对话式交互崛起,从百度度秘看对话式AI的技术实践

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
以下为演讲整理,略有增删:
今天,我们的演讲主题围绕对话式 AI。我将首先介绍对话式 AI 产品的背景,包括产品应用场景、市场阶段等;第二部分展开介绍产品中的基本技术问题,同时分享百度的深度学习和增强学习在一些模块的应用。

在介绍对话式 AI 之前,我们有必要先了解一下 Conversational UI(对话式 UI)的概念。很简单,就像我们今天的分享一样,我们用对话来实现自然交互,这其中所用到的技术就是对话式 AI。我不用对话系统来定义,原因在于,要实现自然交互要用到很多技术,可能不仅限于大家传统理解上的自然语言技术,还包括搜索、推荐、知识图谱等,所以说,对话式 AI 基本上是一个 AI 的集大成者。
所谓的对话式交互也是一种人机交互的方式,我们换一个视角,从人机交互的演变来看。
在 PC 时代,最早的交互方式就是 command 命令,输入一个有限的命令集,输出非常有限的文字。再往后大家开始享受到图 UI 的便利,大家可以在界面中进行点击、拖拉等各种操作,搜索也开始变得多模态了。到了移动时代,交互方式成为所谓的 GUI+,可以输入更多信息,包括地理位置等,输出也更多,包括触感等,这就是所谓的 AI 和 IoT 时代。我认为可以更好地混合这些交互方式,而且更重要的其实是自然的交互方式,因为前三种交互方式更多地是在适应机器。虽然 GUI 很好用,但是大家可能下载过一些 App,发现很难用,设计并不好用。从这个角度来看,在 AI 时代,应该让机器来适配人。语音交互其实就是一种非常自然的机器适配人类的过程。


