基于Docker的交互式人脸识别应用

极市导读
在本文中,你已经了解了如何将GUI、摄像头设备、GPU与Docker一起使用。了解如何结合这些,提供了许多可用于学术和商业目的的可能性。此外,使用相同的策略,通过Docker共享etc设备,你应该能够利用其他库和框架,而不必经历环境问题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

本文将介绍如何开发一个交互式应用程序,利用Adam Geitgey的人脸识别框架,从摄像头或网络摄像头设备识别人脸。
为了创建一个交互式应用程序,我们将使用Tkinter,Docker将用于确保一个包含所有必要依赖项的隔离环境。本文可以作为你自己项目的起点,因为使用哪些框架和库并不重要。
了解如何通过Docker创建一个利用摄像头设备、GPU加速和深度学习框架的交互式应用程序有很多可能性。
如果只希望通过Docker运行GUI,我创建了本文,你可以按照以下内容进行操作:https://towardsdatascience.com/empowering-docker-using-tkinter-gui-bf076d9e4974
如果你想立即运行应用程序,可以下载我的Github存储库,并按照本文末尾的“运行应用程序”部分进行操作。
阅读教程
在本文中,将介绍应用程序中的脚本,之后将介绍运行应用程序的教程。文章将按照以下顺序进行。
-
环境 -
应用程序概述 -
Docker -
编程 -
摄像设备 -
计算机视觉 -
Shell脚本 -
运行应用程序 -
结论
环境
此应用程序仅使用Linux进行了测试,但是,它的工作原理应该与其他操作系统类似,其中一些参数可能不同,例如在运行Docker时。
对于先决条件,你应该安装摄像头或网络摄像头、Docker、CUDA和CuDNN。我已使用以下方法测试了应用程序:
-
Docker 20.10.8 -
CUDA 11.4 -
CuDNN 8.2.2 -
OS:Manjaro 21.1.2 Phavo -
GPU:NVIDIA GeForce GTX 1080 Ti -
摄像头设备:罗技网络摄像头C930e
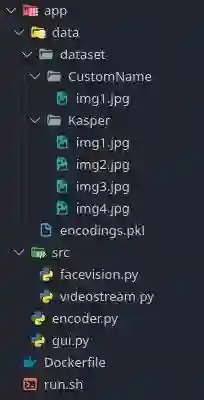
目录结构
本项目的目录结构如下所示。你可以事先创建这些文件,或者直接从我的Github存储库下载所有文件。
此外,你需要在dataset目录中创建自己的目录,并插入所需的图像。在我的例子中,如下所示,我在Kasper目录中添加了四个图像。你在不同场景中为同一个人添加的图像越多,你的预测就越可靠。关于脚本,本文将介绍它们的内容。
注意:encodings.pkl将在以后自动生成。
应用程序的目录结构:
应用程序概述
该应用程序包含一个GUI,其中有一个用于显示相机设备输出的面板。此外,还有一个用于激活/禁用人脸识别的按钮。
当前打开人脸识别的应用程序。

Docker
为了创建一个安装人脸识别、OpenCV、Dlib、Python等的隔离环境,使用了以下Docker代码。
Dockerfile创建隔离环境:
FROM nvidia/cuda:11.4.1-cudnn8-devel-ubuntu20.04
ARG DEBIAN_FRONTEND=noninteractive
# Install dependencies
RUN apt-get update -y
RUN apt-get install -y \
git \
cmake \
libsm6 \
libxext6 \
libxrender-dev \
python3 \
python3-pip \
gcc \
python3-tk \
ffmpeg \
libopenblas-dev \
liblapack-dev
# Install dlib
RUN git clone https://github.com/davisking/dlib.git && \
cd dlib && \
mkdir build && \
cd build && \
cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1 && \
cmake --build . && \
cd .. && \
python3 setup.py install
# Install Face Recognition and OpenCV
RUN pip3 install face_recognition opencv-python
WORKDIR /face_recognition/app
Tkinter
为了创建一个可由用户控制的交互式GUI以启用和禁用人脸识别,使用Tkinter库。下面的代码创建了先前显示的GUI。
主脚本,用于创建GUI并允许人脸识别。
import tkinter as tk
from src.facevision import FaceVision
from src.videostream import VideoStream
if __name__ == '__main__':
# Tkinter窗口
root_window = tk.Tk()
# Window设置
root_window.title('Face Recognition')
root_window.geometry('500x540') # widthxheight+x+y
root_window.configure(background='#353535')
# 摄像头可视化面板
panel = tk.Label(root_window)
panel.pack(side='top', fill='none')
