人物 | 如何打造家用机器人:伯克利大牛Pieter Abbeel的故事
机器之心发布
来源:AI Frontier
第三届美国硅谷顶级人工智能前沿大会(AI Frontiers Conference) 将于 2018 年 11 月 9-11 日在美国硅谷最高级别会议中心圣何塞会展中心盛大举行。美国 AI 界领军人物悉数出席。机器之心专属折扣码:P25SYNC。

许多人都希望有这样一个机器人:能做饭、打扫房间、铺床、扔垃圾以及把洗好的衣服都折叠起来。绝大多数人只是在空想,但 Pieter Abbeel 是真的将这项任务视作他一生的目标。
这位加州大学伯克利分校的教授在 2002 年还是斯坦福大学的研究生时,加入了吴恩达的小组,并开始了这项任务。当时他的研究对象还完全不是机器人,而是自动驾驶汽车和直升机。
2004 年,Abbeel 发表了论文《Apprenticeship Learning via Inverse Reinforcement Learning》。他提出了一种通过观察执行任务的专家来训练机器人的新方法。他在模拟自动驾驶汽车时展示了这种方法的可行性。该论文后来被认为是他生涯中最重要的论文之一。
之后,他将学徒学习应用于直升机控制。Abbeel 和他的同学 AdamCoates 以及导师吴恩达一起成功地训练了一架直升飞机,使之能在没有人工监督的情况下进行航展。
Abbeel 在获得博士学位后成为加州大学伯克利分校的助理教授。在接下来的 10 年里,他就全身心投入他一直以来的梦想:研造家用机器人。
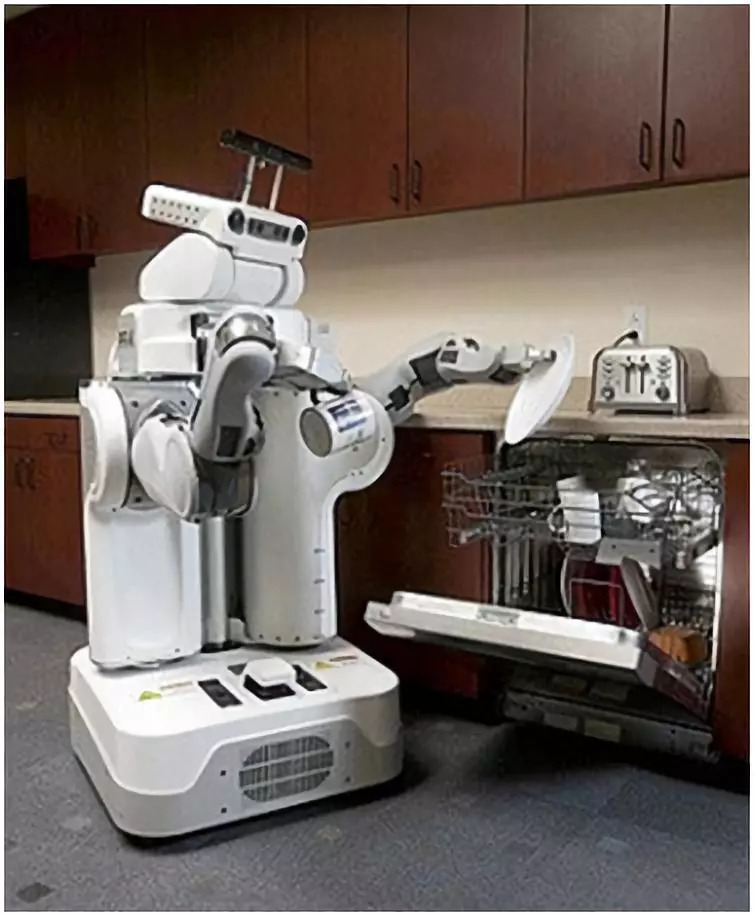
一个家庭机器人应该「多才多艺」才能够应付各种各样的家务事。你肯定不会想要 5 种不同的机器人:一个做饭,一个洗衣,一个洗碗,诸如此类。即使你的房子足够大到可以容纳 5 个专业机器人,你也可能会需要机器人做其他事情:把地板上的衣服捡起来,为你倒一杯咖啡,打开窗户等等。
那我们如何才能建造全能机器人?如今的机器人专心完成一项任务都算得上是勉强。比如一个机器人需要花费数小时的训练才能学会将手臂朝正确的方向移动来拿起一个杯子。
这种困难并不能阻止 Abbeel 朝他的梦想进发。他的第一个想法是利用「模仿」。一个人完成任务,然后机器人重复它。这样可以节省培训时间,也许可以让机器人完成额外的工作。