有人可能会问,一定要用语音吗?什么时候语音对话交互会非常有效呢?其实有三个场景,一是你只想对话或只能对话;第二种是既可以对话,也可以使用 GUI,但对话的方式更加灵活、成本低时。只能对话是受限场景,受限场景还有很多,比如手表屏幕太小,对话显然更方便,UI 的交互效率很低。还有一种限制于人的场景,比如车载、厨房、洗漱台等手被占用的场景,另外就是非受限的场景。那么,语音对话式交互如何比其他交互更好?可以更灵活地应对长尾开放式交互,让操作更灵活,交互成本更低?
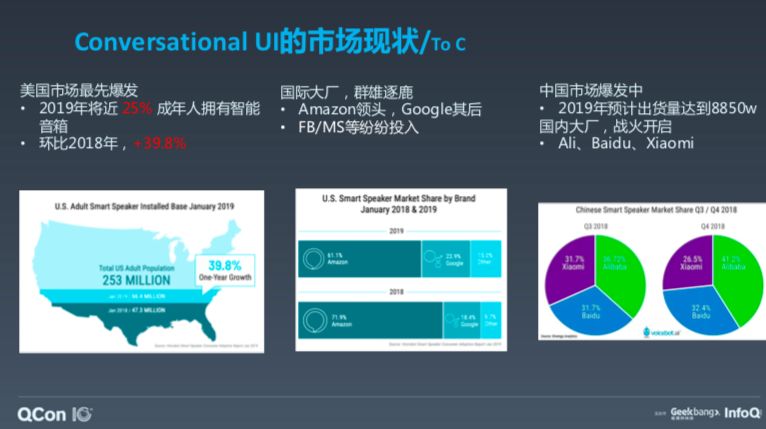
数据显示,很多人都用上了智能音箱,现在美国智能音箱市场是最具爆发力的,据预测,2019 年,25% 的成年人家里都会拥有至少一台智能音箱,相较 2018 年同比增长 39%。当然,智能音箱市场玩家众多,包括大家熟知的亚马逊 Echo,它点燃了市场的一把火,紧随其后的是 Google。据预测,国内市场智能音箱的出货量将达到 8000 多万,战火从去年开始烧起来,今年烧得最激烈,百度不算非常成功,但还在追赶,类似于谷歌的角色。现在份额第一的是阿里的天猫。
对话 Bot 类型
接下来我将展开介绍技术问题,以及在克服技术问题中采用的详细技术。
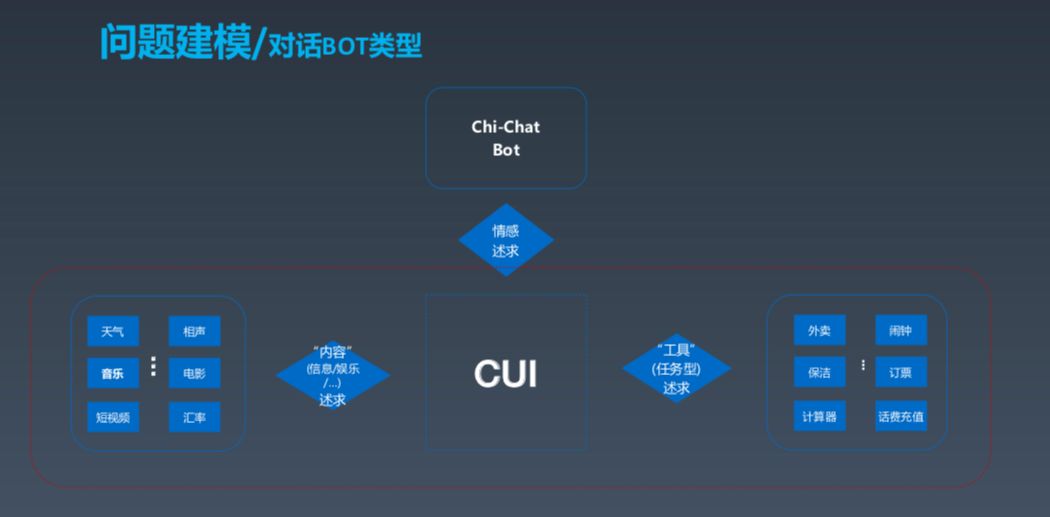
在讲问题建模之前,我们先划分一下所谓的对话类型。按需求来分,分为这几部分,第一部分是通过对话获取内容,比如天气、音乐、汇率等信息和内容,类似于搜索;还有一种偏向工具型,如点外卖、定闹钟等;另外还有一种重要的对话类型,即情感诉求。
