WWW'21 | 基于图的视角学习推荐系统的公平表征
关注【GEAR 图学习】公众号,每日获取最新图学习研究资讯!

1基于图的视角学习推荐系统的公平表征
论文标题:Learning Fair Representations for Recommendation: A Graph-based Perspective
作者:Le Wu, Lei Chen, Pengyang Shao, Richang Hong, Xiting Wang, Meng Wang
单位:合肥工业大学人工智能研究所 & 微软研究院
论文链接:https://arxiv.org/abs/2102.09140
代码链接:https://github.com/newlei/FairGo
今天给大家分享合肥工业大学人工智能研究所团队被WWW'21接收的一篇论文:「Learning Fair Representations for Recommendation: A Graph-based Perspective」。International World Wide Web Conferences (WWW)会议是万维网领域的国际顶级学术会议,位列CCF-A级别。WWW 2021会议共收到投稿1736篇,最终录用357篇,录用率为20.6%。
本文来源于知乎作者知乎@随意凯的解读,转载已获授权。文章来源:https://zhuanlan.zhihu.com/p/433648567
2摘要
本文指出当前绝大多数研究AI公平的方法都有个强假设,就是每个个体是独立的,然后在此基础上设计各种复杂网络去消除敏感信息从而确保公平。但推荐系统显然不适合,因为用户和物品天然地形成了一张双向图,在图结构上体现了协同相关联系。文章提出了基于图上的novel技术适用于任何推荐模型公平的方法。这里的公平是指在用户建模过程中不会暴露用户的敏感信息。具体讲,就是给定任何推荐模型的原始embedding,我们都要学习一组filters,用来将用户/物品的原始embedding变换到一个独立于敏感特征集合的filtered embedding space。对每个用户,这种变换是通过以用户为中心的图之下进行对抗学习实现的,以达到不管是在filtered user embedding还是在用户的子图结构上都做到混淆每个敏感特征的目的。
3介绍
在所有去偏差模型中,公平性表征学习由于简单、通用且技术成熟先进而大方异彩,这种方法就是要学习一个数据分布,该分布能够保持主要信息同时又能过滤掉任何隐藏在数据中的敏感信息。公平性表征学习主要方法有:添加公平性正则化项和使用对抗学习技术以满足给定任何敏感值,其特征条件分布都相同。
本文采用公平性表征方法来从表征学习中消除敏感信息,而且可以融入任何现代推荐结构中。也就是说,公平性推荐问题的问题就转变成了如何学习一种公平的用户、物品表征以实现将敏感信息从embedding中剔除。
事实上,即使有些用户-物品操作没有包含任何用户敏感信息,但是直接利用一些SOTA的用户和物品表征学习仍然会导致用户敏感信息的泄露,这是因为用户行为和属性在社交理论中可以发现是具有关联性的。例如,一个人的隐私(如性别、政治观点)都是可以从他的行为中预测出来的。如果利用现有的一些公平感知的有监督ML技术来确保用户embedding的公平,一定程度上确实可以做到,但之前也说了,这些方法都是基于实体之间是独立的,是在没有建模这些实体间关联性的基础上来考虑消除不公平。而其实在用户和物品形成的双向图中,每个用户embedding不仅仅和他的行为相关,而且与相似用户的行为、有相同物品的用户之间都有隐层关系。这就打破了之前的假设条件,而且这其实也是CF推荐的根基。确切的讲,即使我们消除了embedding的敏感特征,但是以用户为中心的图结构仍然会暴露其敏感属性导致泄露。
为了验证上述思想,文章提供了实验证明,就是用SOTA embedding models基础上,展示用户特征是如何从用户中心的局部图结构来推断出属性值。这个初步的实验也就表明了用户敏感特征也和用户中心图有关系。因此,从图结构角度来学习推荐的公平表征非常重要。
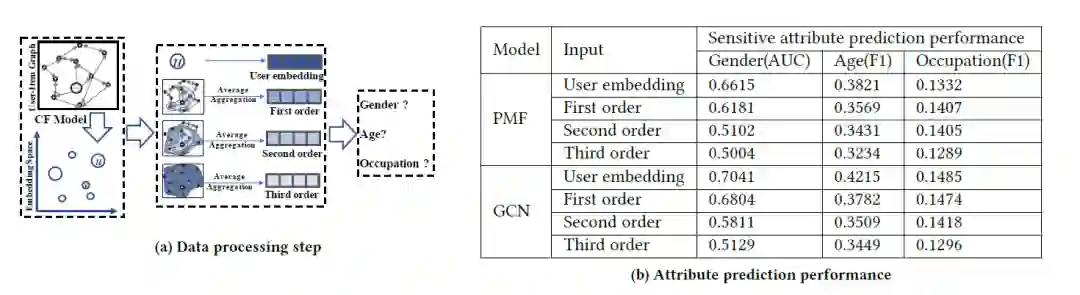
提出的方法是通过对每一个敏感特征学习一个filter来讲用户/物品的原始embedding变换到filtered embedding space中。每个用户都被表示成一个子中心图结构,filters就可以在这种结构上基于对抗学习训练得到,鉴别器用来预测对应的属性。