2010 年,Abbeel 创建了 BRETT(全称「消除繁琐任务的伯克利机器人」),这个一个改造自 Willow Garage PR2 的机器人,配备相机和手柄。根据一系列基于规则的指示,BRETT 成为第一个可以折叠成堆毛巾的机器人。通过这样做,Abbeel 证明了家用机器人的硬件问题可以解决。
然后他把注意力转向了软件问题。机器人如何学会去进行一个任务?机器人如何学习做多个工作?
强化学习
Abbeel 一直被强化学习(RL)所吸引,这是一种机器学习方法,教导代理人通过奖励和惩罚来做正确的行动。这种学习方法假定代理与其环境交互,从而为机器人的行为提供反馈。
一个简单的例子是经典的老虎机问题:不同的老虎机为你提供不同的收益。你很快就学会了:拉动摇杆来获得最高的回报。这被称为多臂强盗问题。一个更复杂的例子是玩视频游戏。通过尝试不同的动作,如射击和躲闪,你可以获得不同的分数,并学会更好地玩游戏。
强化学习对于训练机器人很有效,因为机器人需要通过移动,抓取,折叠或做其他动作来与世界互动。如果机器人收到奖励,它可以更频繁或更正确地执行该操作。
Abbeel 在他的大多数研究中都用到强化学习。以 BRETT 为例,它的车载摄像头可以精确定位前方的物体,以及自己的手臂和把手的位置。通过反复试验,它学会调整锤子的位置,并将角度调到正确的位置来拔出钉子。
深度强化学习
强化学习的缺点是环境复杂。为了描述任务、房间或游戏,我们必须列举所有位置、所有不同角度和不同情况。如果我们将每个独特的情况称为一个状态,那么对于一个简单的任务,状态的数量将为数千或数万。
机器人如何快速总结当前状态并快速地学习?深度学习是一个最好的解决方案、深度学习于 2012 年开始流行,当时它被证明可以有效地对「猫」(ICML 2012 中展示)和 AlexNet 论文(在 NIPS 2012 中展示)中的图像进行分类。深度学习采用原始图像像素并将它们概括为几个类。因此,它使我们无需手动识别图片或环境中的重要「特征」。
因此,将深度学习应用于与其环境相互作用的机器人是很自然的。这里深度学习用于总结不同的状态。机器人仍然可以使用强化学习来决定动作。
2013 年,通过将深度学习与强化学习相结合,机器人可以玩 Atari 游戏了,并在 2016 年与人类围棋高手一起对抗。深度强化学习领域就这样诞生了。
Abbeel 的贡献是他首先将深度强化学习应用在机器人身上。他非常热衷于此,并在 NIPS 2016 上通过提供了一个叫 DeepReinforcement Learning through Policy Optimization 的教程。它仍然是最受欢迎的深度强化学习教程之一。
虽然深度强化学习教会机器人很好地完成任务,但它并不能衍生为多个任务。换句话说,机器人学会做五秒钟的动作。但是,一个花费五秒钟的技能和一个话费一天时间的技能非常不同,这是一个机器人在房子里漫游,执行不同的家务所需要的。这是元学习是必要的。
元学习:推广学习新任务
元学习是从多个任务中学习并将学习应用于新任务。它也被称为「如何学习学习」。
在 2017 年的 NIPS 大会中,Abbeel 和 OpenAI 和加州大学伯克利分校的研究人员通过元学习提出了 One-Shot Visual Imitation Learning viaMeta-Learning,该学习将元学习与一次性学习相结合,该系统只需要观察 1 个演示,然后就可以为新任务产生正确的动作。
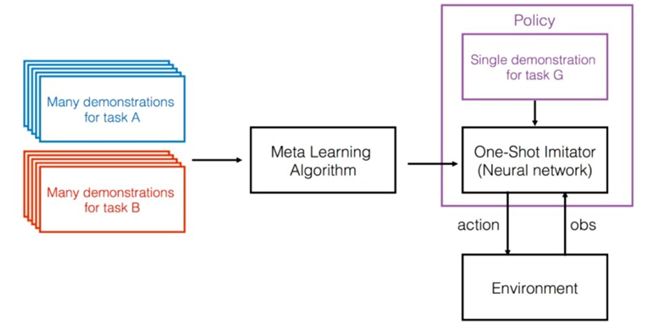
Abbeel 和他的团队进一步发明了 Simple Neural Attentive Learner(SNAIL)并在 ICLR2018 做了论文展示中。这是一个在单个深度神经网络中实现的元学习者。该网络将序列与序列学习与软关注相结合,使机器人能够记住不同任务的背景。
其他研究活动
作为一名加州大学伯克利分校的教授,PieterAbbeel 享有最顶尖的人才资源,许多有才华和勤奋的研究生和他一起合作。如今,他正在指导 25 名博士和博士后。以及 25 名本科生。以下是他的团队正在研究的其他研究。
终身学习
机器人需要不断适应不同的任务和不同的情况。终身学习是连续应用元学习并进行泛化的一项技术。在两个蜘蛛机器人相互战斗的实验中,研究员表明连续自适应机器人最终获胜。这篇论文一作是 CMU 的 MaruanAl-Shedivat,并且与 Abbeel 所属的 OpenAI 研究员共同完成。
利用模拟训练机器人
学习过去的经验
这个方法被称为 Hindsight Experience Reply(HER)。我们可以将奖励传播回过去的所有操作,并创建重播,而不是等到机器达到最终目标才更新模型。在重播中,每个中间奖励被视为最终奖励。因此,我们可以在每个中间步骤(状态)中更新学习功能并更快地学习。这减少了学习所需的数据。
Pieter Abbeel 正在实现他梦想的道路上:创造一个真正的家用机器人。也许在不远的将来,家里的机器人会把吃剩的盘子端走,为你做饭。当你表示赞赏时,机器人摇摇头微笑,「不需要感谢我。我只是 Pieter Abbeel 的学徒。」
Pieter Abbeel 将在 2018 年 11 月 9 日于加州圣何塞举办的 AI Frontiers 大会的视频理解单元上发言。

AI Frontiers 大会演讲嘉宾
AI Frontiers 大会汇集了人工智能界最顶尖的思想领袖,将为参会者展示最前沿的研究和产品。今年,AI Frontiers 大会的发言人包括:OpenAI 创始人 Ilya Sutskever,Google AI 副总裁 Jay Yagnik,创新工场的首席执行官李开复,iRobot 高级副总裁 Mario Munich,Google Brain 研究员 Quoc Le,加州大学伯克利分校教授 Pieter Abbeel 等。
点击「阅读原文」,查看大会官网信息。机器之心读者限时特别优惠折扣码:P25SYNC