从大的技术框架来说,Bot 可以分为内容型和工具型两类,与闲聊型 Bot 的技术差异比较大,下面将重点展开这部分,学术界称之为 Task-Orented Bot,即面向任务型的聊天机器人。
算法框架
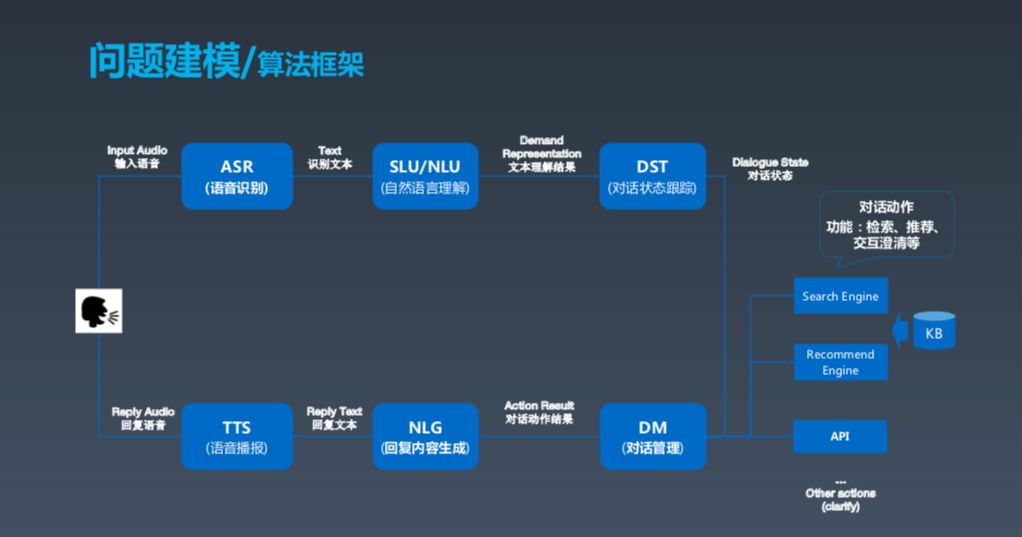
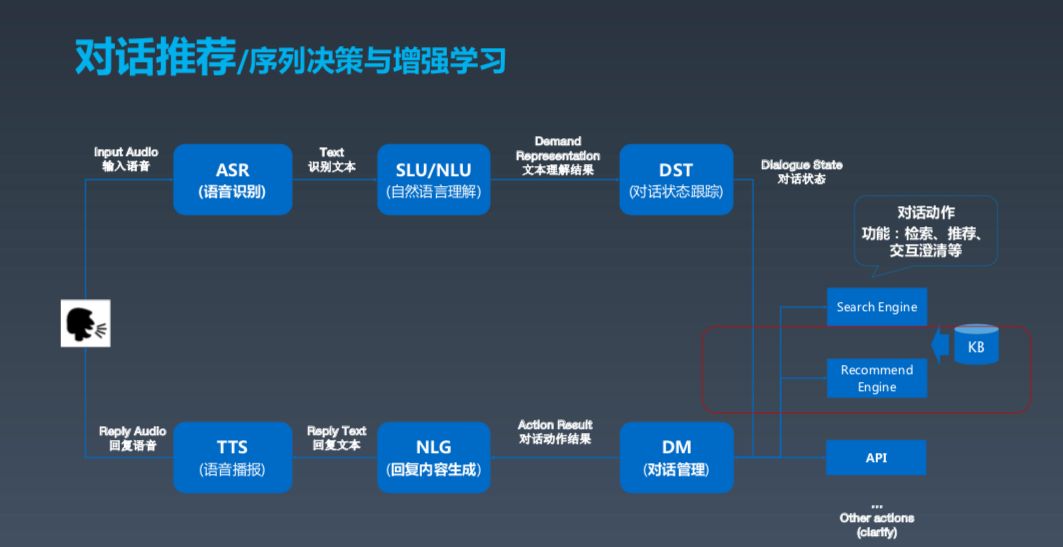
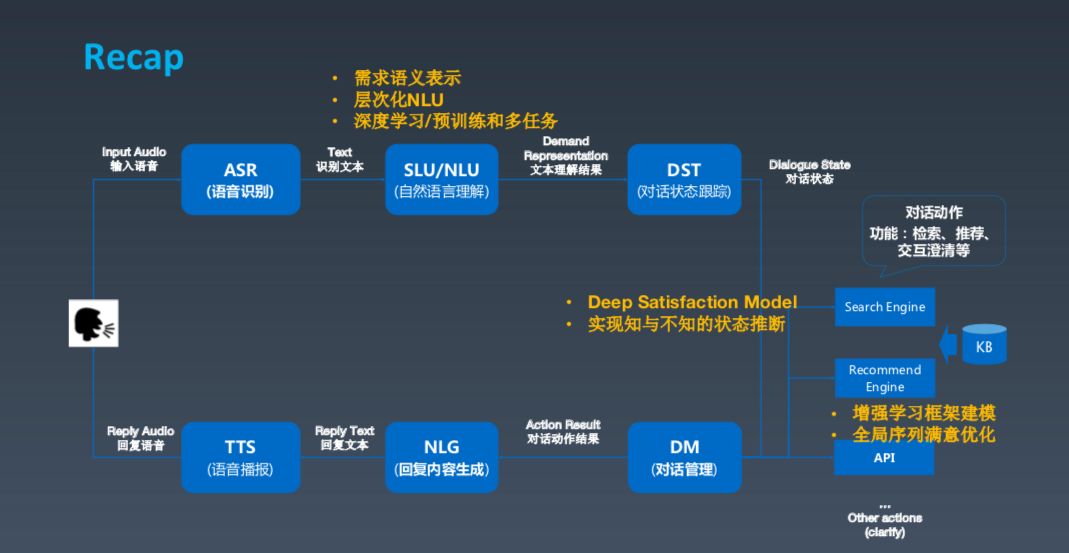
这是一张经典的对话式框架建模图,基本上分为几大块,第一块是用户,如果用户发出语音,我们需要先做(ASR)语音识别,包括之前的唤醒。ASR 之后产生文本,再之后进行对话理解,了解用户相应的需求。这两个部分实际上是做对话的跟踪状态跟踪和对话管理,可以理解成根据上下文确定并采取一些动作以满足用户需求。这些动作包括搜索、推荐等。最后,Bot 组织成一段人话,生成语言,用 TTS 的方式输出。这就是对话式 Bot 的基本框架。
接下来,我会围绕这个框架展开介绍一下其中的技术。举例说明,帮用户设置一个提醒,我们需要做什么。
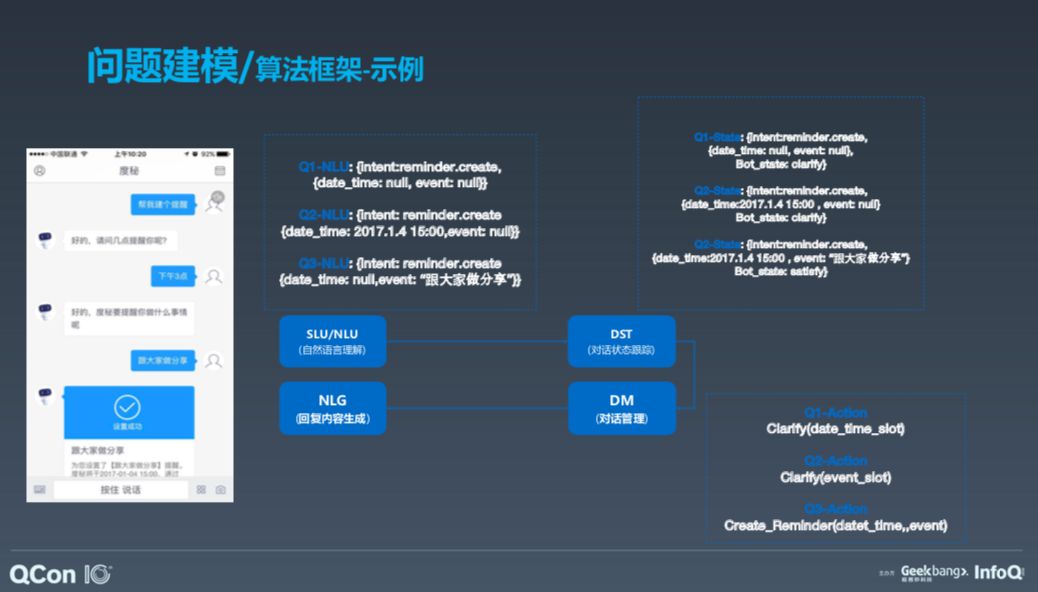
首先是进行 NLU,即自然语言理解,了解任务目的是设置一个提醒。接着是对话状态跟踪,即要达到什么样的状态;对话管理,即理解任务是否可以创建,比如定时几点提醒用户。接着进入第二轮,如果用户要求定下午三点的闹铃,那么把两轮信息连接到一起,创建三点钟提醒用户这一问题。这是创建提醒任务的整个框架。
首先介绍自然语言理解。这包含两大核心问题,第一个问题是什么是机器自然语言理解,以及机器用什么表达理解,即机器的语义理解表示;第二大问题是用什么算法。
