【AI说】揭秘京东实时数据仓库背后的神秘力量—JDQ
技术背景
Kafka是由LinkedIn开发的一个分布式的消息系统,它以可水平扩展和高吞吐率而被广泛使用。现在它已被多家不同类型的公司作为多种类型的数据管道和消息系统使用。
主要设计目标如下:
♦ 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能;
♦ 高吞吐率——即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输;
♦ 支持Kafka Server间的消息分区,及分布式消费,保证每个Partition内的消息顺序传输, 同时支持离线数据处理和实时数据处理;
♦ Scale out:支持在线水平扩展
京东实时数据总线JDQ
在不断发展的京东,高速增长数据已经突破了我们的想象,我们的实时数据平台接受的任务也尤为艰巨。截止2017年618大促结束,实时数据平台生产消息8000亿条/天,大小约为285TB/天,消费能够到达1014TB/天。在每天系统最繁忙的时候,瞬时峰值流量能够达到生产73GB/s,消费263GB/s. 为了保证平台的正常运行,我们基于kafka形成了我们的京东实时数据总线-JDQ,这些数据都会采集进入到JDQ,然后后续在进行计算,分发,消费等处理(见实时平台架构图)。
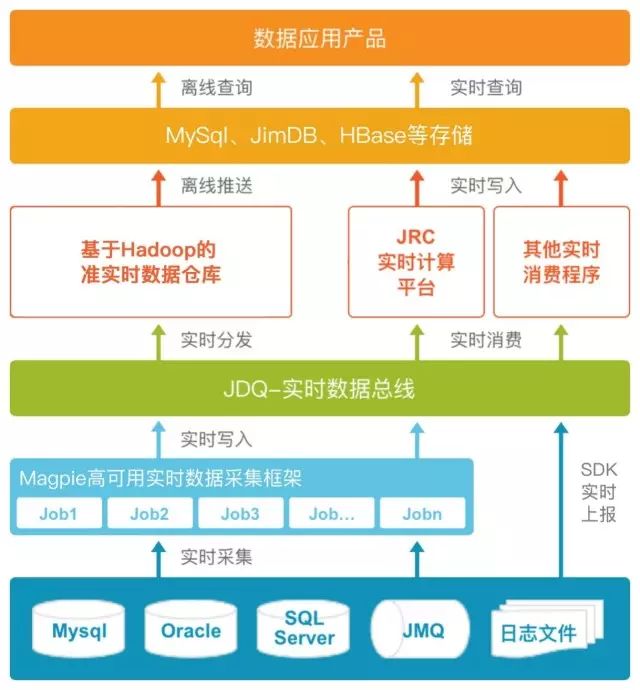
JDQ能做些什么
♦ 流式数据:JDQ内部存有实时数据仓库的所有数据,包括关系型数据库日志,点击流数据,日志类数据,以及自定义上报数据等,这里有京东内部齐全的流式数据。
♦ 解耦:JDQ可以介于不同的系统直接做消息传输,不同系统直接只需要支持处理消息来进行交互,这样系统就可以进行独立的扩展。
♦ 扩展性:增大消息入队和处理的频率是很容易的,可通过扩展分区来增加并发。不需要改变代码、不需要调节参数。
♦ 峰值处理能力:在访问量剧增的情况下,应用仍然需要继续提供正常服务,但是这样的突发流量并不常见。JDQ利用强大的吞吐量使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
♦ 可恢复性:下游系统的一部分组件失效时,不会影响到整个系统。JDQ降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
