教你用机器学习匹配导师 !(附代码)

作者:Zipporah Polinsky-Nagel, Gregory Brucchieri, Marissa Joy, William Kye, Nan Liu, Ansel Andro Santos and Merle Strahlendorf
翻译:王雨桐
校对:丁楠雅
本文约2000字,建议阅读8分钟。
本文将通过实例展示如何应用机器学习来更好地匹配学生和导师,最终在Flask图表界面中展示结果。
介绍
在顶点课程中我们组被分配到一个非营利机构,这个机构帮助青年学生和科技领域中的专业人士建立联系,目的在于提升在校学生对科技产业的参与度(译者注:顶点课程capstone project是美国大学高年级学生的环节,类似于中国大学的毕业设计)。学生要和导师(专业人士)配对,导师与学生会面并带他们了解这个行业。每次会面后,学生和导师都需要对会面进行评分。满分是5分,1分是最低分。
这个机构根据学生的评分来衡量会面是否成功,因此他们想了解哪些特征和变量会提升评分。一旦有这些东西,我们就可以构建一个算法来匹配学生和导师,并生成一个在线图表界面进行可视化展示。
我们计划用Python完成算法和实现展示。 首先,我们进行数据清洗并定义语料库(Corpus),随后借助逻辑回归来识别重要特征,接着我们构建了匹配得分和分配算法,最终将所有内容打包并放到Flask图表界面中。
数据清洗和生成语料库
数据集由80多个特征组成,但是我们要尽量减少特征,最后选择了25个最重要的特征。数据集中的数值型数据相对干净,但字符型数据比较乱,需要对数据进行标准化处理。
