让机器“察言作画”:从语言到视觉|VALSE2018之二
编者按:唐代诗人王维在《画》一诗中,曾写道:
“远看山有色,近看水无声。
春去花还在,人来鸟不惊。”
这首他在赏画时所作的诗,是人类从视觉到语言最高水平映射的表现。然而,如果我们来读这首诗,是否能浮现出他所欣赏的画作呢?显然还不能。
因此,对于人类而言,相较于视觉到语言的映射,语言到视觉的映射似乎是一个更大的挑战。而对机器而言,深度学习构建了语言与视觉之间的联系,也让机器在吟诗作画方面取得了超过普通人的成绩。
1958年,鼠标的发明者Douglas Engelbart,在麻省理工学院见到了人工智能先驱Marvin Minsky,据说他们之间曾发生过这样一段对话,Minsky说我们要让机器变得更加智能,我们要让它们拥有意识,而Engelbart则这样回应:你要为机器做这些事,那你又打算为人类做些什么呢?
今天,我们通过回答“机器能为人类做些什么”这个问题,来间接回答后者的问题。来自京东AI平台与研究部的张炜博士,将为大家介绍,从语言到视觉,机器能为人类做些什么。
文末提供文中提到参考文献的下载链接。


首先看一下CV的前世今生。前世的CV跟语言息息相关。在1966年Marvin Minsky定义CV是把一个摄像头放在机器上,让机器描述看到了什么。注意定义中的关键词“describe”跟语言非常相关:CV主要做的任务就是描述,而描述最直接的媒介就是用语言。
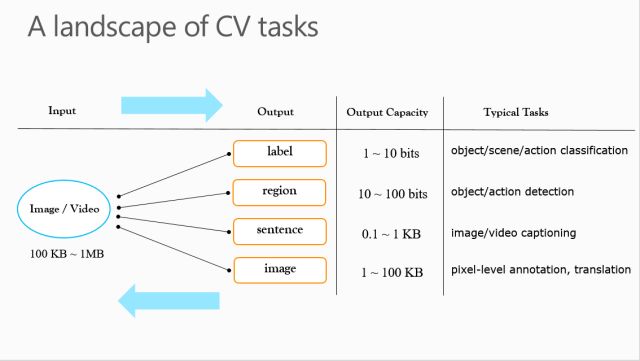
经过 50多年的发展,今生的CV已经成了比较大的领域,我做了一张表格来概括CV领域的多个任务。现在CV任务大都是从输入域(视觉:图像/视频)往输出域(描述)的映射。输入大部分都是图像和视频,而输出比较多样,比如标签,区域,还有句子,甚至是图像。每一种输出的大小是不一样的,十年前侧重于用标签描述图像,CV领域多是一些图像分类任务,比如物体、场景、动作分类。如果是二分类,输出就只有一个比特,如果有10个比特,就能用二的十次方种标签描述,区分出1000+类的场景或物体。如果把输出变大一点,就有了物体、动作检测问题,它的输出是边框坐标。如果输出更大一些,对应的任务就是图像或视频描述(image/video captioning)。如果段落非常大,输出有可能到1KB以上。现在还有一部分以图片做为输出的研究,比如说语义分割、图像转换等,其实我们可以把这个问题看成一个从图像到图像的描述问题。
传统做得比较多的方向是从左向右,最近几年因为计算机视觉领域的发展和深度模型的盛行,也开始有了一些从传统输出到输入域的反向映射。跟我们今天主题相关的,一个是标签,一个是句子,都跟语言非常相关。今天我也会着重讲讲从标签和句子生成图像和视频。
先定义一下视觉和语言,视觉指的是图像和视频,而语言的种类多一些,从传统的标签、标题、评论、诗歌,到对视频的语言描述,同时还包括VQA、情感等新语言。这种映射不仅可以从左到右,从右向左也越来越多。

