准确率、精准率、召回率、F1,我们真了解这些评价指标的意义吗?

本文首发于知乎 https://zhuanlan.zhihu.com/p/147663370
作者 | NaNNN
编辑 | 丛末
-
二分类模型的常见指标快速回顾 -
多分类模型的常见指标详细解析
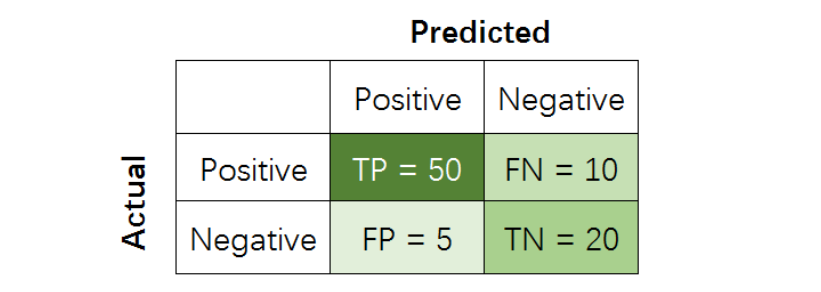
-
True Positive (TP): 把正样本成功预测为正。 -
True Negative (TN):把负样本成功预测为负。 -
False Positive (FP):把负样本错误地预测为正。 -
False Negative (FN):把正样本错误的预测为负。
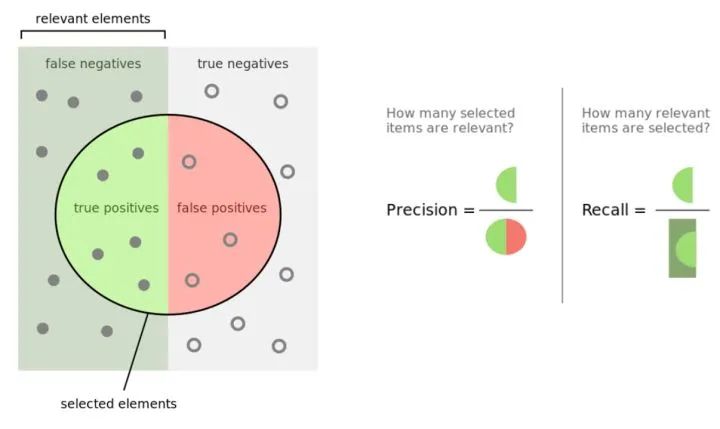




在一堆癌症病人和正常人中,有多少人被系统给出了正确诊断结果(患癌或没患癌)?
当False Negative (FN)的成本代价很高 (后果很严重),希望尽量避免产生FN时,应该着重考虑提高Recall指标。
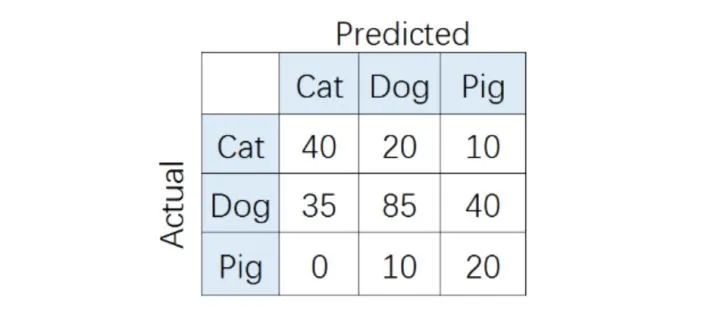
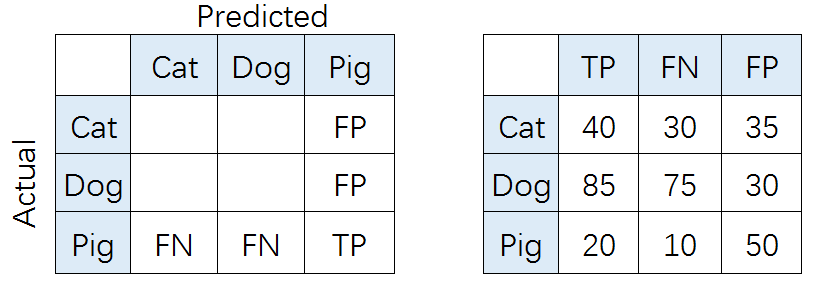
比如,对类别「猪」而言,其Precision和Recall分别为:


 (P代表Precision)
(P代表Precision)
 (R代表Recall)
(R代表Recall)


