基于深度模型的人脸对齐和姿态标准化

美好世界
Wonderful world

相隔41天,Edison又回来了,由于自己和团队的事情比较多,没有在我们的“计算机视觉战队”平台花费过多的精力,今天我来和大家分享一些人脸的故事。之前接触了一些人脸领域的知识,现在人脸相关的技术无处不在(例如机场的认证合一,人脸支付等技术),在这先和大家说一点生活中观察的一些事——记得2月中旬在哈尔滨机场,进行安检的时候,我特意观察了机场人脸检测的系统,令我震惊不已,因为我看到的是检测效果差,Bounding Box的位置若你观察后你会发现Recall一定很差,但是,重点来了,他能把人脸特征提取和身份证比对,一般都通过,是不是很神奇。如果有兴趣的朋友,可以下次过这种认证合一的时候,仔细观察一番,你如果有一点的硬件设备和软实力,也是可以做到一样乃至更好的效果。
今天的小故事将完了,开始说说大故事,也就是今天所要说的人脸对齐及人脸姿势标准化,希望有兴趣的您继续阅读下去,谢谢!
1
历史
ORL, Extended Yale B: 1990~2012 (<50 persons)
nIdentification rate: 95%~99% (SRC and variants [J.Wright et al, 2008])
FERET: 1994~2010 (1196 persons, 2~5 ipp)
nIdentification rate: 94% (for Dup.I and Dup.II) (LGBP + B-LDA [S.Xie, S.Shan, X.Chen, IEEE T IP10])
FRGC v2.0: 2004~2012 (~500 subjects, >50ipp)
nVerification Rate (VR) = 96.1% @ FAR=0.1% (LPQ + LGBP + B-LDA [Y.Li, S.Shan, H.Zhang, S.Lao, X.Chen, ACCV12])
LFW: 2007~currently (~5749 subjects, 1680>2 ipp)
nVR=94.5% @FAR=1% [Unrestricted, Labeled Outside Data] (DeepID [Y. Sun, X. Wang, and X. Tang, CVPR14])
nVR=87.0% @FAR=0.1% [Unrestricted, Labeled Outside Data](DeepFace [Y.Taigman, M. Yang, M.Ranzato, L. Wolf, CVPR14])
2
EmotioW 2014 challenge