以前的任务可能更加侧重从数据中学习知识,对应人类小孩的3~5岁。下一步CV领域应该是要往七岁的级别去演进了,可能会多一些内容生成。比如小孩子看过一些东西,学着做一些分类,慢慢的他会自己去设计一些东西,这是未来的趋势。
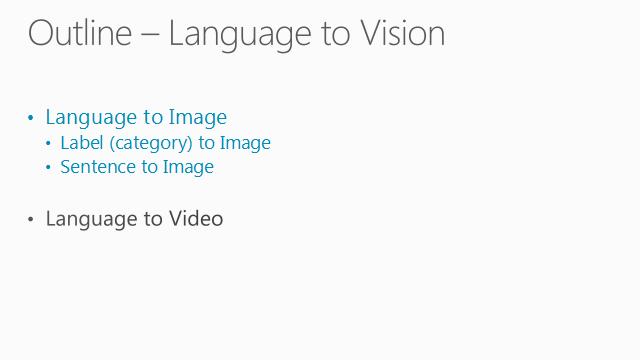
我的报告分为两个部分,一个是从语言到图像的映射,另外一个是从语言到视频的映射。先说说图像:这里面会涉及两种,一个是用标签生成图像,一个是用句子生成图像。
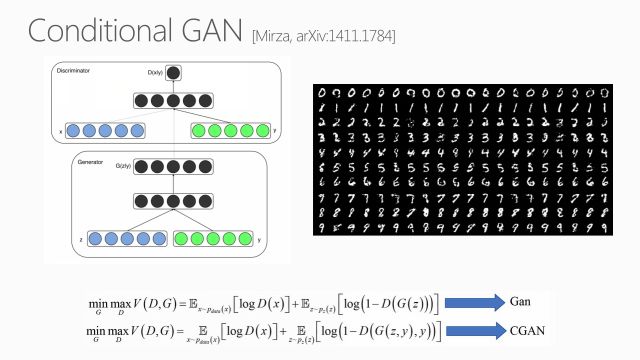
说起这个问题,不得不说2014年的文章,Conditional GAN。普通对抗网络的生成器是输入随机噪声产生一个图像。如果要把语言加进去,必须要有条件(conditioning)地输入额外信息。这时需用到Conditional GAN,其主要不同在于生成器除了随机噪声,还需要另外的信息y。如果y是标签,就是从标签到图像的转换,如果y是一个句子,那就成了标题到图片。这篇文章在当时是比较有开创性的,右面一些结果,从上到下每一行都是加上一个有条件标签的结果样例。
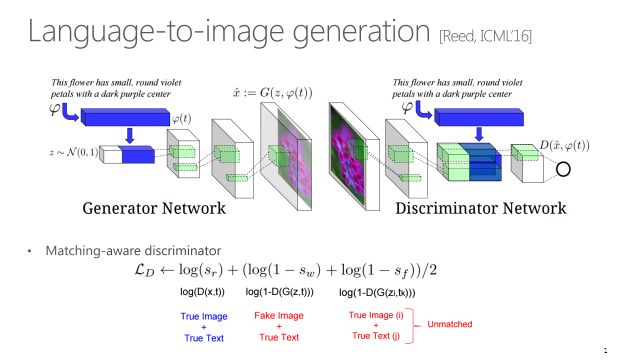
后来2016年有一篇ICML也是具有比较大的开创性,因为这是第一篇做语言到图像的转换。这篇文章在模型上跟Conditional GAN类似,唯一不同是把输入y换成了ψ(t)。其中t是文本序列,通过CNN-RNN网络对t进行了编码形成ψ(t),然后与随机噪声拼起来输入到生成网络,同时在判别网络的输入上也加了ψ(t),约束产生的图片要跟句子相关。这篇文章另外一个贡献点是除了分真假,还分了对错,即考虑了ψ(t)和生成对抗网络产生的结果的相关性。