我们对输入文本进行了自然语言处理。首先将所有用户的文本字段汇总在一起;随后用Python中的NLTK包进行分词;接着我们去掉了其中的表情符号、终止词和标点,并对剩余的词进行词形还原。300余名用户的原始单词集中有81000个词汇,在文字处理后,词汇数量减少到了54000个。最后,我们统计每个单词在数据集中出现的频数并删除出现次数少于5次的单词。最终,唯一的词汇列表形成语料库。
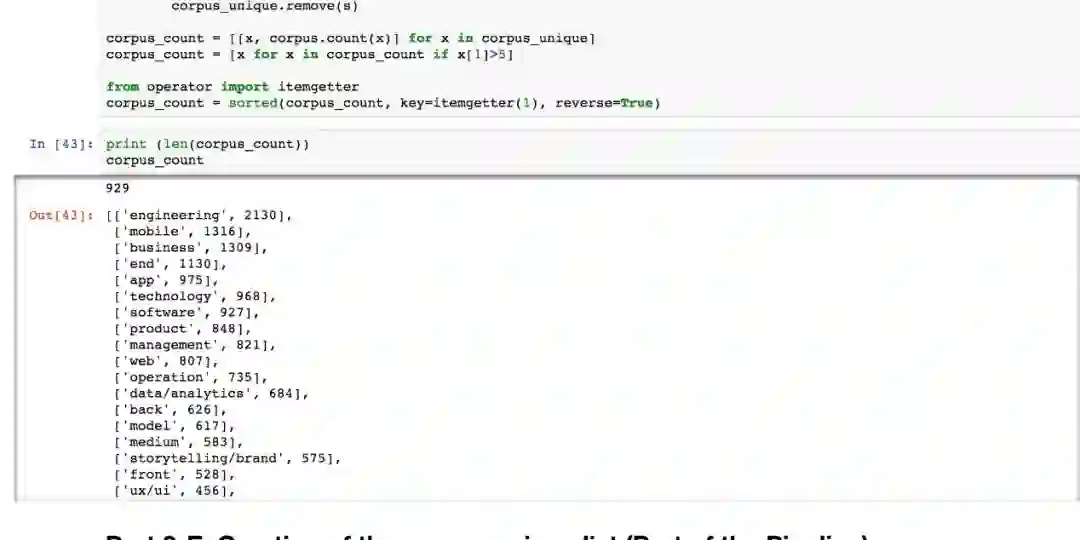
用同样的方式,进一步得到每个用户的经语料库过滤的关键词列表。
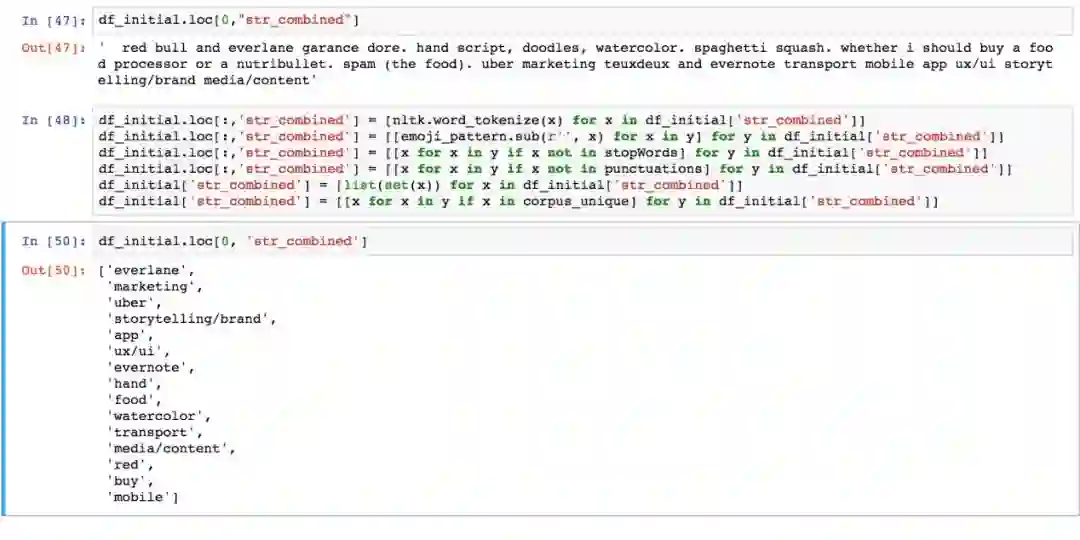
筛选重要特征
为了确定哪些变量对满分评价有更大贡献,我们对18个特征进行逻辑回归。结果显示word_count, tech_common, and tech_common:stud_experience_o是影响最显著的变量。其中word_count是学生和导师共同使用的单词的数量;tech_common是一个布尔值,当学生和导师有相同的技术兴趣时,它的值为True;tech_common:stud_experience_o是一个变量,这个变量结合了tech_common的效果还有学生已达到的教育水平。
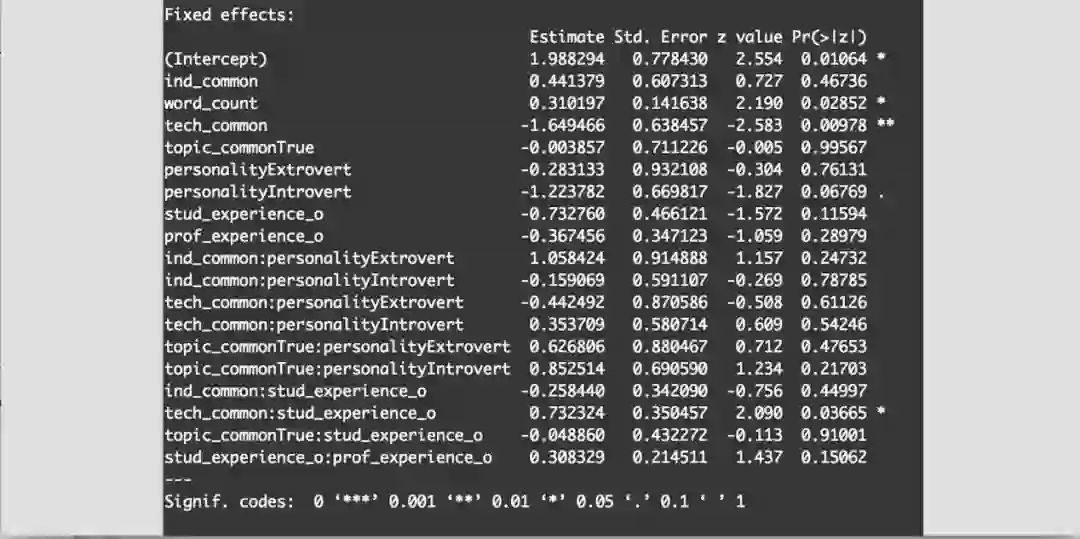
结果在我们预料之中,因为有更多相同的关键字意味着学生和导师有更多的共同话题。更有可能获得有趣的交流,使学生更倾向给会面打高分。