4相关工作
4.1推苃算法
用户集 ,物品集 ,交互矩阵 代表用户 对的评分,如果没交互过记作0分。构建一个用户-物品双向图 是在 评分矩阵 上描述的
代表用户和物品的embeddings,是通过编码学到的:; 预测偏好
当前embedding方法主要有两类:一类是经典的基于模型的latent factor方法,另一类是基于模型的神经图方法。latent factor模型采用MF技术来学习到无ID的embedding;而神经图模型主要是在用户-物品图上迭代地叠加多层图卷积,在l+1次迭代中,该层的每个节点embedding都是l层邻居embedding的卷积聚合。一般来说,神经图模型效果更好,因为他把协同信号隐藏地注入到图中用于用户和物品的embedding学习。
4.2公平算法和应用
目前解决公平算法的方法主要分为:基于因果的方法、基于排序模型、公平性表征学习方法。文章采用公平性表征学习方法中的对抗训练学习方法,这相对于加入正则项的方法而言,理论简洁巧妙而且可以很方便迁移到许多下游任务中。其实作者也不是第一个提出用图结构进行表征学习,之前有工作也同样利用了SOTA graph embedding学习表征,对每个敏感特征都相应的训练一个鉴别器,但不足的地方就在于他虽然是基于图的,但却仅仅利用了节点embedding学习,仍然是通过独立地对每个节点的敏感信息进行过滤实现。这还是会导致用户的敏感信息会被他们喜欢的物品所暴露。
4.3推荐公平性
有实验证明了RS的后处理技术来提升推荐多样性的方法将会放大用户的不公平性。对于CF方法的推荐,研究者提出了四个新的指标来解决具有二进制敏感属性,来衡量优势组和劣势组之间预测行为的差异,这些公平指标被当做是正则化项来达到组公平的目的;re-ranking模型主要是通过设计公平指标来引导学习过程以减轻不平等现象。文章不同于之前的工作,1. 用户天然的形成了用户-物品双向图结构 2. 用户敏感信息可能会被他的局部图结构所暴露。
5FAIRGO模型
目标:在filtered space中进行公平表征学习实现模型无关的方法
设定用户敏感属性集 ,提出Fair Graph based RecOmmendation (FairGo)模型(这些大佬是真的会取名字)
5.1结构总览
给定原始embedding matrix 和敏感属性集 ,FireGO设计了包含 个filter的组成成分作为filter结构,用来移除 中的信息,每个节点都是从原始空间到filtered空间: 也等于 ,过滤结构部分记作 每个敏感属性都和对应的sub filter 有关,每个节点都会通过这些过滤 结构,然后在filtered embedding space中记作:
给定filtered embedding space,预则偏好就记作:
对于过滤结构,我们的目标:一方面当然是要能够很好的表征用户的偏好以实现高的推荐准确率,另一方面,这些filtered embedding也应该是公平的,不会遗漏任何敏感信息。
使用对抗学习技术实现公平。将filtered embedding 作为输入,第 个子鉴别器应该尽力预测 第 个属性值。过滤结构和鉴别器网络实际上是进行具有下面值函数 的two-player minimax game:
(左右可滑动公式)
VR是评分分布的极大似然,VG是预测属性分布的极大似然,是这两个值函数的平衡参数,如果其为 0 ,那么公平性需求就无了。对于评分分布,我们假设其遵从高斯分布,因此VR值函数如下
5.2用于公平性建模的图对抗学习
我们很自然的可以想到在每个节点上设计如下值函数
其实上述值函数仅仅是在用户独立性假设的前提下考虑filtered embedding space中的公平性, 是一个节点层次的表征。
对每个用户 ,我们记 代表用户-物品图 中用户 的自中心网络(其实就是 -hop子图网络),这一部分的目标就是使用户的 敏感信息不会从 中暴露出来。而一般的全局表征 并不擅长捕捉局部图结构,因此我们一需 要为每个用户得到一个自中心图结构的表征
是用户局部图结构的结构表征函数,相应的pu是这个函数的输出,是一个图结构的表征。这一 步可以通过聚合用户L阶邻域的表征,也可以用SOTA的复杂图结构学>模型 对于 ,我们同样也可以执行对抗训练来保证敏感信息不会被局部图结构暴露:

