学界 | UC Berkeley新研究:通过深度学习建模注意点采样阵列
选自BAIR
作者:Brian Cheung
机器之心编译
参与:黄小天、蒋思源、路雪
近日,加州大学伯克利分校(UC Berkeley)在研究中尝试使用深度学习计算模型解释生物学中观察到的自然特征,在建模灵长类动物视网膜的注意点采样点阵的基础上,这些结果可引领主动视觉系统前端的新型设计方式的未来思考,并希望这种学科之间的良性循环仍会持续。
我们为什么需要注意力
我们通过眼睛观察到的只是世界的很小一部分,双眼只能采样周遭光场的少许片段,即使在这些片段中,大多数分辨力都是专注于神经节细胞(ganglion cell)浓度最高的注视中心。这些细胞负责把视网膜上的图像从眼睛传递到大脑。神经节细胞的空间分布高度不均匀。结果,我们的大脑接收到一个「注视点」(foveated)图像。

一张注视中心分别为蜜蜂(左)和蝴蝶(右)的注视点图像。
尽管这些细胞只覆盖了一部分视野,但是大约 30% 的大脑皮层会处理其提供的信号。如果大脑集中注意力处理整个视野,则体积会大到不切实际。可以说,专注于视觉的神经处理的数量相当大,如果被有效利用将有助于生存。
注意力是很多智能系统的基本属性。由于物理系统的资源有限,有效分配就变得很重要。注意力涉及到动态地分配信息处理资源从而最优地完成一个具体任务。在自然中,这种设计在动物视觉系统中十分常见。通过在场景中快速移动注视点,有限的神经资源高效地散布在整个视觉场景内。
外显注意力(Overt Attention)
这项工作中,我们研究了涉及感知器官清晰运动的外显注意力机制,下图中这只处于青春期的跳跃蜘蛛是它的一个实例:

一只使用外显注意力正在跳跃的蜘蛛。
我们可以看到这只蜘蛛通过认真审慎地移动身体来处理所处环境的不同部分。如果你盯着它半透明的头部时,甚至可以看到蜘蛛的眼动轨迹与人类眼动类似。这些眼动叫作 saccades。
