专访 | MATLAB更新R2017b:转换CUDA代码极大提升推断速度
机器之心原创
作者:蒋思源
近日,Mathworks 推出了包含 MATLAB 和 Simulink 产品系列的 Release 2017b(R2017b),该版本大大加强了 MATLAB 对深度学习的支持,并简化了工程师、研究人员及其他领域专家设计、训练和部署模型的方式。该更新版本从数据标注、模型搭建、训练与推断还有最后的模型部署方面完整地支持深度学习开发流程。此外,MATLAB 这次更新最大的亮点是新组件 GPU Coder,它能自动将深度学习模型代码转换为 NVIDIA GPU 的 CUDA 代码,GPU Coder 转换后的 CUDA 代码可以脱离 MATLAB 环境直接高效地执行推断。经 MATLAB 内部基准测试显示,GPU Coder 产生的 CUDA 代码,比 TensorFlow 的性能高 7 倍,比 Caffe2 的性能高 4.5 倍。
对此,机器之心采访了 MathWorks 中国资深应用工程师陈建平,陈建平从 MATLAB 中的数据标注开始沿着深度学习模型的开发、训练、调试到最后使用 GPU Coder 部署高性能模型,为我们介绍了 MATLAB 这一次更新针对深度学习所做的努力。本文将沿着 MATLAB 深度学习开发过程简要介绍这次更新的要点,同时重点向大家展示能自动将模型转化为 CUDA 代码的 GPU Coder 模块。
数据标注
对于计算机视觉来说,Computer Vision System Toolbox 中的 Ground Truth Labeler app 可提供一种交互式的方法半自动地标注一系列图像。除了目标检测与定位外,该工具箱现在还支持语义分割,它能对图像中的像素区域进行分类。陈建平说:「我们现在的标注工具可以直接半自动地完成任务,它可以像 Photoshop 中的魔棒工具一样自动标注出像素层级的类别,我们选中图片后工具会自动将对象抠出来。在我们完成初始化的图像语义分割后,工具会使用自动化的手段把后续行驶过程中的其它元素都抠出来。因为中间和后续过程都是以机器为主导完成的,所以我们只需要在前期使用少量的人力就能完成整个标注过程。」
