【视频行为理解新边界】上交团队ActivityNet竞赛两项冠军,技术分享
1新智元专栏
来源:上海交通大学计算机视觉实验室
【新智元导读】近日,视频行为分类界的ImageNet竞赛——ActivityNet Challenge主办方在竞赛官网上正式公布了2017年的成绩。来自上海交通大学计算机视觉实验室的团队(自动化系研究生林天威,导师赵旭副教授;合作者:哥伦比亚大学寿政博士),获得了未修剪视频序列时序动作提名和时序动作定位两项任务的冠军。本文将分享冠军团队在两项竞赛任务中的算法思路和方案。

理解视频中人的动作和行为,是计算机视觉领域的挑战性问题,也是视频内容理解的关键,极具应用前景。ActivityNet挑战赛旨在催生视频行为理解的新算法和新技术,是目前视频行为理解领域数据规模最大、最具影响力的技术竞赛,已成功举办三届,吸引了全球计算机视觉领域诸多强队积极参赛。
近日,ActivityNet Challenge主办方在竞赛官网上正式公布了ActivityNet Challenge 2017的成绩。来自上海交通大学计算机视觉实验室的团队(自动化系研究生林天威,导师赵旭副教授;合作者:哥伦比亚大学寿政博士),获得了未修剪视频序列时序动作提名和时序动作定位两项任务的冠军。
在时序动作提名任务上,微软亚洲研究院团队获得第二名,马里兰大学团队获得第三名;在时序动作定位任务上,来自香港中文大学、苏黎世联邦理工学院等学校的联合团队获得第二名,伦敦帝国理工学院团队获第三名。本文将分享冠军团队在两项竞赛任务中的算法思路和方案。
ActivityNet名字与ImageNet相似,不同的是ImageNet是最大的图像识别数据库,而ActivityNet是目前视频动作分析方向最大的数据集。目前ActivityNet数据集的版本为1.3,包括20000个Youtube 视频(训练集包含约10000个视频,验证集和测试集各包含约5000个视频),共计约700小时的视频,平均每个视频上有1.5个动作案例,涵盖了共200个动作类别。今年的比赛数据在规模、多样性和自然度(用户生成的视频)上较往年均有显著提升,比赛任务也由去年的两项增加到了五项,包括:
任务1: 未修剪视频动作分类;
任务2: 修剪视频动作识别(Kinetics数据);
任务3: 时序动作片段候选提名;
任务4: 时序动作定位;
任务5: 视频事件检测和描述。
围绕上述5项竞赛任务,今年的挑战赛吸引了来自全球四大洲14个国家、42个团队参赛,比赛由阿卜杜拉国王科技大学视觉计算中心在CVPR 2017会议上举办,得到谷歌、英伟达、松下、高通等公司的赞助。
本次竞赛中,上交团队参加了任务3:时序动作片段候选提名,以及任务4:时序动作定位的比赛。其中,任务4要求在视频序列中确定动作发生的时间区间(包括开始时间与结束时间)以及动作的类别。这个问题与二维图像中的目标检测问题有很多相似之处。相关算法的算法内容一般可以分为两个部分:(1) 时序动作提名,产生候选视频时序片段,类似于Faster-RCNN中的RPN网络的作用;(2) 动作分类: 即判断候选视频时序片段的动作类别。两个部分结合在一起,即实现了视频中的时序动作检测。在今年的竞赛中,时序动作提名作为单项竞赛任务被单独列出(任务3)。
1. 任务测评方式
在时序动作定位问题中,mean Average Precision (mAP) 是最常用的评估指标。此次竞赛计算0.5到0.95, 以0.05为步长的多个IoU阈值下的mAP,称为 Average mAP,作为最终的测评以及排名指标。相较于使用mAP@0.5 作为测评指标,Average mAP 更看重在较严格IoU阈值下的检测精度。时序动作提名任务由于无需对时序片段进行分类,所以通常使用average recall (AR) 来进行评估。在此次竞赛中,Average Recall vs. Average Number of Proposals per Video (AR-AN) 曲线下的面积被作为最终的评测指标。举个例子,AN=50 时的AR分数 可以理解为对于每个视频,使用proposal set中分数最高的前50个proposal时,所能达到的召回率。
2.任务分析
如上所述,时序动作定位任务主要可以分解为时序动作提名和动作分类两个部分。后者,也就是动作识别方向,在最近一两年时间,准确率已经较高。在ActivityNet 的未修剪视频动作分类任务中,去年最高的Top-1 精度大概在88%,今年的第一名则提高到了92%左右。 然而,时序动作定位方向的性能指标依旧很低,各个数据集中,0.5 IoU阈值下的mAP都还没有超过 50%。基于上述情况,我们认为问题的关键在于提高时序动作提名环节的效果,因此,此次竞赛我们主要专注于时序动作提名任务。
