K近邻算法哪家强?KDTree、Annoy、HNSW原理和使用方法介绍

原创 · 作者 | Giant
学校 | 浙江大学
研究方向 | 对话系统、text2sql
知乎专栏 | 大熊猫游乐园
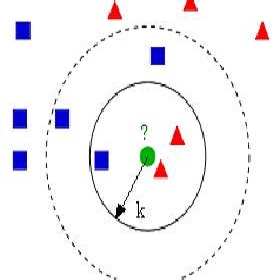
1、什么是K近邻算法
K近邻算法(KNN)是一种常用的分类和回归方法,它的基本思想是从训练集中寻找和输入样本最相似的k个样本,如果这k个样本中的大多数属于某一个类别,则输入的样本也属于这个类别。
关于KNN算法,一个核心问题是:如何快速从数据集中找到和目标样本最接近的K个样本?
本文将从这个角度切入,介绍常用的K近邻算法的实现方法。具体将从原理、使用方法、时间开销和准确率对比等方面进行分析和实验。
2、距离度量
在介绍具体算法之前,我们先简单回顾一下KNN算法的三要素:距离度量、k值的选择和分类决策规则。
其中机器学习领域常用的距离度量方法,有欧式距离、余弦距离、曼哈顿距离、dot内积等

主流的近邻算法都支持上述不同的距离度量。其中n维特征空间的a、b向量的欧式距离 
实际应用中,需要根据业务目标来选择合适的度量方法。
3、K近邻算法的实现方法
K近邻的实现方式多达数十种,笔者从中挑选了几种常用、经典的方法作为分析案例。
首先最直观的想法(暴力法),是线性扫描法。将待预测样本和候选样本逐一比对,最终挑选出距离最接近的k个样本即可,时间复杂度O(n)。对于样本数量较少的情况,这种方法简单稳定,已经能有不错的效果。但是数据规模较大时,时间开销严重无法接受。
所以实际应用中,往往会寻找其他类型的数据结构来保存特征,以降低搜索的时间复杂度。
常用的存储结构可以分为树和图两大类。树结构的代表是KDTree,以及改进版BallTree和Annoy等;基于图结构的搜索算法有HNSW等。
4、KDTree和BallTree
KDTree
kd 树是一种对k维特征空间中的实例点进行存储以便对其快速检索的树形数据结构。
kd树是二叉树,核心思想是对 k 维特征空间不断切分(假设特征维度是768,对于(0,1,2,...,767)中的每一个维度,以中值递归切分)构造的树,每一个节点是一个超矩形,小于结点的样本划分到左子树,大于结点的样本划分到右子树。