语义表示
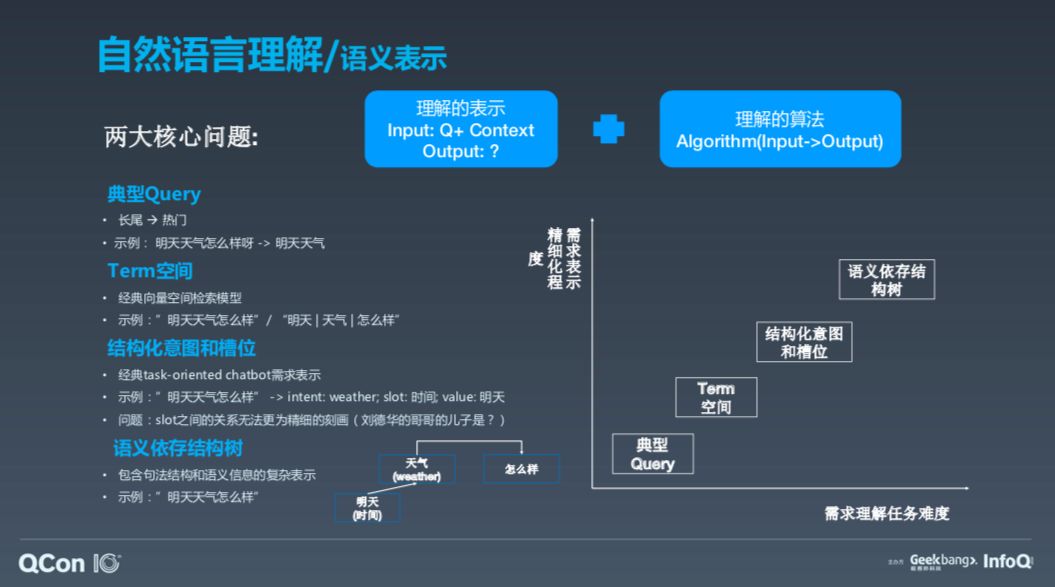
以我的理解,语义表示可以分为这几类,第一种是用文本表示,我们叫做典型 Querry;第二种语义理解是 Term 空间;第三种是结构化意图和槽位,这是学术流派流行的术语,它分为两部分,第一部分是意图(intent),第二部分是槽位(slot),即更加详细地描述需求的信号,但实际它有一个问题,即 slot 的关系很难精细刻划,比如问“刘德华的哥哥的儿子是谁”,由于 slot 是个平行结构,无法表示这种复杂的关系。所以,句法解析流派也有用基于语义异存结构数来进行语义表示。
算法 -Hierarchical NLU Framework

谷歌做过一个叫做 Multi-action 的技术,一次可以做两个动作,比如“帮我打开电视机,调到中央一台”,这就是两个动作。这用结构化意图和槽位很难做到,因为它很难理解两个动作之间的关系。所以,需求理解的任务难度和需求表示的精细化程度之间的关系,是越精细的理解越难。
对此,我们有 Hierarchical NLU Framework 把热门 Quarry 变成一个搜索,通过 deep match 也可以把它变成翻译问题。
对于 Term 空间理解,我们用一个推理数做形式化推理,以理解中间的逻辑。实际上 Siri 很早就做了这个技术,但现在很多流派都走向 ERNIE Pretrained Based Joint Deep Model ,我们也将展开介绍一下这部分的工作。
ERNIE Pretrained Based Joint Deep Model