这种半自动方法确实可以大大提升标注的效率,特别是标注车道边界线和汽车边界框等视觉系统目标。在这种自动标注框架下,算法可以快速地完成整个数据集的标注,而随后我们只需要少量的监督与验证就能构建一个精确的数据集。如下所示,MATLAB 文档向我们展示了如何创建车道线自动标注。
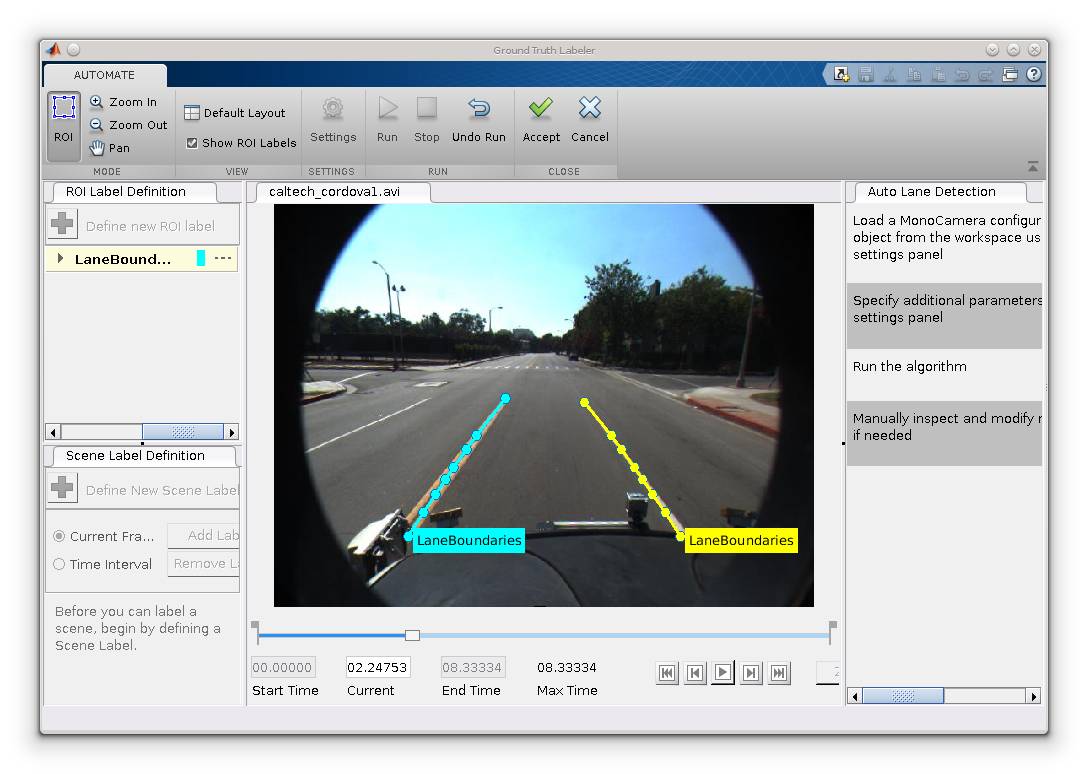
我们可以使用不同的算法,如能自动检测车道线特征的 Auto Lane Detection、使用聚合通道特征(Aggregate Channel Features/ACF)检测车辆的 ACF Vehicle Detector 和使用 Kanade-Lucas_Tomasi(KLT)在小间隔内追踪一个或多个 ROI 的算法等。如果我们选择自动算法,那么接下来设置 ROI、最大车道数、车道线宽度等参数后就可以直接运行自动标注。若视频经过人工微调与校验,并达到不错的效果,我们就可以选择「Accept」完成标注任务。
模型构建
在模型构建方面,Neural Network Toolbox 增加了对复杂架构的支持,包括有向无环图(DAG)和长短期记忆(LSTM)网络等,并提供对 GoogLeNet 等流行的预训练模型的访问方式。陈建平表示:「其实 MATLAB 在 2016 年的时候就已经支持一些深度学习模型,而现在不仅支持 VGGNet 和 GoogleNet 等流行的预训练模型,同时还支持使用 Caffe Model Importer 直接从 Caffe 中导入。」
因为我们可以直接从 Caffe Model Zoo 中导入各种优秀与前沿的模型,所以 MATLAB 在模型方面可以提供广泛的支持。但直接从 Caffe 中导入模型又会产生一个疑惑,即如果我们在 Python 环境下使用 Caffe 构建了一个模型,那么导入 MATLAB 是不是需要转写代码,会不会需要做一些额外的工作以完成导入?对此,陈建平解答到:「假设我们使用 Python 和 Caffe 完成了一个模型,并保存以 Caffe 格式,那么 Caffe Model Importer 会直接从保存的 Caffe 格式中读取模型。在这个过程中,Caffe 并不需要为 MATLAB 做额外的工作,所有的转换结果都是 MATLAB 完成的。」
在导入模型后,我们可以直接使用类似于 Keras 的高级 API 修改模型或重建模型。下面将简要介绍如何导入预训练 AlexNet,并修改完成迁移学习。