♦ 顺序保证:在大多使用场景下,数据处理的顺序都很重要。JDQ保证一个Partition内的消息的有序性。
♦ 缓冲:JDQ可作为缓冲层来帮助任务获得最的执行高效率,该缓冲有助于控制和优化数据流经过系统的速度。
♦ 异步通信:JDQ提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
JDQ的演进稳定之路
经过了将近4年的积累和沉淀,kafka日趋稳定,支撑了整个实时平台,下面介绍下JDQ的在平台中应用:
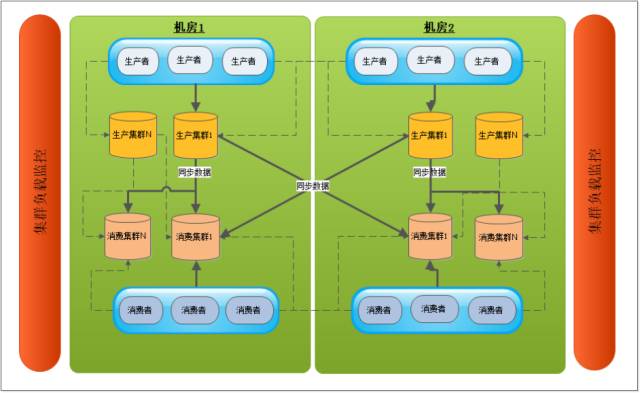
♦ JDQ—读写分离
在线上生产环境中,同时读写一个kafka集群的时候会相互影响,大部分情况下由于消费客户端的数量比较多,导致流出的数据量过大,可能会到达机器的硬件瓶颈,这个时候kafka的集群稳定性会受到一定的影响,可能会影响到生产,导致生产数据不能实时写入,造成生产的延迟。这种状况下,我们采用读写分离,生产集群中只会接收生产数据,而消费端只会有同步程序来进行消费,然后数据同步到消费集群的时候,大家再从消费集群消费数据,同时消费集群也可以为多个,消费者数据很多的时候可以消费多个集群的数据。
♦ JDQ—跨机房灾备
减少跨机房传输:每个机房都会部署1个或者多个生产集群和消费集群,在生产的时候客户端会选择本机房的kafka集群进行生产以减少跨机房的带宽。
生产灾备:当生产集群出现故障的时候,生产者可切换本机房的生产集群,如果本机房的集群没有可用的情况下可转发到其他机房的生产集群。
消费灾备:生产集群的是数据会被同步到各个机房的消费集群,如果某个消费客户端出现故障无法消费,则可切换到其他可用的消费集群,优先选择本机房的集群,如果本机房无可用集群切换至其他机房的消费集群。
♦ JDQ—消费切换衔接
集群数据同步是指将生产集群的数据同步到消费集群,而且对于单个topic来讲,所有消费集群的数据都是一样的。当消费中断需要切换消费的时候则需要将切换后的消费位点进行衔接,这里我们会在数据同步的时候将读写集群的位点关系维护起来,这样每个生产集群的位点都会对应到消费集群位点,而且消费位点对应生产位点的关系我们也会维护起来,这样每次再需要切换衔接位点的时候,我们就会从消费位点找到生产位点,然后再由生产位点找到其他的消费位点,这样保证消费衔接的问题。
♦ JDQ—安全认证