# FaceVision初始化
face_vision = FaceVision()
# Webcam初始化
vs = VideoStream(panel=panel, face_vision=face_vision)
vs.stream()
# 人脸识别按钮
button_face_recognition = tk.Button(root_window, text='Activate Face Recognition', command=lambda: face_vision.change_facerec_state(button_face_recognition))
button_face_recognition.pack()
# 主循环
root_window.mainloop()
摄像设备
为了从相机设备获取图像并更新Tkinter GUI,可以使用以下脚本。
在第7行中,它使用函数VideoCapture by OpenCV,其中的参数应与你的设备相对应。默认相机id通常为0,但是,如果不起作用,可以尝试使用1或-1。
如果你希望使用视频,你应该能够用视频路径替换设备id,但可能需要进行一些其他调整。在第26行,它在一毫秒后再次调用函数本身。
import cv2
from PIL import Image, ImageTk
class VideoStream():
def __init__(self, panel, face_vision):
self.cap = cv2.VideoCapture(0) # 参数应该对应于你的设备
self.panel = panel
self.face_vision = face_vision
def stream(self):
# 从相机获取图像
_, frame = self.cap.read()
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 人脸识别
img = self.face_vision.process_image(img=img)
# Tkinter
img = Image.fromarray(img)
tk_img = ImageTk.PhotoImage(img)
self.panel.imgtk = tk_img
self.panel.configure(image=tk_img)
# 再次运行
self.panel.after(ms=1, func=self.stream)
计算机视觉
与大多数计算机视觉应用程序相反,在大多数计算机视觉应用程序中,你通过展示数百个类的示例来训练模型以对所需类进行分类,而在人脸识别中,你可以使用深度度量学习。
通过深度度量学习,你可以训练模型来描述所需对象,而不是预测它是哪个类。在我们的例子中,我们使用它来提供一个特征向量,一种128维编码,它使用实数来描述每个人脸。教授一个模型来描述人脸而不是预测一个特定的人是一个优势,因为如果想要识别一个新的人,就不需要对模型进行再训练。
相反,我们应该简单地保存模型可以访问的新人的编码。我们将在本文后面获得这些编码。使用框架人脸识别,我们不必从头开始训练模型,而是使用通过人脸识别提供的已经训练过的模型。如果想要进一步探索人脸识别领域,《人脸识别框架》详细阐述了这一主题:
https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
数据集与编码器
为了使模型能够识别人脸,需要一个包含人脸编码的pickle文件。要实现这一点,正如前面在“目录结构”一节中提到的,你必须在目录数据集中创建一个包含所需人员姓名的目录。之后,编码器应包含以下代码。
在这段代码中,我们递归地获取dataset目录中每个人的所有图像。通过使用人脸识别框架,我们定位人脸并为每幅图像提取编码。
构造包含数据集编码的pickle文件:
import face_recognition
import cv2
from pathlib import Path
import pickle
if __name__ == '__main__':
print('Starting Encoding..')
data = {'names': [], 'encodings': []}
# 数据集路径
path = Path.cwd() / './data/dataset/'
# 浏览每一张图片
for file_name in path.rglob('*.jpg'):
# 从数据集读取图像
img = cv2.imread(str(file_name))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 定位人脸
face_location = face_recognition.face_locations(img, number_of_times_to_upsample=1, model='cnn')
# 编码的人脸
encoding = face_recognition.face_encodings(face_image=img, known_face_locations=face_location, model='small')
# 保存信息
data['names'].append(file_name.parent.name)
data['encodings'].append(encoding)
# 在pickle文件中保存编码
with open('./data/encodings.pkl', 'wb') as f:
pickle.dump(data, f)
print('Completed Encoding!')
