[ICML-Google]先宽后窄:对深度薄网络的有效训练

Go Wide, Then Narrow: Efficient Training of Deep Thin Networks
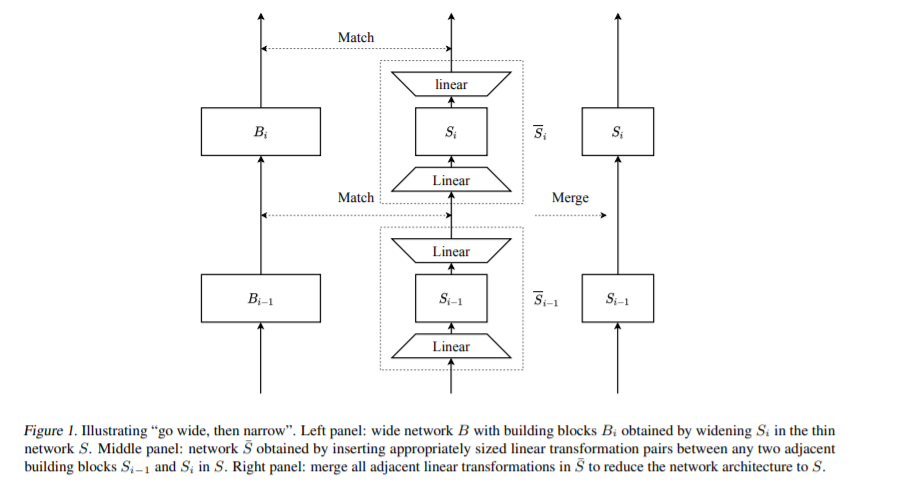
为了将深度学习模型部署到生产中,它需要准确和紧凑,以满足延迟和内存的限制。这通常会导致网络的深度(以确保性能)和瘦(以提高计算效率)。本文提出了一种在理论保证下训练深薄网络的有效方法。我们的方法是由模型压缩驱动的。它由三个阶段组成。在第一阶段,我们充分拓宽深薄网络,并训练它直到收敛。在第二阶段,我们使用这个训练良好的深宽网络来预热(或初始化)原始的深薄网络。这是通过让瘦网络从层到层模拟宽网络的直接输出来实现的。在最后一个阶段,我们进一步优化这个初始化良好的深薄网络。通过平均场分析,建立了理论保证,表明了分层模拟比传统的反向传播从头开始训练深薄网络的优越性。我们还进行了大规模的实证实验来验证我们的方法。通过使用我们的方法进行训练,ResNet50可以超过ResNet101, BERTBASE可以与BERTLARGE相媲美,后者的模型都是通过文献中的标准训练程序进行训练的。
https://www.zhuanzhi.ai/paper/d7345d410bbd97d5f5959aaec46667ba
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DTN” 可以获取《[ICML-Google]先宽后窄:对深度薄网络的有效训练》专知下载链接索引




登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文