匹配得分和分配算法
匹配算法包括确定所有可能配对的得分和分配逻辑两个部分。我们既可以通过逻辑回归,也可以通过K-近邻(KNN)来计算匹配得分。
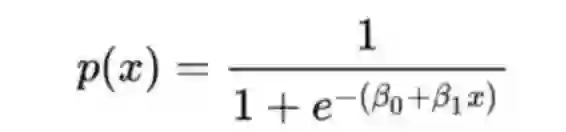
逻辑回归的公式会计算一个0到1之间的值,这是得到目标结果的概率,在本案例中是得到5星评价的概率。我们的目标当然是得到更高的概率。计算所有可能配对的得分并将其放到矩阵中。数据格式化的方式很重要,因为它将生成输入配对算法的原始数据。
现在我们将通过K-近邻算法计算得分。对第二部分中的每个用户制作关键词列表,这将成为K-近邻计算得分的输入。
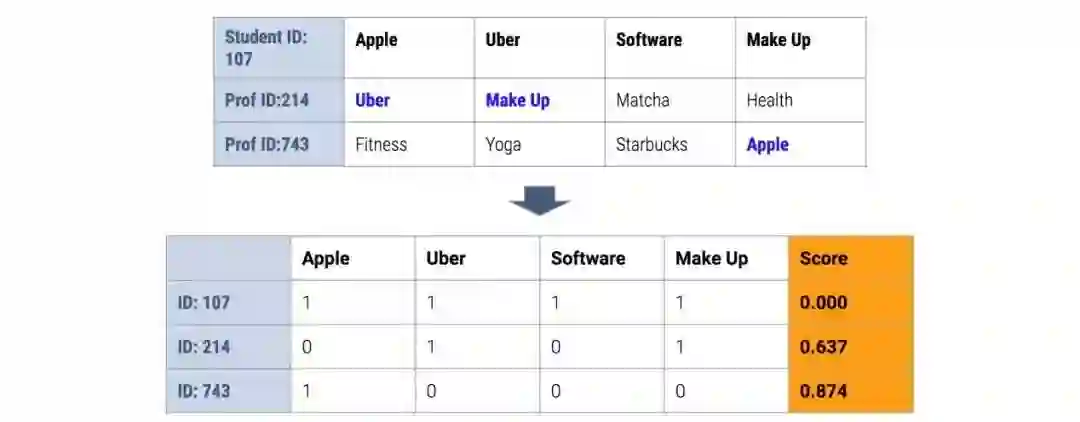
如上所示,针对每个用户都会生成一个二维矩阵,其中每列是用户产生的关键词,每个用户都是索引。用户和其他用户是否有共同词汇将通过0和1表示。这个矩阵将作为K-近邻函数的输入,随后得到一个代表两个人之间距离的值。两个人之间的共同词汇越多,这个值就越低。我们对这个值进行标准化处理,使其值在0到1之间。这意味着一个人和他自己的距离是0;如果另一个人和他没有任何匹配单词,则两个人的距离为1。
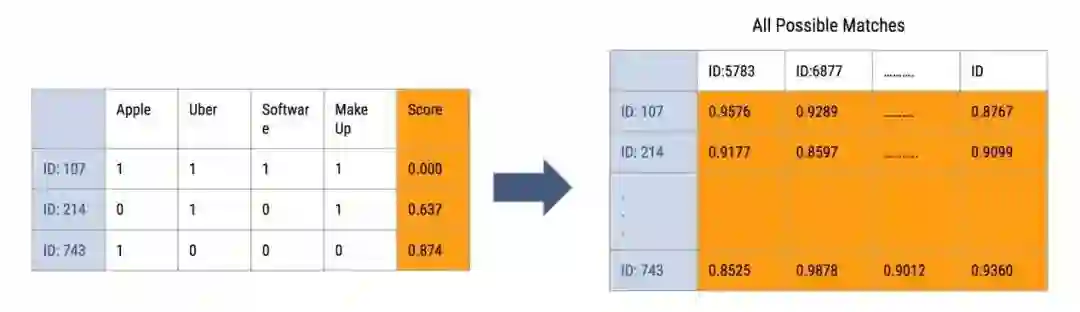
使用所有可能配对的分数矩阵来计算基于特定条件的可能配对。例如,为了见面方便,我们希望学生和导师来自同一个城市。首先用最严格的条件集合。如果没有找到匹配得结果。条件逐步放松,直到最终只剩下一个条件。
