独家 | 手把手带你用无监督学习检验国际美食!

作者:Ben Sturm
翻译:和中华
校对:Nicola
本文约2900字,建议阅读10分钟。
本文作者将自己所学的数据科学知识和一颗吃货的心相结合,对12,500个来自世界各地25种菜系的食谱进行了无监督分析,并发现了一些有趣的结论。

Typical Tyrolean Käsespätzle (Image courtesy: https://austria-forum.org/)
像很多人一样,我也是一名吃货。我很幸运能在一个所有食物都是从头开始亲自做的家庭里长大。所有的烹饪都由我妈妈完成,因为她是从德国移民到美国的,我也跟着接触了很多美味的德国菜。我最喜欢的一些包括Käsespätzle,Semmelknödel和Sauerbraten。虽然我没有妈妈的烹饪天赋,但我非常喜欢从头开始做饭的过程,当然也会和我的家人分享的过程。
以此为背景,我觉得开展一个涉及世界各地食谱的数据科学项目肯定很有意思。我想看看是否能够了解世界各地不同菜系的关系。为了探索这个主题,我从代表了25种不同菜系类型的12,000种不同食谱中收集了数据。然后,我进行了自然语言处理(NLP),将文本数据转换为可以输入机器学习算法的格式。最后,我进行了主成分分析(PCA)和主题建模,以获得对数据的深入见解。
数据收集
这个项目的食谱数据来自Yummly。我获得了API的一个学生许可证(谢谢Yummly!),让我可以直接从ipython notebook进行查询和搜索食谱。Yummly支持根据菜系类型进行搜索。以下是所支持的菜系类型清单:
美式,意大利菜,亚洲,墨西哥,美国南部料理,法国,西南地区食物,烧烤,印度,中餐,克里奥尔风味,英国,地中海,希腊,西班牙,德国,泰国,摩洛哥,爱尔兰,日本,古巴,夏威夷,瑞典,匈牙利,葡萄牙
总的来说,我为25种菜系分别下载了大约500份食谱。这就产生了12,500种不同的食谱。关于数据收集,我通过Requests库读取数据,使用内置JSON编码器将JSON数据转换为python字典。之后将数据转换为Pandas DataFrame就相对简单了。下图展示了DataFrame中的某些行:
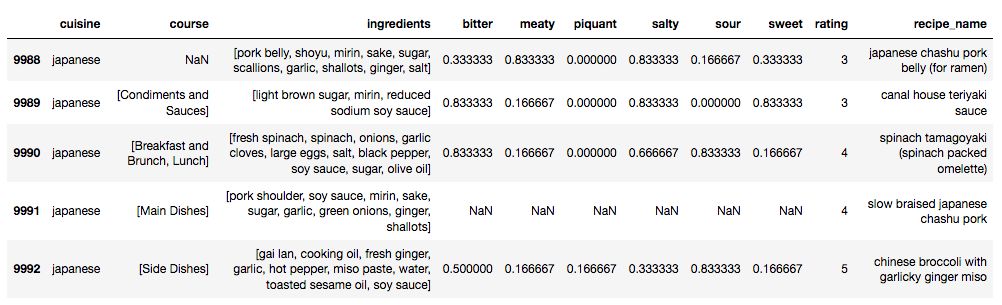
对于我的分析,我只使用了与菜系和配料相关的列。其他列都被忽略了。
文本数据处理和机器学习工作流
由于数据仅由文本组成,因此有必要使用NLP技术进行许多预处理步骤。这些步骤如下:
用连字符连接某些配料(例如olive-oil橄榄油,corn-starch玉米淀粉)
分词,将配料分解成单词的列表
删除停顿词和其他经常出现的词(例如盐,胡椒,水)
通过删除单词的复数形式和其他后缀来词干化
词袋处理从而创建一个稀疏矩阵,该矩阵由配料列表中的所有单词以及它们出现的频率组成
实现上面步骤列表的工具包括sklearn中的TfidfVectorizer和CountVectorizer。 其中一些步骤,如删除连字符和停顿词,需要编写自己的代码来实现,因为这些步骤更针对于这个具体的用例。读者可以查看我的Github repo来了解更多信息。
