解密蚂蚁金服MISA:37℃的自助语音交互是怎么做到的?
什么是IVR
IVR(interactive voice response)即互动式语音应答,由PC机(或工控机)、电话接口卡、语音板(语音处理卡)和传真卡组成。通过IVR系统,客户可以利用音频按键电话或语音输入信息,通过录音导航从该系统中获得预先录制的数字、语音或合成语音信息。IVR作为呼叫中心的门户,被赋予如下几种重要功能:
缓解服务压力:为简单、适合人机对话的业务提供自助方式办理,同时也大大降低日益增加的人力成本。
拓展服务空间:可以为客户提供7X24全天候不间断的服务。
提升服务质量:初步甄别客户的需求,精准派单,为找到最合适的客服专员来服务用户提供依据,保障用户的问题能够得到有效、快速的解决。
加快服务进程:协助获取用户的诉求,为人工服务提供有效的信息,加快服务进程,让用户享受到极致的服务体验。
目前,IVR系统已被广泛应用于客服、催缴、订票订餐、购物、节日问候、回访、查询修改激活等场景,在金融保险、通信运营、政府事业、旅游服务、教育培训等行业发挥着重要作用。
传统互动式语音问答系统酷似迷宫,在各类提供语音服务的行业中不难听到一个非常庞大的IVR语音提示系统,如果不是经常拨打热线的老司机,真的很难找到自己想要的入口。
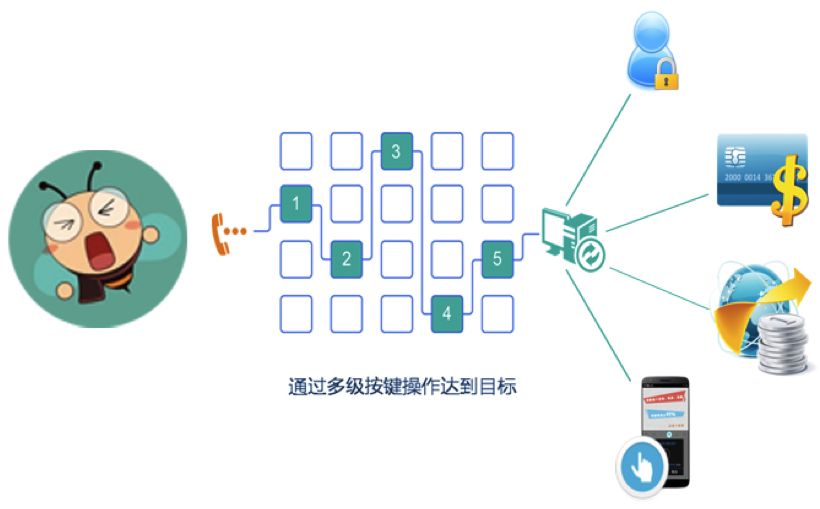
如上图所示,传统IVR有如下三个显著的体验问题:
菜单设置复杂,客户易迷失:经过层层按键,才有可能获取到解决方案或者人工服务,这还是建立在对业务逻辑能够分清楚、按键不出错的情况下,很难一蹴而就。
按键机械繁琐,等待时间长:用户需要听完按键提示,再操作按键,菜单层级复杂的话,需要如此反复好几次,整个求解过程没有个几分钟搞不定。
人工入口埋藏深,接听难:入口埋藏深,大家都司空见惯了,一般都是在按键提示的最后,才提供入口按键,最可怕的是,废了九牛二虎之力才找的人工入口,最后听到系统端的提示“现在人工坐席忙,继续等待请按1,返回上一层目录请按星号键”。
随着蚂蚁金服各项业务的蓬勃发展、业务线的日益增长,目前大大小小的业务多达100多个,传统的IVR菜单很难满足我们的需求。一方面我们很难将这么多业务合理地安置到0-9的按键中,即便运营有如此实力,大部分的用户也是蒙圈的(就跟现在95188热线让用户选择首层按键业务的时候,70%以上的人会选择“1-支付宝”),另一方面,层层按键能够覆盖的用户问题非常有限,面对如此复杂的业务结构以及业务咨询,按键菜单在解决能力上似乎举足无措。因此,从2015年起,我们就开启了智能化的IVR语音交互探索之路。
