AAAI 2020 | 北理工&阿里文娱:你所看视频的介绍,可以用到这样的「图像描述」技术
机器之心发布
机器之心编辑部
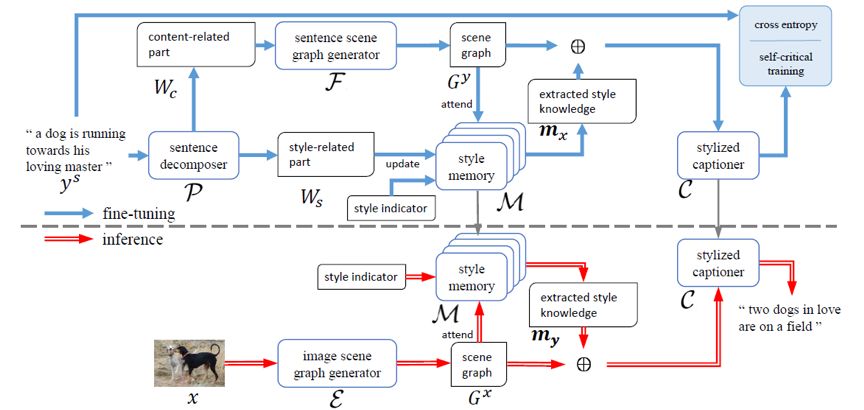
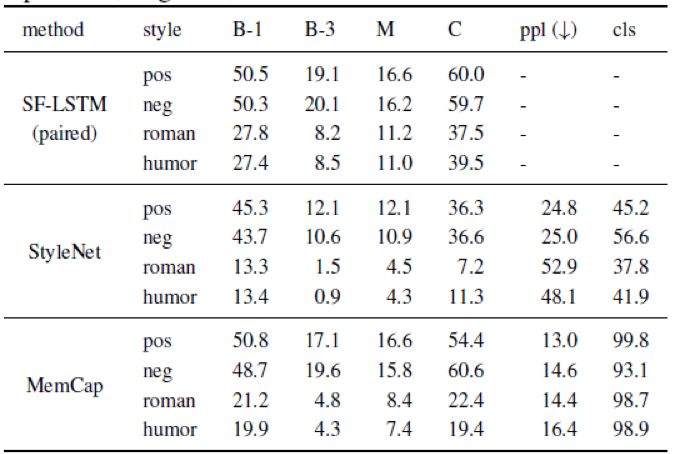
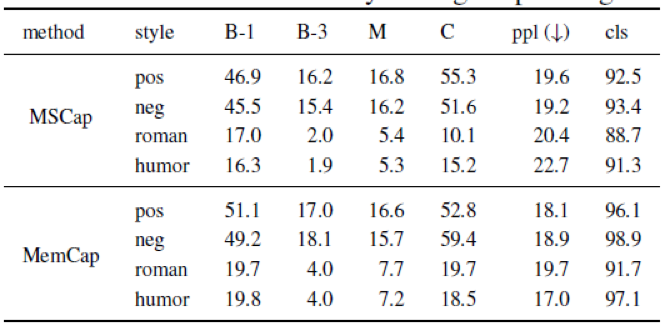
人工智能顶级会议 AAAI 2020 将于 2 月 7 日-2 月 12 日在美国纽约举办,不久之前,AAAI 2020 公布论文介绍结果:今年最终收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。本文对北京理工大学、阿里文娱摩酷实验室合作的论文《MemCap:Memorizing Style Knowledge for Image Captioning》进行解读。



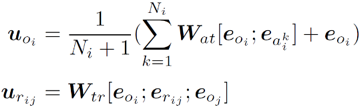
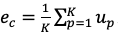


登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年3月3日
Arxiv
3+阅读 · 2018年5月28日



相关VIP内容
专知会员服务
54+阅读 · 2020年3月3日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年5月28日