学联合主办,全球首次公开 100 万商品品牌数据集!全球首个目标检测鲁棒性防御赛事!吸引了全球 600 多家校企的 36000 多人参加。
来自华中科技大学计算机学院智能与嵌入式计算实验室的冷福星同学,获得该
奖项冠军。
他在本次比赛中使用基于梯度均衡的方法和大量的模型训练和数据增强策略,解决电商标识检测比赛中的小目标、长尾分布、对抗样本攻击等问题,最终初赛达到 70.2448 mAP,复赛 63.8793 mAP,总成绩第一的结果。
-
https://tianchi.aliyun.com/competition/entrance/531888/introduction
7、KDD CUP 2021 City Brain Challenge冠军方案:对路网特征进行精细建模 (上海交通大学电子工程系“IntelligentLight”团队)
KDD CUP 2021 City Brain Challenge
2021 年数据挖掘顶会 KDD 在数据竞赛单元 KDD Cup 特别设置了 City Brain Challenge,旨在挑战城市容纳车辆极限,助力城市交通决策规划。
上海交通大学电子工程系“IntelligentLight”团队获得 KDD CUP 2021 City Brain Challenge 冠军。
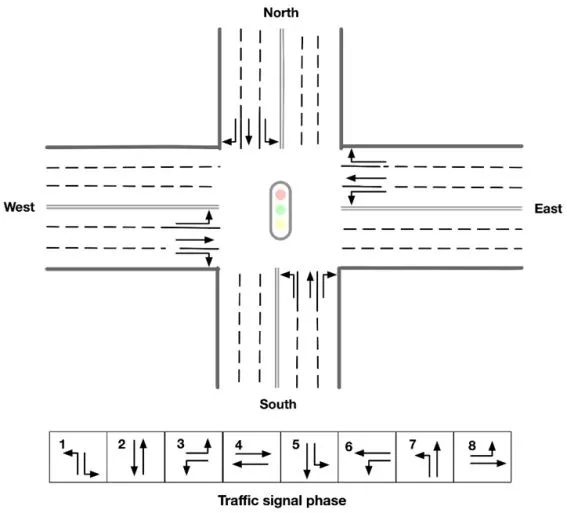
主办方为参赛者提供了一个城市规模的真实道路网络,且其交通需求来自真实的交通数据。参赛者将负责协调交通信号,以最大程度地服务车辆,同时保持可接受的延迟。其中重要的评价指标是延迟指标(Delay Index)。延迟指标指的是车辆已经行驶的时间加上车辆在剩余道路上自由通行的时间,是车辆在整条行驶路径上自由行驶的时间。在本次比赛中,每个红绿灯有8个相位,任务具体而言就是在城市路网中对这8个相位之间选择和切换,使总延误指标,也就是每辆车延误指标的均值最小。
针对真实道路网络场景,上海交大团队设计的方案包含两个核心亮点:
算法总体框架的核心思想是,以每辆车为中心建模,根据收集的信息给每辆车分配一个投票分数。对于信号灯路口的每个时间点,分析如图所示的八种相位的情况,将其 Q 值定义为该相位下车辆投票得分的总和,继而选择 Q 值最大的相位作为该路口在当前时间点的最佳相位。
具体的模型建立,在 Max Pressure 方法与交通模式识别机制的有效的基础上,为了提高性能,冠军团队又进一步添加了各种特征。最终将每辆车的投票得分定义为三个项目的乘积。
第一项是车辆在时间点 t 时总行驶路径的时间预测项。根据延迟指标的定义,自由行驶时间较小的车辆的延迟指标会对总延误指标造成更大的影响,因此冠军团队提升了这些车辆的票值,并区分为以下两种情况:对于路径信息已知车辆,该项值为一常数除以
其自由行驶时间,该常数为实验中得到经验值;对于路径信息未知车辆,该项值为1。实验结果表明,这一项添加进方程确实对模型性能的提高有一定作用。
第二项为时间点 t 时的压力项。对于车道中的某一辆车,它的上游车道压力可以容易得
到(即为当前所在车道的压力);而由于其下游车道未知,下游压力的定义需要借鉴我们构建的交通模式识别机制(有60%的预测准确率),具体也分为两种不同情况:如果道路可以根据历史信息被准确预测出,那么下游压力就是其目的地的压力;如果道路信息无法被预测,那么下游压力取为下游内侧车道和直行车道压力中的最大值。这一项的定义基于车辆不会在上游道路中变换其车道的假设。
第三项为基于道路的时间项。由于靠近路口的车辆更有可能快速到达交叉路口,在下一阶段的投票中,它们应该有更大的票值权重。为了精确衡量车辆到达路口的时间,将道路剩余长度、车辆当前速度、道路限速等信息进行了综合考量,以此为基础设计了基于道路的时间选项。
-
官方地址:http://www.yunqiacademy.org/poster
8、CVPR 2021 阿里产品挑战赛规模产品识别冠军方案:采用多模型投票去除数据集噪声结合多阶段训练策略(欢聚时代 AI 团队)
在 CVPR 2021 中,阿里巴巴达摩院视觉实验室联合 Traxretails,Facebook 举办零售视觉 workshop CVPR 2021 Retail Vision。
欢聚时代的 AI 团队在本次阿里产品挑战赛:大规模产品识别中获得第一名。