2016年当时的结果还非常有限,只能在非常有限的领域,比如花和鸟,生成比较粗糙的结果,可以看到图像上有非常多的人造痕迹,而且分辨率也会比较小。
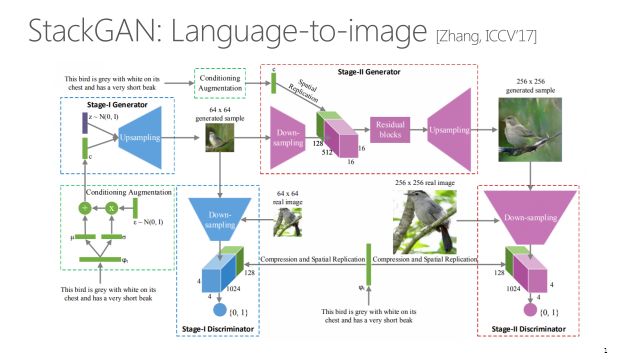
后来有一个比较著名的改进,Stack GAN,是语言到图像比较明显的改进。它产生的图片细节非常不错,在当时效果应该是最好的。主要思路是把生成过程分成两个阶段,像一个七岁的小孩画一只鸟的时候,肯定先从简笔画开始,不可能一开始画栩栩如生的眼睛、羽毛。第一阶段只画64×64的样本,只有大概的形状和颜色;第二阶段填充一些细节,对第一阶段产生的图片进行上采样,产生更大、更高清,并且具有更多细节的图像。

Stack GAN产生的图像,跟ICML2016的文章相比,一是细节更丰富,更像鸟更像花,另外它产生的图像分辨率更大。
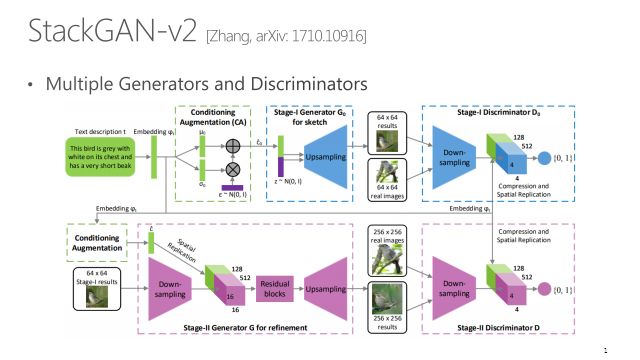
现在StackGAN也出了V2版本,这篇文章里面有一个新的扩展叫StackGAN++,引入了多个生成器和分类器,产生多个尺度的图像中间结果,效果进一步提升。

另外一篇比较有代表性的文章,Deep Attention GAN (DA-GAN),主要的贡献在于引入了注意力机制到GAN网络里。
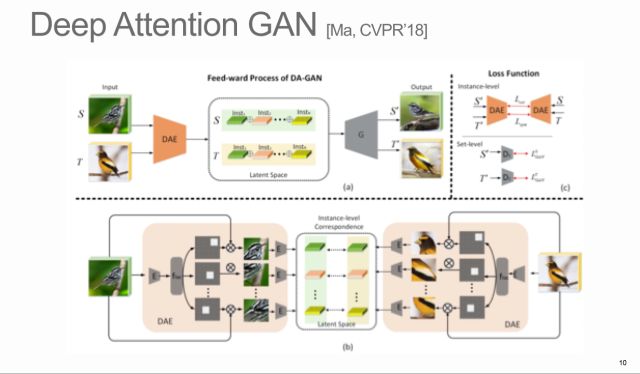
由于引入了注意力机制,可以在S和T上找到对齐的注意力元素:头对头,脚对脚,背对背,尾巴对尾巴。有了这种实例级的对齐信息,生成过程能更加关注关键位置。这篇看似跟语言没什么关系,但是如果把源S的域换成文本,就成了从标题到图像的应用。文本也可以在其中找到比较重要的一些word,比如某些部位、形状、颜色,以此画出更加生动的鸟。
刚才讲了很多都是基于语言到图像。接下来讲讲由语言到视频。这个领域可能比较新,文章非常少。
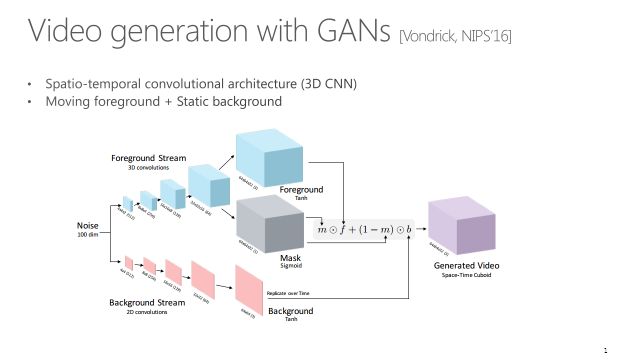
这篇文章发表在 NIPS’16,虽然和语言到视频没有什么关系,但还是值得提一下,因为这个是开创性的一个工作。它是从一个随机噪声生成视频:从噪声z开始分了两条线,一个产生前景,另一个生成背景。背景通道只有3,就是一张静止的图片,而前景是一个具有时间动态的视频。通过mask把这两条线做融合,最终产生一个视频。虽然当时结果不是特别好,但是非常有代表性。