本研究中,我们构建了一个模型视觉系统,该系统扫视整个场景以寻找和识别目标,它允许我们通过探索优化性能的设计参数来研究注意力系统的特性。视觉神经科学感兴趣的一个参数是视网膜采样点阵,它定义了人眼中神经节细胞阵列的相关位置。
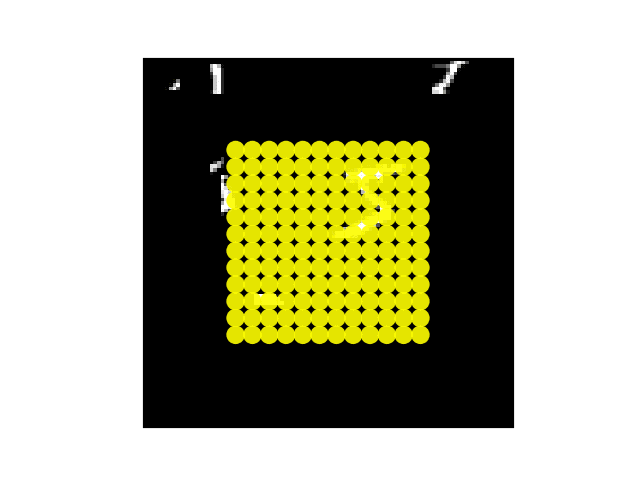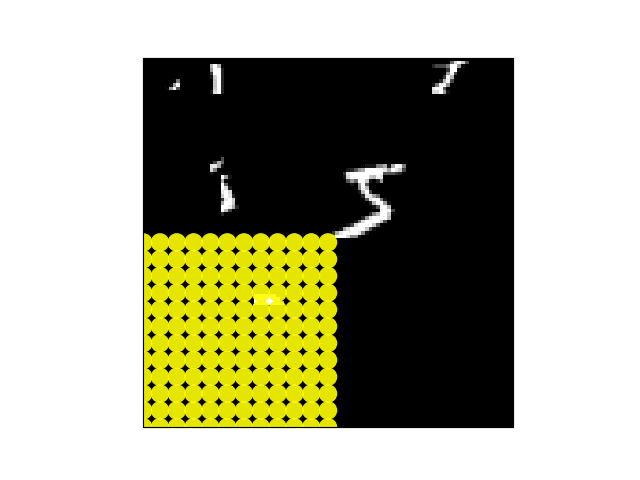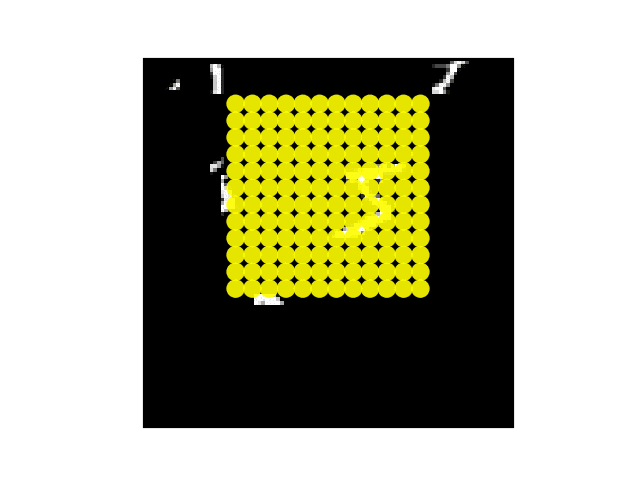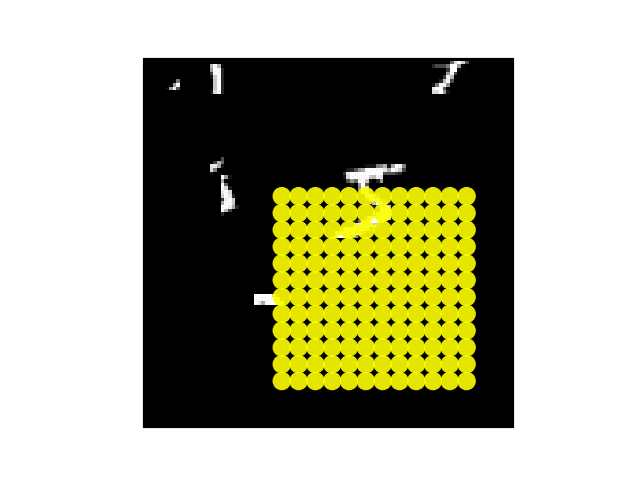
注意单个场景不同部分的模型视网膜采样点阵。
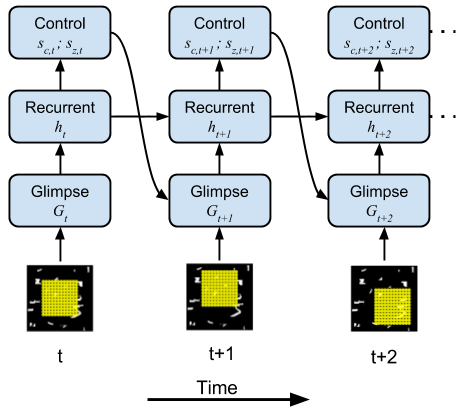
控制注意力窗口的神经网络模型。
通过梯度下降逼近进化
大概是出于进化的压力,大自然调整了灵长类动物视网膜中的采样阵列,因此我们的视力在搜索物体时体现出十分优秀的属性。为了代替这种模拟演化,我们利用一个更高效的随机梯度下降过程而构建一个处处可微的动态注意力模型。
目前大多数神经网络有可学习的特征提取器构成,而这些特征提取器可以将固定的输入转化为如类别那样更加抽象的表征。在训练过程中模型能续能学到内部特征,即权重矩阵和卷积核等,而保持输入的几何属性仍然不变。我们扩展了深度学习框架以创造可学习的结构特征。此外,我们还学习了神经视网膜采样阵列的几何形状。
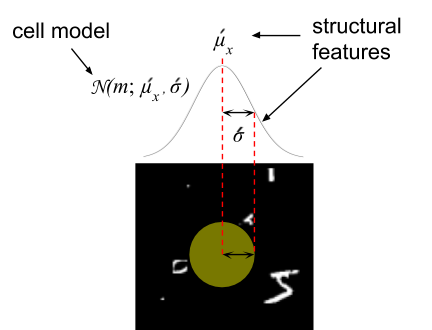
采样阵列中一个单元的结构化特征
我们模型的视网膜采样阵列是通过反向传播学习的,它就如同神经网络中调整权重的方式,我们调整视网膜并列式感知的参数以优化损失函数。我们初始化视网膜采样阵列为标准的正方形表格,然后使用梯度下降更新这种排列的参数。