其中大规模产品识别挑战是基于阿里巴巴发布的数据集,该数据集包含近300 万张图片,涵盖 5 万个 SKU 级别的商品类别。这是第一次有一个行业规模和粒度的数据集可供计算机视觉研究社区使用,以理解并帮助解决现实世界商品图像识别中的挑战,比赛任务是对图片中的商品进行分类。
在这次比赛中,欢聚团队对长尾数据集、场景复杂性和组合策略做了一些探索。最终的解决方案采用了 11 个模型,包括三个骨干模型:efficientnet,efficientnetv2 和 nfnet。Efficientnetv2-s 取得最好的单一模型分类性能最好,最高错误率为 0.0604,同时,集合模型的最高准确率也达到了 0.0558。
原始训练数据集 V1 含有大量的标签噪声,尤其是同一产品的多个 SKU 经常混在一起。使用多个骨干模型,可以在模型的准确性未知的情况下,通过多个模型来投票去除噪音。这些模型首先在训练数据集 V1 上用几个 epoch 进行训练:小模型用较少的 epoch 进行训练,大模型用较多的 epoch 进行训练。当验证损失减少到 1 时,所有的模型都被提前停止,以防止过拟合。然后,骨干学习率被固定,分类器学习率被设定为增加,模型在随机选择的 V1 的类平衡训练集上再训练 2 个 epoch。验证 Top-1 的准确率上升到 87%-92% 。在获得一个相对高精度的模型后,采用多模型投票来清理 V1 的噪音。欢聚团队使用 efficientnetb3, nfnetf0, nfnetf1, 和 nfnetf3 进行模型投票,结果不一致的训练样本被删除,因此训练集的数量减少到 1.66M ,形成新的训练集 V2 。最后,根据结果完成缺失数据的分类,形成分类平衡数据集 V3 。
不考虑过拟合的影响,模型在原始训练数据集上训练了 10 个以上的 epoch,以获得更高的单模型精度,这导致的结果是,对于中等规模的网络,如 nfnetf1 和随后的 efficientnetv2-m,显示了不同程度的过拟合。也就是说,它们在验证数据集中的准确率低于较小的 nfnetf0 和 efficiententnetv2-s ,但与此同时,较大的 nfnet3 网络取得了较好的结果,最高错误率为 0.1247。欢聚团队在过拟合模型中加入了更多的正则,包括 RandomAffine 和 ColorJitter,以提高准确性。接下来在训练过程中加入了训练数据集 V2,模型在原始训练集 V1 和经过清洗的训练数据集 V2 上交替训练了 5 个以上的 epoch,直到验证中的准确性保持稳定。通过这样做,模型的准确性提高了 1∼2 个点。最终,骨干学习率被固定,分类器学习率被设定为增加,模型在训练数据集 V3 上训练 2 个以上的 epochs ,在验证数据集上获得了 91%~94% 的单一模型精度。
-
论文地址:https://trax-geometry.s3.amazonaws.com/cvpr_challenge/cvpr2021/recognition_challenge_technical_reports/1st+Place+Solution+for+AliProducts+Challenge+Large-scale+Product+Recognition.pdf
-
天池地址:https://tianchi.aliyun.com/competition/entrance/531884/introduction
9、ICCV 2021 无人机数据集多赛道冠军方案:结合数据增强、检测器、轨迹后处理(深兰科技)
2021 国际计算机视觉大会 International Conference on Computer Vision (ICCV)是国际首屈一指的国际计算机视觉盛会。
此次会议,深兰科技 DeepBlueAI 团队共参加 2 项比赛 4 个赛道,分别在 VisDrone Object Detection,VisDroneMot, Large-AI-Food.VisDrone 三个赛道获得冠军。
VisDrone 数据集由天津大学机器学习与数据挖掘实验室 AISKYEYE 队伍负责收集,全部基准数据集由无人机捕获,包括 288 个视频片段,总共包括 261908 帧和 10209 个静态图像。
这些帧由 260 多万个常用目标(如行人、汽车、自行车和三轮车)的手动标注框组成。
为了让参赛队伍能够更有效地利用数据,数据集还提供了场景可见性、对象类别和遮挡等重要属性。
VisDrone Object Detection 冠军方案