首先我们需要导入 AlexNet,如果 Neural Network Toolbox 中没有安装 AlexNet,那么软件会提供下载地址。
net = alexnet;
net.Layers
上面的语句将导入 AlexNet,并如下所示展示整个 CNN 的神经网络架构。其中 MATLAB 会展示所有的操作层,每一层都给出了层级名、操作类型和层级参数等关键信息。例如第二个操作层『conv1』表示一个卷积运算,该运算采用了 96 个卷积核,每一个卷积核的尺寸为 11×11×3、步幅为 4,该卷积运算采用了 padding。
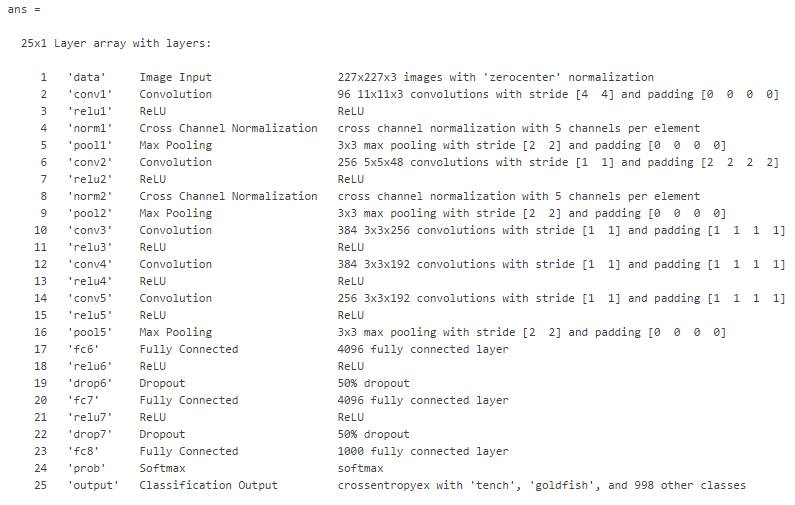
这种描述不仅有利于我们了解整个神经网络的架构,同时还有助于调整架构以匹配特定的任务。由上可知最后的全连接层、softmax 层和分类输出层是与 ImageNet 任务相关联的配置,因此我们需要去除这三个层级并重新构建与当前任务相关联的层级。MATLAB 可以十分简洁地实现这一过程:
layersTransfer = net.Layers(1:end-3);
numClasses = numel(categories(trainingImages.Labels))
layers = [
layersTransfer
fullyConnectedLayer(numClasses,'WeightLearnRateFactor',20,'BiasLearnRateFactor',20)
softmaxLayer
classificationLayer];
由上面的代码可知我们只提取了 AlexNet 预训练模型的前 22 层,而后依次新建了全连接层、softmax 层和分类输出层。完成整个层级重构后,剩下的就只需使用以下代码训练新的模型。其中 trainingImages 为当前任务的训练样本、layers 为前面修正的层级,而 options 是我们设置的一组训练参数,包括优化算法、最小批量大小、初始化学习率、绘制训练过程和验证集配置等设定。
netTransfer = trainNetwork(trainingImages,layers,options);