公平需求就定义在了图结构对抗学习过程中,每个用户的自中心网络结构综合了节点层次的值函数 ,也包含了如结构层次的值函数 ,那么总的
5.3自中心图网络概要
1. 加权平均池化
这里 是一阶邻域filer embedding的平均,那如果泛化到更高阶,就会得到下式:
就对应的一开始说的边权矩阵 , 就是节点i对应的直接相邻的节点集。
这种简单平均聚合的方式效果并不好,原因是他并没有考虑到建模过程中不同阶的图结构会有不同程度的影响,显然,阶数大的节点离当前用户更远,那他暴露用户敏感信息的能力显然也就越低。
2. 局部值聚合
我们希望每一层用户的自中心图结构表征 都不会暴露敏感信息。记 表示第I层子结构的值 函数,就得到下列值函数:
因此子图结构部分的总的值函数就表示为:
用来平衡不同阶值函数的影响,越大表示对应值函数越重要。
3. 基于学习的聚合
局部值聚合需要人工设定不同的 ,不是很好。所以我们可以直接用DNN来学习子图结构表示。使 用MLP来建模所有层的非线性聚合
文章指出之所以使用MLP,而不是其他更nb的结构,是因为文章的出发点是关注对图结构的建 模是否对于公平表征学习是有效的。
6理论分析
这部分主要是对提出的一系列公式进行理论上的分析,有兴趣的可以直接阅读论原文。

7实验部分
7.1实验设置
使用MovieLens-1M和Lastfm-360K作为数据集。
模型包含三部分:预训练推荐模型、使用提出的FairGo模型、验证公平表现
因为是rating prediction,所以使用RMSE指标验证模型性能,使用AUC和全局F1指标作为公平性指标(AUC针对于二分类表现,全局F1用于多值属性表现),这两个指标都是值越小越好。
使用PMF、GCN、ICML_2019提出的一个方法和Non-parity作为baseline,其中由于GCN一开始是用于ranking based loss的,所以对其进行修正以适合于我们的rating based loss,并在图卷积过程中增加了评分值。实验包括单属性值设置和多属性设置。
7.2模型表现
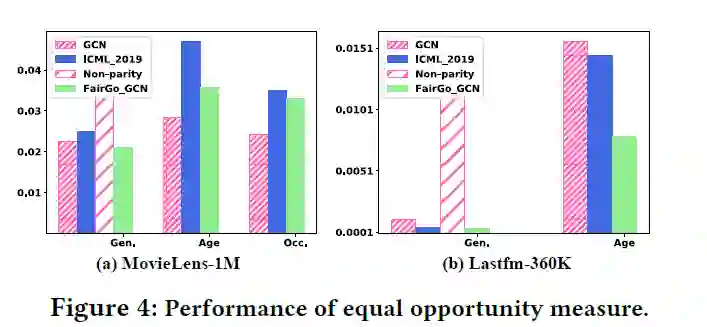
首先是GCN比PMF要好,这是因为GCN模型缓解了稀疏性问题,而且也发现了和敏感特征相关的隐藏特征;第二,所有模型考虑了敏感特征过滤之后性能都下降了5%到10%。这是因为我们过滤掉了敏感特征,而这些特征对于rating来说又是有帮助的。Non-parity方法表现并不好,这是因为他并没有直接剔除掉embedding中的敏感信息。对比这些模型,FairGo_GCN从图结构考虑了实体之间的联系,因而达到了rating和公平的双赢表现。因此,FairGo框架仅牺牲少部分推荐准确率提升了公平性能。Fair_GCN全面压制FairGo_PFM。

7.3模型分析详解
实验结果也表明了基于学习的聚合方法要比局部值聚合的方式要优秀,而局部值聚合又要比一阶邻域方法要好(也就是平均加权聚合);此外,实验也发现图结构层次越高则性能更佳,但我们都知道图结构一般都是两三层,就是因为他时间开销大,模型train不起来。(GCN这个要是解决了,估计要起飞了)
衡量组公平,通常使用统计对等(statistical parity)和机会均等(equal opportunity)两个方法
statistical parity方法是用来衡量一个二进制属性(如性别)的统计对等性,公式如下:
如果是多个值,我们只需要根据不同的属性值将用户分到不同组中,然后取每个组predicted rating的标准差来衡量statistical parity

equal opportunity方法考虑到每个组预测准确性,对于二进制属性的公式如下:
如果是多个值,同statistical parity的多值处理办法
8结论
论文出发点是因为当前大多数研究公平性的工作都是建立在个体公平性的假设之上,不适合于推荐场景。文章提出的FairGo模型是从图视角考虑公平,而且能够适合于当前任何推荐模型当中,即模型无关。理论分析也证明了提出的方法同样适合于多个敏感特征。未来想要将提出的模型应用到某个特定领域下。
本期编辑:李金膛
审核:陈亮


