读书报告 | WORD TRANSLATION WITHOUT PARALLEL DATA

Under review as a conference paper at ICLR 2018
链接:https://arxiv.org/pdf/1710.04087.pdf
摘要
当前跨语言的词向量学习的最有效的方法大多基于双语辞典和平行语料,无监督的方法在效果上并不令人满意。本文提出一种无监督的跨语言词向量学习方法,在仅使用单语词向量的情况下达到了有监督学习相同的效果。实验证明所提出方法在性质不同的两种语言上,例如English-Russian和English-Chinese,也能达到很好的效果。
模型
在词向量中两个有意思的发现:(1)连续低维的词向量空间在不同的语言中有相似的结构(线性映射可以将一种语言投射到另一种语言中)。(2)中心问题:存在一些词是很多词的邻居点,也存在另一些词它们分布偏离中心位置,不是任何词的邻居点。本文基于这两种发现来设计相关模型。
本文首先使用了领域-对抗生成(domain-adversarial)的方法来学习语言对之间的线性映射参数,判别器(Discriminator)目标在于判别向量来自于目标语言还是源语言映射,其目标函数如下:
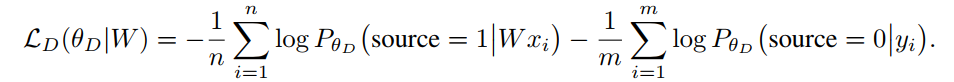
映射器函数目标在于尽量迷惑判别器,让其难以分辨两个向量的来源,目标函数如下:
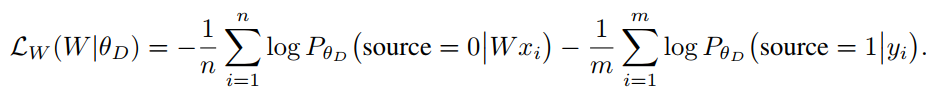
因为稀少词的向量表征并不稳定,会为训练带来噪声。所以这里只使用了高频词进行训练,同时使用self-training来进一步增加模型的准确率。也就是利用已经学习得到的W来自动标注对齐的词对,再利用这些词对进行训练学习。本文提出一种新的相似性度量的方法来产生词对,公式如下:
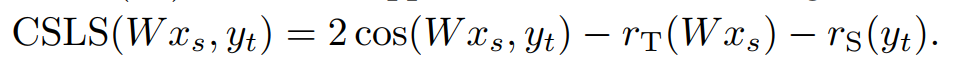
为了缓解中心问题,公式分别使用了第二项和第三项来分别对中心词和偏离词进行惩罚和缓解。
实验
实验部分包含三个部分:词翻译,跨语言词相似度,句子翻译检索。其中词翻译部分中,本文构造了一个100K的词对数据进行衡量。
实验发现本文提出的无监督方法与有监督方法在所有三个任务上有同样甚至略好的表现。
思考
本文的motivation非常清晰,方法上也有让人眼前一亮的点:使用对抗生成的方法来学习线性映射以及提出一种新的度量方法来处理中心分布问题。
有开源的代码,可以考虑缓解low-resource词向量的表征问题。
作者:尹伊淳,北京大学在读博士,研究方向为自然语言处理。