由上,我们发现 MATLAB 的深度学习代码非常简洁,调用高级 API 能快速完成模型的搭建。陈建平说:「MATLAB 上的高级 API 是一个完整的体系,它们完全是针对深度学习而设计的。当然我们还是会用基础的运算,因为 MATLAB 这么多年的累积可以充分体现在基础运算上,但是深度学习这一套高级 API 确实是新设计的。」
其实不只是 AlexNet,很多 Caffe 模型都能够导入到 MATLAB。那么,MATLAB 为什么会选择 Caffe 作为对接的深度学习框架,而不是近来十分流行的 TensorFlow?
陈建平解释说:「MATLAB 选择 Caffe 其实是有很多历史原因的,因为 Caffe 在 CNN 上做得非常好,传统上它在图像方面就是一个非常优秀的框架,从这个角度我们优先选择了 Caffe 作为支持的深度学习框架。当然,MATLAB 在很快也会有针对 TensorFlow 的导入功能。」
训练与推断
对于模型训练来说,最重要的可能就是能支持大规模分布式训练。因为目前的深度模型都有非常多的参数和层级,每一次正向或反向传播都拥有海量的矩阵运算,所以这就要求 MATLAB 能高效地执行并行运算。当然,我们知道 MATLAB 在并行运算上有十分雄厚的累积,那么在硬件支持上,目前其支持 CPU 和 GPU 之间的自动选择、单块 GPU、本地或计算机集群上的多块 GPU。此外,由于近来采用大批量 SGD 进行分布式训练的方法取得了十分优秀的结果,我们可以使用 MATLAB 调用整个计算机集群上的 GPU,并使用层级对应的适应率缩放(Layer-wise Adaptive Rate Scaling/LARS)那样的技术快速完成整个模型的训练。
在模型训练中,另外一个比较重要的部分就是可视化,我们需要可视化整个训练过程中的模型准确度、训练损失、验证损失、收敛情况等信息。当然 MATLAB 一直以来就十分重视可视化,在上例执行迁移学习时,我们也能得到整个训练过程的可视化信息。如下所示,上部分为训练准确度和验证准确度随迭代数的变化趋势,下部分为训练损失和验证损失随迭代数的变化趋势,该迁移学习基本上到第 3 个 epoch 就已经收敛。
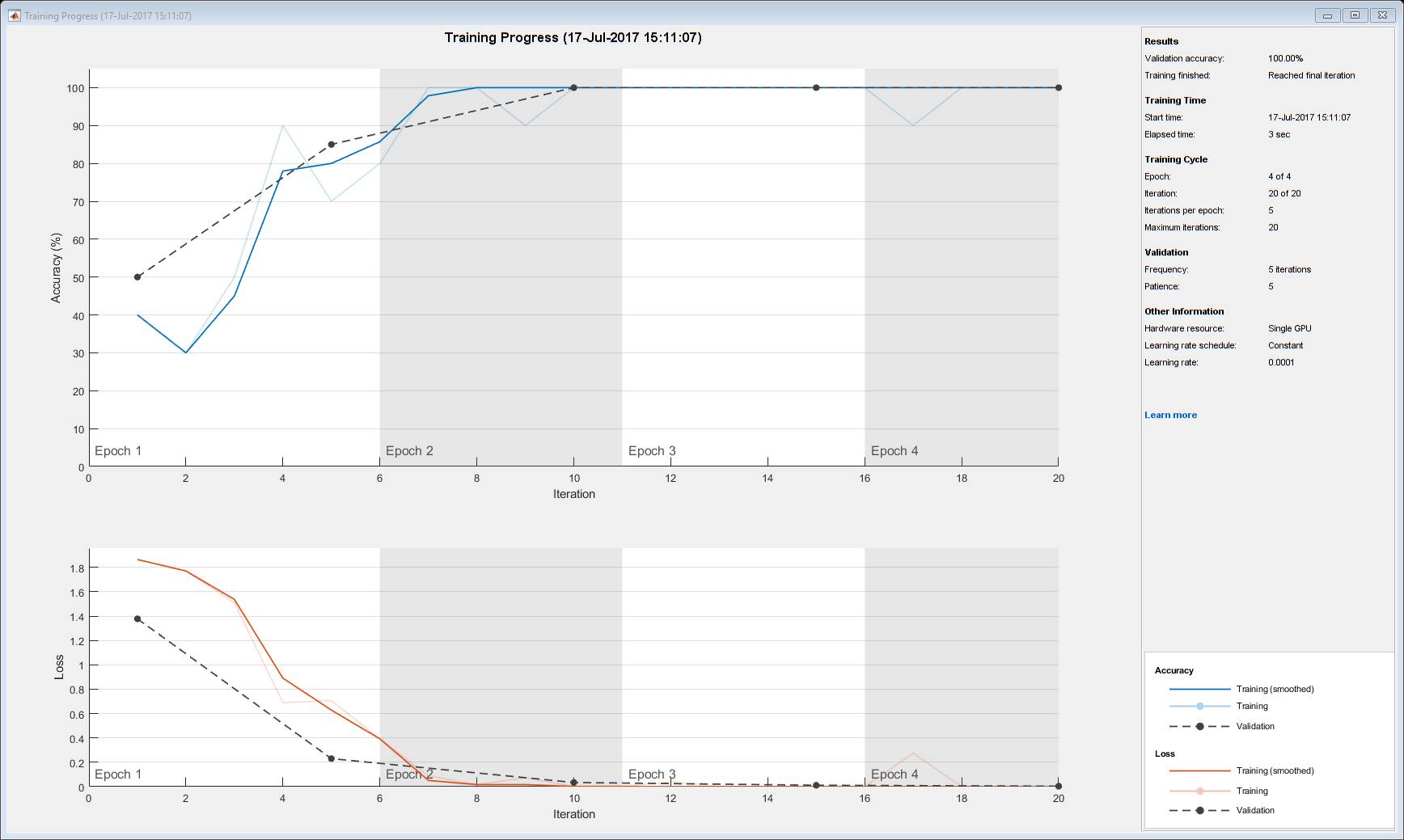
陈建平说:「训练是十分重要的,尤其是对关注算法本身的研究者。但如果我们考虑模型部署,那么也许推断会变得更加重要。」