IVR智能语音交互
在自助语音服务系统(IVR)基础上,我们应用语音识别、机器学习和自然语言理解技术,构建了智能化、人性化、高效率的自助语音服务系统,今年3月初,我们正式取名为“MISA”(Machine Intelligence Service Assistant)。通过自然语言的沟通,用户以“说”代“按”,与直接的人工服务相似,非常具有人性化和亲切感,大大提升了服务体验;另一方面,能够更加快速响应用户的诉求、信息查询,实现问题的快速解决,使得用户可以充分享受自然语音作为交互界面的高效、便捷的服务。这样的交互方式不仅大大缩短了用户等待时间,也为企业有效降低了客户服务成本,大幅提升服务效率和服务质量。
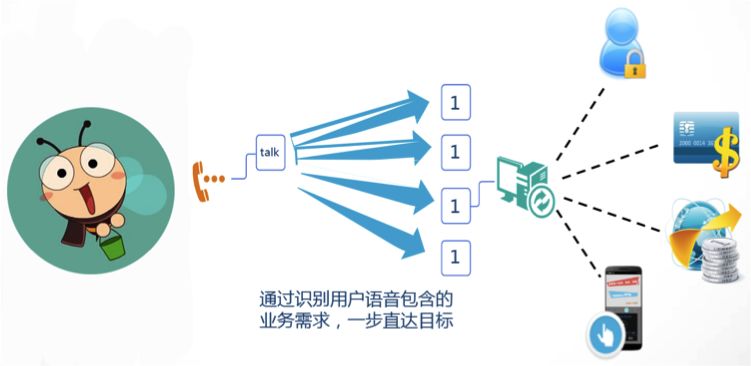
目前,MISA系统具备这样几个功能:
通过猜你问题、问题描述和识别、反问交互等方式,甄别用户问题,对于有信心能通过自助解决的问题,直接通过支付宝APP我的客服PUSH相应的解决方案。
对于自助解决能力不足的问题,根据识别结果,派单到最合适的技能组和人工,使问题得到快速解决。
在人工服务过程中,会将用户在IVR自助服务阶段描述的内容带到工作台,辅助客服小二快速定位问题,同时降低用户的求助成本,加强服务进程。
IVR交互引擎
为了实现IVR更加人性化的交互,技术上通过深度学习和自然语言理解技术,构建了IVR系统的交互引擎,以解决交互模式固定、模块功能固定等问题,实现更加自然、流畅、准确的语音交互。
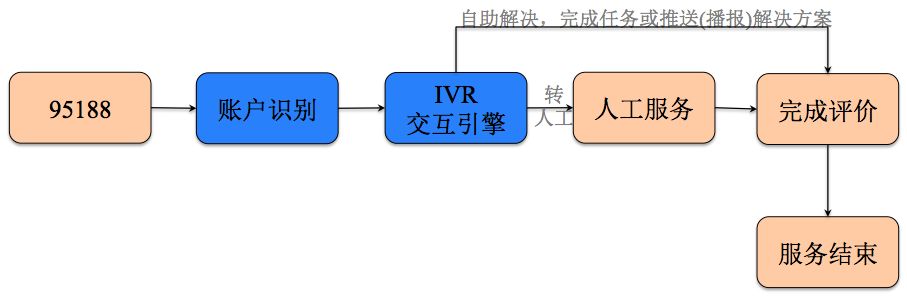
交互引擎作为IVR系统的核心组件,具备如下几个特点:
个性化:结合多次来电、多渠道求助信息做个性化的交互,根据用户状态可食用个性化的引导语。
智能化:根据用户描述,由算法结点自动判断模块调用(问题识别或反问交互)及结果优先级,在特定的情况下(比如咨询被盗被骗的问题、用户要求转人工或者沉默不愿意交互)会自动跳出交互。
精细化:对于用户的意图以及反馈实现精细化运营,交互过程控制进一步细化,根据交互时长、交互轮数和用户当前状态设置不同的交互流程。
配置化:所有交互过程都是动态配置且可以实时切流生效,引导语等相关内容业务也可以自定义配置并进行abtest。
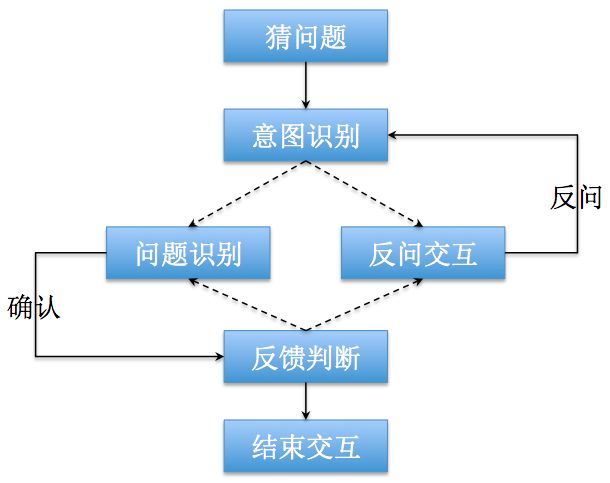
接下来,将从猜问题、问题识别、反问交互、自动化训练上线等几个方面来介绍我们在智能语音交互技术上的思考。
#猜问题
“欢迎致电蚂蚁金服。您好,请问您的问题是花呗如何还款,对吗?”