任务:
将示例音频 - 视频片段分类为七个类别之一(中立,愤怒,厌恶,恐惧,快乐,伤心,惊喜);
挑战:
接近现实世界的条件(大变化 头部姿势,照度,部分遮挡等)。
有挑战性的数据——AFEW * 4.0数据库
从显示接近真实世界的电影中收集的音频视频剪辑
方法:
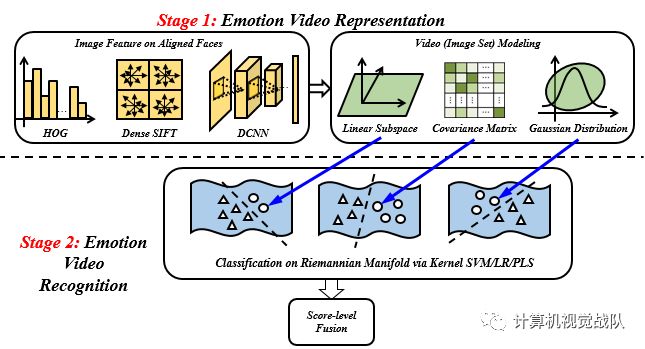
n图像特征
对齐的人脸图像: 64x64;
特征: HOG, dense SIFT, DCNN.
nDCNN
CaffeNet在CFW数据集上进行训练
Trained over 150,000 face imagesfrom 1520 subjects;
Identitiesare served as supervised label in the deep networks.
架构
3@237x237 >96@57x57 > 96@28x28 > 256@28x28 > 384@14x14 > 256@14x14 > 256@7x7 > 4096 > 1520
最后卷积层的输出作为最终图像特征:256x7x7=12,544
nHOG
Block size: 16x16; stride: 8; # ofblocks: 7x7=49
# of cells per block: 2x2; # ofbins: 9; # of total dims: 2x2x9x49=1764
nDense SIFT
Block size: 16x16; stride: 8; # ofpoints: 7x7=49
# of dims per point: 4x4x8=128; #of total dims: 128x49=6272
结果:
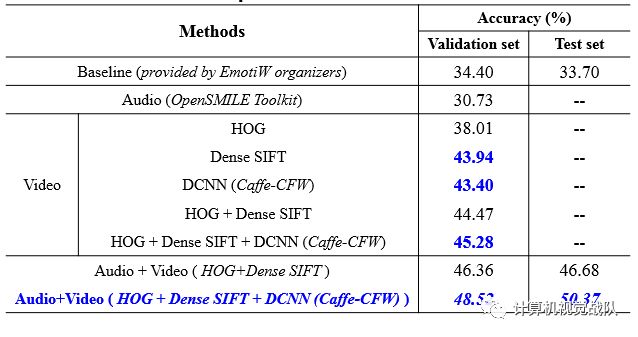
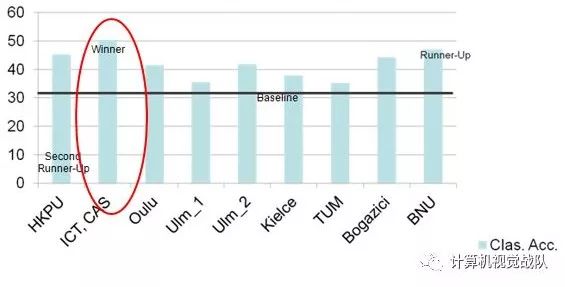
比赛最终结果:
HERML
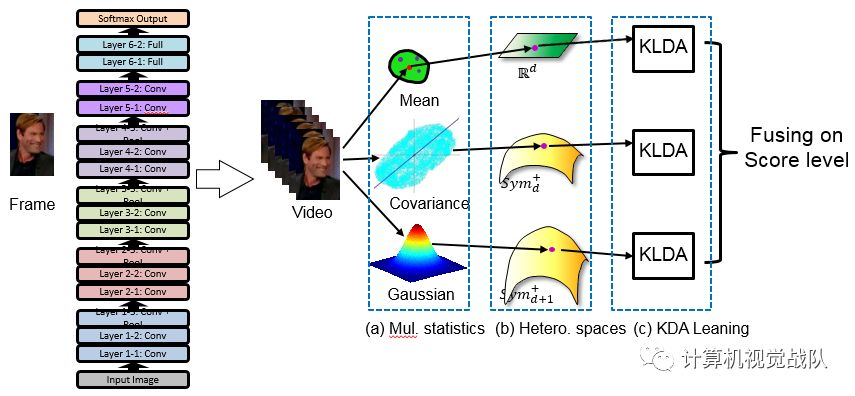
该实验证明了深度越深,效果越好(但是深到一个阈值界限,应该是有所下降或稳定)
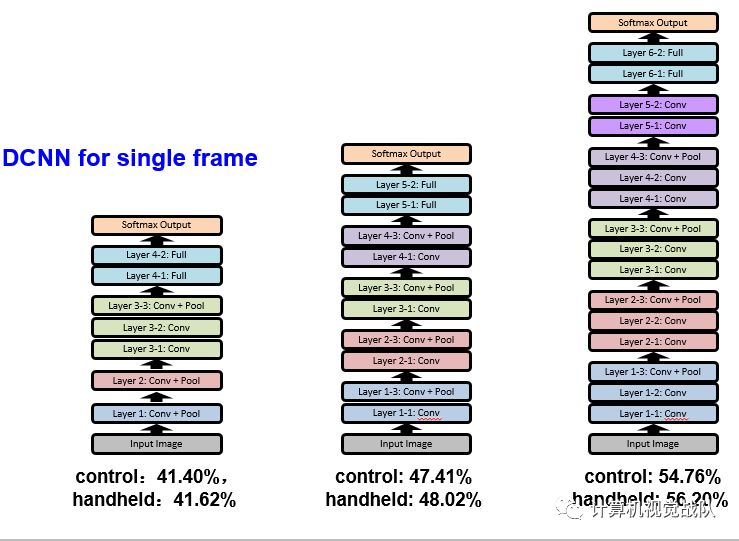
但是DCNN+ HERML (set models)效果更好