对于推断来说,新产品 GPU Coder 可自动将深度学习模型转换为 NVIDIA GPU 的 CUDA 代码。内部基准测试显示,GPU Coder 产生的 CUDA 代码,比 TensorFlow 的性能提高 7 倍,比 Caffe2 的性能提高 4.5 倍。
陈建平说:「其实我们将 MATLAB 和其它框架做了一些基准对比,MATLAB 在测试中比 TensorFlow 快 2.5 倍,比 Caffe 快 40% 左右。而我们还有一种方法让模型的推断速度变得更快,也就是使用 GPU Coder 将模型转化为脱离 MATLAB 环境的 CUDA 代码。我们已经在一台 GPU 工作站上测试 GPU Coder 的效果,基本上它要比 TensorFlow 的性能高 7 倍,比 Caffe2 的性能高 4.5 倍。实际上在转换代码时我们剔除了很多额外的交互过程。其实 GPU Coder 对产品部署是十分有用的,因为 CUDA 代码对需要考虑很多限制的嵌入式系统十分重要,例如 CUDA 代码能高效地控制嵌入式系统的功耗。」
下图展示了内部基准测试的结果:
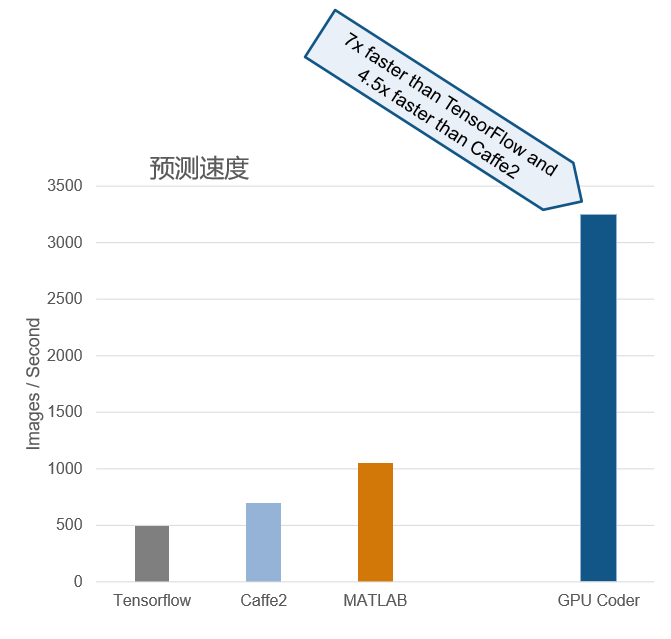
该测试使用 TitanXP GPU 和 Intel(R) Xeon(R) CPU E5-1650 v4 @ 3.60GHz 对 AlexNet 的推断性能进行了内部基准测试。使用的软件版本或框架是 MATLAB(R2017b)、TensorFlow(1.2.0) 和 Caffe2(0.8.1)。每个软件或框架都是使用 GPU 加速版来进行基准测试,所有测试均在 Windows 10 上运行。
模型部署
在 MATLAB 部署模型其实也很简单,MATLAB 很早就支持生成独立于其开发环境的其它语言,比如利用 MATLAB Coder 可以将 MATLAB 代码转换为 C 或 C++代码。而该最新版提供了新的工具 GPU Coder,我们能利用它将生成的 CUDA 代码部署到 GPU 中并进行实时处理,这一点对于应用场景是极其重要的。
GPU 代码生成其实在 MATLAB 中也十分简单,陈建平不仅利用车道线识别模型向我们演示了如何使用 GPU Coder 生成高效的 CUDA 代码,同时还展示了在脱离 MATLAB 环境下运行 CUDA 代码进行推断的效果。