“对!对!我就是想问这个!”
这是支付宝客服热线95188一段真实的通话录音:用户还没有开口说话,智能客服系统就能够“未卜先知”,“猜”中问题,并准确给出相应的解决方案。这一技术在蚂蚁客服的业务上,称为“猜问题”,是蚂蚁金服在客服领域的首创,也是在人工渠道、热线场景的第一次实践,利用用户在支付宝APP或网页历史求助文本等信息及精准因子等,基于深度学习算法框架构建的问题识别模型。
以服务轨迹为例。为适用不同人群在不同场合下的求助需求,支付宝在产品设计上为用户准备了不同的求助渠道,如直接在产品页面可以访问的服务大厅、统一的自助服务入口我的客服、热线和在线的人工求助渠道,服务轨迹就是以相应求助渠道的标识和给用户提供解决方案的标准问题ID组合而成。
除此之外,我们还用到了用户的历史求助文本、精准因子等信息,尽可能精准定位用户问题。服务轨迹是时序的特征,历史求助文本是文本特征,精准因子是静态的特征,如何处理如此复杂且多样化的信息,着实让我们费了一番心事。为此,我们创造性的提出了混合网络结构,如下图所示:
通过Convolutional Neural Network和Long Short Term Memory来做文本的处理,尽可能充分的捕获历史求助文本中的信息;通过Long Short Term Memory来处理服务轨迹特征,可以较好的保留时序信息,提取有效的pattern;对因子进行离散化处理,通过Artificial Neural Network来处理因子特征,最后将各模型提取到的特征整合到一起,做整体的分类训练。相比于单个模型,该方法大幅度提升了猜问题的覆盖率和准确率。
#问题识别
对于没有猜中问题或者反馈猜问题错误的用户,我们会尝试让用户尽可能准确的用一句话描述一下他遇到的问题,对于用户的描述,我们能否准确的理解并定位,就取决于我们的自然语言理解能力了,这也是问题识别这个模块的主要工作。
为此,我们构建了问题识别“子模型+融合模型”的框架,如下图所示:
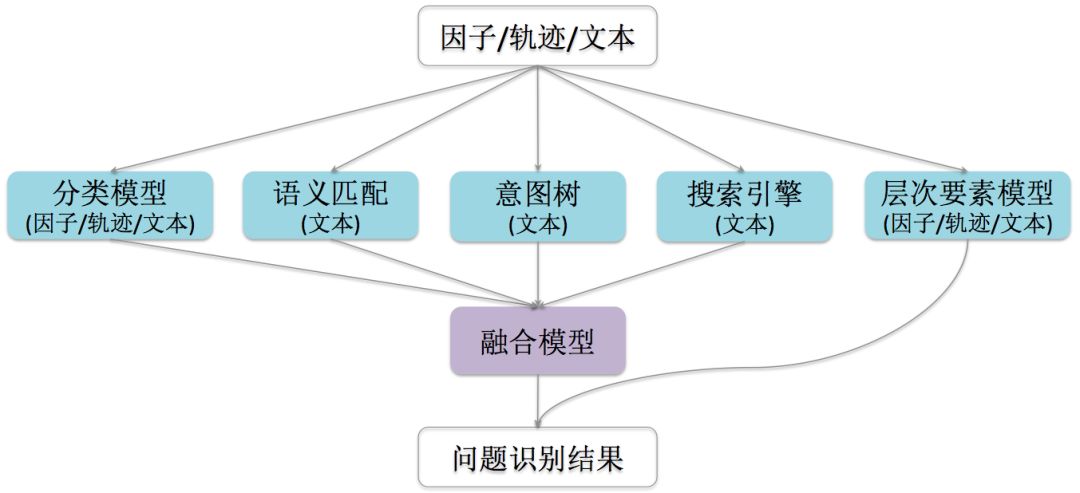