这个工作我们称之为 ERNIE Pretrained Based Joint Deep Model。先来看一下任务,一是进行意图检测,即分类任务;二是槽填充,即序列标注任务。以“来一首祝杰伦的中国风歌曲”为例,意图就是播放音乐,slot 有各种标签,如 singer、unit 等。
BERT 很厉害,刷爆了各项 NLP 任务,我们的很多工作都基于此。BERT 的一个核心思想是迁移学习,我们对此做了两方面的改进,可以说是将迁移学习思想进一步推进,第一是对 EARNIE,用自己的数据做了训练和改进,核心的一点是要迁移其他产品的数据,同时迁移知识的数据;第二点是联合任务学习,当然这也不是新鲜事,但重要的是要结合 Intent Detection 和 Slot Filling 两个任务之间的关系和数据。

接下来是我理解的 BERT 成功的几个关键点。第一个关键点是双向 Transfomer,之前的建模都是从左到右或从右到左进行预测,而 BERT 是双向的;第二是它可以进行 Next Sentence Prediction;第三是它的大框架很好,Pre-train+Fine-tuning 的模式不新鲜,但它的设计很巧妙,基本上能够刷爆各种任务。ERNIE 在 BERT 上进行改进之后,在中文任务上基本上是全面超越,核心点是我们之引入了知识图谱。
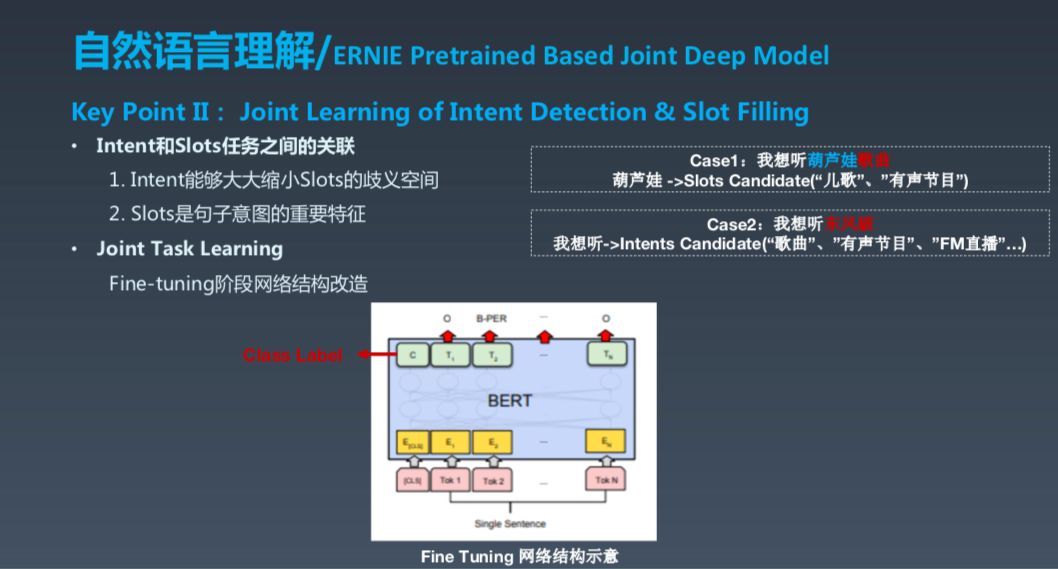