树构造完毕后,最终检索时(1)从根结点出发,递归地向下访问kd树。若目标点 
kd树在维数小于20时效率最高,一般适用于训练实例数远大于空间维数时的k近邻搜索;当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线形扫描。
BallTree
为了解决kd树在样本特征维度很高时效率低下的问题,研究人员提出了“球树“BallTree。KD 树沿坐标轴分割数据,BallTree将在一系列嵌套的超球面上分割数据,即使用超球面而不是超矩形划分区域。
具体而言,BallTree 将数据递归地划分到由质心 C 和 半径 r 定义的节点上,以使得节点内的每个点都位于由质心C和半径 r 定义的超球面内。通过使用三角不等式 
coding 实验
以下实验均在CLUE下的今日头条短文本分类数据集上进行,训练集规模:53360条短文本。
实验环境:Ubuntu 16.04.6,CPU: 126G/20核,python 3.6
requirement:scikit-learn、annoy、hnswlib
实验中我使用了bert-as-service服务将文本统一编码为768维度的特征向量,作为近邻搜索算法的输入特征。

工具包sklearn提供了统一的kdtree和balltree使用接口,可以用一行代码传入特征集合、距离度量方式。
为了减少推理时间,我这里仅选取验证集中前200条文本作为演示。
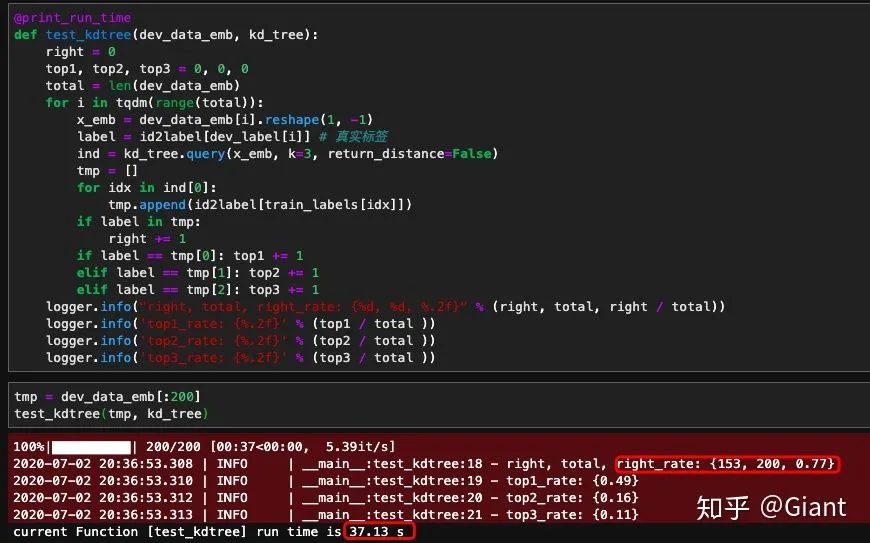
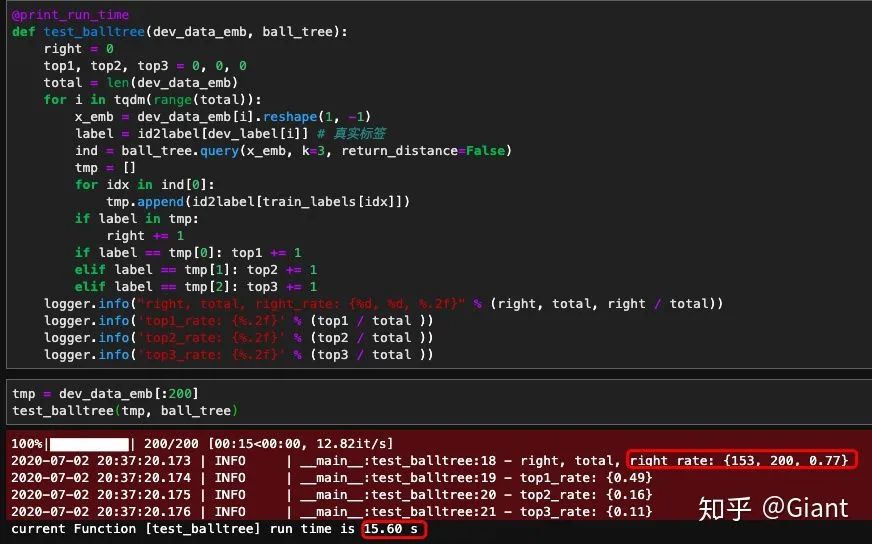
观察实验发现,以欧式距离为度量标准,从5w条知识库中查找和输入文本最接近的top3,200条验证集中kd树和球树均正确检索出153条,但是kd树检索200条花费了37秒(185ms/条),球树花费15秒(75ms/条),balltree的检索时间比kdtree快了1倍以上。
5、Annoy