其中,分类模型使用了用户服务轨迹等、用户描述文本和精准因子特征,通过混合网络来构建模型;语义匹配集中在对用户描述文本的分析,通过word average model的方法进行纯文本的匹配;意图树方法,则是为了更加精准的识别用户意图,通过对用户问题进行树状的分析和匹配,来实现精准定位;搜索引擎更多的是作为一个兜底方案,对知识库进行内容检索;层次要素模型是基于我们构建的语义要素库,可以实现zero-shot的问题识别,下一小节会重点介绍。最终,我们会通过一个GBDT的模型,对前四个模型的结果进行融合,因层次要素模型的精准性和特殊性,可以直接参与到结果输出。
#反问交互
对于一个语音交互系统,如果不具备多轮对话的能力,那么就像人类失去了大脑、飞机失去了引擎,跟智能也就几乎搭不上边了。在任务型的对话中,我们非常容易理解并实现多轮会话,以订机票为例,需要的信息非常明确:时间、始发地和到达地,对话过程中,对于未知的信息直接按顺序提问即可,提问的内容和句式可以是固定不变的。但客服场景却大不相同,用户只有问题没有意图,所以也无法定出需要填充的slot。对于用户描述不完整或表述不清楚,除了能问“您是遇到了XXX什么问题”(XXX一般是某个业务或者产品名),似乎就没有别的招儿了。另外,在语音交互的场景下,业务上做过一次问卷调查,超过3轮以上的交互会给用户非常糟糕的体验,解决率等指标也会直线下降,因此,对于IVR来说,一个非常大的挑战就是如何设计不要超过3轮的个性化交互形态。
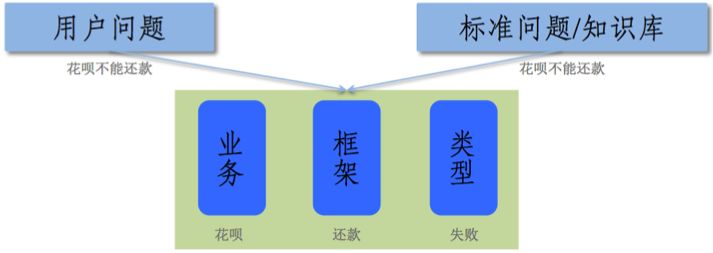
非常幸运的是,我们发现很多的知识点或用户问题都可以直接拆解成三个要素的形态,类似于常说的主谓宾,在我们这里,三要素分别是:业务、框架和问题类型。业务,顾名思义,就是支付宝的一系列业务类别,如花呗、借呗、余额宝等;框架,相比而言有点抽象,一般我们认为一句话或者一个问题的核心动词为框架,如支付、还款、修改等;问题类型,即用户提问的诉求,作为业务和框架的修饰部分,如失败(问原因的)、怎么(问操作方法的)、什么时候(问时间的)。一般情况下,我们认为绝大多数业务知识点或者用户问题,都可以拆解成这样的三要素。下图以“花呗不能还款”为例,对三要素进行了拆解。
以要素库为纽带,我们可以更加方便的做如下几件事情:
问题识别:当识别的一个或多个要素可以唯一确定某一个标问的时候,可以直接推出标准问题识别的结果,需要特别说明的是,这样的问题识别就具备了zero-shot的能力(即便是以前没有见过的问题,在该框架下也有可能识别到)。
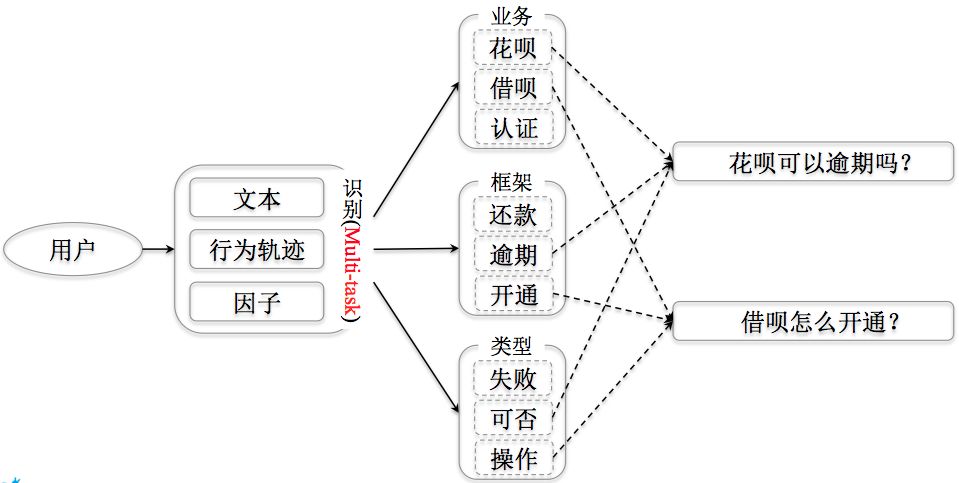
个性化反问:借助识别的要素以及其他要素的识别概率,结合反问模版,可以自动生成个性化的反问问句,尽可能降低用户交互的难度,如下图所示。
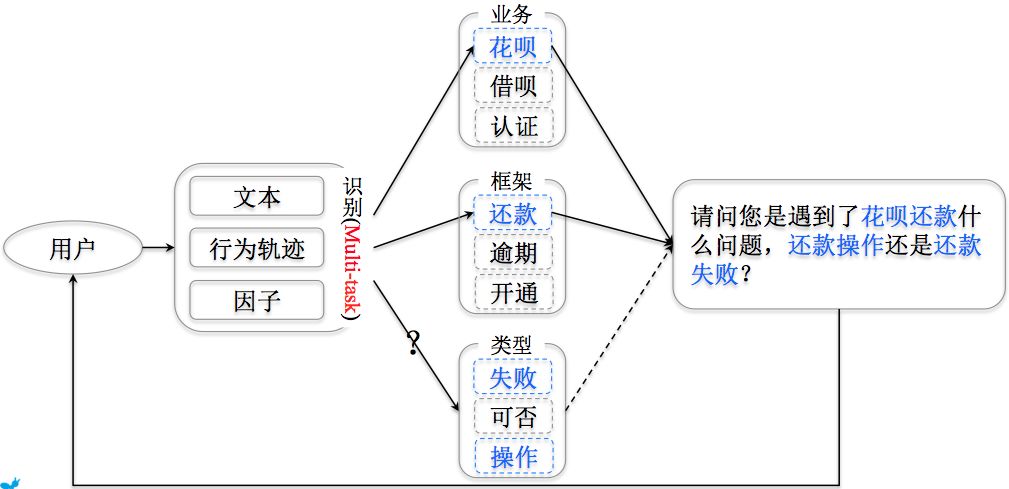
辅助问题识别:识别的一个或多个要素,可以帮助问题识别模块圈定范围,降低问题识别的难度。
在三要素识别阶段,我们同样利用了用户的服务轨迹、因子和文本等信息,基于混合网络结构,构建了Multi-task的学习任务,相比单模型,识别准确率可以提升7个百分点。
#自动化训练上线
考虑到业务和产品的快速变化、产品线比较频繁的运营活动,用户咨询问题的业务范围和问题分布会发生较剧烈的变化,另一方面,用户相关的特征(包括服务轨迹和精准因子等)也在发生着较剧烈的变化。为了保障算法的时效性,及时获取热线用户特征和咨询业务分布变化,我们与内部的核能、armor等平台结合,复用核能平台的特征处理、模型计算、abtest和自动切换上线能力,通过armor进行gpu训练资源的调度,确保进行每天的模型迭代更新,从而保障了多个模型效果的稳定性。
总结
最后,不妨看一段线上用户跟MISA系统的真实对话记录:
-misa: “您好,为给您提供自助或人工服务,请简单描述一下您的问题,请讲”
-user: “蚂蚁借呗信用度不够”
-misa: “请问是借呗的哪方面问题,是申请的问题吗?”
-user: “就是没法借钱”
-misa: “您是想咨询蚂蚁借呗不能借款,对吗?”
-user: “对”
面对今年双十一业务的高速增长,MISA系统经受住考验,并出色完成了IVR热线服务的任务。相比去年双十一,账户识别在覆盖上提升16.6个百分点、准确率提升6.4个百分点;问题识别覆盖提升30.1个百分点、准确率提升15.2个百分点;猜问题作为今年的新建能力,覆盖大盘42.7%的话务,CTR63.5%,准确率84%。
— END —