 (W代表权重,N代表样本在该类别下的真实数目)
(W代表权重,N代表样本在该类别下的真实数目)
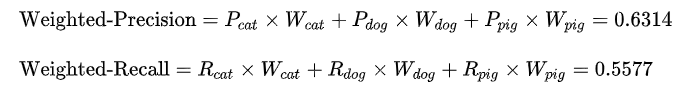



import numpy as np
import seaborn as sns
from sklearn.metrics import confusion_matrix
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, average_precision_score,precision_score,f1_score,recall_score
# create confusion matrix
y_true = np.array([-1]*70 + [0]*160 + [1]*30)
y_pred = np.array([-1]*40 + [0]*20 + [1]*20 +
[-1]*30 + [0]*80 + [1]*30 +
[-1]*5 + [0]*15 + [1]*20)
cm = confusion_matrix(y_true, y_pred)
conf_matrix = pd.DataFrame(cm, index=['Cat','Dog','Pig'], columns=['Cat','Dog','Pig'])
# plot size setting
fig, ax = plt.subplots(figsize = (4.5,3.5))
sns.heatmap(conf_matrix, annot=True, annot_kws={"size": 19}, cmap="Blues")
plt.ylabel('True label', fontsize=18)
plt.xlabel('Predicted label', fontsize=18)
plt.xticks(fontsize=18)
plt.yticks(fontsize=18)
plt.savefig('confusion.pdf', bbox_inches='tight')
plt.show()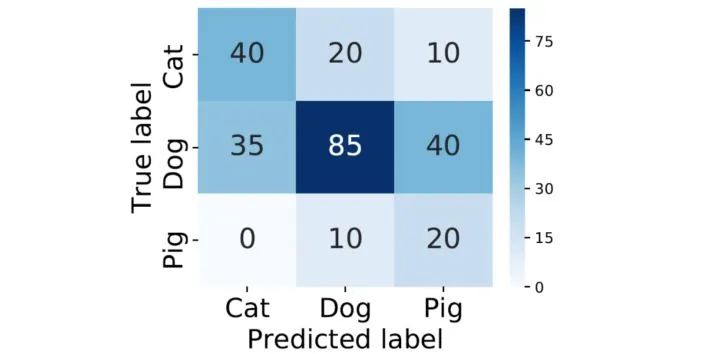
print('------Weighted------')
print('Weighted precision', precision_score(y_true, y_pred, average='weighted'))
print('Weighted recall', recall_score(y_true, y_pred, average='weighted'))
print('Weighted f1-score', f1_score(y_true, y_pred, average='weighted'))
print('------Macro------')
print('Macro precision', precision_score(y_true, y_pred, average='macro'))
print('Macro recall', recall_score(y_true, y_pred, average='macro'))
print('Macro f1-score', f1_score(y_true, y_pred, average='macro'))
print('------Micro------')
print('Micro precision', precision_score(y_true, y_pred, average='micro'))
print('Micro recall', recall_score(y_true, y_pred, average='micro'))
print('Micro f1-score', f1_score(y_true, y_pred, average='micro'))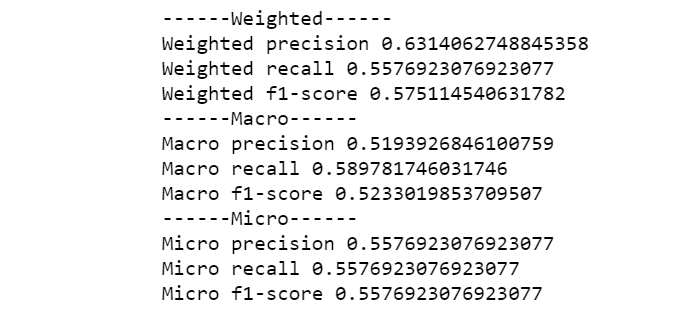
-
4 Things You Need to Know about AI: Accuracy, Precision, Recall and F1 scores -
Multi-Class Metrics Made Simple, Part I: Precision and Recall -
Accuracy, Precision and Recall: Multi-class Performance Metrics for Supervised Learning


登录查看更多
相关内容

Arxiv
17+阅读 · 2020年6月2日
Arxiv
4+阅读 · 2018年7月4日


相关VIP内容
相关资讯
相关论文
Arxiv
17+阅读 · 2020年6月2日
Arxiv
4+阅读 · 2018年7月4日