annoy全称“Approximate Nearest Neighbors Oh Yeah”,是一种适合实际应用的快速相似查找算法。Annoy 同样通过建立一个二叉树来使得每个点查找时间复杂度是O(log n),和kd树不同的是,annoy没有对k维特征进行切分。
annoy的每一次空间划分,可以看作聚类数为2的KMeans过程。收敛后在产生的两个聚类中心连线之间建立一条垂线(图中的黑线),把数据空间划分为两部分。

在划分的子空间内不停的递归迭代继续划分,直到每个子空间最多只剩下K个数据节点,划分结束。

最终生成的二叉树具有如下类似结构,二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。
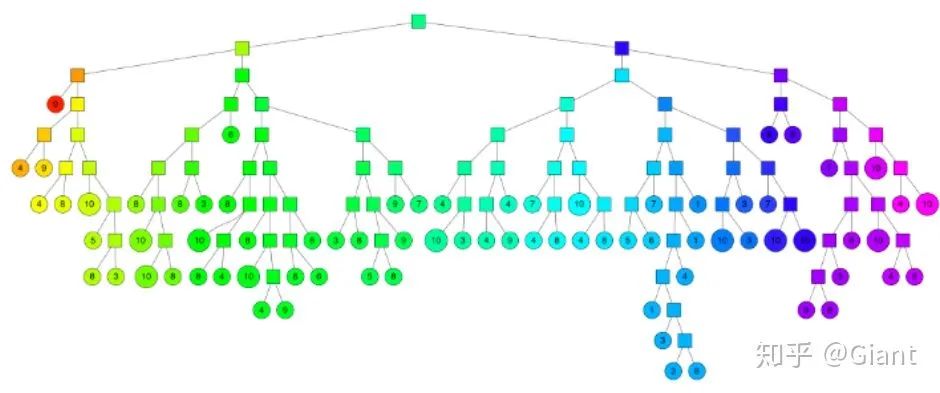
查询过程和kd树类似,先从根向叶子结点递归查找,再向上回溯即可,完整构建、查找过程可以参考快速计算距离Annoy算法。
coding 实验
annoy包封装了算法调用的python接口,底层经C++优化实现。继续使用头条文本数据集,调用方法如下:
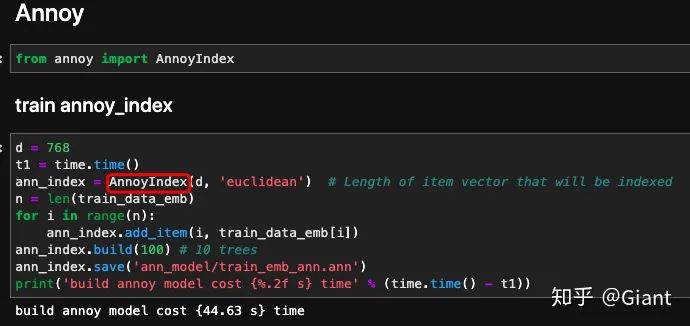
首先构建一个“AnnoyIndex”索引对象,需指定特征维度和距离度量标准(支持多种距离度量方式),并将所有数据集样本特征顺序添加到索引对象中。
之后需要在 build(n_trees) 接口中指定棵数。annoy通过构建一个森林(类似随机森林的思想)来提高查询的精准度,减少方差。构建完成后,我们可以将annoy索引文件保存到本地,之后使用时可以直接载入。(完整说明文档参考annoy的github仓库)
最后,我们对输入的200条文本依次查找top3近邻。
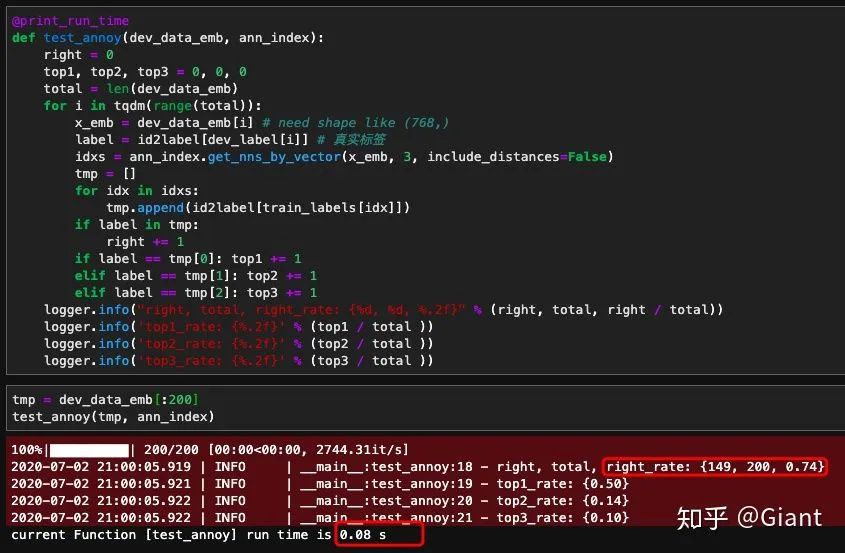
我们发现,正确查找的样本数和之前相差不大(153 -> 149),但是查找速度从之前的15秒(75ms/条)降到了0.08秒(0.4ms/条),提升了100倍以上,达到了实际开发中的延时要求。
最后提一点,annoy接口中一般需要调整的参数有两个:查找返回的topk近邻和树的个数。一般树越多,精准率越高但是对内存的开销也越大,需要权衡取舍(tradeoff)。