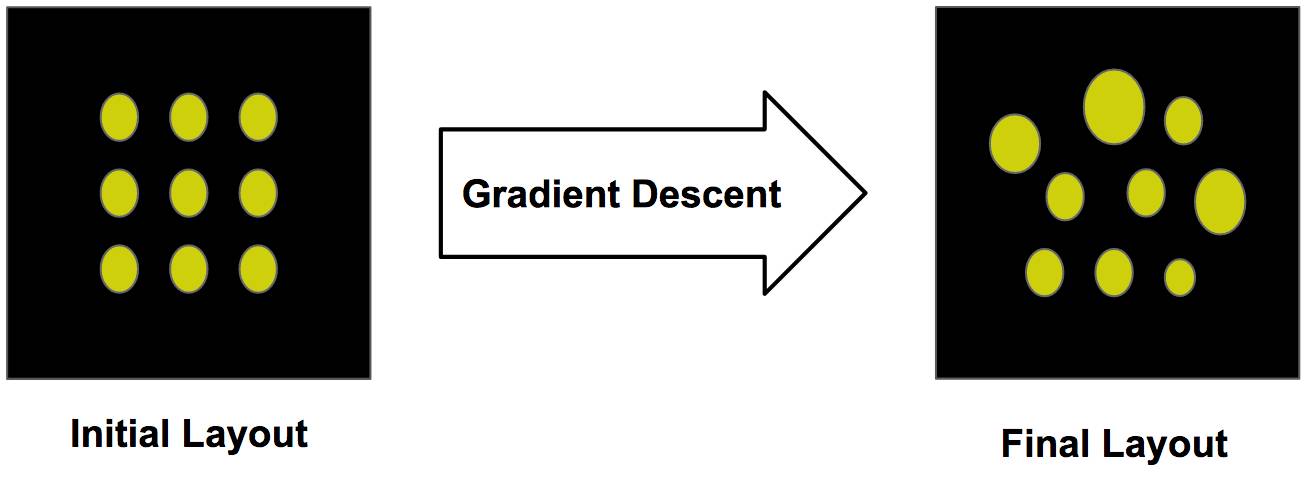
从初始化阵列使用梯度下降学习结构化特征
随着时间的推移,这种排列将会收敛到局部最优的配置以最小化任务损失。本案例中,我们在更大的视觉场景分类 MNIST 手写数字。以下展示了训练期间视网膜排列是如何变化的:
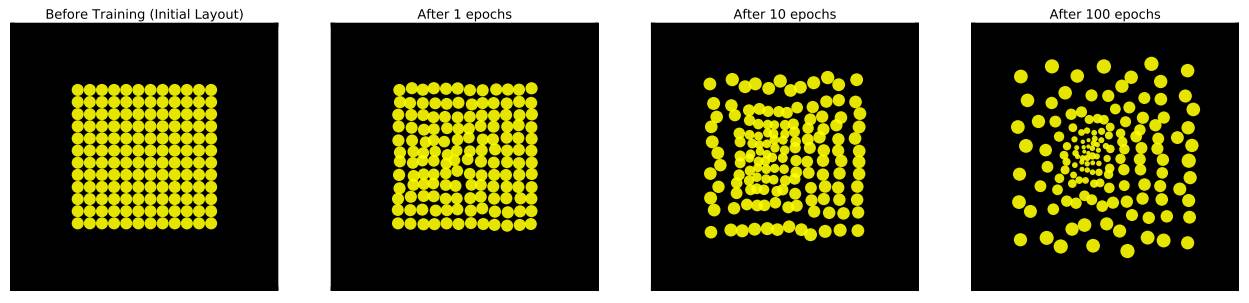
初始化后分别训练 1、10、100 个 epoch 所产生的视网膜采样点阵变化情况。
令人惊奇的是,每个单元都以非常结构化的形式变化,从均匀的网格转化为一个离心的独立性点阵。我们注意到高度敏感的单元集中在采样阵列的中心。此外,每个单元都会扩散它们独立的中心以创造能覆盖整张图片的采样点阵。
控制注意点的出现
因为我们的模型是通过电脑模拟,所以我们能赋予它自然界找不到的属性以观察是否还有其它的点阵排列模式出现。例如,我们可以重新缩放整个采样点阵以覆盖更小或更大的区域,这可以赋予模型放大或缩小图像的能力。

视网膜采样点阵同样有能力重新缩放自身
我们在下面展示了所学到的不同视网膜点阵布局。为了比较,左图展示了模型不具备缩放功能的视网膜点阵布局,而右图展示了能够缩放的视网膜点阵布局。

(左)只能变换的模型视网膜点阵;(右)既能变换又能缩放的模型视网膜点阵。
当注意力模型能够缩放时,就会出现一个不同的布局。注意:视网膜神经节细胞中的多样性较少。这些细胞保留很多初始特性。为了更好地利用学得的视网膜布局,我们对比了具备固定(不可学习)点阵、可学习点阵(不能缩放)和可学习、能够缩放点阵的视网膜的性能。
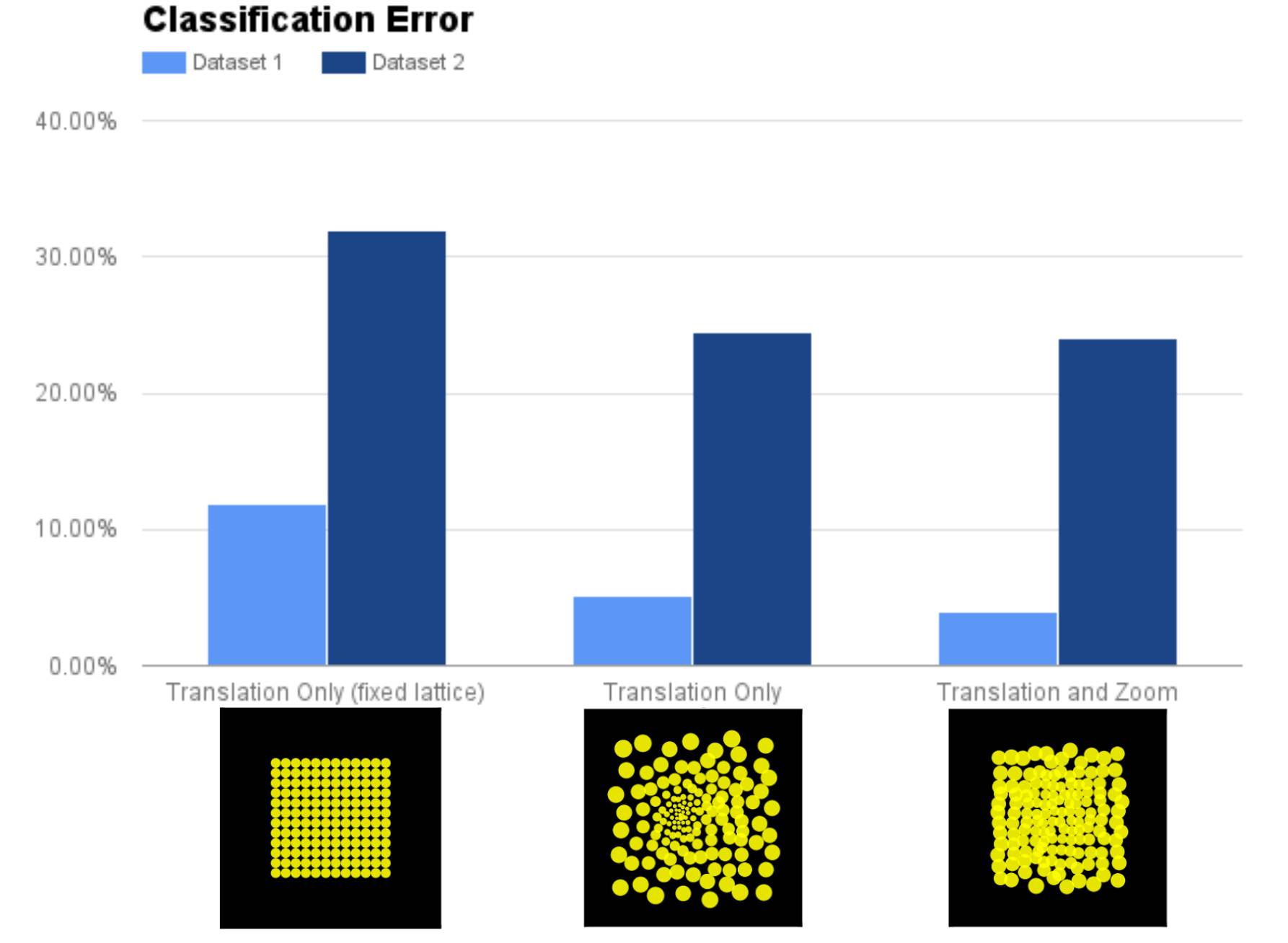
模型在 Cluttered MNIST 数据集的两种版本(数据集 1 和数据集 2)上的性能。数据集 2 包含可随机改变大小的 MNIST 数字,因此数据集 2 比数据集 1 难度更高。