现在开始说说人脸对齐的知识:
3
Deep learning for nonlinear regression
Coarse-to-FineAuto-Encoder Networks (CFAN)
人脸对齐:从检测到的脸部预测面部标志
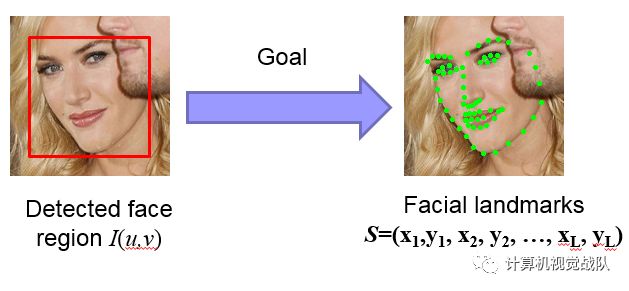
难度:就是一个复杂的非线性映射;
影响因素:大的外观和形状变化(头部姿势、表情、照明、部分遮挡)
动机
n直接应用Stacked Auto-Encoder(SAE)?
可以,但是不是很好,原因:
Easily overfit to small data:
Typically only thousands of images with landmark annotations
nNew ideas – exploiting priors
Features are partially handcrafted
SIFT, shape-indexed
Better initialization
Coarse to fine
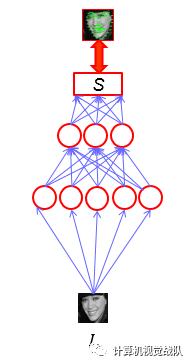
网络框架如下:
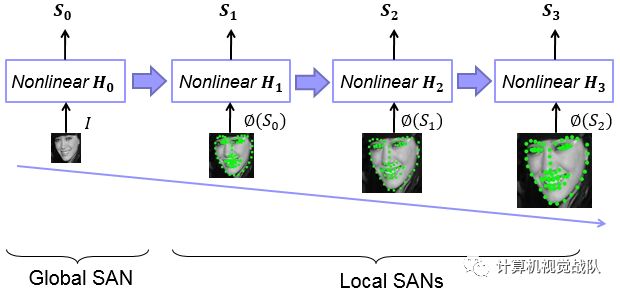
Pipeline
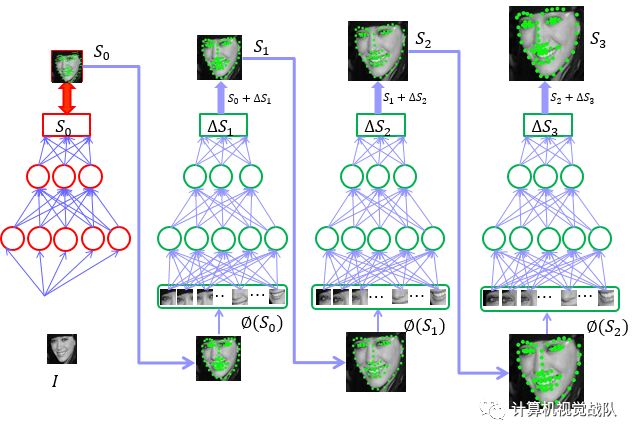
有兴趣的朋友可以去阅读原文(J. Zhang, S. Shan,M. Kan, X. Chen. Coarse-to-FineAuto-Encoder Networks (CFAN) for Real-Time Face Alignment.ECCV2014 (oral))
nGlobal SAN

nLocal SAN
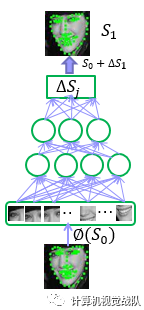

nCoarse-to-fine Cascade
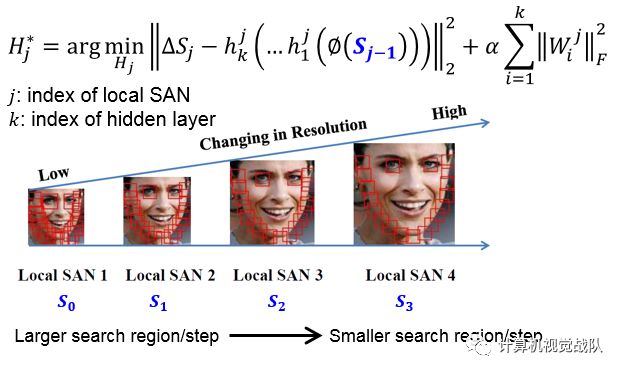
实验结果展示:

今天先讲到这里,下次给大家讲解“StackedProgressive Auto-Encoders (SPAE) for face recognition across pose”。