我关注的机器学习算法都是无监督学习算法。我用了k-Means 聚类来查看是否可以根据菜系类型将食谱聚集在一起,但是聚类对我的分析并不是很有帮助,因为我不清楚不同的聚类代表什么。相反,我把注意力放在主成分分析(PCA)以及Latent Dirichlet Allocation(LDA)上,具体内容我将在结果部分进一步讨论。
结果
为了能够可视化数据,我实现了降维,以便将1982个维度(对应数据集中不同配料的数量)的特征空间减少到2维。这一步是使用PCA完成的,我保留了前两个主要组成部分。然后,我针对前两个主成分创建了每个食谱的散点图,如下所示:
12492个食谱在前两个主成分上的散点图
当在2维主成分空间中绘制所有食谱时,我没有学到很多信息,因为许多数据点都是重叠的,因此很难从数据中看到任何结构。然而,通过菜系对食谱进行分组并沿着前两个主要成分获取质心值(Centroid values),我可以在数据中看到一些有趣的结构。如下所示:
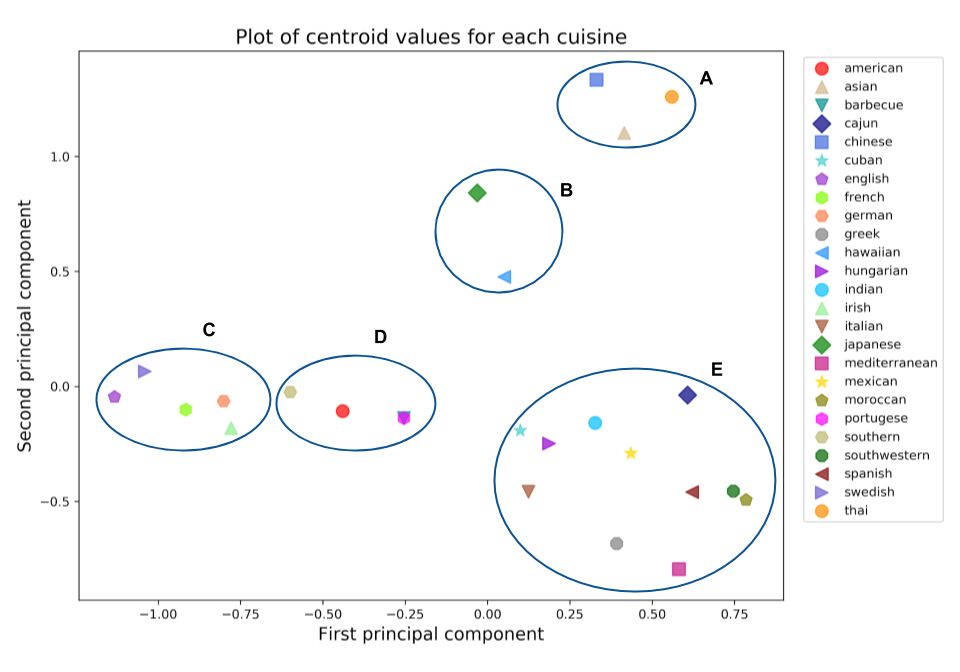
沿着第一、第二主成分的每种不同菜系质心值的图。组(A)与亚洲美食相关,(B)由日本和夏威夷美食组成,(C)和(D)分别是欧洲和美国美食。组(E)是来自世界各地的美食混合,包括古巴,墨西哥,印度和西班牙。
上面的图提供了一些关于不同菜系关系的有趣见解。我们可以观察到质心值倾向于根据类似的菜系对食谱进行分组。例如,图2中的组(A)由中国,泰国和亚洲菜组成,这些都可以归类为亚洲食品。组(B)包括日本料理和夏威夷料理。这两种菜系都非常注重鱼类,因此将它们紧密地组合在一起是有道理的。组(C)完全由瑞典,法国和德国等欧洲美食组成,不远处的组(D)主要由北美菜肴组成。这些包括南部,烧烤和传统的美式菜。最后,组(E)是来自世界各地的美食混合,包括古巴,墨西哥,印度,西班牙和西南美食。当我想到这些美食时,我会想到加重的味道,所以将这些美食紧密地组合在一起是完全合理的。
读者可能会问的问题是,哪些特征(即配料)与第一和第二主成分的联系最紧密?这可以在下图中看到。
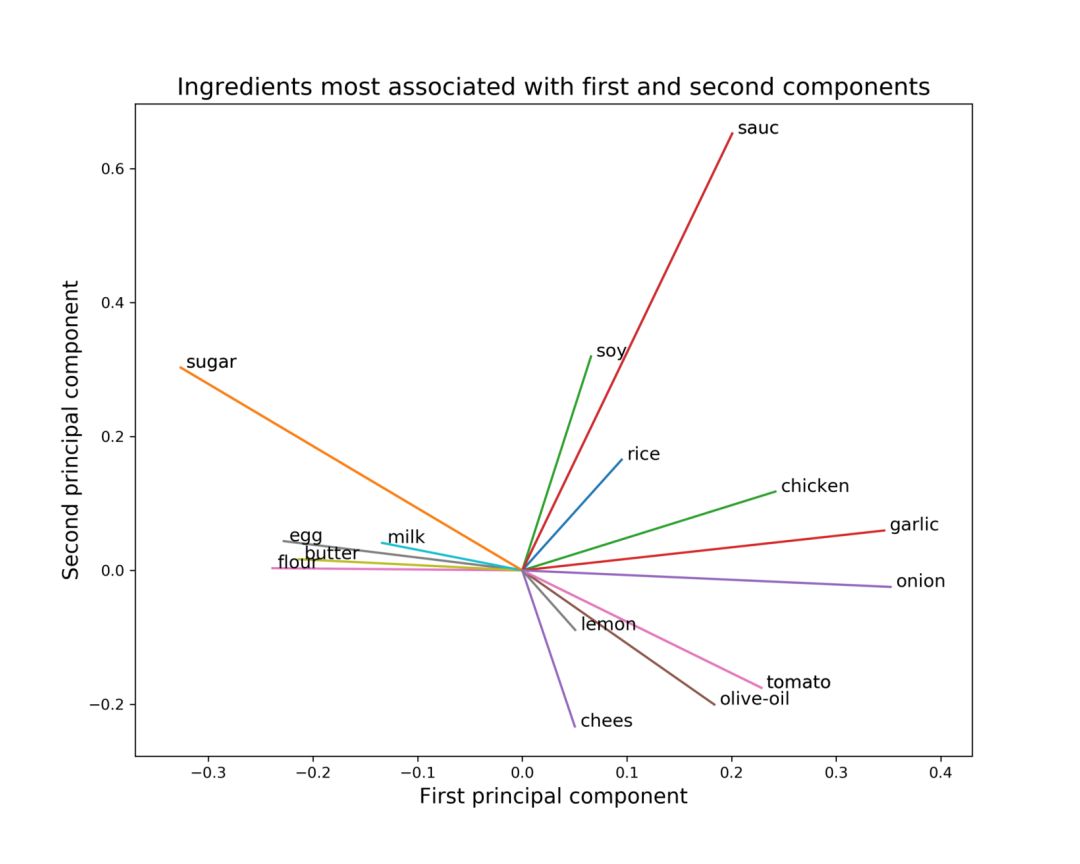
与第一和第二主成分最强烈相关的配料
该图是对两个主成分相应的主要特征的直观表示。鸡肉,大蒜,洋葱和番茄等配料沿着主成分1的正方向有很强的联系。这些口味与西班牙或印度菜等美食有很强的联系。另一方面,鸡蛋,黄油,面粉,牛奶和糖在主成分1的负方向上具有强烈的联系。这些是典型的法国或英国菜肴的原料。同样,大豆,酱油和大米与主成分2的正方向有很强的联系。这些配料在亚洲美食中很常见。最后,奶酪,柠檬,橄榄油和番茄与主成分2的负方向有很强的联系。这些口味在意大利和希腊美食中非常常见。该图有助于解释前一个图的结构,即当沿第一和第二主成分绘制时某些菜系在特定区域聚集在一起的原因。