或许结果不会让人惊讶,缩放/可学习的点阵显著优于只能变换的固定点阵。但是,有趣的是,仅具备变换能力的可学习点阵的性能和具备变换能力还能缩放的点阵性能一致。这进一步证明缩放和灵长类动物视网膜的注意点布局的功能是一致的。
注意力的可解释性
早些时候,我们介绍了注意力高效利用有限资源的能力。注意力还能够帮助我们从内部理解构建的复杂系统如何运转。当我们的视觉模型在处理过程中注意图像的特定部分时,我们能够了解该模型运用哪一部分来执行任务。在我们的案例中,该模型通过学习将注意点放置在数字上来解决识别任务,这说明注意力能够帮助分类数字。我们还看到最下方模型利用其缩放能力来识别数字。
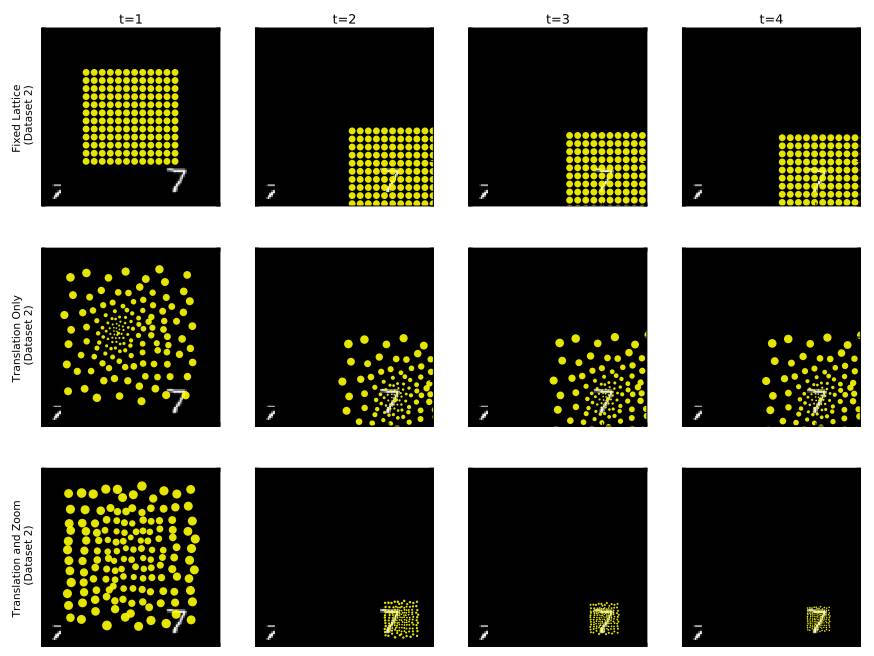
我们的模型随着时间的注意力移动。固定点阵的模型(上),学得的点阵(中),学得的具备缩放能力的点阵(下)。
结论
通常,我们从生物学中寻找灵感来构建机器学习模型。Hubel 和 Wiesel 的研究启发了神经认知机(Neocognitron)模型的出现,该模型又反过来促进卷积神经网络的发展。在该研究中,我们选择了另一个方向,尝试使用深度学习计算模型解释生物学中观察到的自然特征。未来,这些结果可能会引领我们思考主动视觉(active vision)系统前端的新型设计方式,根据灵长类动物视网膜的注意点采样点阵(foveated sampling lattice)进行建模。我们希望这种学科之间的良性循环未来仍会持续。
更多信息,请查看我们发表在 ICLR 2017 的论文《Emergence of foveal image sampling from learning to attend in visual scenes》:https://arxiv.org/abs/1611.09430
参考文献
1. Hubel, David H., and Torsten N. Wiesel.「Receptive fields, binocular interaction and functional architecture in the cat's visual cortex.」The Journal of physiology 160.1 (1962): 106-154.
2. Fukushima, Kunihiko, and Sei Miyake.「Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition.」Competition and cooperation in neural nets. Springer, Berlin, Heidelberg, 1982. 267-285.
3. LeCun, Yann, et al.「Handwritten digit recognition with a back-propagation network.」Advances in neural information processing systems. 1990.
4. Gregor, Karol, et al.「DRAW: A Recurrent Neural Network For Image Generation.」International Conference on Machine Learning. 2015.

原文链接:http://bair.berkeley.edu/blog/2017/11/09/learn-to-attend-fovea/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