陈建平说:「本质上车道线识别模型是通过迁移学习完成的,只不过在模型训练完成后,我们既不会直接在 CPU 上运行模型并执行推断,也不会单纯地通过 MATLAB 环境编译推断过程。因此我们可以通过 GPU Coder 和几行语句基于已训练的模型来产生 CUDA 代码。我们需要告诉 GPU Coder 各种信息,例如我们需要产生的外接包装是 C++、目标是产生一个 CUDA 库文件等。因为 C++ 需要定义严格的数据类型,所以在我们输入参数的信息后,Coder 会递归地推导输入所涉及的所有数据类型。最后 GPU Coder 会根据这些信息产生 CUDA 代码。」
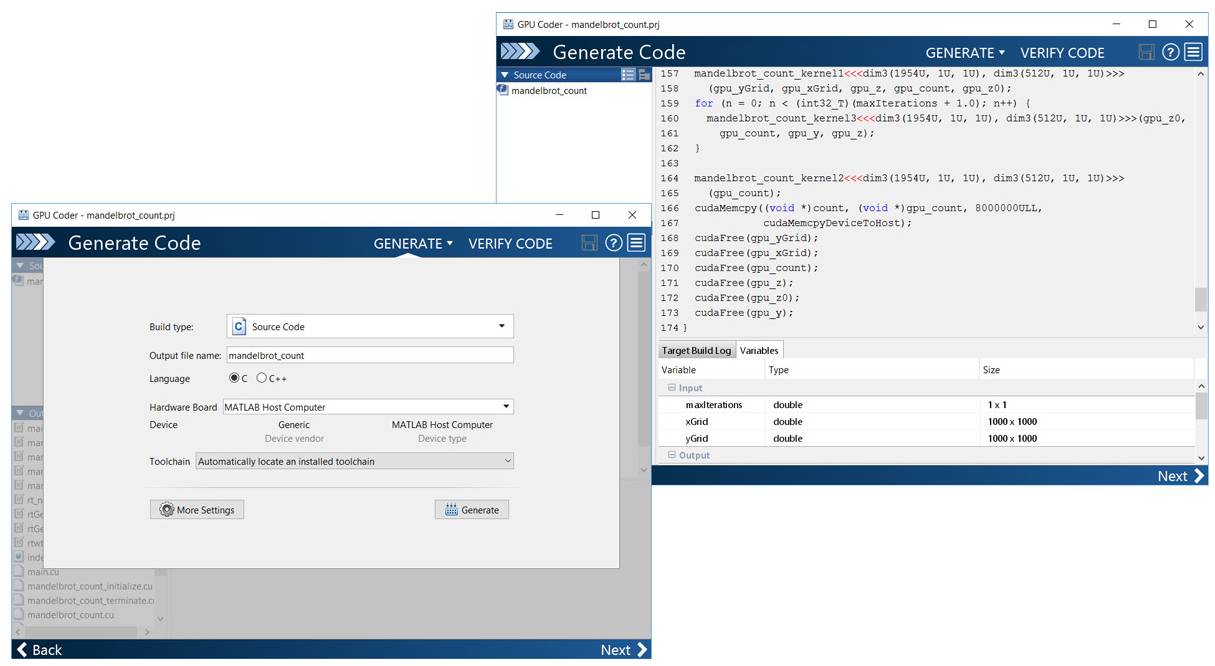
左图为GPU Coder app,右图展示了生成的CUDA代码
如果 GPU Coder 能将模型转化为 CUDA 代码,那么它到底是如何将一个串行设计的模型转换为并行的 CUDA 代码?
陈建平解释说:「推断过程本质上是一个并行过程,而推断的每一步我们可以认为是一个独立循环体。而现在我们有办法将这种独立循环体展开成大量的 CUDA 并发线程,这一过程都是自动完成的。其实 MATLAB 有工具能判断 For 循环是不是独立的,如果是的话它就会将这些 For 循环自动并行化。所以 CUDA 其实就是一种超多线程的并发模型,而只有这种并行化才能充分利用 GPU 的计算资源以加快推断速度。」
最后,MATLAB 会自动完成代码的并行化,并转化为高效的 CUDA 代码,因此我们能脱离 MATLAB 环境来执行整个推断过程。
结语
从数据源、模型构建、训练与推断到最终产品的部署,R2017B 补齐了整个开发链条。MathWorks 的 MATLAB 市场营销总监 David Rich 表示,「借助 R2017b,工程和系统集成团队可以将 MATLAB 拓展用于深度学习,以更好地保持对整个设计过程的控制,并更快地实现更高质量的设计。他们可以使用预训练网络,协作开发代码和模型,然后部署到 GPU 和嵌入式设备。使用 MATLAB 可以改进结果质量,同时通过自动化地真值标注 App 来缩短模型开发时间。」
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