第二个关键点是 Next Sentence Prediction 和 Slot Filling 之间本身有非常强的关联性,这在两方面,第一个是 Intent,它能够大大缩小 Slot 的歧义空间,比如说我想听葫芦娃的歌曲,而葫芦娃可能既是一首儿歌,也是一个有声节目,甚至还是动画片。所以如果你知道它是歌曲就简单多了,而 slot 也可以反过来贡献意图的明确性。所以,我们进行了改造,BERT 在 fine-tuning 时,如果是做分类任务,它是在 lable C 的位置做分类,如果是做 Token lable,它是在每一个 Token 上面截 Soft Max,这相当于一个 Joint 任务,联合起来进行 Fine-Tuning。
知之为知之,不知为不知,是知也
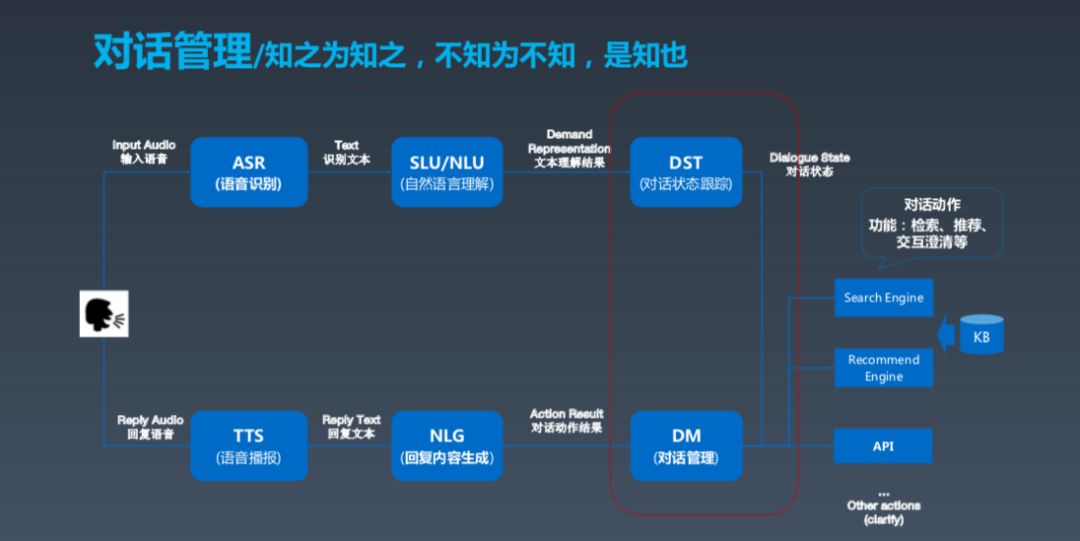
NLU 之后还有一个很重要的对话管理部分,从抽象逻辑上来看就是理解之后,做动作之前还需要做一些事。第一,了解系统的状态;第二,根据现在的状态选择最好的动作。所以,对话管理下的副标题叫“知之为知之,不知为不知,是知也”,意思就是你知道就知道,不知道别瞎说。这很重要,对话智能需要真正做到这一点,不要不懂装懂。
模块定位与赋能
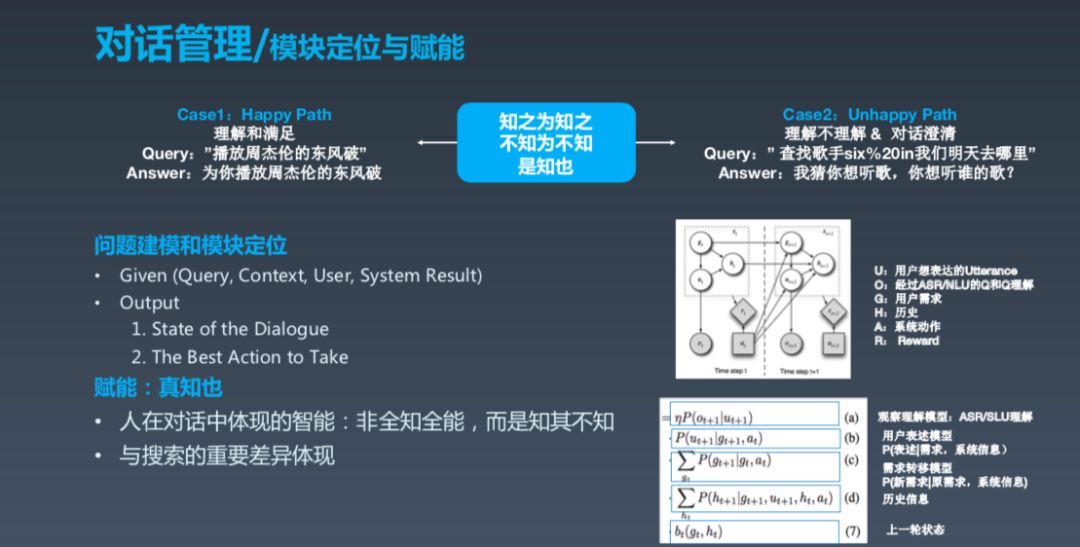
真实场景中环境非常复杂,比如在混入各种杂质声音的时候,系统要了解自己所处的状态,并采取最佳行动。其实人在对话当中体现的真正的智能是非全知智能,人类并非懂得一切,而且可以意识到自己并非全知全能,但这一点对机器来说很难。这也是我们今年在探索的重要课题。
Deep Satisfaction Prediction Model

从技术角度讲,用机器学习建模重要的是要有 lable,什么是知,什么是不知,这是最难的。实际上在对话过程中没有像网页点击等其他强烈的信号,我们对此做了很多探索,比如离线用户行为挖掘,充分挖掘用户的行为特征。
