WWW2022 | 基于交叉成对排序的无偏推荐算法
现有大多数推荐系统都是对观测到的交互数据进行优化,而这些数据受到之前曝光机制的影响,会表现出许多偏差,比如流行偏差。经常使用的基于pointwise的二元交叉熵和pairwise的贝叶斯个性化排序损失函数,并不是专门设计来考虑观测数据的偏差的。因此,对损失进行优化的模型仍然会存在数据偏差,甚至会放大数据偏差。例如,少数受欢迎的商品占据了越来越多的曝光机会,严重损害了小众物品的推荐质量。
在接下来介绍的这篇工作中,其开发了一种新的学习范式CPR,全称为Cross Pairwise Ranking,其实现了在不知道曝光机制的情况下不带偏见的推荐。与反倾向评分(IPS)不同,该工作改变了样本的损失项,并创新性地对多次观察到的交互作用进行抽样,并将其作为预测的组合形成损失。另外还在理论上证明了这种方法抵消了用户/物品倾向对学习的影响,消除了曝光机制引起的数据偏差的影响。对IPS有利的是,所提出的CPR确保每个训练实例的无偏学习,而不需要设置倾向分数。实验结果表明,该方法在模型泛化和训练效率方面均优于最新的去偏方法。

论文地址: http://staff.ustc.edu.cn/~hexn/papers/www22-cpr.pdf
Github地址: https://github.com/Qcactus/CPR
1 Motivation
现有方法的损失函数(例如最常用的二元交叉熵和成对贝叶斯个性化排名)并非旨在考虑观测数据中的偏差。因此,针对这类损失进行优化的模型将继承数据偏差,甚至会放大偏差。因此,作者设计了一种新的学习范式命名为,从而在不知道曝光机制的同时实现无偏推荐。
2 Preliminaries
2.1 Biasedness of Pointwise and Pairwise Loss
作者指出了现有的pointwise损失和pairwise损失都是有偏的。
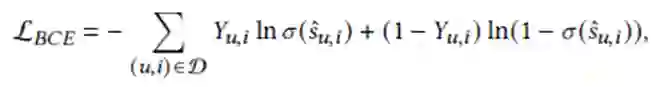 其中
是观测到的交互和未观测到的交互的总集合,
表示用户
对物品
有过交互,反之
,
表示用户
和物品
之间的预测分数。当
时,
越大越好,相反,
越小越好,即:
其中
是观测到的交互和未观测到的交互的总集合,
表示用户
对物品
有过交互,反之
,
表示用户
和物品
之间的预测分数。当
时,
越大越好,相反,
越小越好,即:
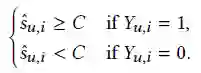
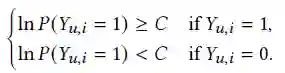
由于
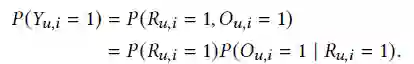
