超详细!使用OpenCV深度学习模块在图像分类下的应用实践
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
极市导读:本文来自6月份出版的新书《OpenCV深度学习应用与性能优化实践》,由Intel与阿里巴巴高级图形图像专家联合撰写,系统地介绍了OpenCV DNN 推理模块原理和实践。极市为大家争取到5本赠书福利,详见文末。
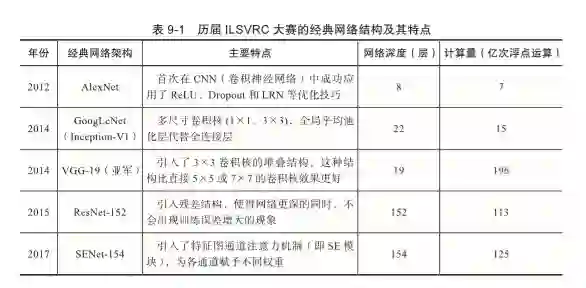




9-2 命令行参数定义
std::string keys="{ help h | | Print help message. }""{ @alias | | An alias name of model to extract preprocessing parameters from models.yml file. }""{ zoo | models.yml | An optional path to file with preprocessing parameters }""{ input i | | Path to input image or video file. Skip this argument to capture frames from a camera.}""{ framework f | | Optional name of an origin framework of the model. Detect it automatically if it does not set. }""{ classes | Optional path to a text file with names of classes. }""{ backend | 0 | Choose one of computation backends: ""0: automatically (by default), ""1: Halide language (http://halide-lang.org/), ""2: Intel's Deep Learning Inference Engine (https://software.intel.com/openvino-toolkit), ""3: OpenCV implementation }""{ target | 0 | Choose one of target computation devices: ""0: CPU target (by default), ""1: OpenCL, ""2: OpenCL fp16 (half-float precision), ""3: VPU }";
9-3 声明命名空间及定义全局变量
using namespace cv;using namespace dnn;
std::vector<std::string> classes;9-4 主函数(解析命令行参数)
int main(int argc, char** argv){CommandLineParser parser(argc, argv, keys);const std::string modelName=parser.get<String>("@alias");const std::string zooFile=parser.get<String>("zoo");keys +=genPreprocArguments(modelName, zooFile);parser=CommandLineParser(argc, argv, keys);parser.about("Use this script to run classification deep learning networks using OpenCV.");if (argc==1 || parser.has("help")){parser.printMessage();return 0;}float scale=parser.get<float>("scale");Scalar mean=parser.get<Scalar>("mean");bool swapRB=parser.get<bool>("rgb");int inpWidth=parser.get<int>("width");int inpHeight=parser.get<int>("height");String model=findFile(parser.get<String>("model"));String config=findFile(parser.get<String>("config"));String framework=parser.get<String>("framework");int backendId=parser.get<int>("backend");int targetId=parser.get<int>("target");
9-5 主函数(类别文件解析)
if (parser.has("classes")){std::string file=parser.get<String>("classes");std::ifstream ifs(file.c_str());if (!ifs.is_open())CV_Error(Error::StsError, "File " + file + " not found");std::string line;while (std::getline(ifs, line)){classes.push_back(line);}}
9-6 主函数(异常情况检查)
if (!parser.check()){parser.printErrors();return 1;}CV_Assert(!model.empty());
9-7 主函数(初始化网络并创建显示窗口)
Net net=readNet(model, config, framework);net.setPreferableBackend(backendId);net.setPreferableTarget(targetId);
static const std::string kWinName="Deep learning image classification in OpenCV";namedWindow(kWinName, WINDOW_NORMAL);
9-8 主函数(创建图像输入对象)
VideoCapture cap;if (parser.has("input"))cap.open(parser.get<String>("input"));elsecap.open(0);
9-9 图像处理循环(读取一帧图像)
Mat frame, blob;while (waitKey(1) < 0){cap >> frame;if (frame.empty()){waitKey();break;}
9-10 图像处理循环(设置网络输入)
blobFromImage(frame, blob, scale, Size(inpWidth, inpHeight),mean, swapRB, false);net.setInput(blob);
Mat prob=net.forward();9-11 图像处理循环(解析网络推理输出)
Point classIdPoint;double confidence;// 找到概率值最大的类别id,该类别为图像所属分类minMaxLoc(prob.reshape(1, 1), 0, &confidence, 0, &classIdPoint);int classId=classIdPoint.x;
9-12 图像处理循环(可视化推理结果)
// 获取网络推理运算耗时,并叠加到原始图像上std::vector<double> layersTimes;double freq=getTickFrequency() / 1000;double t=net.getPerfProfile(layersTimes) / freq;std::string label=format("Inference time: %.2f ms", t);putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX,0.5, Scalar(0, 255, 0));// 将图像类别标签和概率值叠加到原始图像上label=format("%s: %.4f", (classes.empty() ?format("Class #%d", classId).c_str() :classes[classId].c_str()),confidence);putText(frame, label, Point(0, 40), FONT_HERSHEY_SIMPLEX,0.5, Scalar(0, 255, 0));// 显示图像imshow(kWinName, frame);}// 循环结束,退出主函数return 0;}
福利时间




登录查看更多
相关内容

Arxiv
7+阅读 · 2019年4月16日

相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月16日