6、HNSW
和前几种算法不同,HNSW(Hierarchcal Navigable Small World graphs)是基于图存储的数据结构。
图查找的朴素思想
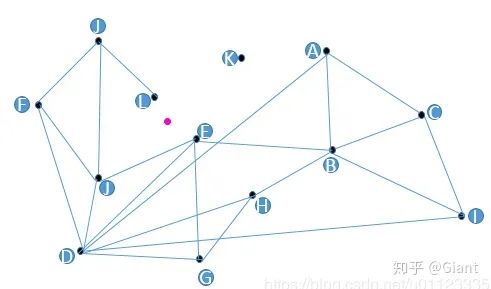
假设我们现在有13个2维数据向量,我们把这些向量放在了一个平面直角坐标系内,隐去坐标系刻度,它们的位置关系如上图所示。
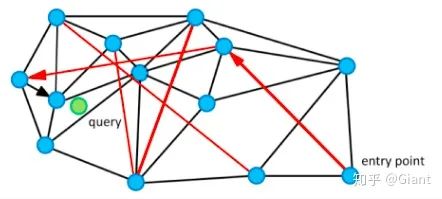
朴素查找法:不少人脑子里都冒出过这样的朴素想法,把某些点和点之间连上线,构成一个查找图,存储备用;当我想查找与粉色点最近的一点时,我从任意一个黑色点出发,计算它和粉色点的距离,与这个任意黑色点有连接关系的点我们称之为“友点”(直译),然后我要计算这个黑色点的所有“友点”与粉色点的距离,从所有“友点”中选出与粉色点最近的一个点,把这个点作为下一个进入点,继续按照上面的步骤查找下去。如果当前黑色点对粉色点的距离比所有“友点”都近,终止查找,这个黑色点就是我们要找的离粉色点最近的点。
HNSW算法就是对上述朴素思想的改进和优化。为了达到快速搜索的目标,hnsw算法在构建图时还至少要满足如下要求:1)图中每个点都有“友点”;2)相近的点都互为“友点”;3)图中所有连线的数量最少;4)配有高速公路机制的构图法。
HNSW低配版NSW论文中配了这样一张图,短黑线是近邻点连线,长红线是“高速公路机制”,如此可以大幅减少平均搜索的路径长度。
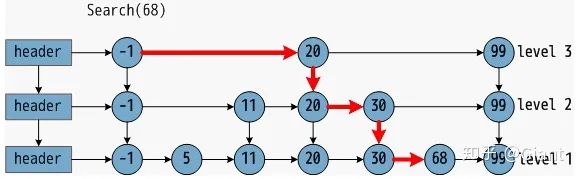
在NSW基础之上,HNSW加入了跳表结构做了进一步优化。最底层是所有数据点,每一个点都有50%概率进入上一层的有序链表。这样可以保证表层是“高速通道”,底层是精细查找。通过层状结构,将边按特征半径进行分层,使每个顶点在所有层中平均度数变为常数,从而将NSW的计算复杂度由多重对数复杂度降到了对数复杂度。
关于HNSW的详细内容可以参考原论文Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs和博客HNSW算法理论的来龙去脉。