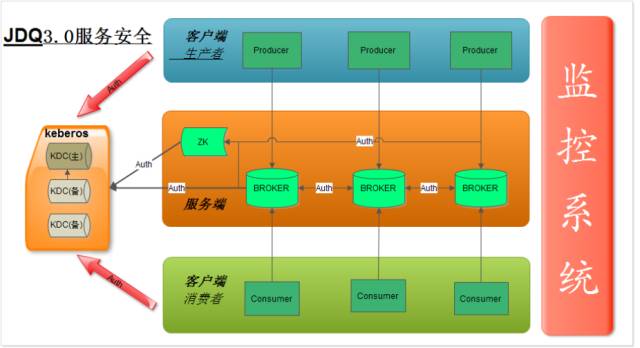
kafka在0.9之后才加入安全认证,在此之前集群的安全问题还是很严重,JDQ需要保证平台的安全稳定运行,需要防止不明身份的broker对集群的访问,不明身份的broker不应该成为集群的一员,不明身份的broker不应该能够从集群中的broker拉取数据,防止集群在ZK上的metadata被篡改,保证数据存储的安全,保证集群与外部客户端的安全通讯,执行客户端的用户身份认证。
我们引入了kerberos帮助kafka做安全认证,我们要对客户端和各个组件都进行认证,保证每个环境的安全。
♦ JDQ—权限管理
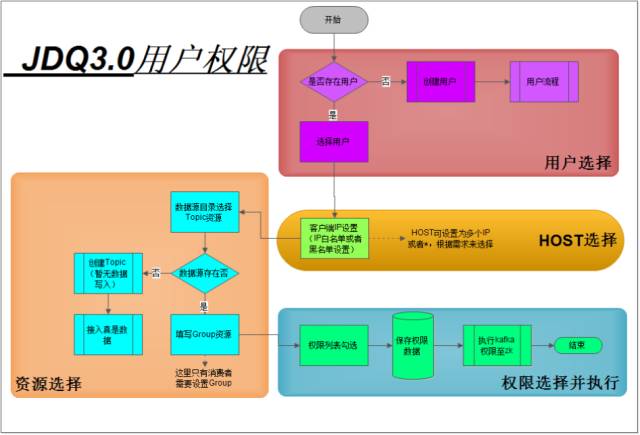
在安全认证之后,权限管理就是下一个需要注重的环境,我们需要控制客户端对资源的访问,只能对授权的资源进行访问,这样我们的安全程度就会更加提高一个层次。如图,我们的权限可以根据各自的需要进行设置。
♦ JDQ—监控
平台能够健康稳定的一个重要因素就是一个精准的监控系统,各个环节以及硬件等各种指标的采集分析都能够帮助平台进行自我检查和恢复。JDQ监控系统会采集服务端,客户端等各项指标进行梳理展示,帮助大家分析问题,也会根据这些指标进行一定的分析,得到现有系统的一个负载状况,当出现一些问题的时候可以进行自我修复。我们利用kafka的生态,用kafka connect进行数据采集,将服务端的metrics采集,然后利用kakfa steam进行一次数据的逻辑处理,再用kafka connect转存数据入ES,最终在grafana进行展示。
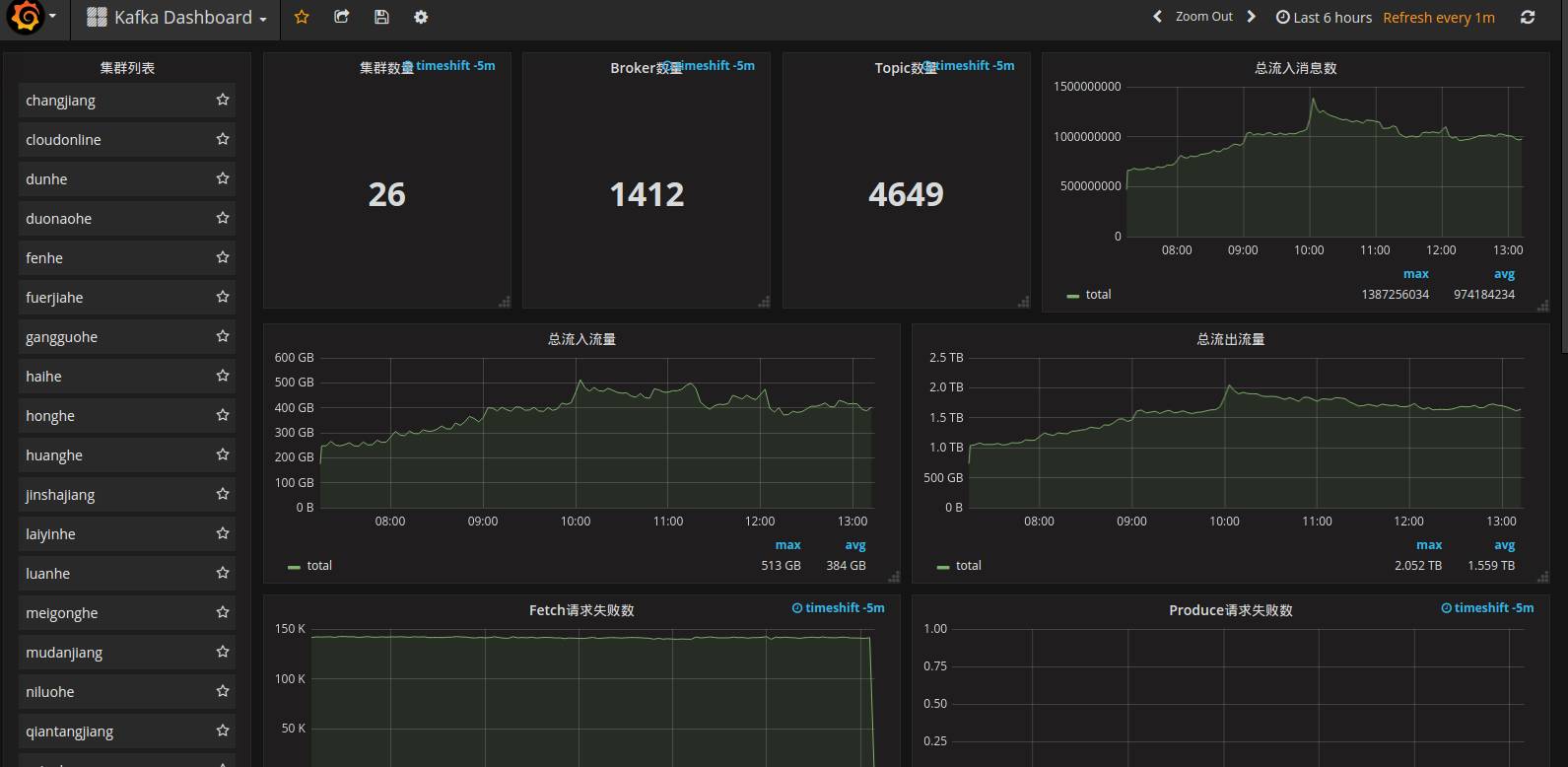
♦ 总结
JDQ已经在实时数据平台内部进行了两个版本的更新,包括集群负载,灾备,读写分离,安全和监控等方面都做了一定的改造,同时经历了多次618和双十一的洗礼之后已经越来越稳定,面对实时数据平台中不断暴涨的业务和数据还是有很大的挑战,我们依然会对现有的框架进行不断的升级,更好的服务各种类型的用户。
乔超
京东AI与大数据部软件开发工程师
从事大数据研发工作5年,在京东4年多的时间里一直从事实时数据、平台相关工作,负责实时数据总线JDQ
擅长领域分布式消息中间件,获得2016年优秀个人奖
专利:kafka多集群负载均衡拓扑方案