序列决策与增强学习
实际上,对话系统不仅限于自然语言理解,还涉及一些其他技术,比如在对话中进行推荐。推荐的核心定位是要能够激发用户持续的对话,这基本上与其他系统的推荐目标一致。这其中的一些推荐场景与搜索 query 类似,但和其差别在于希望获得整个对话全局过程中的满意度。
增强学习建模
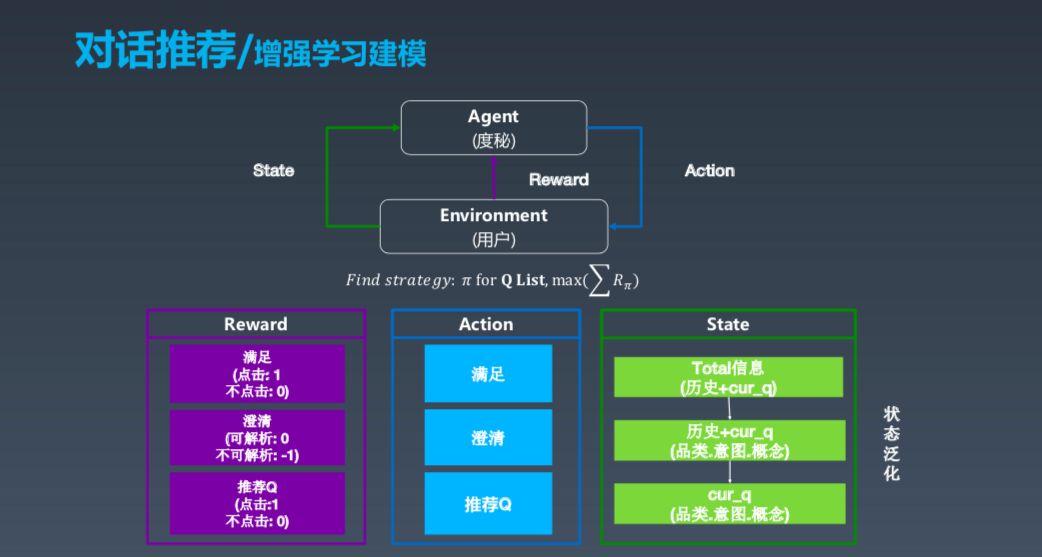
这是序列决策的建模的过程,我们用增强学习的框架来建模。这个大的框架中有 Agent 和 Environment,其中 Agent 是度秘,Environment 是用户,用户会发出信号,度秘结合各种因素得出状态,采取行动,最后整体环境会给出 Reward。这个过程看起来清晰简单,但是在工业界真正实现并做好非常不易。
增强学习框架下的算法求解
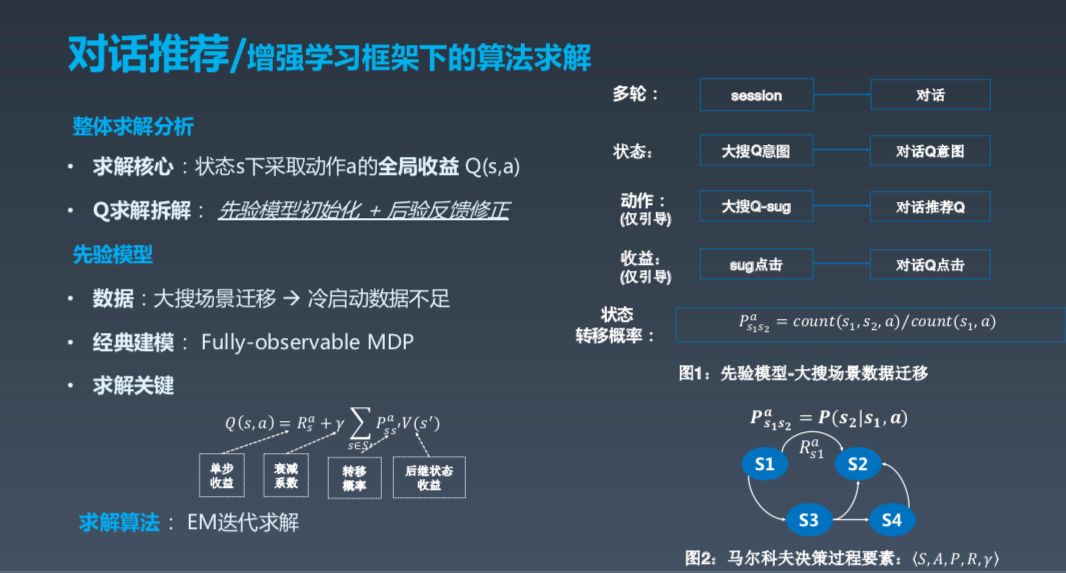
增强学习框架下的算法求解核心在于在状态 s 下采取动作 a 的全局收益,这里的 State 可以理解成各种信息的融合,包括用户信息、历史信息等,完全的 MDP 是指这一轮状态只跟上一轮相关。动作可以建模成几类,一种是满足曾经,另一种是推荐。Reward 这部分实际上是最有技巧,也最难做的一部分,因为到底怎样做 Value 很难。我们希望找到一个策略,能够让所有的 Action 路径加起来 Reward 最大,所以这是一个程序的序列问题。其实求解分析很容易,比如说如何在 X 的状态下,采取一个 Action 让全局的收益最大。
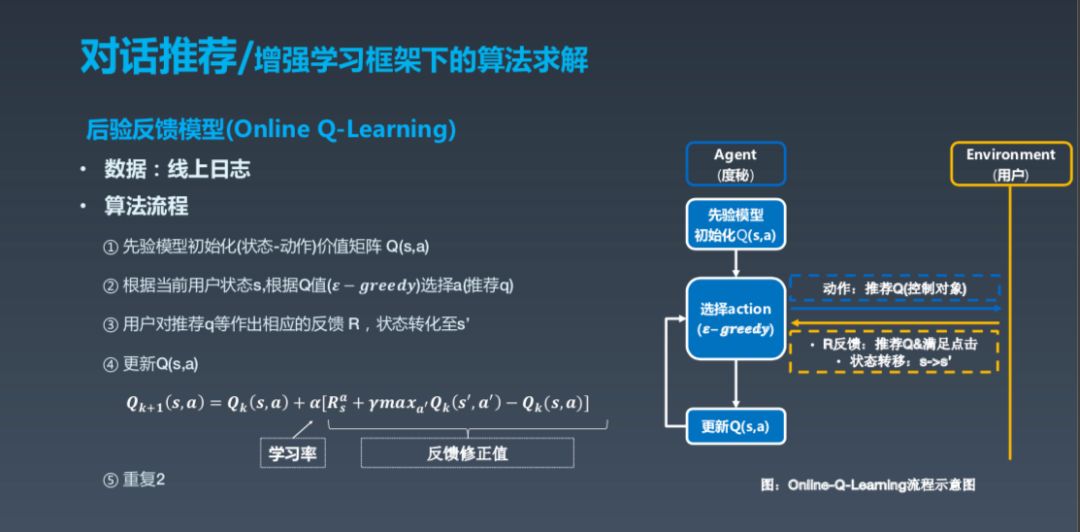