接下来讲一讲真正的由语言转视频:给一段话,产生一个视频。现在有的方法,比如GAN、VAE,只有一些初步的探索,还没有比较完整的数据集和工作。

这篇文章To Create What You Tell: Generating Videos from Captions做得比较前沿。中间有三个例子,分别是三句话对应三个视频,一个比较简单,一个数字8从左到右移动。中间这个稍微难了一点,两个数字一个从上往下,一个从左往右,中间有重合。第三个更难,因为更贴近现实生活中的cooking视频。
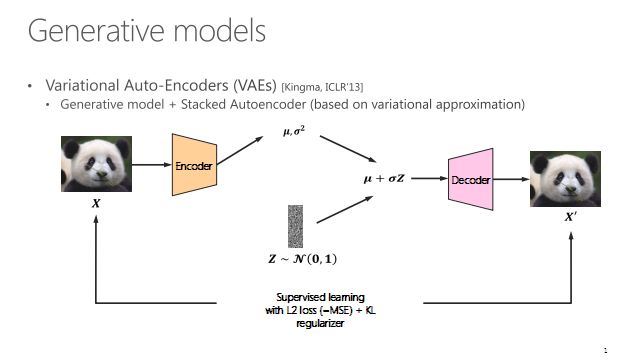
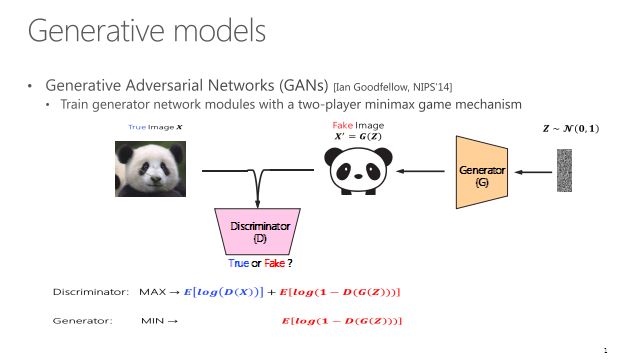
VAE产生的不是那么好,方法比较老。14年的GAN大家也都比较了解。

这个问题难点主要是要产生的信息量更大。2D到3D不仅有空间变化还有时间变化。产生的时候怎么去处理更大量的信息是一个难点。首先2D卷积肯定要换成3D的,直接产生3D volume,不能只产生一张图像。另外产生的视频要和输入的句子一致,不能产生的视频跟句子没有什么关系。