VisDrone Object Detection任务旨在从无人机拍摄的单个图像中检测预定义类别的对象(例如,汽车和行人),目前虽举办多届仍存在以下几个难点:大量的检测物体、部分目标过小、不同的数据分布、目标遮挡严重。为此深兰科技团队设计了一套解决方案包括数据增强处理,检测器和轨迹后处理:
-
-
检测器基于Cascade R-CNN,并用swin-Transformer 系列替换主干,使得线上结果得到了极大的改善。
-
在轨迹后处理部分根据预测的 score 分段集成的,大于等于 0.1 用 WBF ,小于 0.1 用 soft_nms 。目的是既可以提高高分框的定位精度,增加召回从而提升 mAP 。
在数据平衡中,将每一类图片数量小于 4000 张的,通过随机加噪声、改变亮度、cutout 等方式扩充为 4000 张,以缓解类别不平衡的问题。
用中心裁剪的方式,随机在原图上裁剪 320~960 大小的区域,然后把它们 resize 为相近的尺度,以缓解目标尺度不一致的问题。举个例子,在原图中,第一行切了 960×960 大小,第二行切了320×320大小,把它们resize 到同一个尺度(如640×640),相当于达到了小目标放大、大目标缩小的目的。并且对于边界目标是全保留的策略。
马赛克数据增强将 4 张训练图像按一定比例组合成1张,丰富了检测数据集, 增加了很多小目标。Mosaic 是 YOLOv4 中引入的第一个新的数据增强技术。这使得模型能够学习如何识别比正常尺寸小的物体。它还鼓励模型在框架的不同部分定位不同类型的图像。通过缩放,以及一次计算 4 张图片,充分利用了 GPU 资源,使得 batch_size 不用很大就能达到很好的效果。
对于同一挑战赛的 MOT 赛道,深兰科技团队设计了一个简单、在线的多目标跟踪系统,包括检测器、特征提取、数据关联和轨迹后处理。
深兰科技团队基于Cascade RCNN 设计了检测器,同时使用了GFLDetector、Generalized Focal Loss(GFL),具体的来说,GFL 可以分成 QualityFocal Loss(QFL) 以及 Distribution Focal Loss(DFL) 。QFL 专注于 asparse set of hard examples ,同时在相应的类别上产生它们的连续 0~1 之间的 localizationquality estimation;DFL使网络能够在任意和灵活的分布下,学习 bounding boxes 在连续位置上的概率值。
特征提取模块是基于多粒度网络(MGN)的嵌入模型。多粒度网络(MGN)把全局和局部的特征结合在一起,能够有丰富的信息和细节去表征输入图片的完整情况。在观察中发现,确实是随着分割粒度的增加,模型能够学到更详细的细节信息,全局特征跟多粒度局部特征结合在一起,思路比较简单,全局特征负责整体的宏观上大家共有的特征的提取,然后把图像切分成不同块,每一块不同粒度,它去负责不同层次或者不同级别特征的提取。
深兰科技团队借鉴了 DeepSORT 和 FairMOT的想法,以检测框的表观距离为主,以检测框的空间距离为辅。首先,根据第一帧中的检测框初始化多个轨迹。在随后的帧中,团队根据 embedding features 之间的距离(最大距离限制为0.7),来将检测框和已有的轨迹做关联。与 FairMOT 一致,每一帧都会通过指数加权平均更新跟踪器的特征,以应对特征变化的问题。对于未匹配的激活轨迹和检测框通过他们的 IoU 距离关联起来(阈值为0.8)。最后,对于失活但未完全跟丢的轨迹和检测框也是由它们的 IoU 距离关联的(阈值为0.8)。
由于只有较高的置信度的检测框进行跟踪,因此存在大量假阴性的检测框,导致 MOTA性能低下。为了减少置信阈值的影响,深兰科技团队尝试了两种简单的插值方法:
1) 对总丢失帧不超过20的轨迹进行线性插值。我们称之为简单插值(simple interpolation, SI)。
在机器之心 SOTA!模型联合阿里云天池推出的「虎卷 er 行动 · 春卷er」中,我们
基于
「 AI人必追」的本季度举办的国际顶会及机器之心报道中的社区热议工作
,「炼丹者必备」的基准数据集、AI顶会挑战赛优胜算法及开发基础知识,共同设计了由 60 道选择题构成的「虎卷er · 春榜试题」,并编撰了 3 套独家配套技术复习资料,帮助关注前沿 AI 技术发展的开发者梳理第一季度的重要 AI 技术工作的同时帮助注重实践技能的开发者快速温故知新,巩固知识与技能。