然后是后验反馈模型,是指先验模型初始化后,用 epsilon greedy选择 Action,epsilon greedy 可以理解成有一定概率的贪心,选择之后更新 Q,得出相应的学习率等。
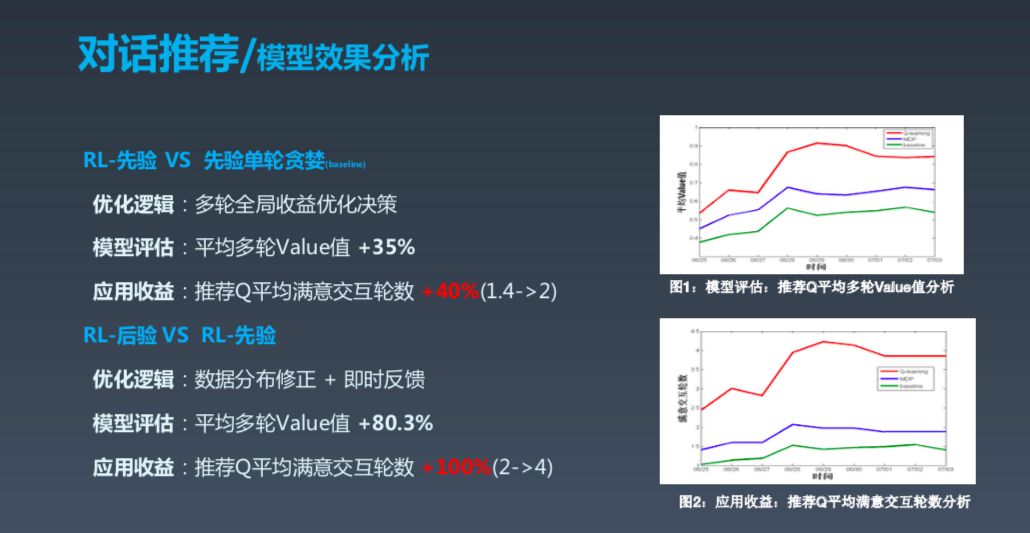
这是一些数字,可以看到效果还是不错的。
最后做一个总结,我大概讲了几部分,第一部分是产品的场景,接着是技术层面,其中包括自然语言理解,这里需要记住两点,一是理解到底是理解什么,理解成什么,第二个问题是用什么方法来理解。另外就是对话 AI 的经典增强学习框架建模方式。

我们正在进行的探索包 NLU 中的形式推理进行 Multi-action,深度增强学习,以及 Term 和 KG 的混合探索,NLG 中的智能场景话术等。
谢剑,百度资深算法工程师、度秘算法团队技术负责人。武汉大学人工智能方向硕士,2012 年毕业后加入百度,先后在凤巢、商业知心、搜索等部门从事机器学习算法工作。在计算广告、自然语言处理、搜索、推荐等方向有多年的技术和团队管理经验,现为度秘算法团队 Tech Leader,负责对话理解、对话管理、对话推荐等方向算法研发和管理工作,有多项计算广告、搜索、对话系统方向专利。
QCon 全球软件开发大会(北京站)2019 已经圆满结束,QCon 上海 2019 即将起航,点击 「 阅读原文 」了解详情。大会 7 折早鸟票限时开售,现在报名立减 2640 元,团购可享更多优惠!有任何问题欢迎联系票务小姐姐 Ring ,电话:13269076283 微信:qcon-0410


你也「在看」吗?👇