这个工作TGANs-C用的是联合对抗学习,T代表时间性(temporal),C代表标题(caption)。跟生成图像不同的是直接用3D卷积产生整个视频张量。
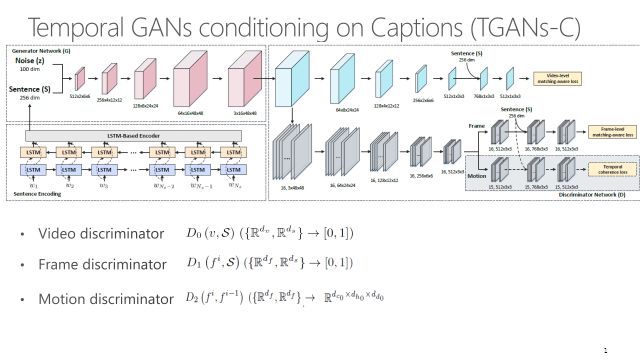
不仅要考虑帧级别上的真实性,也要考虑视频层次上的真实性。首先输出要像一个视频,另外要考虑运动连贯性。通过限制连续帧之间的差异可以让视频看起来更加真实。
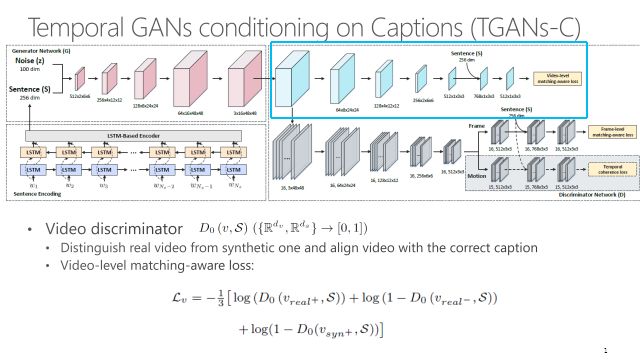
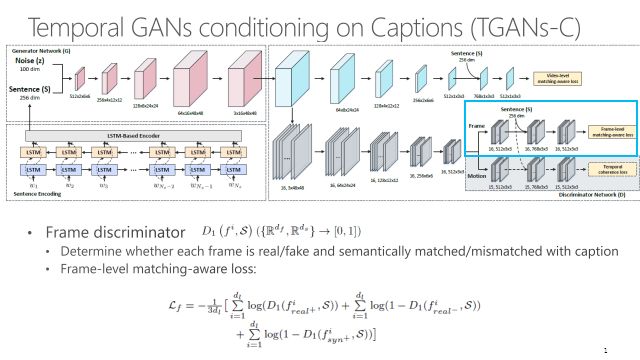
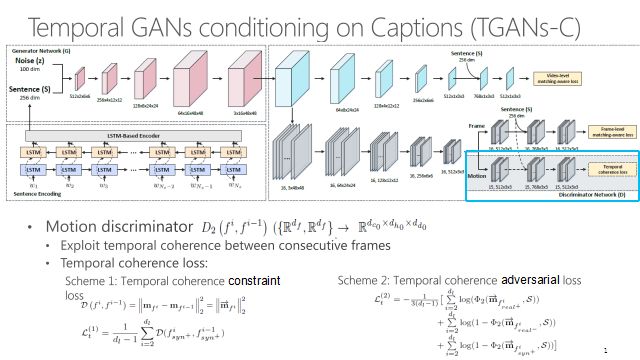
这个框架可能比较复杂,左下角的框做语言编码,通过一个多层LSTM把语言编码成一个向量,代表一个句子。把句子和随机噪声拼在一起,送进一个3D卷积网络,逐渐产生视频,上面这个框是3D生成网络。右面是D网络,普通的GAN只有一个判别器,而这有三个比较重要的D。D0判断产生的内容像不像视频,并且视频内容是否与输入文本S相关。D1保证每一帧像一个真实图像,并且里面的内容还是要跟输入文本有一定的相关性。最后要加入D2判别器,保证产生的视频运动有比较好的平滑性,让视频看起来真实。D2的输出是下面的张量判断器,指的是两帧之间的区别。这个约束包含两种方法,第一个是让运动尽可能的小,非常简单粗暴,如果小到一定程度这个视频就不动了。第二个手段是引入一个对抗损失,让产生的运动跟真实视频的运动要相似而不可区分。