因此上述公式改写为:
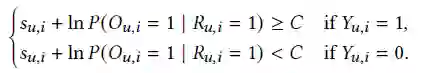
证明pairwise损失有偏与pointwise类似,具体细节可参照原文。
3 Method
3.1 CPR Loss
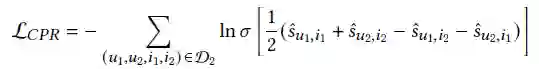
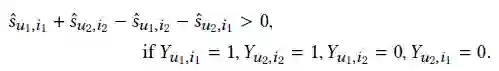
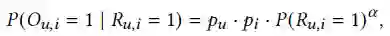
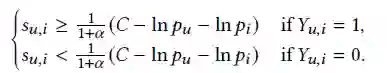
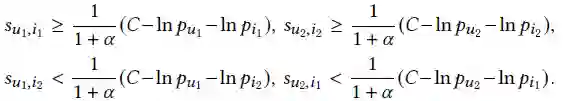
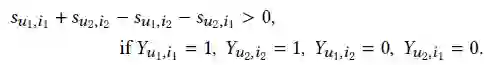
3.2 Extending to More Interactions
上述对于CPR损失的讨论仅限于包含两组观测到的正样本,以下将其拓展到多组正样本:
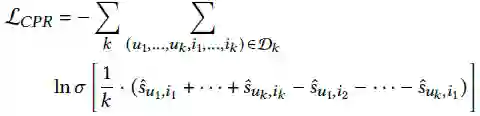
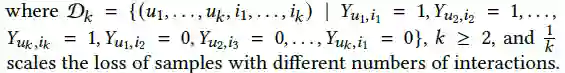

3.3 Discussion
作者在论文中还讨论了CPR与基于IPS的方法,setwise排序的不同,具体细节参照论文。
4 Experiments
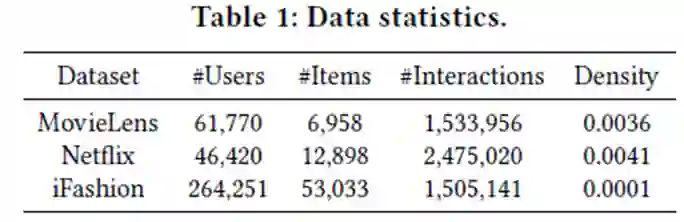
Datasets
Metrics
Recall@K, NDCG@K and ARP@K
Baselines
BPR, Multi-VAE, CausE, Rel-MF, UBPR, DICE
Results
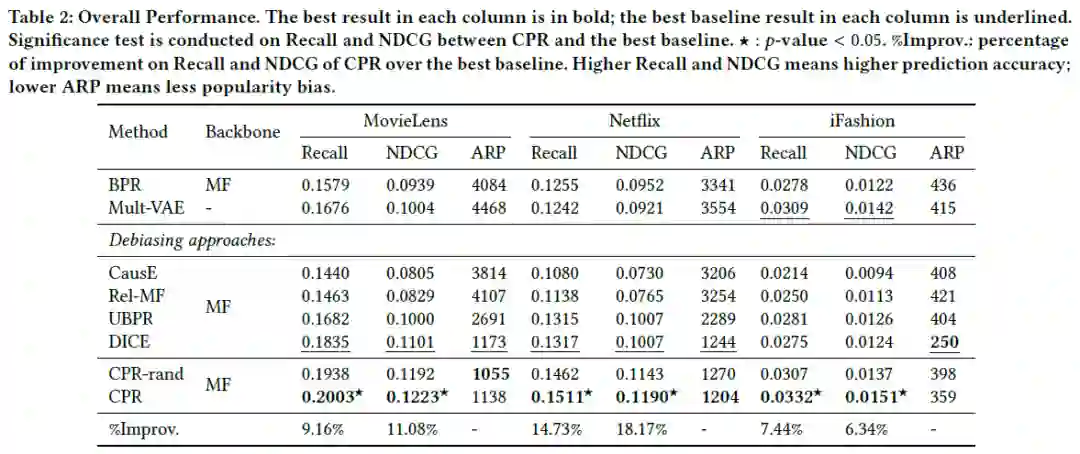
可以看出,在三个数据集上,CPR都取得了明显的性能提升。
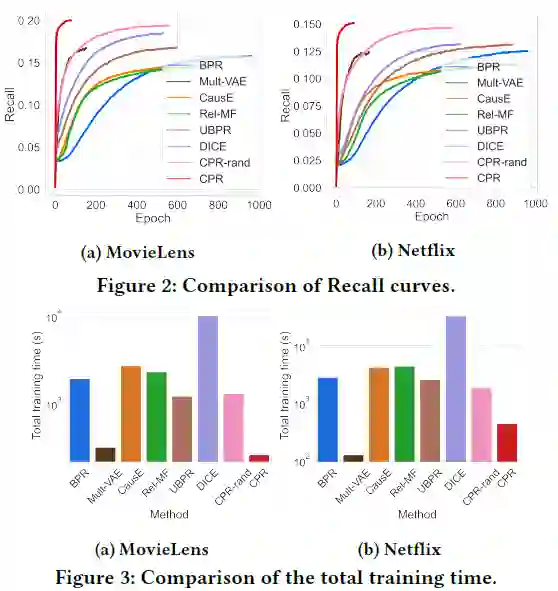
CPR方法相较于其他方法能够更早收敛到最优,训练时间也相较于baseline更短。
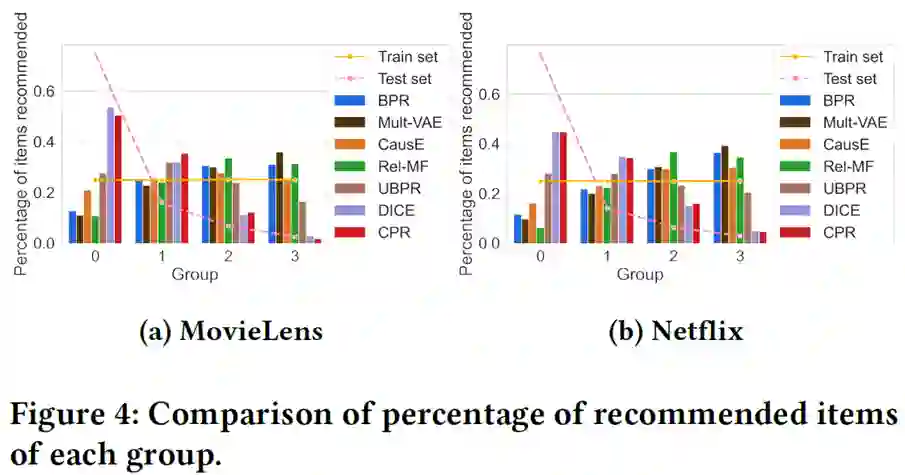
可以看出物品被推荐的概率随着组ID的增大而减小,说明流行物品被推荐的概率逐渐降低。
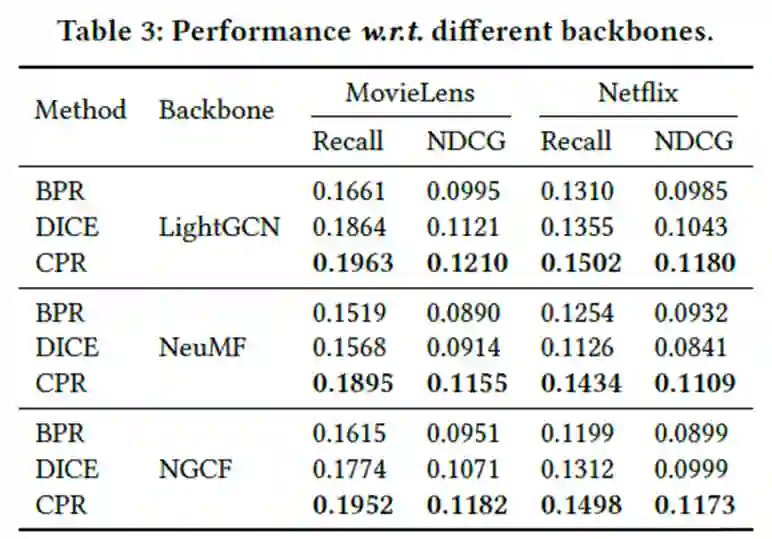
可以看出CPR损失不论应用在哪些backbone上,都明显优于baseline。
更多实验细节参考原文。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。