人脸识别
为了识别人脸,将使用以下代码。为了总结代码,它使用来自我们的相机设备的图像,检测人脸,为每个人脸提取128维编码,然后将新编码与我们的编码数据集进行比较。
为了进行比较,它会检查新编码的特征与我们编码的数据集之间的距离,如果特征的距离小于阈值参数,则该特征将获得投票。为了找到最佳匹配,我们只需选择得票最多的人。如果简单的解决方案不够,你可以实现更强大的分类器。
更具体地说,视频流为每一帧调用函数process_image,该函数完成了实现人脸识别所需的所有工作。在第43–45行中,可以调整比较的阈值参数。阈值越低,比较就越严格。此外,在第48-51行中,最高投票数也可以调整,以增加或减少严格程度。
计算机视觉部分,基于人脸识别框架:
import face_recognition
import pickle
import cv2
import numpy as np
class FaceVision():
def __init__(self):
# 加载编码
data = pickle.loads(open('./data/encodings.pkl', 'rb').read())
self.encoded_data = data['encodings']
self.name_data = data['names']
self.use_face_recognition = False
def process_image(self, img):
# 检测和定位人脸
face_locations = self.__locate_faces(img)
# 如果没有找到人脸,返回原始图像
if not face_locations:
return img
# 编码输入图像
encodings = face_recognition.face_encodings(face_image=img, known_face_locations=face_locations, model='small')
# 通过比较新的编码和之前编码的pickle文件来识别人脸
self.__identify_faces(image=img, face_locations=face_locations, encodings=encodings)
return img
def __locate_faces(self, image):
if self.use_face_recognition is True:
# 检测人脸并接收他们的位置
face_locations = face_recognition.face_locations(img=image, number_of_times_to_upsample=1, model='cnn')
return face_locations
def __identify_faces(self, image, face_locations, encodings):
# 比较保存的编码和新的编码
for face_bbox, encoding in zip(face_locations, encodings):
# 找到匹配
matches = face_recognition.compare_faces(known_face_encodings=self.encoded_data,
face_encoding_to_check=encoding,
tolerance=0.01)
# 计算投票并找到最佳匹配
votes = [np.count_nonzero(m==True) for m in matches]
highest_vote = max(votes)
highest_vote_idx = votes.index(highest_vote)
person_match = self.name_data[highest_vote_idx]
# 投票阈值,如果没有超过,投票的名字将是Unknown
if highest_vote < 20:
person_match = 'Unknown'
# 添加可视化图像
t, r, b, l = face_bbox
cv2.rectangle(image, (l, t), (r, b), (0, 255, 0), 2)
cv2.putText(image, person_match, (l, t-10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 1)
def change_facerec_state(self, button):
# 取反
self.use_face_recognition = not self.use_face_recognition
# 改变按钮的文本
if self.use_face_recognition is True:
button.configure(text='Disable Face Recognition')
else:
button.configure(text='Activate Face Recognition')
Shell脚本(警告)
为了简化操作,请创建一个shell脚本,该脚本使用以下参数运行xhost和Docker。
对于xhost,启用对所有人的访问,然后在卸载Docker容器后禁用它。在这个Docker命令中,我们共享GPU,显示GUI。
警告:如果在本地运行,则使用xhost和这些Docker参数不应成为问题。但是,如果在生产中使用,则应增强安全性,这在此处是推荐的。
自动启用/禁用xhost并运行Docker容器:
#!/bin/bash
xhost +
docker run --gpus all --device /dev/nvidia0 --device /dev/nvidia-uvm --device /dev/nvidia-uvm-tools \
--device /dev/nvidiactl \
-it \
--rm \
-e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix:rw \
-v $(pwd):/face_recognition \
--device=/dev/video0:/dev/video0 \
face_recognition
xhost -
运行应用程序
-
构建Docker镜像: docker build -t facerecognition_gui -
使shell脚本可执行: chmod +x ./run.sh -
运行shell脚本: ./run.sh -
在Docker容器中,创建编码的数据集(确保图像位于数据集目录中的目录中): python3 encoder.py -
运行应用程序: python3 gui.py -
现在可以启用人脸识别。
注意:要分离/退出Docker容器,请按ctrl-D
结论
在本文中,你已经了解了如何将GUI、摄像头设备、GPU与Docker一起使用。了解如何结合这些,提供了许多可用于学术和商业目的的可能性。
此外,使用相同的策略,通过Docker共享etc设备,你应该能够利用其他库和框架,而不必经历环境问题。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