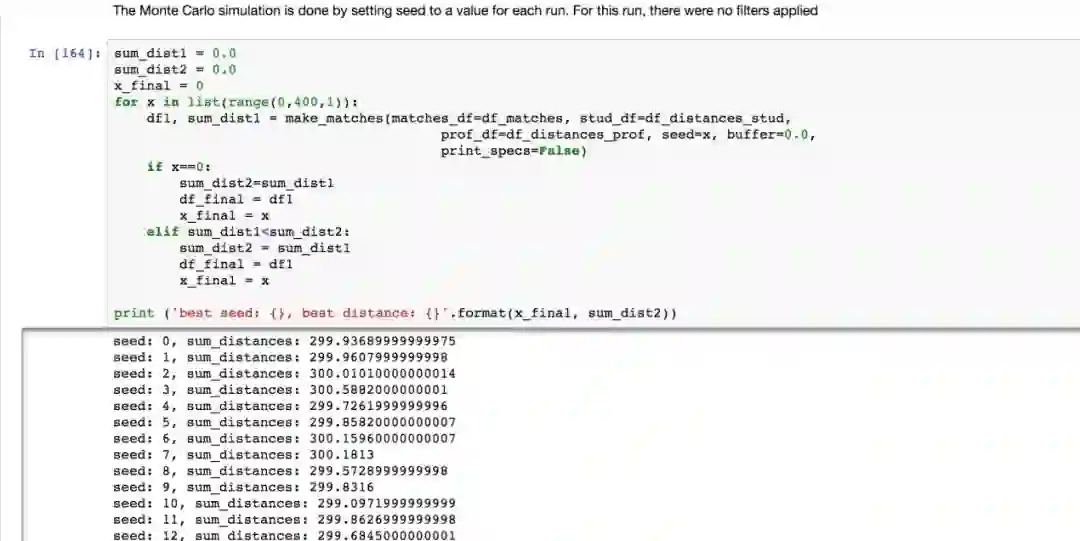
一个用户可能有多个相同最佳得分的匹配结果。我们通过随机抽样来进行配对。我们使用蒙特卡洛模拟来进行随机配对,进而得到给定的学生群体的最佳匹配集。
Flask图表界面
图表界面会显示每批次数据,排名分布,常用关键词词云,以及每个用户的关键词列表。此外,还有一个区域可以查看最佳匹配结果。图表界面使用了Jupyter notebook的结构,后端是Python代码,可以生成CSV文件,这个CSV文件进而在前端Flask中处理。
附YouTube连接(Flask图表界面的视频演示)
https://www.youtube.com/embed/qih0b11bFFE?feature=oembed
结论和建议
我们已经展示了哪些因素会决定评分预测结果,并开发了一种改进算法来匹配导师和学生。通过K-近邻方法,我们改进了目前的匹配方法。尽管有更多的数据,使用逻辑回归进行配对是更有效的选择。
原文标题:Mentor Matching using Machine Learning
原文链接:
https://nycdatascience.com/blog/student-works/capstone/mentor-matching-using-machine-learning/
译者简介

王雨桐,统计学在读,数据科学硕士预备,跑步不停,弹琴不止。梦想把数据可视化当作艺术,目前日常是摸着下巴看机器学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织