最后,我还运行了一个LDA模型来进行主题建模(见下文)。我很想知道是否有可能根据各种配料通常所属的美食菜系来将其分离。我指定的主题数量为25,因为我知道数据集中有25种不同的菜系。然而,LDA的结果有点混乱。在某些情况下,LDA主题是特定的菜系,比如意大利菜或泰国菜。然而,还有一些主题是不同类别的菜肴,比如甜点,酱汁,甚至鸡尾酒。虽然这个结果不是我想要的,事后看来它实际上是完全合理的。LDA是一种机器学习技术,可以识别出经常出现在一起的单词组(group of words)。因此,在超过12,000个食谱的语料库中,基于菜肴的类型(即甜点,汤,沙拉或酱汁)而非菜系类型,可能存在更强的单词组关联

LDA主题建模的结果
思考
我在探索食谱数据集时有很多乐趣,因为我非常享受将我对食物的热爱与我在数据科学中获得的新技能相结合。人们还可以为此类分析做一个商业案例,因为这些信息可用于向Yummly平台的用户提供菜谱推荐。例如,非常喜欢烧烤的人也可能喜欢葡萄牙美食,因为这两种菜系在沿第一二主成分绘制质心时会重叠。这种内在关系是我在没有探索数据之前无法预料的。
然而需要注意的是,本文使用的数据并非没有缺陷。比如,Yummly基本上是一个汇集了来自许多其他食谱网站或博客的食谱网站,所有这些都是英文的。因此,许多食谱可能是站在美国人的角度对其他美食的看法。我相信我的意大利朋友会说像鸡肉和香蒜酱这样掺和在一起的食谱“并不意大利!”,尽管Yummly将这个食谱标记为意大利式。处理这个问题的一个更好的方法可能是找到他们母语的食谱,并使用一些高级翻译算法将它们翻译成英语。然而,由于食物配料可能对特定地理区域是特定的,这也可能导致意外问题。例如,某些配料可能没有英语中的等价物(例如,Prosciutto di Parma,Parmigiano Reggiano),因此这些配料将始终与意大利美食相关联。这可能会导致不同类型的菜系之间只能找到更少的相似性,但仍然值得探索。
非常感谢您阅读我的博客文章。如果想浏览我的代码,可以在Github repo中找到它。此外,我也非常欢迎反馈,如果你喜欢这篇文章,请给我点个赞。
原文标题:
An Examination of International Cuisines through Unsupervised Learning
原文链接:
https://towardsdatascience.com/an-examination-of-international-cuisines-through-unsupervised-learning-93c8b56d1ea0
译者简介

和中华,留德软件工程硕士。由于对机器学习感兴趣,硕士论文选择了利用遗传算法思想改进传统kmeans。目前在杭州进行大数据相关实践。加入数据派THU希望为IT同行们尽自己一份绵薄之力,也希望结交许多志趣相投的小伙伴。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织




