特斯拉AI主管新作:用当前深度学习技术复现LeCun 33年前手写数字识别论文
译者:Yang
来源:学术头条
我认为 Yann LeCun 等人于 1989 年发表的论文「反向传播应用于手写邮政编码识别」(Backpropagation Applied to Handwritten Zip Code Recognition),具有相当重要的历史意义,因为据我所知,这是最早用反向传播机制端到端训练的神经网络在现实生活中的应用。
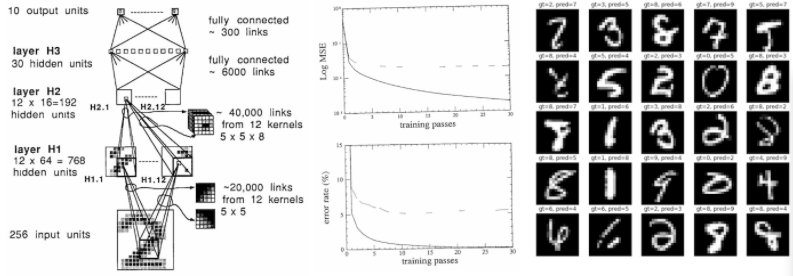
除了其使用的微型数据集(7291 个 16x16 的灰度数字图像)和微型神经网络(仅 1000 个神经元)显得落伍之外,在 33 年后的今天,这篇论文读来仍然十分新颖——它展示了一个数据集,描述了神经网络结构、损失函数、优化器,并报告了在训练集和测试集上实验得到的错误率。
除了时光已流逝 33 年,这篇文章仍是一篇标准的深度学习论文。因此,我此次复现这篇论文,一是为了好玩,二是将这次练习作为一个案例来研究深度学习进展的本质。
2)一个自动求导引擎,能跟踪正向计算特征,并能提供反向传播操作;
3)可编程(Python)的深度学习编码器,高级的 API,需要包含常见的深度学习操作,比如构建层、架构、提供优化器、损失函数等。
训练细节
复现 1989 年的表现
eval: split train. loss 2.5e-3. error 0.14%. misses: 10
eval: split test . loss 1.8e-2. error 5.00%. misses: 102
而我的复现代码在同时期的表现如下:
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45
eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
由此可见,我只能粗略地再现这些结果,却不能做到完全一样。可悲的是,很可能永远无法进行精确复现了,因为我认为原始数据集已经被遗弃在了时间的长河中。
坐上时光车「作弊」
这是我最喜欢的部分。
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45
eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
eval: split train. loss 9.536698e-06. error 0.00%. misses: 0
eval: split test . loss 9.536698e-06. error 4.38%. misses: 87
eval: split train. loss 0.000000e+00. error 0.00%. misses: 0
eval: split test . loss 0.000000e+00. error 3.59%. misses: 72
eval: split train. loss 8.780676e-04. error 1.70%. misses: 123
eval: split test . loss 8.780676e-04. error 2.19%. misses: 43
eval: split train. loss 2.601336e-03. error 1.47%. misses: 106
eval: split test . loss 2.601336e-03. error 1.59%. misses: 32

更进一步
用数据「作弊」
eval: split train. loss 4.073383e-03. error 0.62%. misses: 45
eval: split test . loss 2.838382e-02. error 4.09%. misses: 82
eval: split train. loss 1.305315e-02. error 2.03%. misses: 60
eval: split test . loss 1.943992e-02. error 2.74%. misses: 54
eval: split train. loss 3.238392e-04. error 1.07%. misses: 31
eval: split test . loss 3.238392e-04. error 1.25%. misses: 24
总而言之,在 1989 年简单地扩展数据集将是提高系统性能的有效方法,且不需要牺牲推理时间。
反思
-
首先,33 年来宏观层面上没有太大变化。我们仍在建立由神经元层组成的可微神经网络结构,并通过反向传播和随机梯度下降对其进行端到端优化。所有的东西读起来都非常熟悉,只是 1989 时它们的体量比较小。
-
按照今天的标准,1989 年的数据集就是一个「婴儿」:训练集只有 7291 个 16x16 的灰度图像。今天的视觉数据集通常包含数亿张来自网络的高分辨率彩色图像(例如,谷歌有 JFT-300M,OpenAI CLIP 是在 400M 的数据集上训练的),但仍会增长到几十亿。这大约是此前每幅图像约一千倍的像素信息(384*384*3/(16*16))乘以十万倍的图像数(1e9/1e4),输入的像素数据的差距约为一亿倍。
-
那时的神经网络也是一个「婴儿」:这个 1989 年的网络有大约 9760 个参数、64 K 个位址和 1 K 个激活值。现代(视觉)神经网络的规模通常有几十亿个小参数(1000000X)和 O(~1e12)个位址数(~1000000X),而自然语言模型甚至可以达到数万亿级别的参数量。
-
最先进的分类器花了 3 天时间在工作站上训练,而现在在我的无风扇笔记本电脑上训练只需 90 秒(3000 倍原始提速),通过切换到全批量优化并使用 GPU,很可能能进一步获得 100 倍的提升。
-
事实上,我能够根据现代的技术创新调整模型,比如使用数据增强,更好的损失函数和优化器,以将错误率降低 60%,同时保持数据集和模型的测试时间不变。
-
仅通过增大数据集就可以获得适度的收益。
-
进一步的显著收益可能来自更大的模型,这将需要更多的计算成本和额外的研发,以帮助在不断扩大的规模上稳定训练。值得一提的是,如果我被传送到 1989 年,我最终会在没有更强大计算机的情况下,使模型达到改进能力的上限。
-
2055 年的神经网络在宏观层面上与 2022 年的神经网络基本相同,只是更大。
-
我们今天的数据集和模型看起来像个笑话。两者都在大约上千亿倍大于当前数据集和模型。
-
我们可以在个人电脑设备上用大约一分钟的时间来训练 2022 年最先进的模型,这将成为一个有趣的周末项目。
-
今天的模型并不是最优的,只要改变模型的一些细节,损失函数,数据增强或优化器,我们就可以将误差减半。
-
我们的数据集太小,仅通过扩大数据集的规模就可以获得适度的收益。
-
如果不升级运算设备,并投资一些研发,以有效地训练如此规模的模型,就不可能取得进一步的收益。
作者介绍

原文链接:
http://karpathy.github.io/2022/03/14/lecun1989/
登录查看更多
相关内容

反向传播一词严格来说仅指用于计算梯度的算法,而不是指如何使用梯度。但是该术语通常被宽松地指整个学习算法,包括如何使用梯度,例如通过随机梯度下降。反向传播将增量计算概括为增量规则中的增量规则,该规则是反向传播的单层版本,然后通过自动微分进行广义化,其中反向传播是反向累积(或“反向模式”)的特例。
在机器学习中,反向传播(backprop)是一种广泛用于训练前馈神经网络以进行监督学习的算法。对于其他人工神经网络(ANN)都存在反向传播的一般化–一类算法,通常称为“反向传播”。反向传播算法的工作原理是,通过链规则计算损失函数相对于每个权重的梯度,一次计算一层,从最后一层开始向后迭代,以避免链规则中中间项的冗余计算。
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月15日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月15日