3.方案介绍
此次竞赛我们主要对我们此前投稿在ACM Multimedia 2017的 SSAD模型(Single shot temporal action detection)[1] 进行了改进。具体的方法介绍可以见竞赛算法报告(http://activity-net.org/challenges/2017/program.html)。算法的整体框架如下图1所示。下面分别对各个部分进行简要介绍。
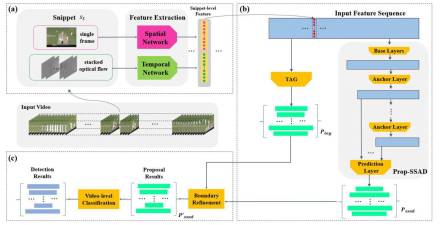
图 1 :整体方法框架。(a) 特征提取;(b)动作片段提名生成;(c)提名修正与动作定位。
特征提取。在特征提取阶段,我们主要将视频切分成16帧不重叠的单元,然后采用 two-stream network 提取特征。对于spatial network, 我们使用每个单元的中心帧提取特征;对于temporal network,我们则使用每个单元的中心6帧图像计算得到的光流图像提取特征。之后将两部分特征拼合即得到了最终的特征。
提名生成与修正。在该阶段,我们对SSAD模型进行了改进,改进后的模型称为Prop-SSAD。使用Prop-SSAD模型,对每个视频我们可以生成一个提名视频片段集合, 该方法得到的集合在高IoU阈值下的AR较低,即边界不够准确。因此,我们还实现了CUHK 今年在[2]中提出的 TAG (Temporal Action Grouping) 方法来生成另外一组proposal 集合, 该方法得到的proposal的边界相对准确,但由于TAG方法缺乏对于每个proposal的评价,因此该方法在AN 较小时的AR比较差,导致最终的AR-AN 面积指标不高。因此,我们以SSAD为主体,使用TAG来进行边界的修正。经过候选提名的生成和边界修正两个步骤,我们就可以获得一个未修剪视频上的时序动作提名集合。该结果即为此次竞赛时序动作提名任务的提交结果。
时序动作定位。在获得了动作提名后,我们还需要对其进行分类从而得到最终的时序定位结果。由于ActivityNet上大部分视频中只有一类动作,因此我们直接使用了视频级别的分类结果作为对应视频所有提名片段的类别。
对于时序动作提名任务,由于在测试集上只能看到最终的AR-AN面积指标,所以实验部分我们给出的是验证集上的结果。下表中是提名任务的基准方法、Prop-SSAD方法和 修正的Prop-SSAD方法的性能,可以看出边界的修正对于提名的召回率有进一步的提高效果。
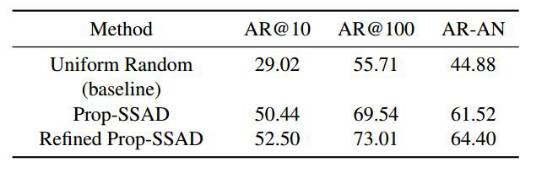
表格 1:验证集上时序动作提名的结果比较
对于修正的Prop-SSAD方法,使用官方提供的测试代码,我们还可以得到AR-AN曲线,如下图所示。
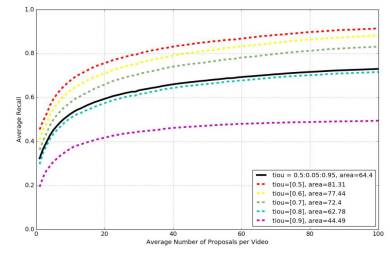
图 2: AR-AN曲线
对于时序动作定位任务,我们的方法在验证集上的效果如下表所示。其中Ours@n 代表每个视频使用提名集合中的前n个提名。从表中可以看出,提名集合中分数最靠前的一小部分提名贡献了大部分的时序定位mAP。
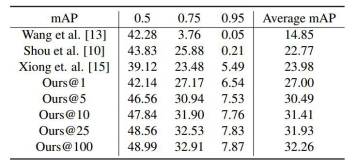
表格 2:验证集上的时序动作定位结果比较
下表所示是我们的方法在测试集上的效果,对照方法为此前该数据集上相关论文的效果,不包括此次竞赛的方法。可以看出,我们的方法比起此前的方法提高了大约5%的mAP。
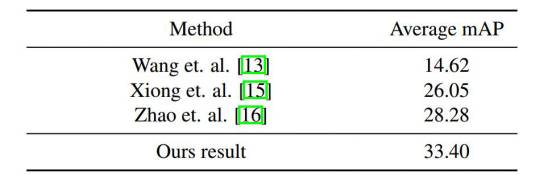
表格 3:测试集上的动作定位结果比较
通过参加此次ActivityNet挑战赛,我们主要有以下几点收获:
(1)动作提名的质量对后续动作定位的效果有很大的影响, 目前改进动作定位的重点在于提高提名集的质量;
(2)提名集中最靠前的一小部分提名片段贡献大部分的定位mAP;
(3)时序卷积以及锚点机制在时序动作提名与检测任务中能起到很好的效果。
在后续的工作中我们会对此次竞赛的方案进行进一步的改进与优化,希望大家关注我们的工作。
参考文献
[1] T. Lin, X. Zhao, and Z. Shou. Single shot temporal action detection. 25nd ACM international conference on Multimedia, 2017.
[2] Y. Xiong, Y. Zhao, L. Wang, D. Lin, and X. Tang. A pursuit of temporal accuracy in general activity detection. arXiv preprint arXiv:1703.02716, 2017.