目前使用的数据集有三个,对应我一开始展示的三个例子:一个数字在屏幕上移动;两个数字进行移动;还有一个比较真实的数据集,MSVD,是从真实的视频选出来的做饭视频。

如果把中间输出都画出来,可以看到随着训练过程从1000轮到10000轮,网络产生的每一帧更像真实的图像,而且帧和帧之间的运动也更流畅。

如果只加视频的判别器D0,效果还不太好;如果加入视频判别器和每一帧的判别器,效果略微好了一点;加了运动约束,这个视频就感觉更加的平滑,更像真实视频。如果我们不用这种简单粗暴的损失,而加对抗性损失的话,效果应该是最好的。
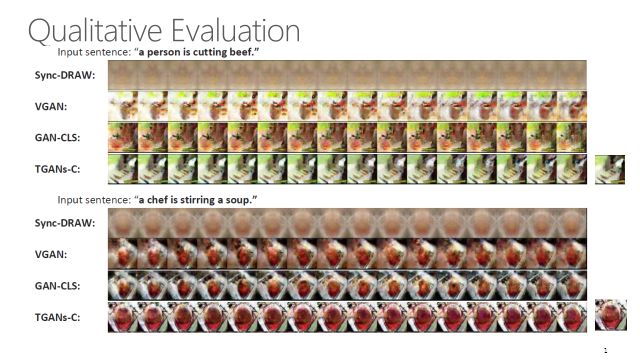
还有一些真实视频的例子,可以看到如果跟以前的方法比,TGAN-Cs目前是做得最好的。
GAN评价一直是比较头疼的问题,我们也做了一些用人评测的工作,判断要评测视频是不是真实,跟输入的文本是不是一致,同时还要看一下时间连续性,运动是不是比较流畅。实验发现结果还是非常好的。

接下来请允许我插一个广告,京东AI的CV Lab主要做视觉和多媒体相关的研究与应用,欢迎大家投递简历加入我们。另外,京东AI组织了一个AI时尚挑战赛,欢迎大家报名参加,目前我们开放了两个任务,一个是时尚风格识别,另外一个是时尚单品搜索,优胜者不仅有钱有奖,还有优先实习、访问机会。欢迎大家投递简历,欢迎大家参赛!
比赛链接为:
https://fashion-challenge.github.io/
文中提到参考文献的下载链接为:
链接:https://pan.baidu.com/s/1CWtw8XAqiwpvvymn8Icnjg
密码:2ood

主编:袁基睿 编辑:程一
整理:马泽源、杨茹茵
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 ruyin712。
作者信息:
作者简介:

张炜博士,京东AI平台与研究部,资深研究员。2015年获香港城市大学博士学位,天津大学硕士/学士,2013-2014年于美国哥伦比亚大学交流访问。主要从事多媒体计算、大规模视觉样例分析、多媒体内容安全等方面的研究。发表顶级国际期刊和会议论文20余篇,包括CVPR、ACM Multimedia、AAAI、T-IP、T-MM、T-IFS等,获得7项发明专利,ACM-HK Openday 2013最佳展示论文奖,在国际标准评测NIST-TRECVID竞赛中取得2012年“实例搜索”Runner-UP(24个国际知名高校与公司),开源代码被多次应用于学术界和工业界,其中包括清华大学、中科院、香港科技大学、复旦大学、阿里巴巴研究院、华为、南加州大学、昆士兰大学等单位。张博士是CCF-腾讯犀牛鸟科研基金获得者,曾担任ACM汇刊TOMM、Advances in Multimedia客邀编委,ICME、MMM、VCIP等知名国际会议分会/研讨会主席。
作者简介:

梅涛博士,京东AI平台与研究部AI研究院副院长,美国计算机协会杰出科学家,国际模式识别学会会士。他领导京东AI研究院视觉与多媒体实验室,聚焦该领域的基础研究和技术创新,并探索该领域技术在零售、物流、金融、云计算、以及时尚和设计等领域的应用。梅博士在多媒体分析和计算机视觉领域发表论文200余篇,先后11次荣获最佳论文奖,并拥有50余项美国和国际专利。梅博士目前同时担任 IEEE 和 ACM 计算机视觉与多媒体汇刊(IEEE TIP, IEEE TCSVT 和 ACM TOMM)等顶级学术期刊的编委,并且是2018年 ACM 多媒体年会(ACM Multimedia)的程序委员会主席和2019年 IEEE 多媒体年会(IEEE ICME)的大会共同主席。他是 IEEE 信号处理学会2018-2019年度杰出工业演讲者,并且担任中国科学技术大学、中山大学和复旦大学的客座教授。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站