coding 实验
通过 hnswlib 库,可以方便地调用hnsw算法。
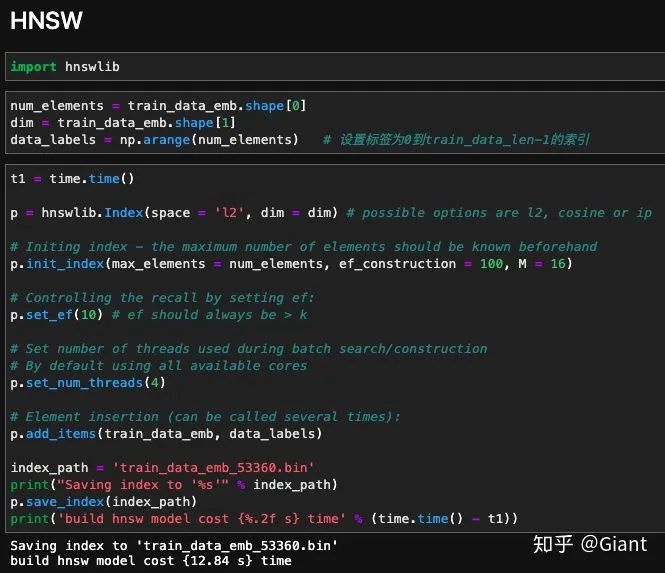
同样,首先将输入特征载入索引模型并保存到本地,下一次可以直接载入内容。具体测试实验:
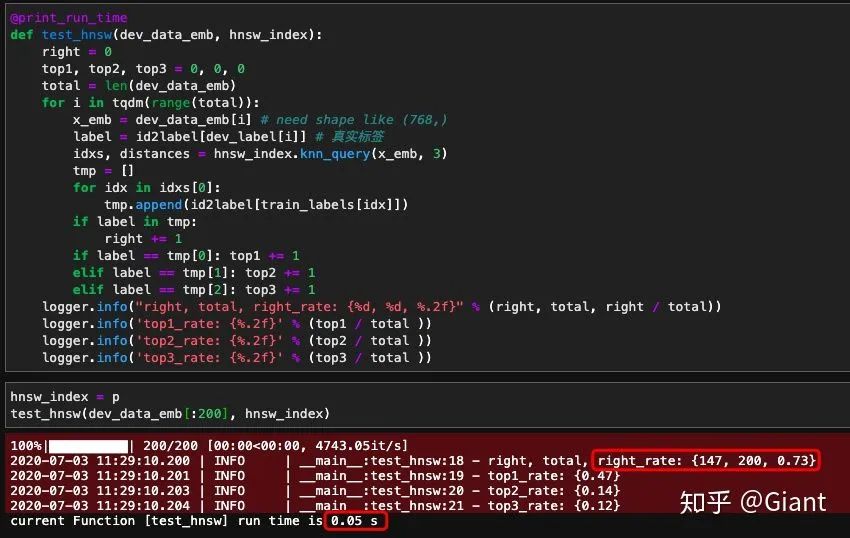
最终,预测200条样本耗时0.05秒(0.25ms/条),速度优于annoy。

此外,同样的53360条特征向量(768维度),保存为静态索引文件后 ann 索引的大小是227MB,hnsw索引是171MB,从这一点看hnsw也略胜一筹,可以节约部分内存。
参数设置中,ef表示最近邻动态列表的大小(需要大于查找的topk),M表示每个结点的“友点”数,是平衡时间/准确率的超参数。可以根据服务器资源和查找的召回率等,做相应调整。
7、小结
本文介绍了几种常用的k近邻查找算法,kdtree是KNN的一种基本实现算法;考虑到并发、延时等要素,annoy、hnsw是可以在实际业务中落地的算法,其中bert/sentence-bert+hnsw的组合会有不错的召回效果。
除此之外,还有众多近邻算法。感兴趣的同学可以阅读相关论文做进一步研究。
Reference:
1.Annoy - Github
2.HNSW - Github
3.Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
4.Five Balltree Construction Algorithms
5.李航 《统计学习方法》P53-P57: K近邻法的实现: kd树
6.快速计算距离Annoy算法原理及Python使用
7.HNSW算法理论的来龙去脉
8.高维空间最近邻逼近搜索算法评测
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/152522906
推荐阅读
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